![]()
这篇博士论文解决了大型语言模型(LLMs)的两个重要挑战:鲁棒性和可扩展性。首先,我们通过学习代码表示的视角来提高大型语言模型的鲁棒性。我在这里强调我们在ContraCode上的工作,该模型学习了对保留标签编辑具有鲁棒性的代码表示。其次,我们从系统角度解决可扩展性挑战。我们提出了Checkmate,这是一个通过最优再物化超越GPU内存容量限制来支持模型训练的系统。此外,Skyplane,一种优化云对象存储之间大批量数据传输的系统,使得在云端训练更大的预训练数据集成为可能。总的来说,这些贡献为提高大型语言模型的鲁棒性和可扩展性提供了一条路径。
在1945年,Vannevar Bush设想出了一种名为memex的假想设备,该设备能够存储和索引人类的所有知识,使用户能够通过"全新形式的百科全书"查询和导航知识。尽管Bush设想的memex是一种基于机械微胶片的设备,但他的远见远超出了该设备的物理形态。他预见了深度语言理解、知识存储和推理系统的发展。大型语言模型(LLMs)通过学习可以查询和推理的语言表示,已经朝这个方向取得了重大进展。不同于以往的语言模型,这些神经网络在大量数据上进行训练,以预测单词并理解语言。他们在某些基准测试上达到了人类水平的表现,但也面临着限制其广泛部署的重大挑战。具体来说,大型语言模型在两个维度上面临重要难关:鲁棒性和可扩展性。大型语言模型的鲁棒性是一个多面的挑战。虽然大型语言模型在理解和生成文本方面取得了显著进步,但他们仍然在处理幻觉、对输入扰动的敏感性和组合泛化上存在困难。另一方面,可扩展性是一个关于规模和计算资源的挑战。对于大型语言模型,交叉熵损失随着模型规模、数据集规模和用于训练的计算量的增加而呈幂律增长。在这篇博士论文中,我为持续改进大型语言模型的鲁棒性和可扩展性做出了贡献。
第二章:增强大型语言模型的鲁棒性
在第二章中,我们研究了提高大型语言模型鲁棒性的策略。这个讨论的一个核心问题是语言建模目标是否会导致学习鲁棒的语义表示,或者仅仅是基于局部上下文预测标记。为了回答这个问题,我们转向源代码的情境,其中程序的语义是由其执行定义的。我们探索了对比预训练任务ContraCode,它学习代码的功能而不是形式。ContraCode预训练一个神经网络,区分功能上类似的程序变体与众多非等效的干扰项。这种策略在JavaScript总结和TypeScript类型推断精度上显示出改善。我们还介绍了一个新的零射击JavaScript代码克隆检测数据集,结果表明与其他方法相比,ContraCode更具鲁棒性和语义意义。
第三章:解决大型语言模型的可扩展性挑战
在第三章中,我们开始解决大型语言模型的可扩展性挑战,首先考察了在训练大型模型过程中出现的"内存壁"问题。在这里,我们介绍了Checkmate,一个在DNN训练中优化计算时间和内存需求之间权衡的系统。Checkmate解决了张量重制化优化问题,这是先前检查点策略的一种推广。它使用现成的MILP求解器确定最优的重制化计划,并加速了数百万次的训练迭代。该系统可以扩展到复杂、现实的架构,并且是硬件感知的,使用基于特定加速器的配置文件成本模型。Checkmate使得能够训练实际网络,其输入最大可达5.1倍。
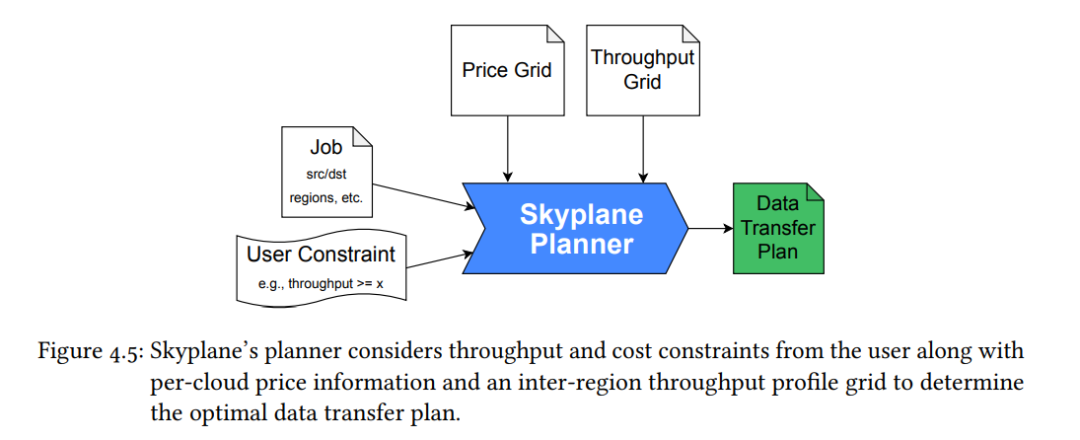
第四章:大型预训练数据集的管理
在第四章中,我们探讨了大型预训练数据集的管理,这也是可扩展性挑战的另一个方面。具体而言,我们研究了如何在云端目标之间收集和移动这些数据集。我们介绍了Skyplane,一个使用云感知网络覆盖来进行云对象存储间批量数据传输的系统。它使用混合整数线性规划来确定数据传输的最优覆盖路径和资源分配,从而优化价格和性能的平衡。Skyplane在单一云中的传输性能比公共云传输服务高出4.6倍,跨云传输性能高出5.0
![]()