爱可可AI前沿推介(2.14)


LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
摘要:基于几何深度学习的药物结合结构预测、基于黎曼分数的生成模型、哈密尔顿神经网络归纳偏差解构、基于注意力的人脸编辑、表面离散化无关学习、社交互动对新内容发现过程的影响、深度学习药物对评分库、基于大规模并行的机器人质量-多样性算法加速、优化与机器学习工具包
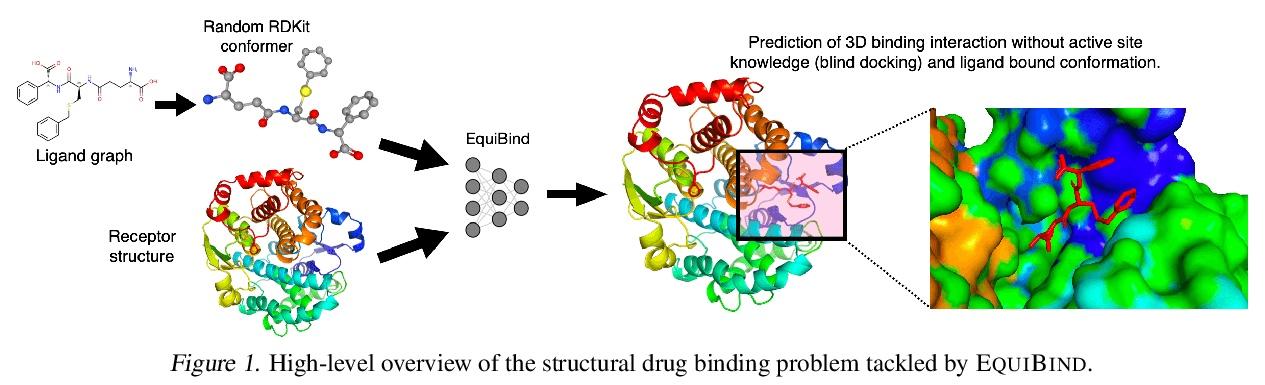
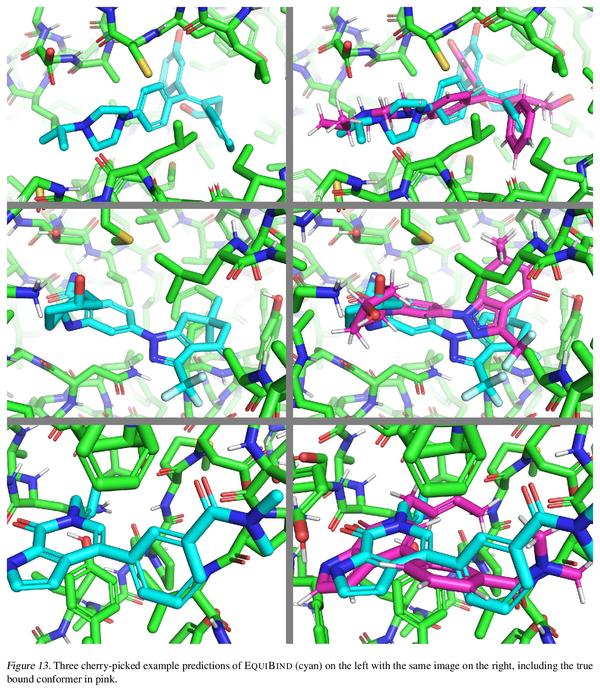
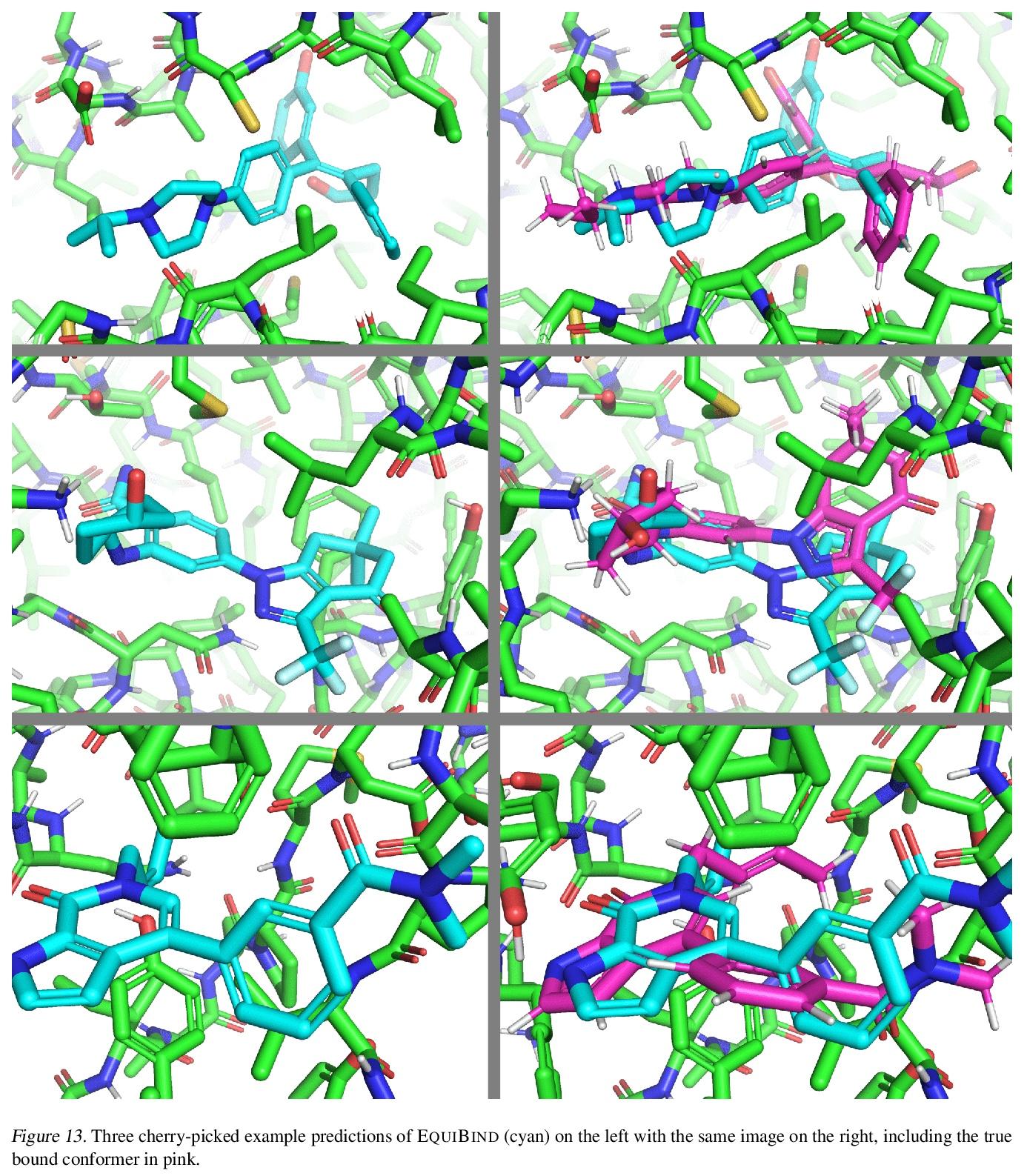
1、[LG] EquiBind: Geometric Deep Learning for Drug Binding Structure Prediction
H Stärk, O Ganea, L Pattanaik, R Barzilay, T Jaakkola
[Technical University of Munich & MIT]
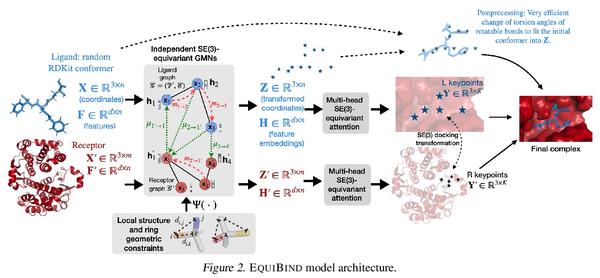
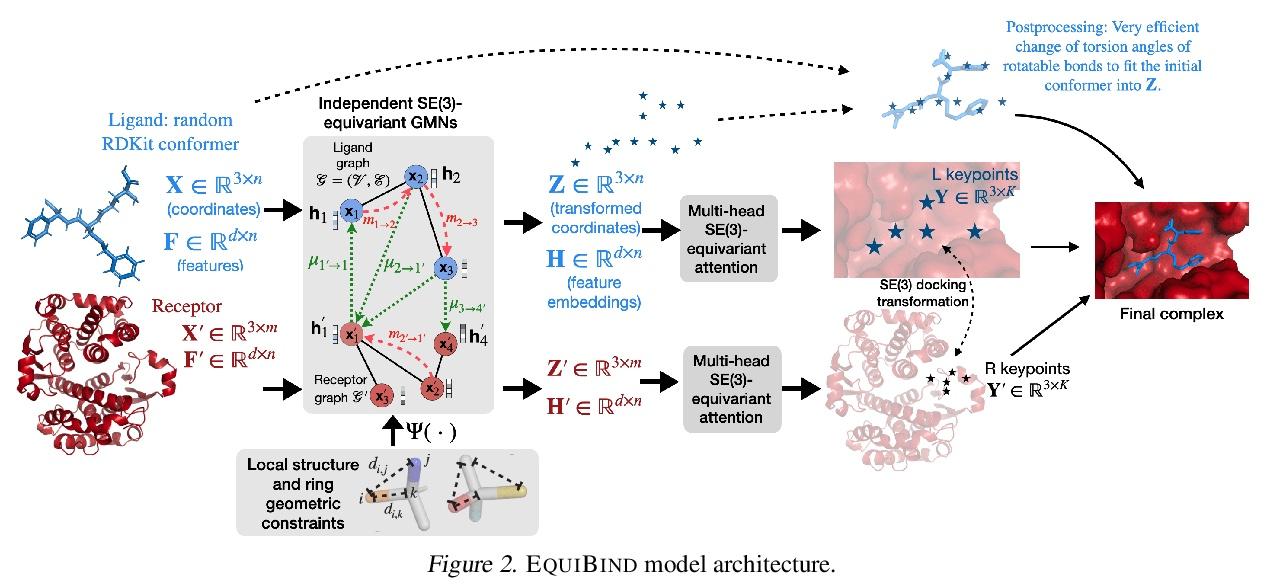
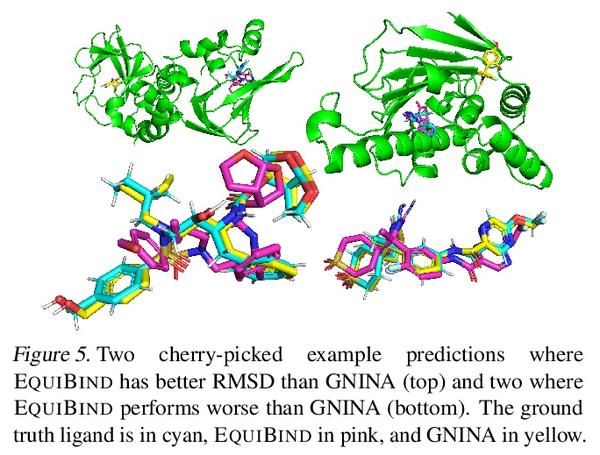
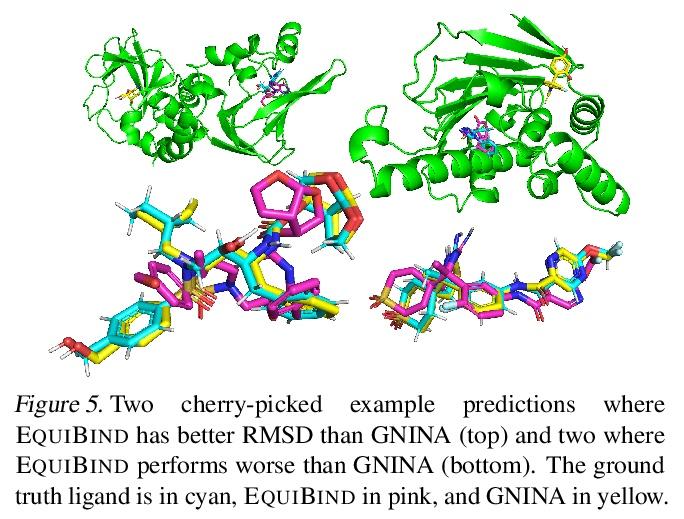
EquiBind:基于几何深度学习的药物结合结构预测。预测类药物分子如何与特定蛋白质靶点结合,是药物发现的一个核心问题。一种极快的计算结合方法,将使快速虚拟筛选或药物工程等关键应用成为可能。现有方法在计算上是昂贵的,依赖于大量的候选样本,再加上评分、排序和微调等步骤。本文用EquiBind挑战这种模式,一种SE(3)等变几何深度学习模型,对 i)受体结合位置(盲对接) 和 ii)配体结合姿态方向进行direct-shot预测。与传统的和最近的基线相比,EquiBind实现了显著的速度提升和更好的质量。此外,当它与现有的微调技术结合时,显示出额外的改进,但代价是运行时间的增加。提出了一种新的快速微调模型,基于von Mises角距离与给定输入原子点云的全局最小值调整配体可旋转键的扭角,避免了之前昂贵的能量最小化的差分进化策略。
Predicting how a drug-like molecule binds to a specific protein target is a core problem in drug discovery. An extremely fast computational binding method would enable key applications such as fast virtual screening or drug engineering. Existing methods are computationally expensive as they rely on heavy candidate sampling coupled with scoring, ranking, and fine-tuning steps. We challenge this paradigm with EQUIBIND, an SE(3)-equivariant geometric deep learning model performing direct-shot prediction of both i) the receptor binding location (blind docking) and ii) the ligand’s bound pose and orientation. EquiBind achieves significant speed-ups and better quality compared to traditional and recent baselines. Further, we show extra improvements when coupling it with existing fine-tuning techniques at the cost of increased running time. Finally, we propose a novel and fast fine-tuning model that adjusts torsion angles of a ligand’s rotatable bonds based on closed-form global minima of the von Mises angular distance to a given input atomic point cloud, avoiding previous expensive differential evolution strategies for energy minimization.
https:// weibo.com/1402400261/Lf nfA6xUV


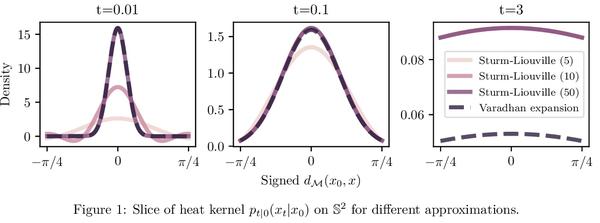
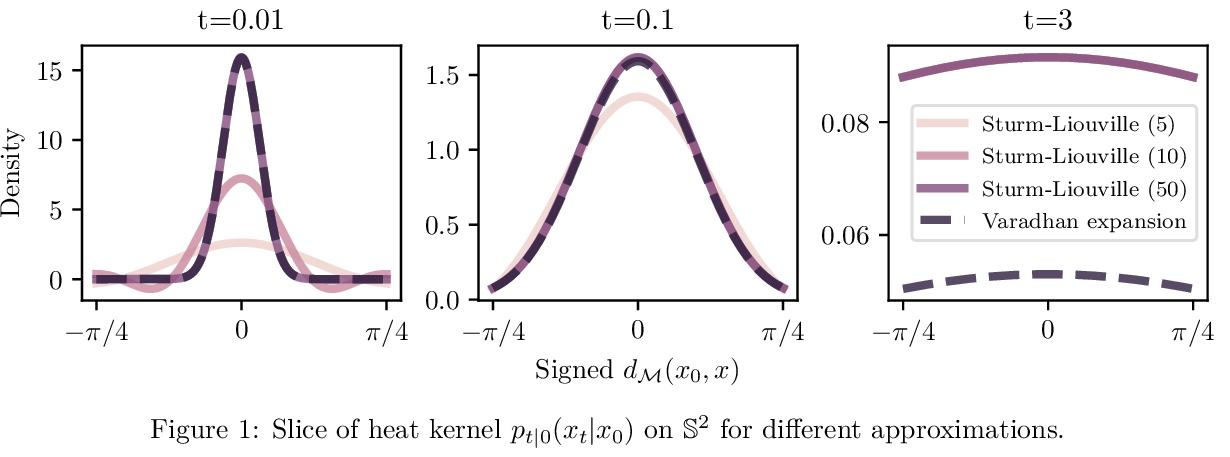
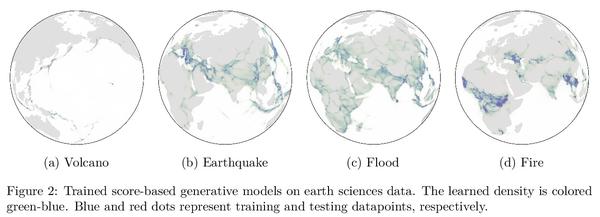
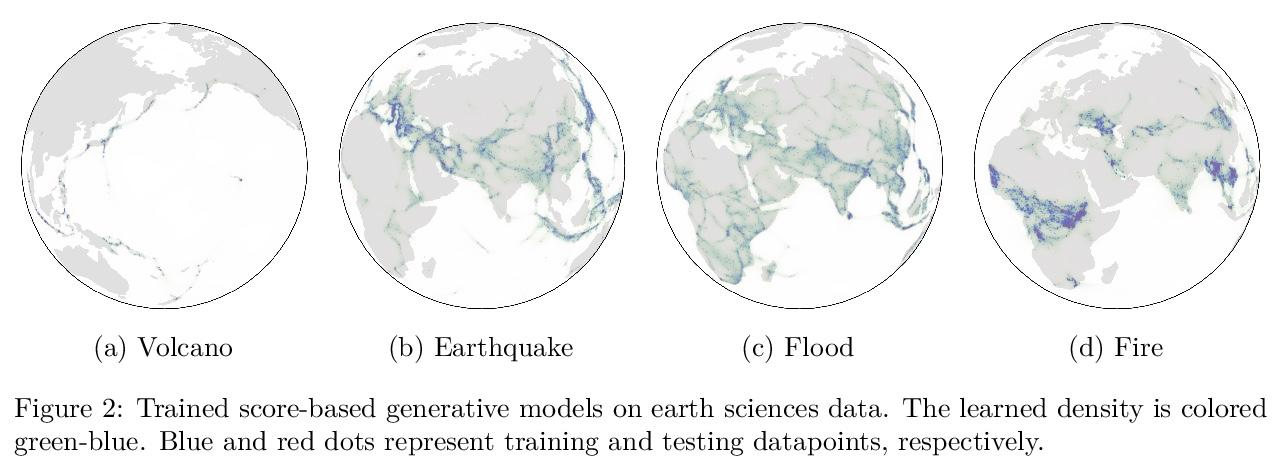
2、[LG] Riemannian Score-Based Generative Modeling
V D Bortoli, E Mathieu, M Hutchinson, J Thornton, Y W Teh, A Doucet
[University of Oxford]
基于黎曼分数的生成模型。基于分数的生成模型(SGM)是一类新的生成模型,展示了显著的经验性能。用扩散来逐渐向数据添加高斯噪声,而生成模型是一个"去噪"过程,通过近似这种"噪声"扩散的时间反演来获得。然而,目前SGM的基本假设是,数据被支持在一个具有平面几何的欧几里得流形上。这阻碍了这些模型在机器人、地球科学或蛋白质建模中的应用,这些应用依赖于在黎曼流形上定义的分布。为克服这个问题,本文提出基于黎曼分数的生成模型(RSGM),将目前的SGM扩展到紧凑黎曼流形环境中,其主要优点在于它对高维的可扩展性,由于可用损失函数的多样性,适用于一类广泛的流形,以及它对复杂数据集的建模能力。用地球和气候科学数据来说明该方法,并说明RSGM如何通过解决流形上的薛定谔桥问题来加速。
Score-based generative models (SGMs) are a novel class of generative models demonstrating remarkable empirical performance. One uses a diffusion to add gradually Gaussian noise to the data, while the generative model is a “denoising” process obtained by approximating the time-reversal of this “noising” diffusion. However, current SGMs make the underlying assumption that the data is supported on a Euclidean manifold with flat geometry. This prevents the use of these models for applications in robotics, geoscience or protein modeling which rely on distributions defined on Riemannian manifolds. To overcome this issue, we introduce Riemannian Score-based Generative Models (RSGMs) which extend current SGMs to the setting of compact Riemannian manifolds. We illustrate our approach with earth and climate science data and show how RSGMs can be accelerated by solving a Schrödinger bridge problem on manifolds. Keywords— Diffusion processes, Generative modeling, Riemannian manifold, Score-based generative models, Schrödinger bridge
https:// weibo.com/1402400261/Lf nlXwT0X


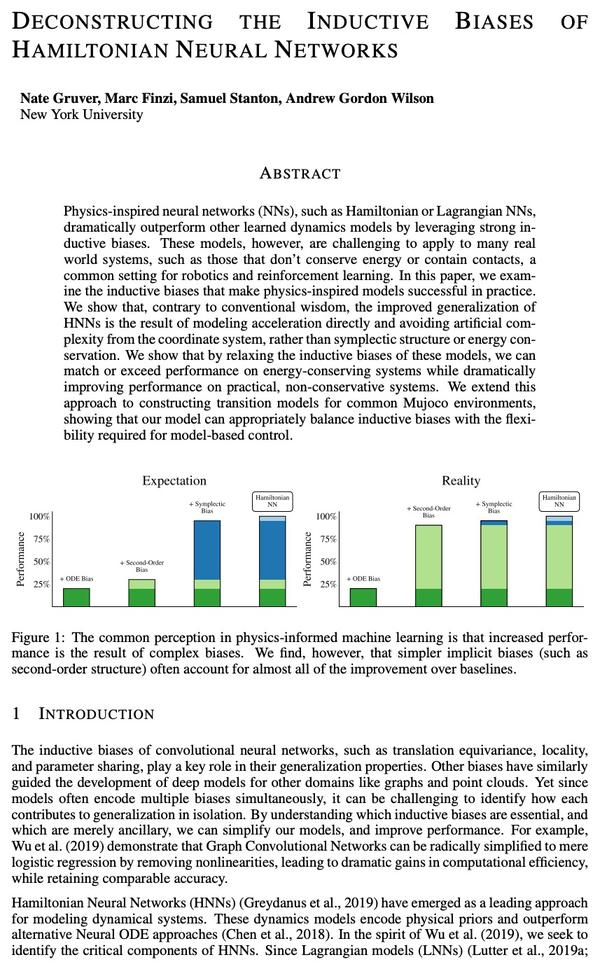
3、[LG] Deconstructing The Inductive Biases Of Hamiltonian Neural Networks
N Gruver, M Finzi, S Stanton, A G Wilson
[New York University]
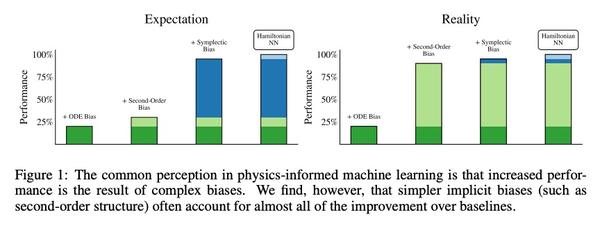
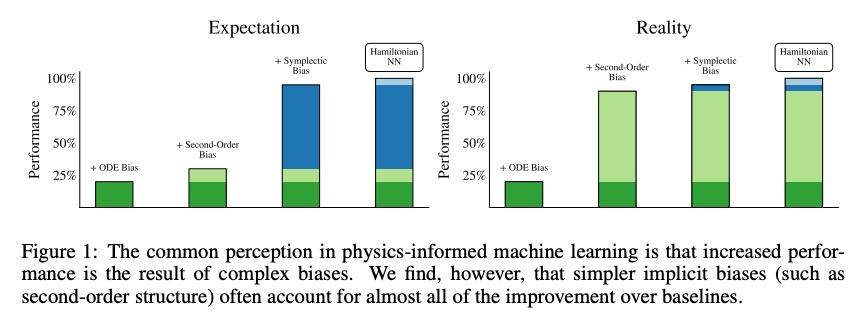
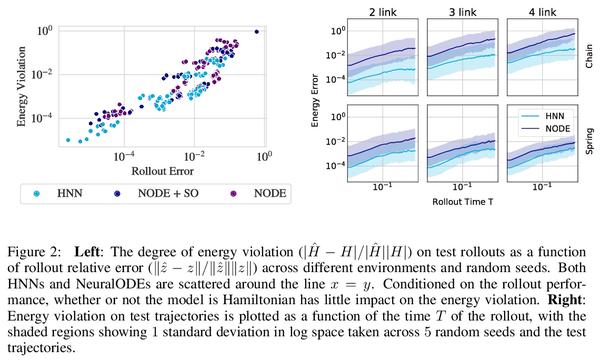
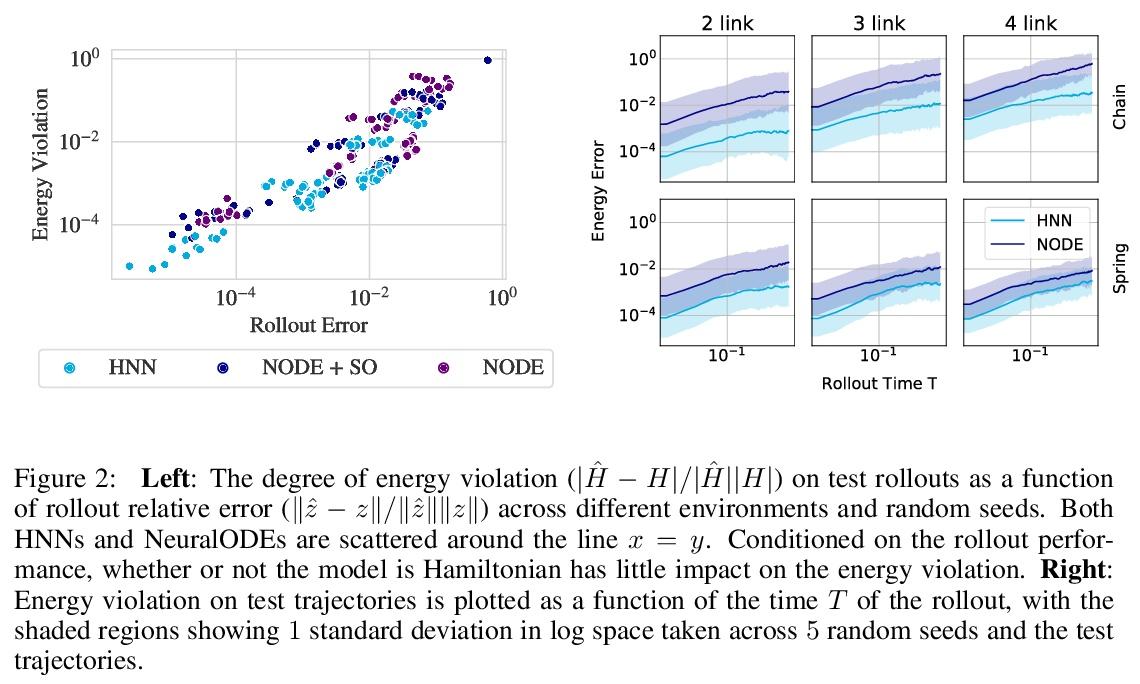
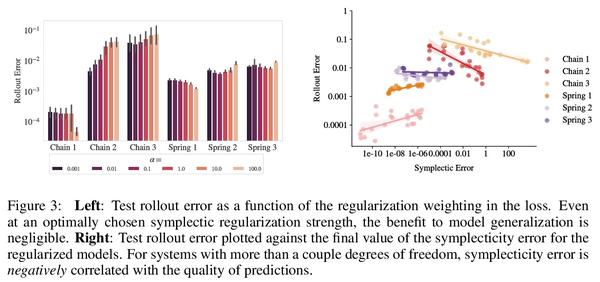
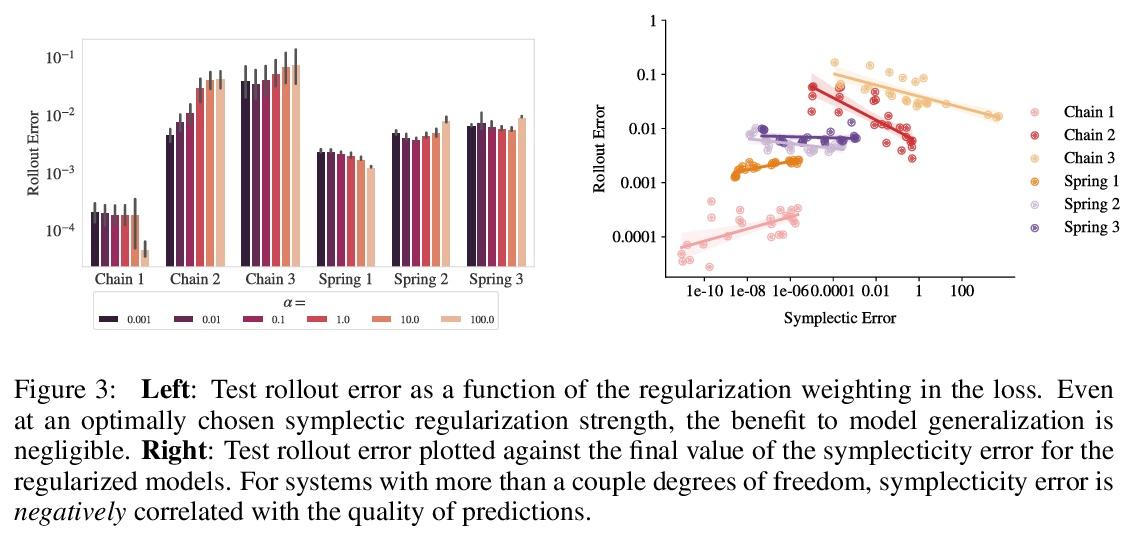
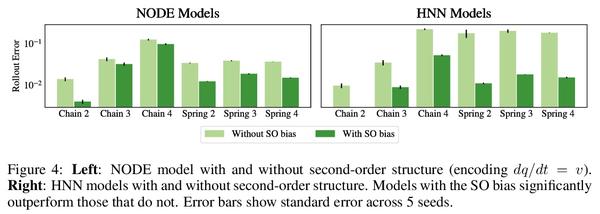
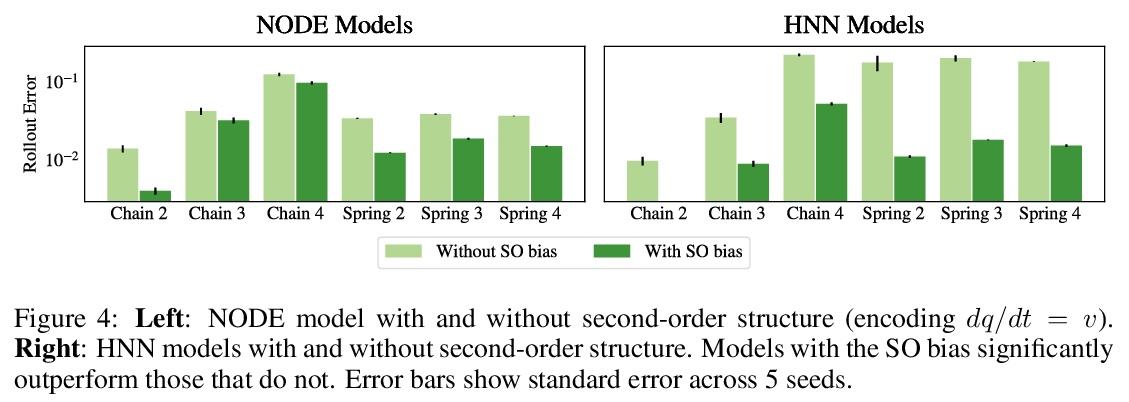
哈密尔顿神经网络归纳偏差解构。受物理学启发的神经网络,如哈密尔顿或拉格朗日神经网络,利用强大的归纳偏差,极大超越了其他习得动力学模型。然而,这些模型在应用于许多现实世界系统时具有挑战性,例如那些不保存能量或包含接触的系统,而这是机器人和强化学习的常见设置。本文研究了使物理学启发模型在实践中取得成功的归纳偏差。将高性能的HNN模型的归纳偏差解构为其组成部分,即NeuralODE、交感性、习得能量函数守恒和二阶结构。与传统观点相反,HNN的泛化改进来自于系统可以被表达为单一的二阶微分方程的假设,避免了来自坐标系的人为复杂性,而不是共轭结构或能量守恒。剥去HNN的其他组成部分,剩下的是一个更简单、计算效率更高的模型,而且限制更小,可直接应用于非Hamilton系统。通过放松这些模型的归纳偏差,可匹配或超越能量守恒系统上的性能,同时极大提高实际的非守恒系统的性能。将这种方法扩展到为常见的Mujoco环境构建过渡模型,表明该模型可适当地平衡归纳偏差和基于模型的控制所需的灵活性。应用所得到的模型为具有挑战性的Mujoco运动环境构建过渡模型,取得了可喜的成绩。
Physics-inspired neural networks (NNs), such as Hamiltonian or Lagrangian NNs, dramatically outperform other learned dynamics models by leveraging strong inductive biases. These models, however, are challenging to apply to many real world systems, such as those that don’t conserve energy or contain contacts, a common setting for robotics and reinforcement learning. In this paper, we examine the inductive biases that make physics-inspired models successful in practice. We show that, contrary to conventional wisdom, the improved generalization of HNNs is the result of modeling acceleration directly and avoiding artificial complexity from the coordinate system, rather than symplectic structure or energy conservation. We show that by relaxing the inductive biases of these models, we can match or exceed performance on energy-conserving systems while dramatically improving performance on practical, non-conservative systems. We extend this approach to constructing transition models for common Mujoco environments, showing that our model can appropriately balance inductive biases with the flexibility required for model-based control.
https:// weibo.com/1402400261/Lf npAp6Sm
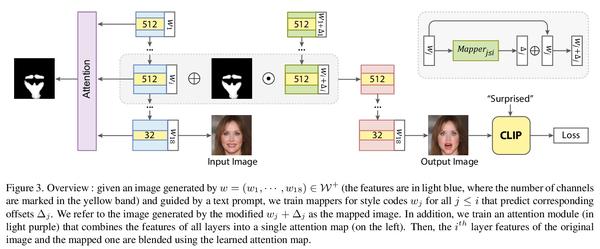
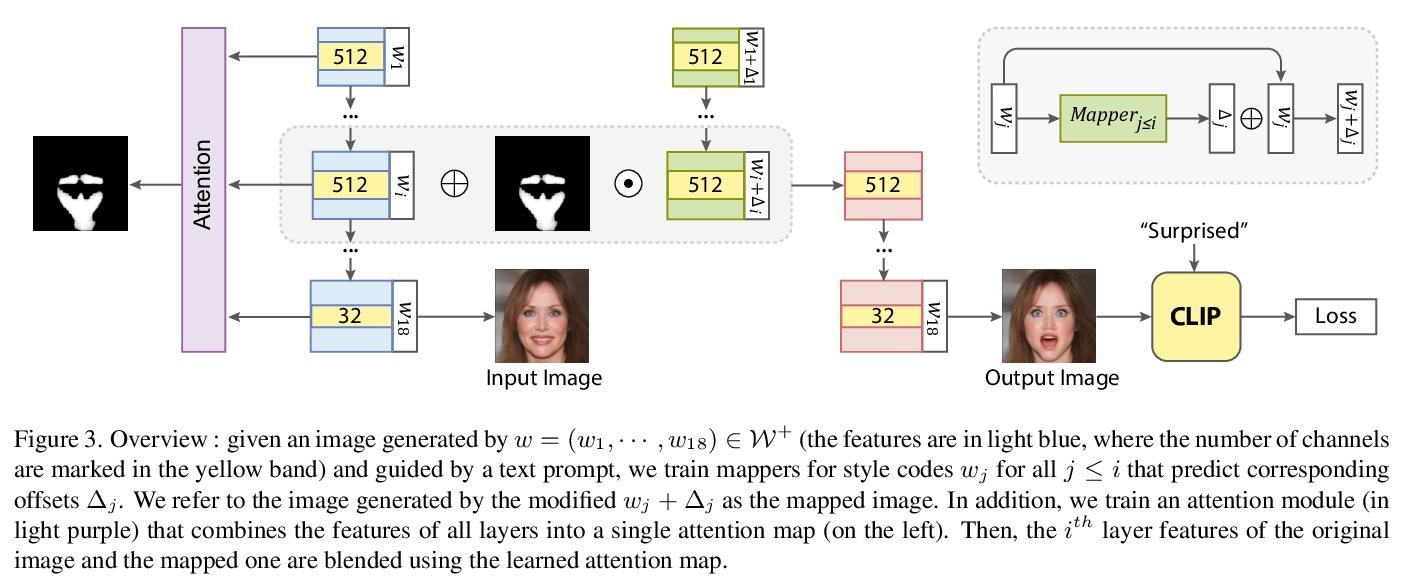
4、[CV] FEAT: Face Editing with Attention
X Hou, L Shen, O Patashnik, D Cohen-Or, H Huang
[Shenzhen University & Tel Aviv University]
FEAT:基于注意力的人脸编辑。利用预训练生成器潜空间最近被证明是基于GAN的人脸操纵的一种有效手段。其成功在很大程度上依赖于生成器潜空间轴的自然解缠。然而,人脸操纵往往意在影响局部区域,而普通生成器往往不具备必要的空间分解性。本文在StyleGAN生成器基础上,提出一种方法,明确鼓励人脸操纵通过纳入习得注意力图而集中在预定区域。在编辑图像的生成过程中,注意力图作为掩码,指导原始特征和修改后特征间的融合。潜空间编辑的指导是通过CLIP实现的,CLIP最近已经被证明对文本驱动的编辑是有效的。本文进行了广泛的实验,表明该方法可通过只关注相关区域来进行基于文本描述的分解和可控的人脸操纵。定性和定量实验结果证明了所提出方法在人脸区域编辑方面比其他方法的优越性。
Employing the latent space of pretrained generators has recently been shown to be an effective means for GANbased face manipulation. The success of this approach heavily relies on the innate disentanglement of the latent space axes of the generator. However, face manipulation often intends to affect local regions only, while common generators do not tend to have the necessary spatial disentanglement. In this paper, we build on the StyleGAN generator, and present a method that explicitly encourages face manipulation to focus on the intended regions by incorporating learned attention maps. During the generation of the edited image, the attention map serves as a mask that guides a blending between the original features and the modified ones. The guidance for the latent space edits is achieved by employing CLIP, which has recently been shown to be effective for text-driven edits. We perform extensive experiments ∗Corresponding author and show that our method can perform disentangled and controllable face manipulations based on text descriptions by attending to the relevant regions only. Both qualitative and quantitative experimental results demonstrate the superiority of our method for facial region editing over alternative methods.
https:// weibo.com/1402400261/Lf nwt6G8m








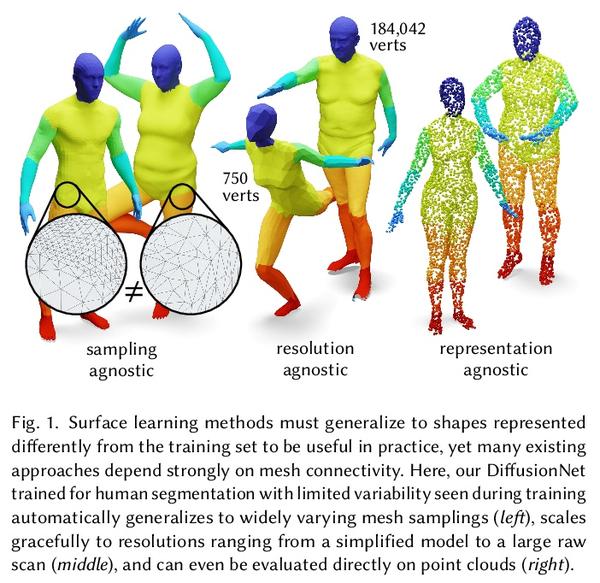
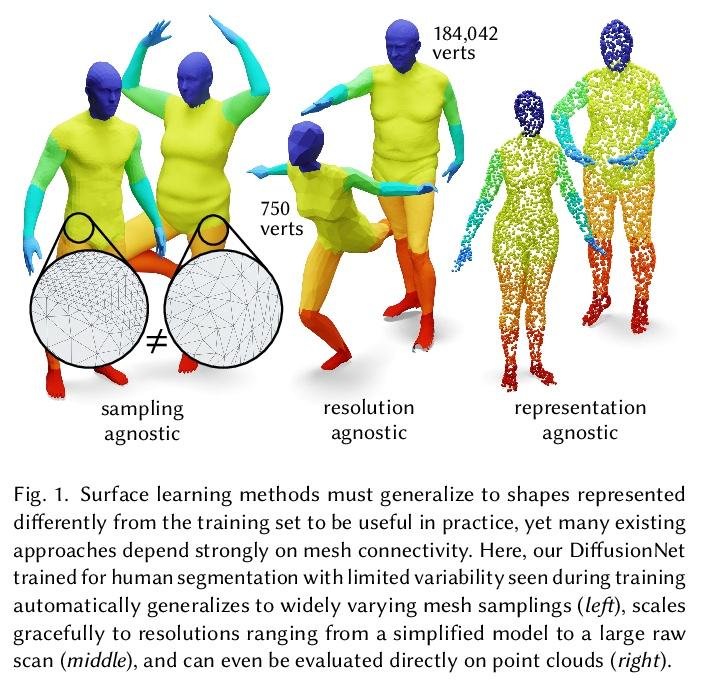
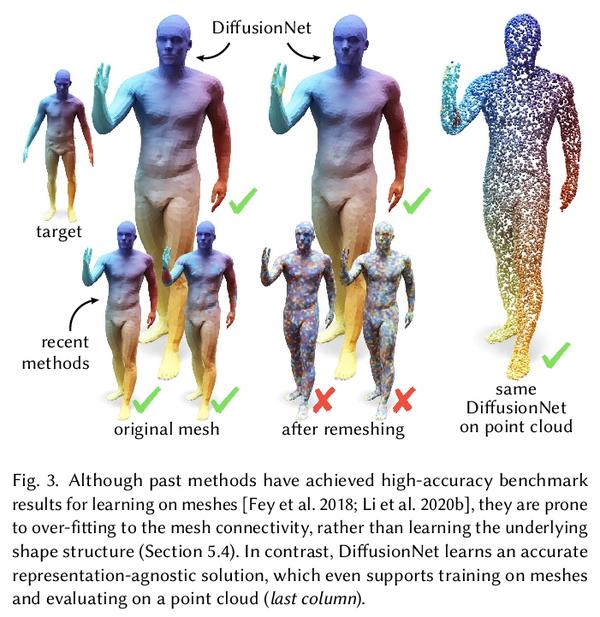
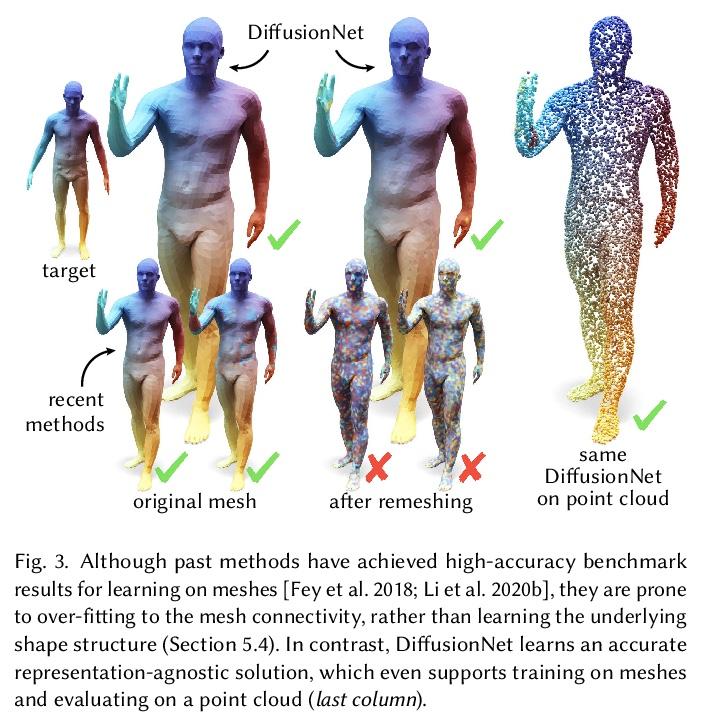
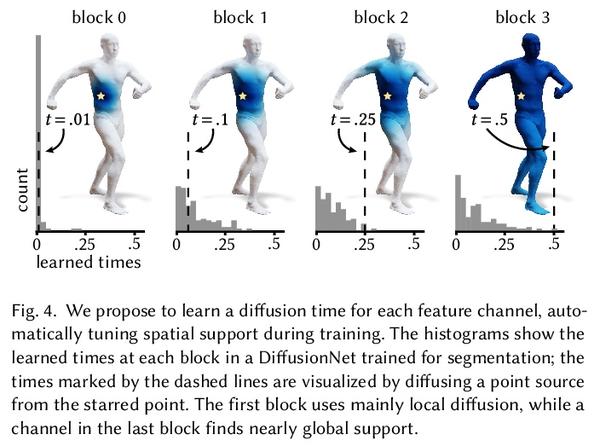
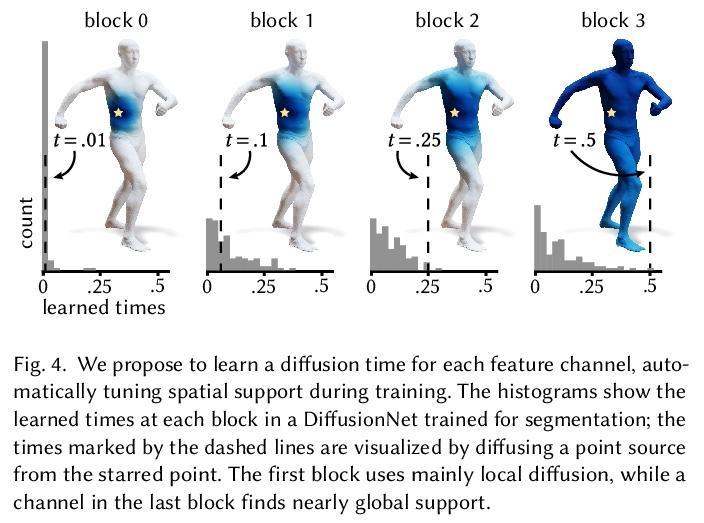
5、[CV] DiffusionNet: Discretization Agnostic Learning on Surfaces
N Sharp, S Attaiki, K Crane, M Ovsjanikov
[University of Toronto & École Polytechnique & CMU]
DiffusionNet: 表面离散化无关学习。本文提出一种新的在3D表面进行深度学习的通用方法,基于简单扩散层对空间通信非常有效的洞察,用空间梯度特征来注入方向性信息。由此产生的网络对表面分辨率和采样变化具有自动的鲁棒性——这是对实际应用至关重要的基本属性。所提出网络可在各种几何表示上离散化,如三角网格或点云,甚至可以在一种表示上训练,然后应用于另一种表示。将扩散空间支持作为一个连续的网络参数进行优化,范围从纯局部到完全全局,消除了手动选择邻域大小的负担。该方法中唯一的其他成分是在每个点独立应用的多层感知器,以及支持方向性过滤器的空间梯度特征。由此产生的网络是简单、鲁棒和高效的。在这里,主要关注三角网格表面,并展示了各种任务的最先进结果,包括表面分类、分割和非刚性对应。
We introduce a new general-purpose approach to deep learning on 3D surfaces, based on the insight that a simple diffusion layer is highly effective for spatial communication. The resulting networks are automatically robust to changes in resolution and sampling of a surface—a basic property which is crucial for practical applications. Our networks can be discretized on various geometric representations such as triangle meshes or point clouds, and can even be trained on one representation then applied to another. We optimize the spatial support of diffusion as a continuous network parameter ranging from purely local to totally global, removing the burden ofmanually choosing neighborhood sizes. The only other ingredients in the method are a multilayer perceptron applied independently at each point, and spatial gradient features to support directional filters. The resulting networks are simple, robust, and efficient. Here, we focus primarily on triangle mesh surfaces, and demonstrate state-of-the-art results for a variety of tasks including surface classification, segmentation, and non-rigid correspondence.
https:// weibo.com/1402400261/Lf nA8xMdV




另外几篇值得关注的论文:
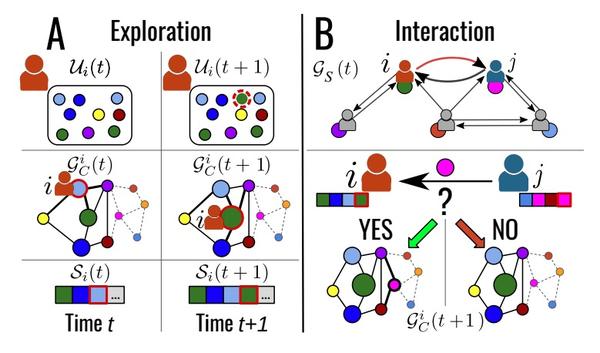
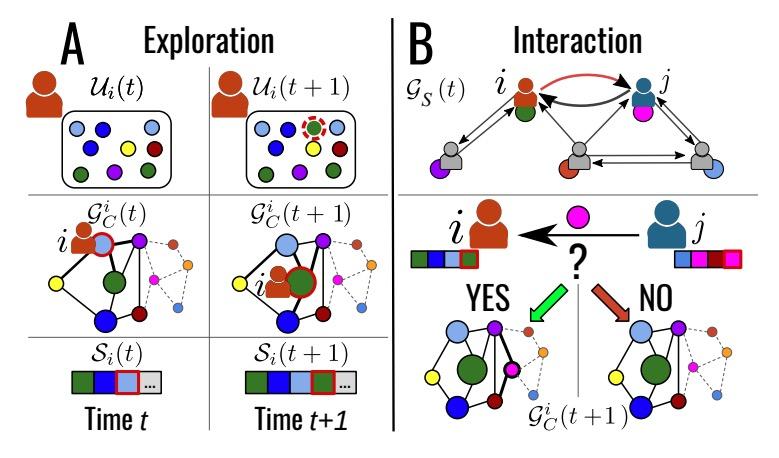
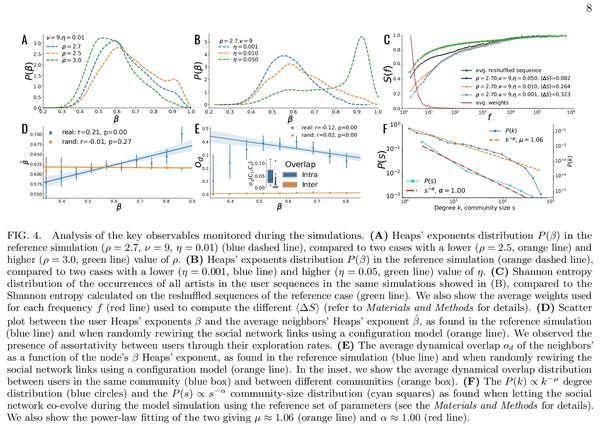
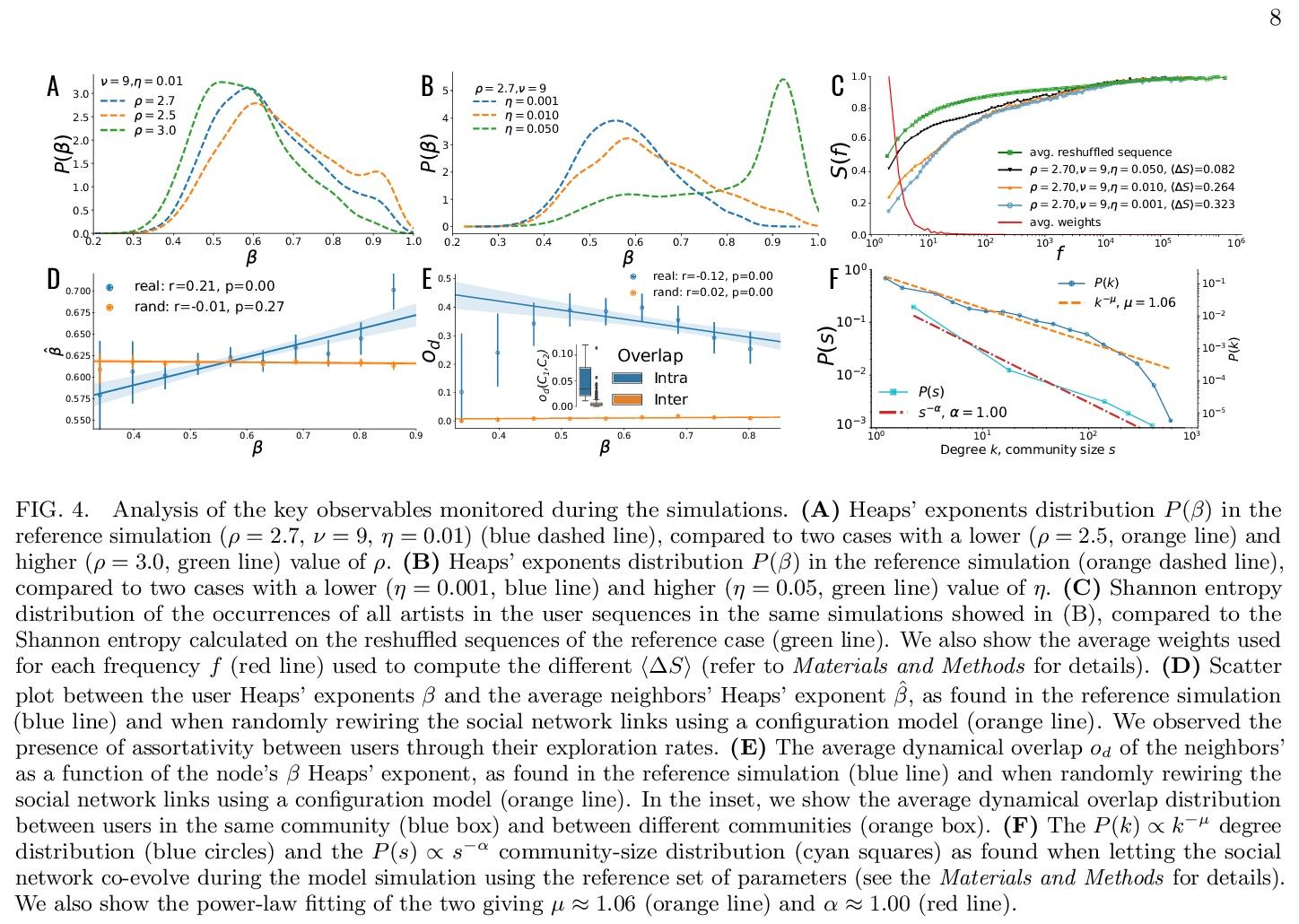
[SI] Social interactions affect discovery processes
社交互动对新内容发现过程的影响
G D Bona, E Ubaldi, I Iacopini, B Monechi, V Latora, V Loreto
[Queen Mary University of London & SONY Computer Science Laboratories & Central European University]
https:// weibo.com/1402400261/Lf nEfiX8j


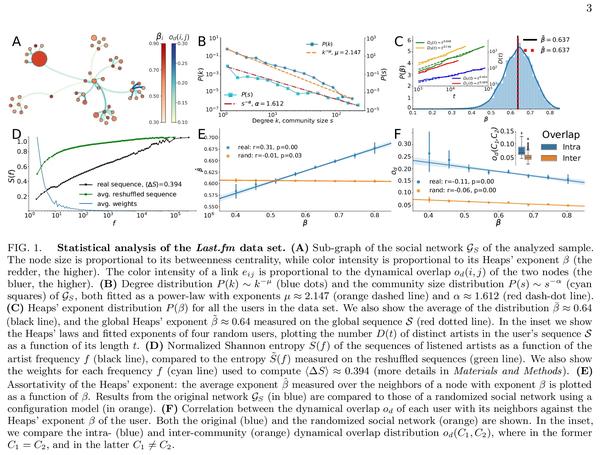
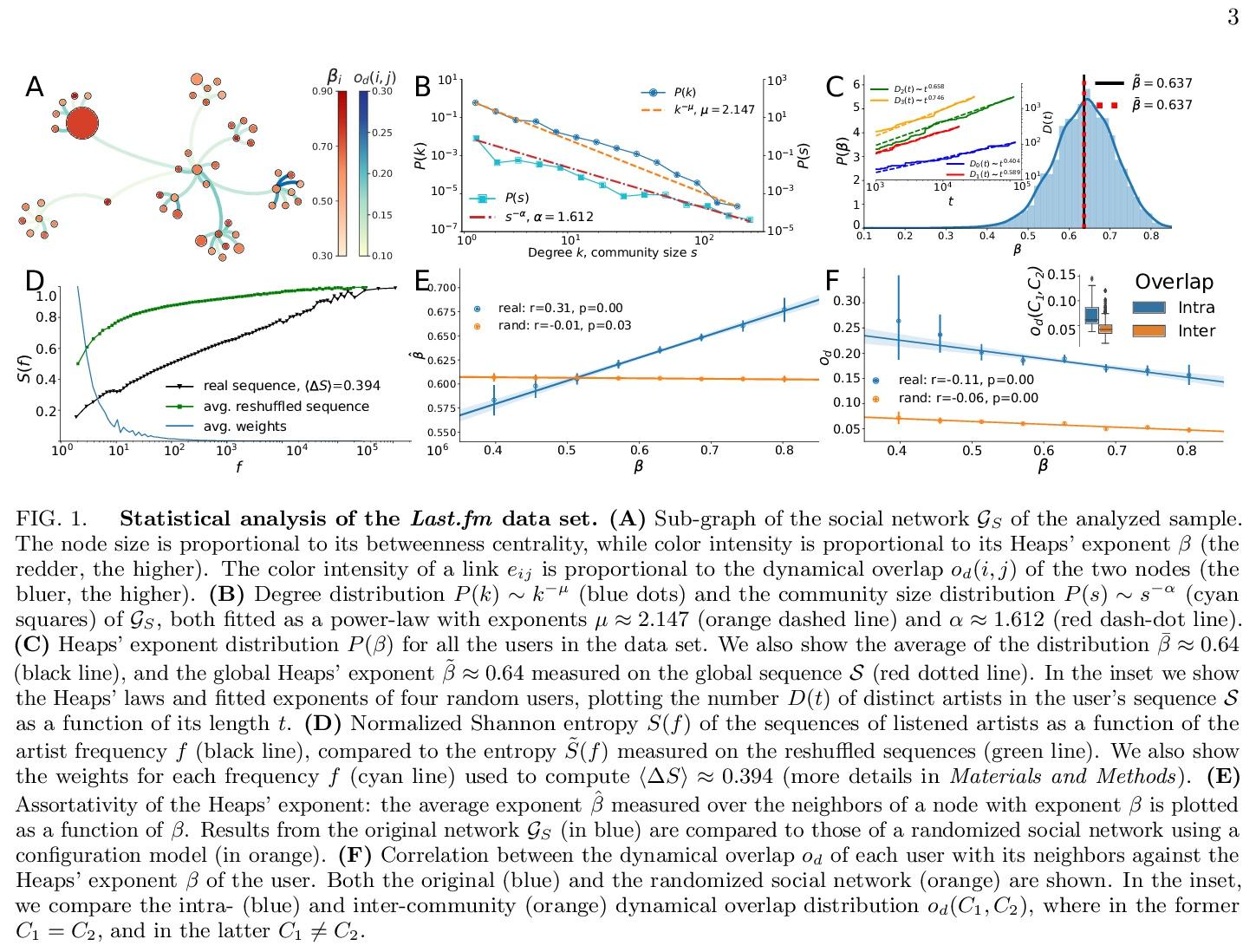
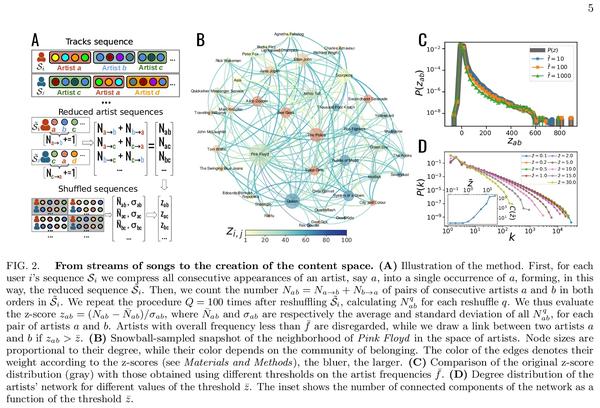
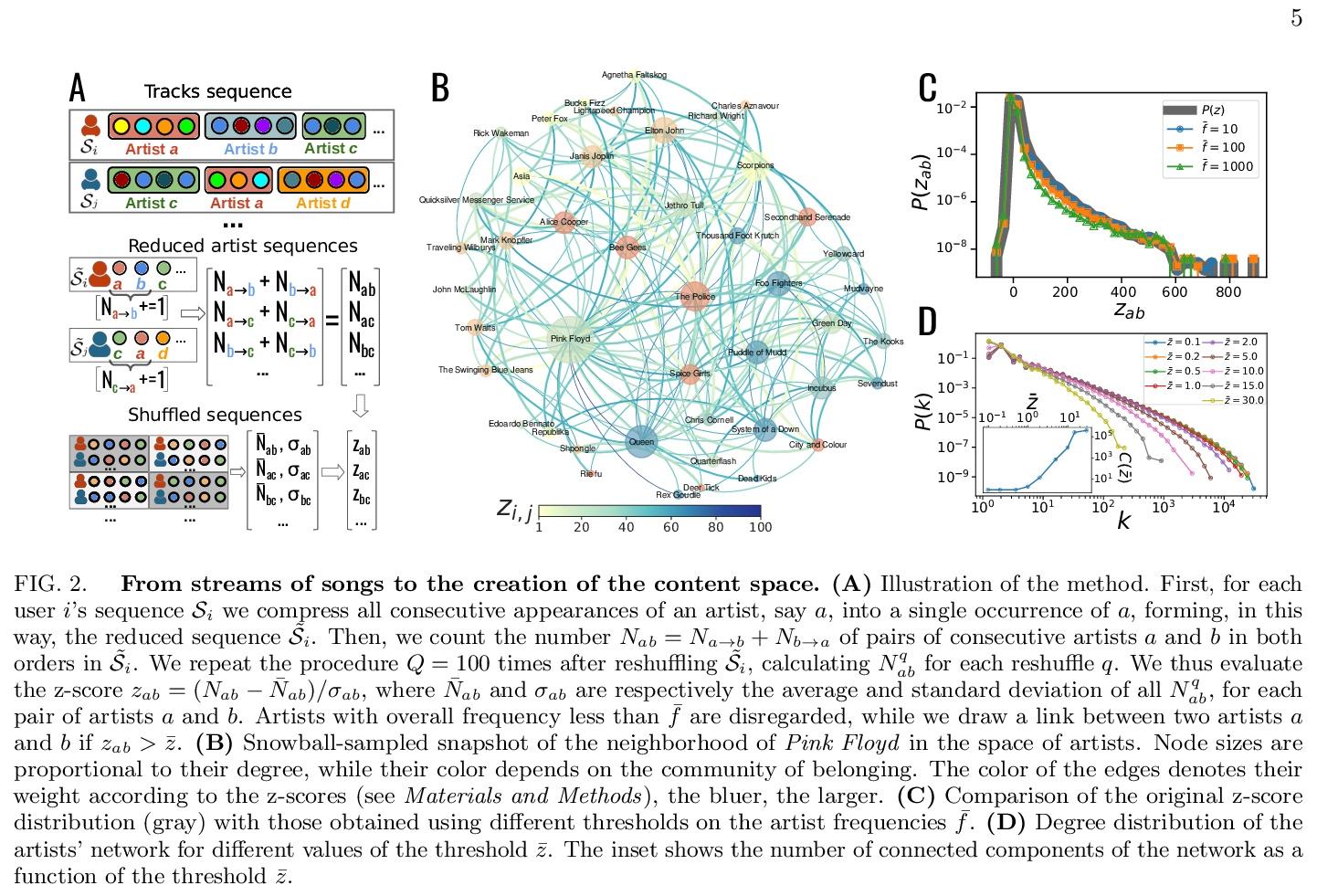
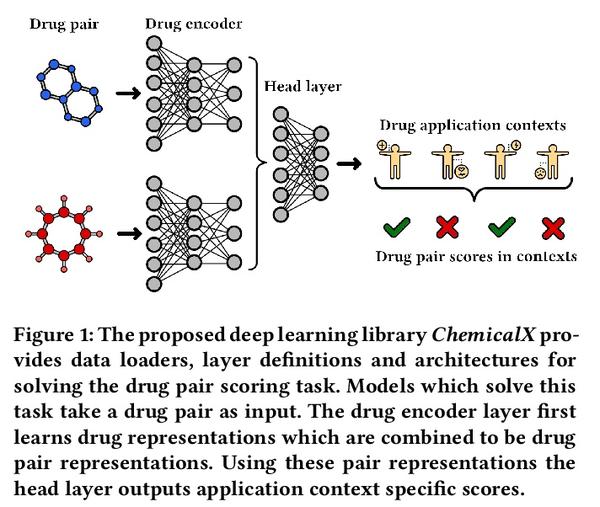
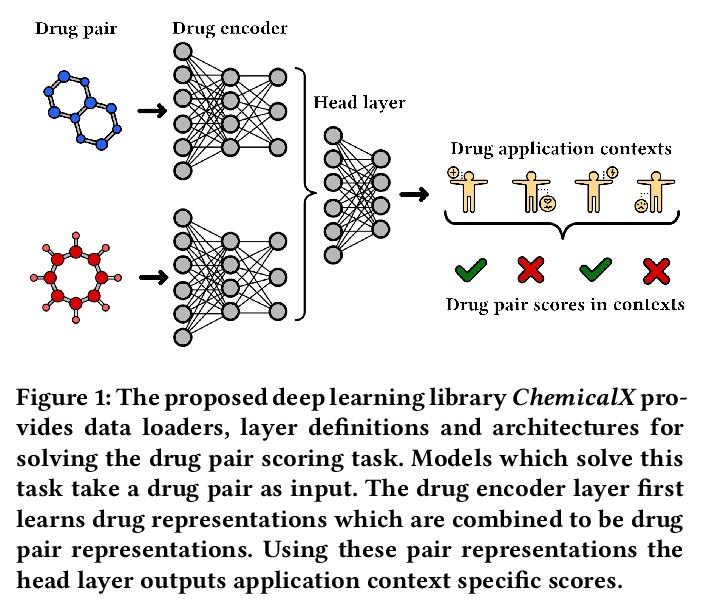
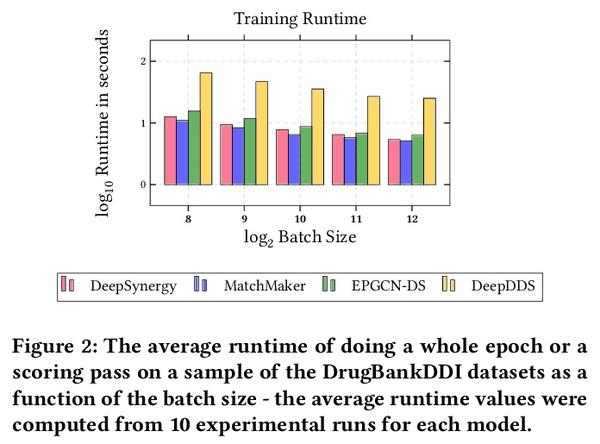
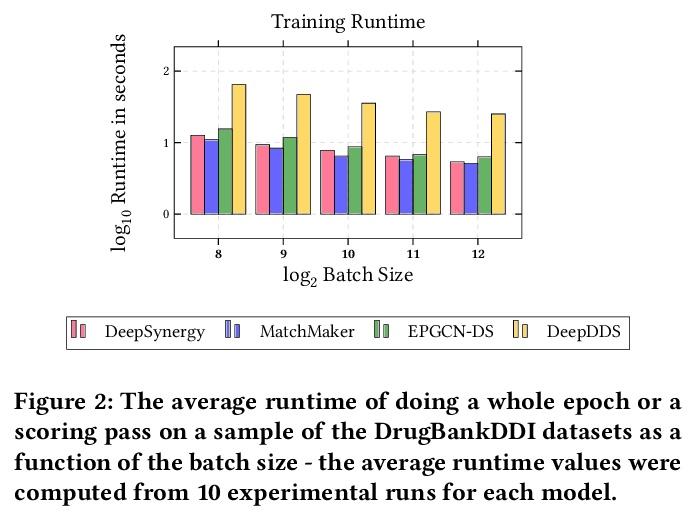
[LG] ChemicalX: A Deep Learning Library for Drug Pair Scoring
ChemicalX:深度学习药物对评分库
B Rozemberczki, C T Hoyt, A Gogleva, P Grabowski, K Karis, A Lamov, A Nikolov, S Nilsson, M Ughetto, Y Wang, T Derr, B M Gyori
[AstraZeneca & Harvard Medical School & Vanderbilt University]
https:// weibo.com/1402400261/Lf nHE3xKH


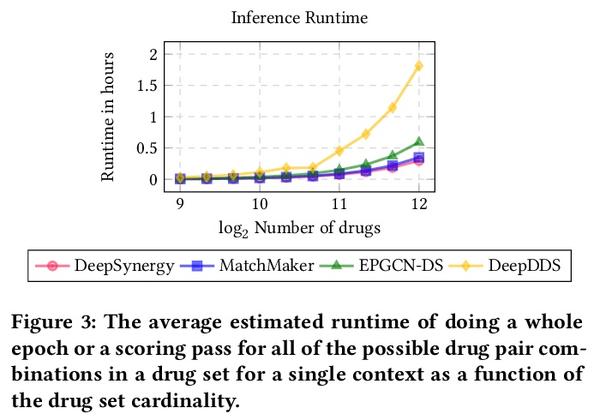
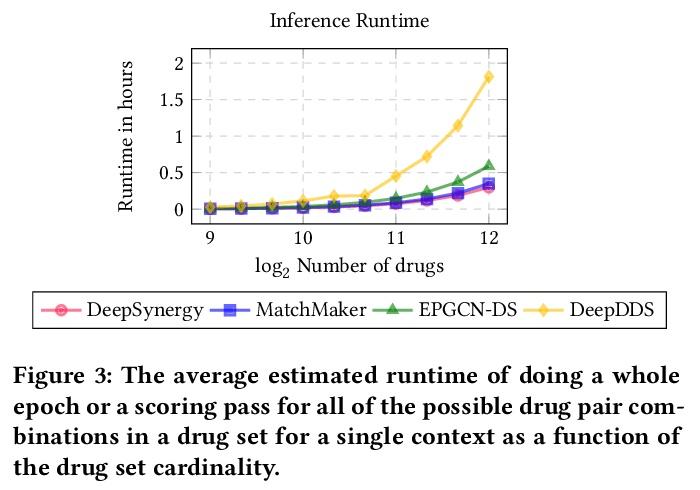
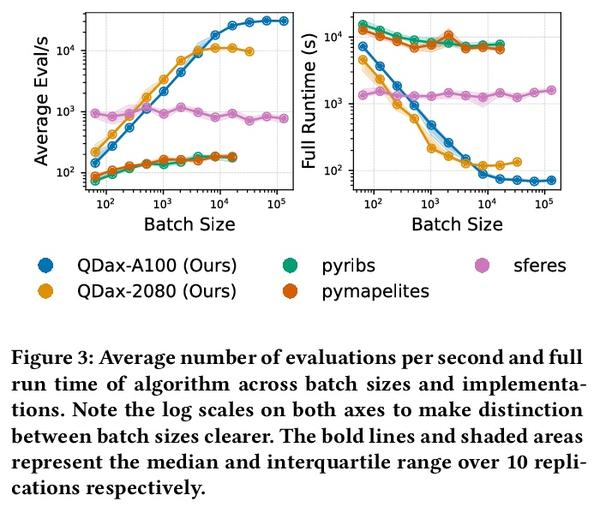
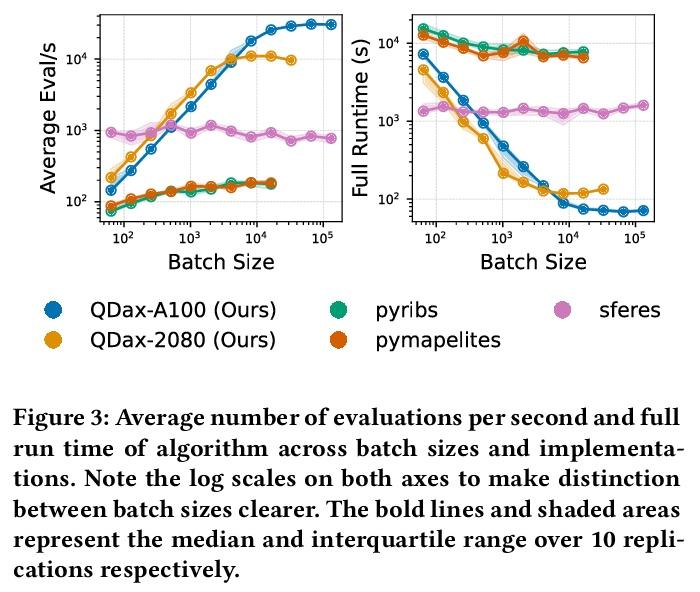
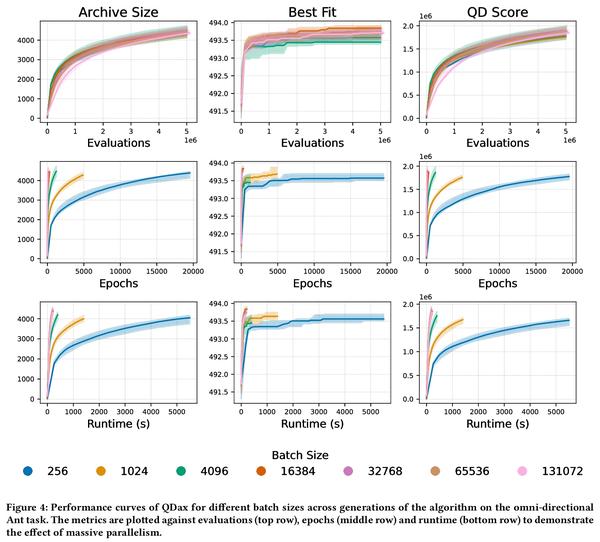
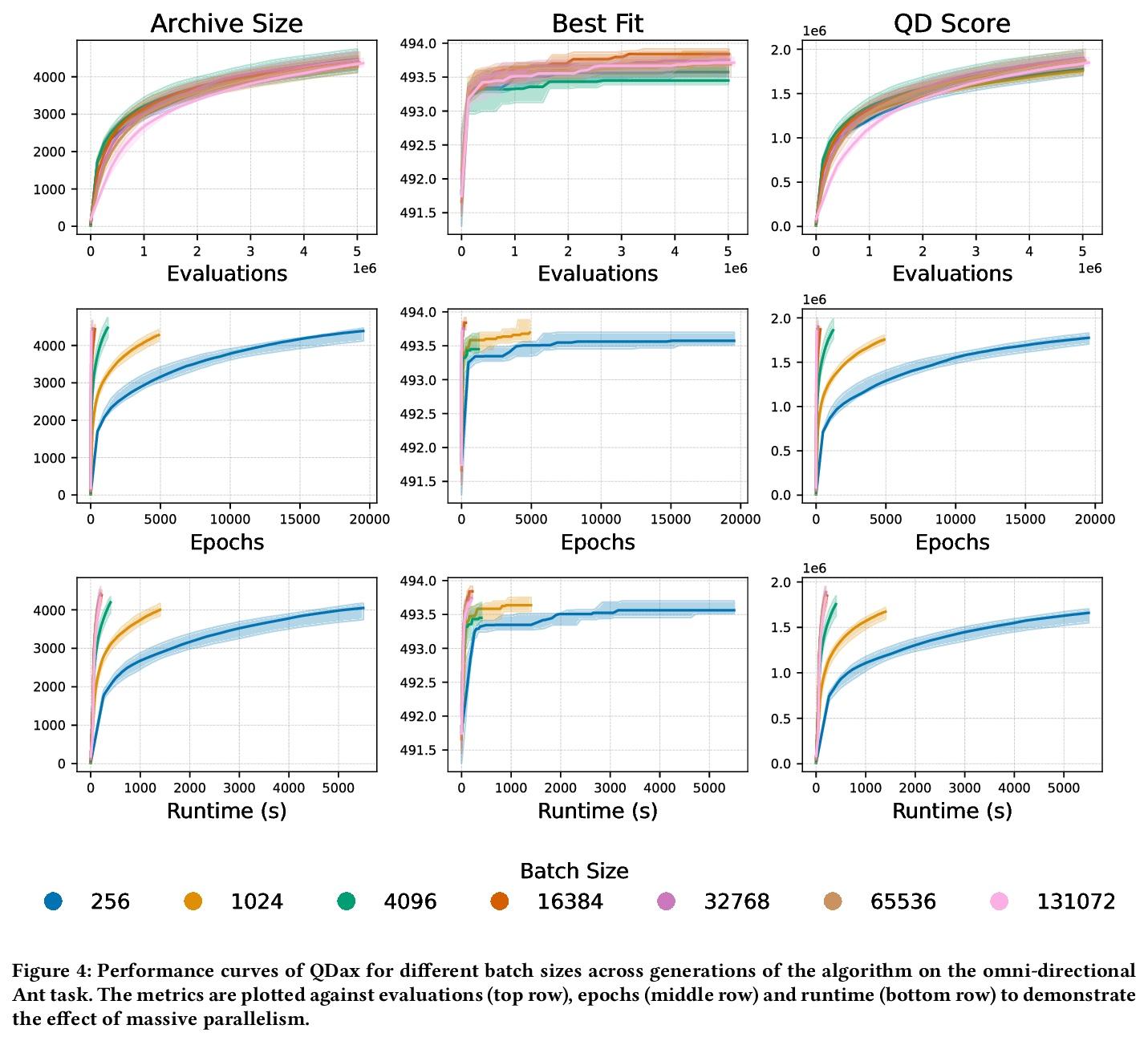
[LG] Accelerated Quality-Diversity for Robotics through Massive Parallelism
基于大规模并行的机器人质量-多样性算法加速
B Lim, M Allard, L Grillotti, A Cully
[Imperial College London]
https:// weibo.com/1402400261/Lf nJf2W6k




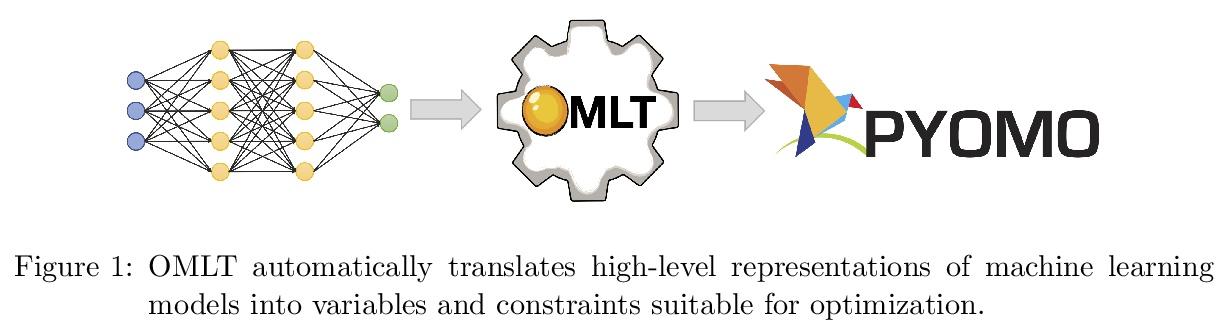
[LG] OMLT: Optimization & Machine Learning Toolkit
OMLT:优化与机器学习工具包
F Ceccon, J Jalving, J Haddad, A Thebelt, C Tsay, C D. Laird, R Misener
[ Imperial College London & Sandia National Laboratories & CMU]
https:// weibo.com/1402400261/Lf nLdB6Xg