在pandas里对于数值字段而言,groupby后可以用sum()、max()等方法进行简单的处理,对于字符串字段, 如果把它们的值拼接在一起,可以用使用
str.cat()
和
lamda
方法。
如,将下面表格中的内容,对skill字段按照id进行分组合并
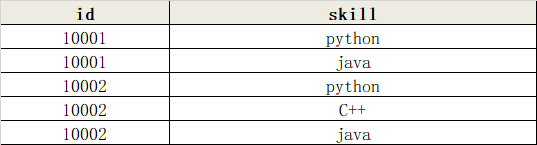
实现代码:
import pandas as pd
file_name='test.xlsx'
df=pd.read_excel(file_name)
data=df.groupby('id')['skill'].apply(lambda x:x.str.cat(sep=':')).reset_index()
print(data)
效果如下:
另,数据处理时,常常需要将某一列进行拆分,分列,替换等,相关的函数有str.split()、str.extract()、str.replace().

import pandas as pd
fpath = "./datas/beijing_tianqi/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
df.head(3)
知识:使用df.info()可以查看每列的类型
df.info()
知识:series怎样从str类型变成int
df["bWendu"] = df["bWendu"].str.repla
data2 = data2.groupby(['cat_1','cat_2','cat_3','cat_4'])['market'].apply(lambda x:x.str.cat(sep=',')).reset_index()
对’cat_1’,‘cat_2’,‘cat_3’,‘cat_4’ 这几列进行汇总成一行, 贼妙!!!
一、GROUPING SETS
Grouping sets允许用户指定要分组的多个列列表。将不属于分组列的给定字列表的列设置为NULL
比如,需求分别按照店铺分组、订单组分组、店铺和订单组分组统计订单销售额,并获取三者的结果集(插入到宽表)。可以通过union all 多个group by来实现
select store_id,
null,
sum(coalesce(order_amount, 0))
from yp_dwb.dwb_order_detail
group by s
string_agg,array_agg 这两个函数的功能大同小异,只不过合并数据的类型不同。
https://www.postgresql.org/docs/9.6/static/functions-aggregate.htmlarray_agg(expression)
把表达式变成一个数组 一般配合 array_to_string() 函数使用string_agg(expression, de
众所周知,在pandas里对于数值而言,groupby后可以用sum()、max()等方法进行简单的处理,对于字符呢, 如果把它们“sum”在一起?可以用str.cat()和lamda方法。
如下所示:
d2 = pd.DataFrame({
'a': [1, 1, 2, 2],
'b': ["nimena", "naive", "asswe", "can"],
tt...
((select '《' + TV + '》' from TVShow a where a.Name = TVShow.Name AND a.Area = TVShow.Area for xml path(''))) AS 喜欢的剧
只需要使用GROUP_CONCAT函数可以在使用groupby分组后,将某个字段的值进行拼接合并示例:mysql--dba_admin@127.0.0.1:test 12:38:31>>select * from student;+----+-----------------+--------+| id | class | name |+----+------...
在数据分析中,我们经常需要对数据进行分组聚合,而使用pandas库的groupby函数可以很容易地实现这一过程。我们需要根据商品名称进行分组聚合,并将每个分组对应的销售日期、销售数量和销售金额合并成一个字符串输出。以上就是使用pandas库的groupby函数和agg函数进行数据分组聚合和内容合并的过程,该操作能够帮助我们更好地对数据进行分析和处理。在上述代码中,使用了lambda函数将每个分组对应的数据拼接成一个字符串,并且将销售数量和销售金额的数据类型转换为字符串类型。
import pandas as pd
import numpy as np
fpath=r"G:\360Downloads\myself\zuoye\groupby后字符串合并处理\tianqi.xlsx"
df=pd.read_excel(fpath)
df.head()
#info可查看每列类型
df.info()
#将最高温度最低温度由字符串变成数字
df["bwendu"]=df[
'user_id':[1,2,1,3,3],
'content_id':[1,1,2,2,2],
'tag':['cool','nice','clever','clever','not-bad']

