监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),如果预测的变量是连续的,我们称其为回归。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线性是一个超平面...这里,谈一谈最简单的一元线性回归模型。
1.一元线性回归模型
模型如下:
总体回归函数中Y与X的关系可是线性的,也可是非线性的。对线性回归模型的“线性”有两种解释:
(1)就变量而言是线性的,Y的条件均值是 X的线性函数
(2)就参数而言是线性的,Y的条件均值是参数
 的线性函数
的线性函数
线性回归模型主要指就参数而言是“线性”,因为只要对参数而言是线性的,都可以用类似的方法估计其参数。
2.参数估计——最小二乘法
对于一元线性回归模型, 假设从总体中获取了n组观察值(X1,Y1),(X2,Y2), …,(Xn,Yn)。对于平面中的这n个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好地拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。 选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小。有以下三个标准可以选择:
(1)用“残差和最小”确定直线位置是一个途径。但很快发现计算“残差和”存在相互抵消的问题。
(2)用“残差绝对值和最小”确定直线位置也是一个途径。但绝对值的计算比较麻烦。
(3)最小二乘法的原则是以“残差平方和最小”确定直线位置。用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。这种方法对异常值非常敏感。
最常用的是普通最小二乘法( Ordinary Least Square,OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。(Q为残差平方和)
样本回归模型:
残差平方和:
则通过Q最小确定这条直线,即确定
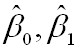 ,以
,以
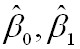 为变量,把它们看作是Q的函数,就变成了一个求极值的问题,可以通过求导数得到。求Q对两个待估参数的偏导数:
为变量,把它们看作是Q的函数,就变成了一个求极值的问题,可以通过求导数得到。求Q对两个待估参数的偏导数:
3.最小二乘法c++实现
#include<iostream>
#include<fstream>
#include<vector>
using namespace std;
class LeastSquare{
double a, b;
public:
LeastSquare(const vector<double>& x, const vector<double>& y)
double t1=0, t2=0, t3=0, t4=0;
for(int i=0; i<x.size(); ++i)
t1 += x[i]*x[i];
t2 += x[i];
t3 += x[i]*y[i];
t4 += y[i];
a = (t3*x.size() - t2*t4) / (t1*x.size() - t2*t2);
//b = (t4 - a*t2) / x.size();
b = (t1*t4 - t2*t3) / (t1*x.size() - t2*t2);
double getY(const double x) const
return a*x + b;
void print() const
cout<<"y = "<<a<<"x + "<<b<<"\n";
int main(int argc, char *argv[])
if(argc != 2)
cout<<"Usage: DataFile.txt"<<endl;
return -1;
vector<double> x;
ifstream in(argv[1]);
for(double d; in>>d; )
x.push_back(d);
int sz = x.size();
vector<double> y(x.begin()+sz/2, x.end());
x.resize(sz/2);
LeastSquare ls(x, y);
ls.print();
cout<<"Input x:\n";
double x0;
while(cin>>x0)
cout<<"y = "<<ls.getY(x0)<<endl;
cout<<"Input x:\n";
监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),如果预测的变量是连续的,我们称其为回归。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线
总体回归函数中Y与X的关系可是线性的,也可是非线性的。对线性回归模型的“线性”有两种解释:
(1)就变量而言是线性的,Y的条件均值是 X的线性函数
(2)就参数而言是线性的,Y的条件均值是参数的线性函数
线性回归模型主要指就参数而...
5月9号到北大去听hulu的讲座《推荐系统和计算广告在视频行业应用》,想到能见到传说中的项亮大神,特地拿了本《推荐系统实践》求签名。讲座开始,主讲人先问了下哪些同学有机器学习的背景,我恬不知耻的毅然举手,真是惭愧。后来主讲人在讲座中提到了最小二乘法,说这个是机器学习最基础的算法。神马,最基础,我咋不知道呢! 看来以后还是要对自己有清晰认识。
回来赶紧上百度,搜了下...
//最小二乘拟合相关函数定义
double sum(vector<double> Vnum, int n);
double MutilSum(vector<double> Vx, vector<double> Vy, int n);
目标值 y 是输入变量 x 的线性组合
如果 y^\hat{y}y^ 是预测值,那么有:
y^(w,x)=w0+w1x1+…+wpxp\hat{y}(w, x) = w_0 + w_1 x_1 + … + w_p x_py^(w,x)=w0+w1x1+…+wpxp
在sklearn中,定义向量 w=(w1,…,wp)w = (w_1, …, w_p)w=(w1,…,wp) 为系数(斜率) coef_ ,定义 w0w_0w0 为截距 intercept_
普通最小二乘法
在sklearn中,LinearRegression 拟合
神经网络模型可以通过多层神经元的组合来逼近一元线性回归模型。具体来说,可以使用一个输入层和一个输出层,其中输入层只有一个神经元,输出层有一个神经元。在训练过程中,通过反向传播算法来更新神经元的权重和偏置,使得神经网络的输出尽可能接近真实值。
与传统的最小二乘法相比,神经网络模型具有以下不同之处:
1. 神经网络模型可以处理非线性关系,而最小二乘法只能处理线性关系。
2. 神经网络模型可以自适应地学习数据的特征,而最小二乘法需要手动选择特征。
3. 神经网络模型可以处理大量数据,而最小二乘法可能会因为数据量太大而无法处理。
4. 神经网络模型需要大量的计算资源和时间来训练,而最小二乘法的计算量相对较小。
总之,神经网络模型和最小二乘法都有各自的优缺点,需要根据具体问题来选择合适的方法。
typedef函数指针用法
爱钓鱼的歪猴:
typedef函数指针用法
爱钓鱼的歪猴:

