

深入分析Kafka Connect的Worker实现

根据Confluent官方文档 Kafka Connect Concept 的描述。Kafka Connect的Connectors和Tasks都是运行在进程中的逻辑工作单元。而这些工作进程称为 Worker ,Kafka Connect运行逻辑如下图所示:
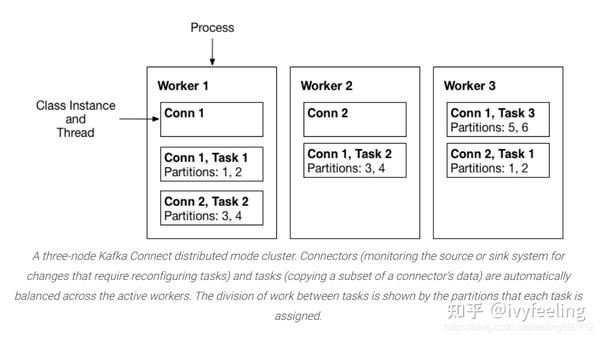
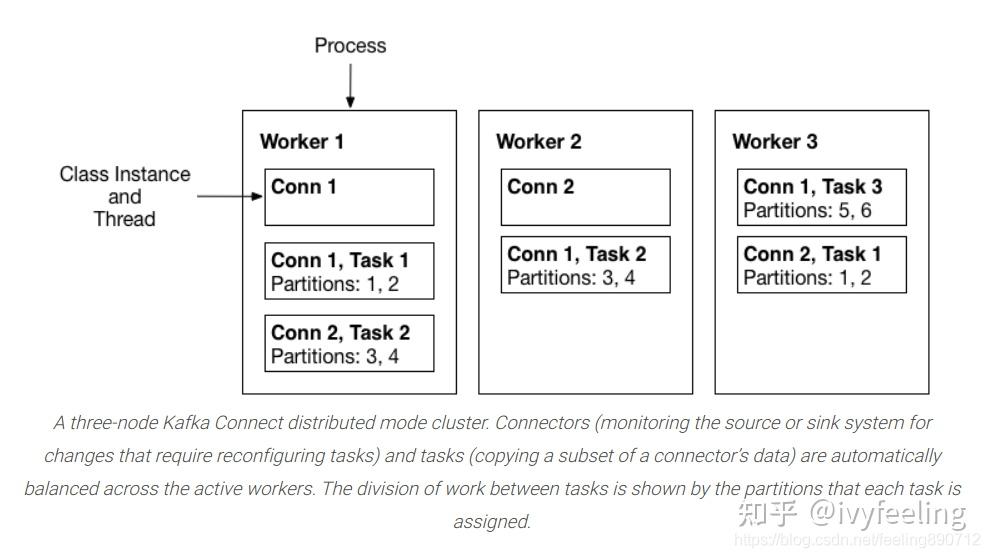
从上图来看,一个Kafka Connect进程就是一个Woker。同一组Kafka Connect组成同一组Worker,分担属于该组的Connectors和Taskss运行工作。根据 Distributed mode下Kafka Connect启动流程详解 分析的启动过程来看,Kafka Connect源码中抽象了一个 Worker 类,在启动的时候会创建一个实例,并且运行。这篇文章就是深入分析 Worker 类的实现和如何启动运行分配给它的Connectors和Tasks。
Worker中的线程池
Woker中有一个线程池,用于运行Connectors和Tasks的工作的。Worker的公共构造函数如下:
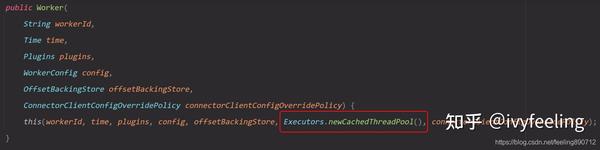
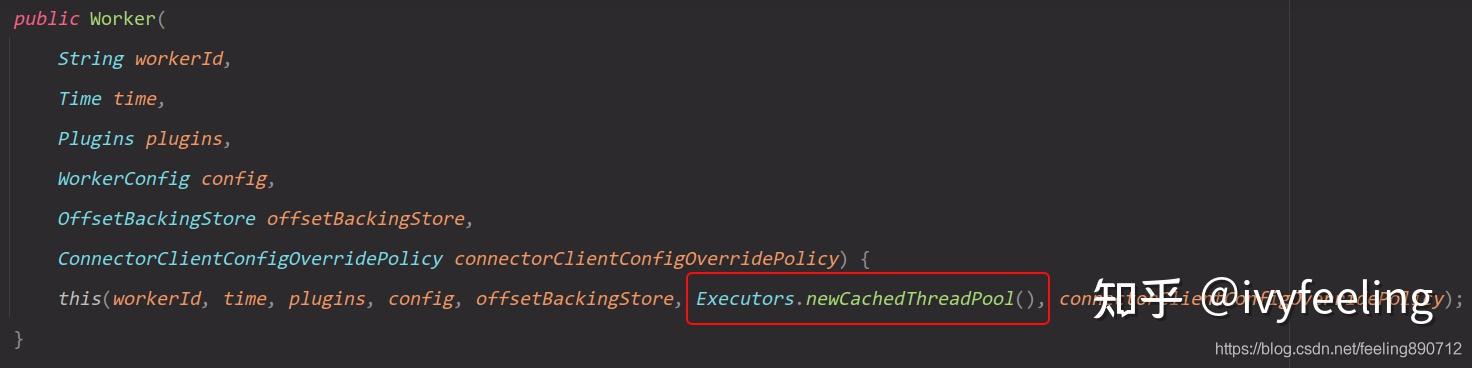
从上面的构造函数可知,Worker的线程池是一个默认的缓存线程池。每次要运行一个Connector或Task任务,都会提交一个Runnable。线程池会随着运行的Connectors和Tasks数量增加。
Worker的启动
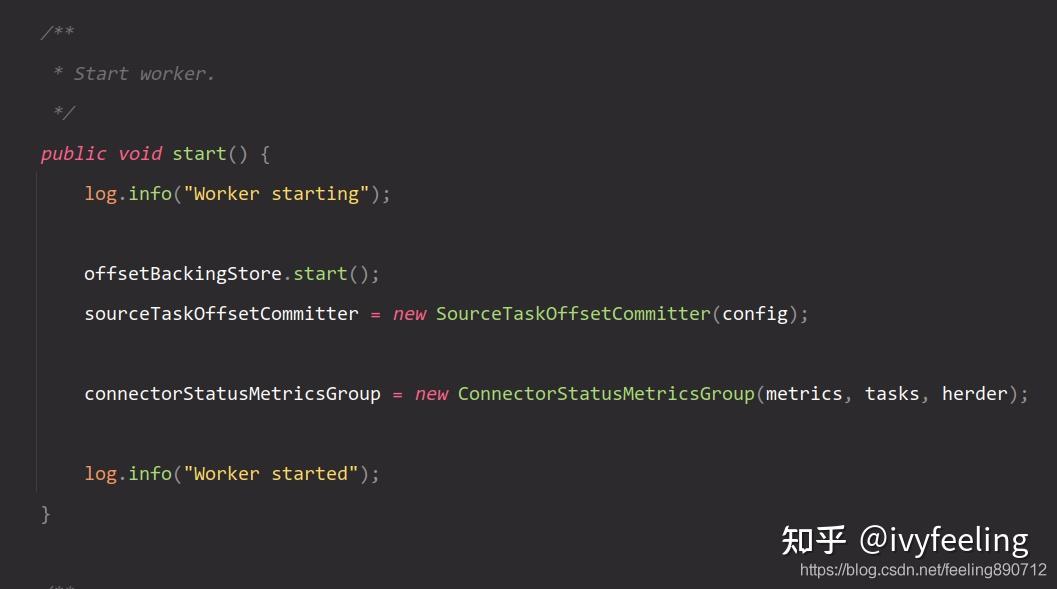
在Kafka Connect启动流程中,创建了Worker实例后会调用
start
方法,启动Worker。Worker的
start
方法实现如下:
Worker的
start
方法比较简单,主要是启动
offsetBackingStorage
。
offsetBackingStorage
可用于Source Connector的任务,保存已经产生的offset信息。这样给需要保存已经产生的消息的信息的Source Connector提供了一个统一的机制,无需Source Connector另外设计一套。
offsetBackingStorage
信息的持久化都是依赖Kafka的topic,与Consumer的offset保存原理一样。
Worker运行Connector
一般当我们希望向Kafka Connect提交新的Connector时候都会调用如下REST接口例子:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" 192.168.39.213:8083/connectors -d '{
"name": "project-connector",
"config": {
"tasks.max": "1",
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "127.0.0.1",
"database.port": "3306",
"database.user": "root",
"database.password": "123456",
"database.server.id": "100",
"database.server.name": "myServerName",
"database.include.list": "myDatabase",
"table.whitlelist" : "project,member",
"database.history.kafka.bootstrap.servers": "127.0.0.1:9092",
"database.history.kafka.topic": "debezium-mysql",
"include.schema.changes": "true"
}'
当Kafka Connect组的Leader收到这个Connector配置后,会保存到Config的topic中。这组Kafka Connect就开始新的Rebalance过程,当Rebalance结束后,这个Connector就会被分配给其中一个Kafka Connect运行。 Kafka Connect运行Connector时都会调用
Worker.startConnector
方法:
public void startConnector(
String connName,
Map<String, String> connProps,
CloseableConnectorContext ctx,
ConnectorStatus.Listener statusListener,
TargetState initialState,
Callback<TargetState> onConnectorStateChange
try (LoggingContext loggingContext = LoggingContext.forConnector(connName)) {
. . . . . . .
final WorkerConnector workerConnector;
ClassLoader savedLoader = plugins.currentThreadLoader();
try {
// 根据配置中Connector class类,从插件classLoader加载这个类
final String connClass = connProps.get(ConnectorConfig.CONNECTOR_CLASS_CONFIG);
ClassLoader connectorLoader = plugins.delegatingLoader().connectorLoader(connClass);
savedLoader = Plugins.compareAndSwapLoaders(connectorLoader);
log.info("Creating connector {} of type {}",
connName, connClass);
// 创建该Connector类实例
final Connector connector = plugins.newConnector(connClass);
// 根据Connector类型不同创建不同的ConnectorConfig配置类
final ConnectorConfig connConfig = ConnectUtils.isSinkConnector(connector)
? new SinkConnectorConfig(plugins, connProps)
: new SourceConnectorConfig(plugins, connProps, config.topicCreationEnable());
final OffsetStorageReader offsetReader = new OffsetStorageReaderImpl(
offsetBackingStore, connName, internalKeyConverter, internalValueConverter);
// 创建WorkerConnector类,其中封装了Connector
// WorkerConnector是实现Runnable接口
workerConnector = new WorkerConnector(
connName, connector, connConfig, ctx, metrics, statusListener, offsetReader, connectorLoader);
log.info("Instantiated connector {} with version {} of type {}", connName, connector.version(), connector.getClass());
workerConnector.transitionTo(initialState, onConnectorStateChange);
Plugins.compareAndSwapLoaders(savedLoader);
} catch (Throwable t) {
. . . . . . .
return;
. . . . . .
executor.submit(workerConnector);
log.info("Finished creating connector {}", connName);
workerMetricsGroup.recordConnectorStartupSuccess();
}
从上面的代码片段可知,
startConnector
的主要工作是将Connector实例和配置都封装到
WorkerConnector
类中。
WorkerConnector
实现了Runnable接口,可以提交到线程池中运行。 下图是
WorkerConnector
run方法在启动时的大致过程,run方法会调用doRun方法进行实际的工作。
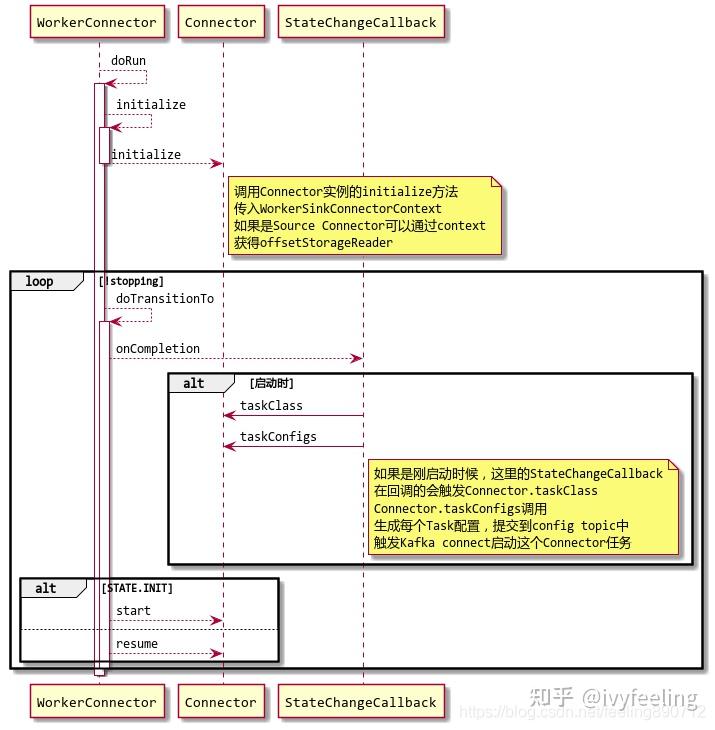
通过上面的时序图可知,Connector启动过程是调用Connector的几个接口,调用顺序为:
initialize
-->
taskClasss
-->
taskConfigs
-->
start
。 从taskClasss,taskConfigs两个方法的调用是Connector最主要的工作。由于Connector不是做实际的数据读写工作的,而这些工作是交由Conenctor对应的Task来处理的。那么Connector的主要工作就是创建对应的Task的配置,当Connector生成了Task的配置并且这些配置被放入Config的topic中后,会触发Kafka Connect新一轮的Rebalance,新的Rebalance结束后,这些Task也被分配到对应的Kafka Connect上面运行了,这个过程跟分配Connector是一样的。
Worker运行Task
下面是Worker的
startTask
方法实现片段:
public boolean startTask(
ConnectorTaskId id,
ClusterConfigState configState,
Map<String, String> connProps,
Map<String, String> taskProps,
TaskStatus.Listener statusListener,
TargetState initialState
final WorkerTask workerTask;
try (LoggingContext loggingContext = LoggingContext.forTask(id)) {
. . . . . .
ClassLoader savedLoader = plugins.currentThreadLoader();
try {
// 加载Task的class类,并且创建实例
String connType = connProps.get(ConnectorConfig.CONNECTOR_CLASS_CONFIG);
ClassLoader connectorLoader = plugins.delegatingLoader().connectorLoader(connType);
savedLoader = Plugins.compareAndSwapLoaders(connectorLoader);
final ConnectorConfig connConfig = new ConnectorConfig(plugins, connProps);
final TaskConfig taskConfig = new TaskConfig(taskProps);
final Class<? extends Task> taskClass = taskConfig.getClass(TaskConfig.TASK_CLASS_CONFIG).asSubclass(Task.class);
final Task task = plugins.newTask(taskClass);
log.info("Instantiated task {} with version {} of type {}", id, task.version(), taskClass.getName());
Converter keyConverter = plugins.newConverter(connConfig, WorkerConfig.KEY_CONVERTER_CLASS_CONFIG, ClassLoaderUsage
.CURRENT_CLASSLOADER);
Converter valueConverter = plugins.newConverter(connConfig, WorkerConfig.VALUE_CONVERTER_CLASS_CONFIG, ClassLoaderUsage.CURRENT_CLASSLOADER);
HeaderConverter headerConverter = plugins.newHeaderConverter(connConfig, WorkerConfig.HEADER_CONVERTER_CLASS_CONFIG,
ClassLoaderUsage.CURRENT_CLASSLOADER);
. . . . . . .
// 构造WokerTask实例,封装Task实例和配置信息等
workerTask = buildWorkerTask(configState, connConfig, id, task, statusListener, initialState, keyConverter, valueConverter,
headerConverter, connectorLoader);
workerTask.initialize(taskConfig);
Plugins.compareAndSwapLoaders(savedLoader);
} catch (Throwable t) {
. . . . . .
return false;
WorkerTask existing = tasks.putIfAbsent(id, workerTask);
if (existing != null)
throw new ConnectException("Task already exists in this worker: " + id);
executor.submit(workerTask);
. . . . . .
return true;
}
从上面的代码可知,启动Task过程跟Connector相似。从插件的ClassLoader加载Task的class并且创建Task实例。然后创建
WorkerTask
实例,
WorkerTask
会封装Task实例,对应的KafkaProducer/KafkaConsumer和配置信息等。下面是
buildWorkerTask
方法实现片段:
private WorkerTask buildWorkerTask(ClusterConfigState configState,
ConnectorConfig connConfig,
ConnectorTaskId id,
Task task,
TaskStatus.Listener statusListener,
TargetState initialState,
Converter keyConverter,
Converter valueConverter,
HeaderConverter headerConverter,
ClassLoader loader) {
ErrorHandlingMetrics errorHandlingMetrics = errorHandlingMetrics(id);
final Class<? extends Connector> connectorClass = plugins.connectorClass(
connConfig.getString(ConnectorConfig.CONNECTOR_CLASS_CONFIG));
RetryWithToleranceOperator retryWithToleranceOperator = new RetryWithToleranceOperator(connConfig.errorRetryTimeout(),
connConfig.errorMaxDelayInMillis(), connConfig.errorToleranceType(), Time.SYSTEM);
retryWithToleranceOperator.metrics(errorHandlingMetrics);
// 判断Task类型是Source还是Sink
if (task instanceof SourceTask) {
SourceConnectorConfig sourceConfig = new SourceConnectorConfig(plugins,
connConfig.originalsStrings(), config.topicCreationEnable());
retryWithToleranceOperator.reporters(sourceTaskReporters(id, sourceConfig, errorHandlingMetrics));
// 如果配有Transformer,这里构造Transformer链,用于发送前转换消息
TransformationChain<SourceRecord> transformationChain = new TransformationChain<>(sourceConfig.<SourceRecord>transformations(), retryWithToleranceOperator);
. . . . . . .
Map<String, Object> producerProps = producerConfigs(id, "connector-producer-" + id, config, sourceConfig, connectorClass,
connectorClientConfigOverridePolicy, kafkaClusterId);
// 如果是SourceTask就要创建对应的KafkaProducer,用于向Kafka topic发送数据
KafkaProducer<byte[], byte[]> producer = new KafkaProducer<>(producerProps);
. . . . . . .
// Note we pass the configState as it performs dynamic transformations under the covers
return new WorkerSourceTask(id, (SourceTask) task, statusListener, initialState, keyConverter, valueConverter,
headerConverter, transformationChain, producer, admin, topicCreationGroups,
offsetReader, offsetWriter, config, configState, metrics, loader, time, retryWithToleranceOperator, herder.statusBackingStore(), executor);
} else if (task instanceof SinkTask) {
// 如果配有Transformer,这里构造Transformer链,用于收到消息后发送给SinkTask处理前进行消息转换
TransformationChain<SinkRecord> transformationChain = new TransformationChain<>(connConfig.<SinkRecord>transformations(), retryWithToleranceOperator);
SinkConnectorConfig sinkConfig = new SinkConnectorConfig(plugins, connConfig.originalsStrings());
retryWithToleranceOperator.reporters(sinkTaskReporters(id, sinkConfig, errorHandlingMetrics, connectorClass));
WorkerErrantRecordReporter workerErrantRecordReporter = createWorkerErrantRecordReporter(sinkConfig, retryWithToleranceOperator,
keyConverter, valueConverter, headerConverter);
Map<String, Object> consumerProps = consumerConfigs(id, config, connConfig, connectorClass, connectorClientConfigOverridePolicy, kafkaClusterId);
// 如果是SinkTask,创建对应的KafkaConsumer,同一组的Task的Consumer group id由生成Connector名字组成
KafkaConsumer<byte[], byte[]> consumer = new KafkaConsumer<>(consumerProps);