随着数据可视化分析的流行,对python的论坛进行可视化分析可以有效帮助论坛进行引流,达到优化论坛资源,分析论坛走势的目的。该程序分为数据爬虫和数据分析两个部分。该设计为我本科比耶设计。
词云图分析:

问题发布年限分析:
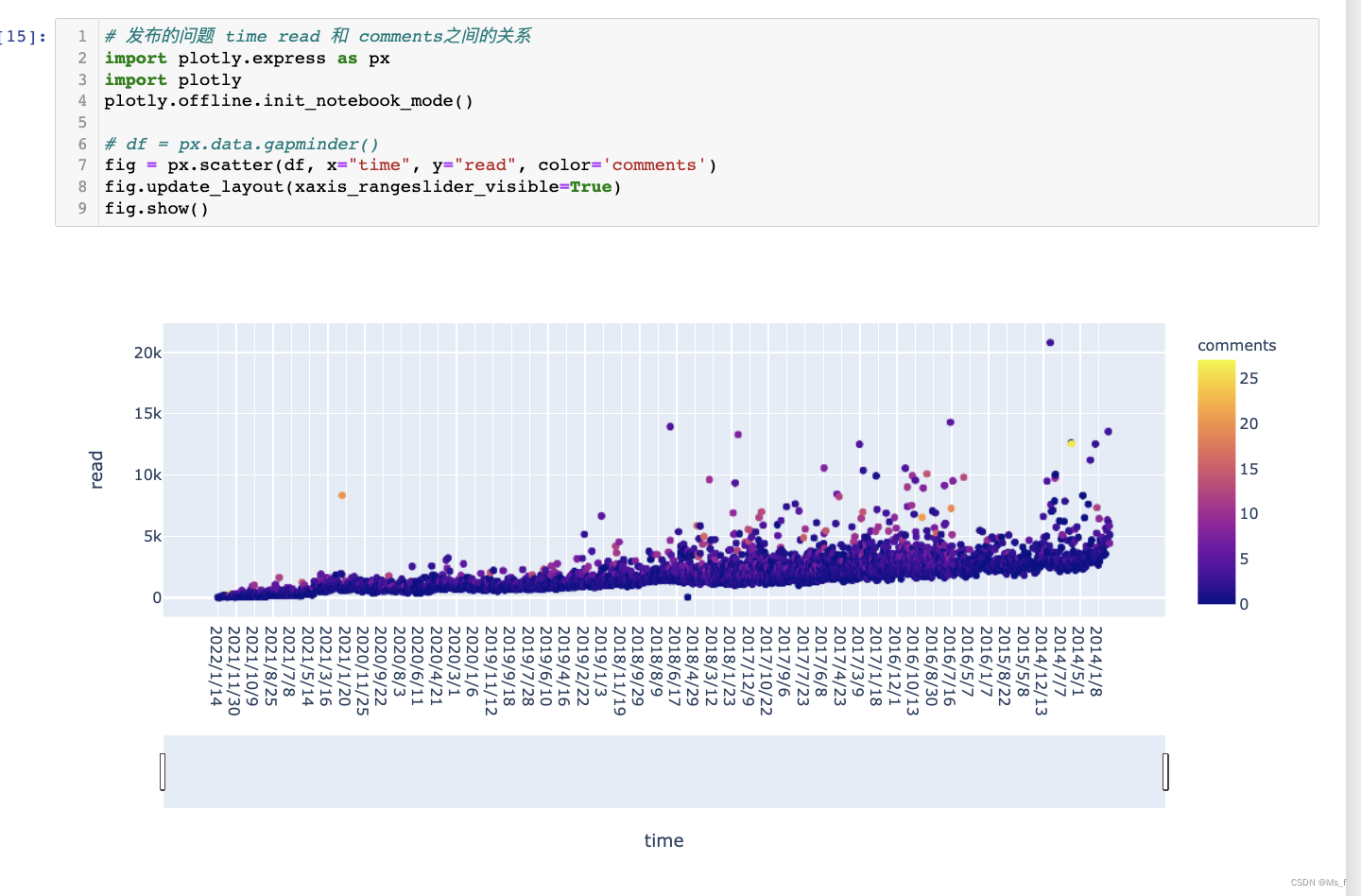
问题回复综合分析:
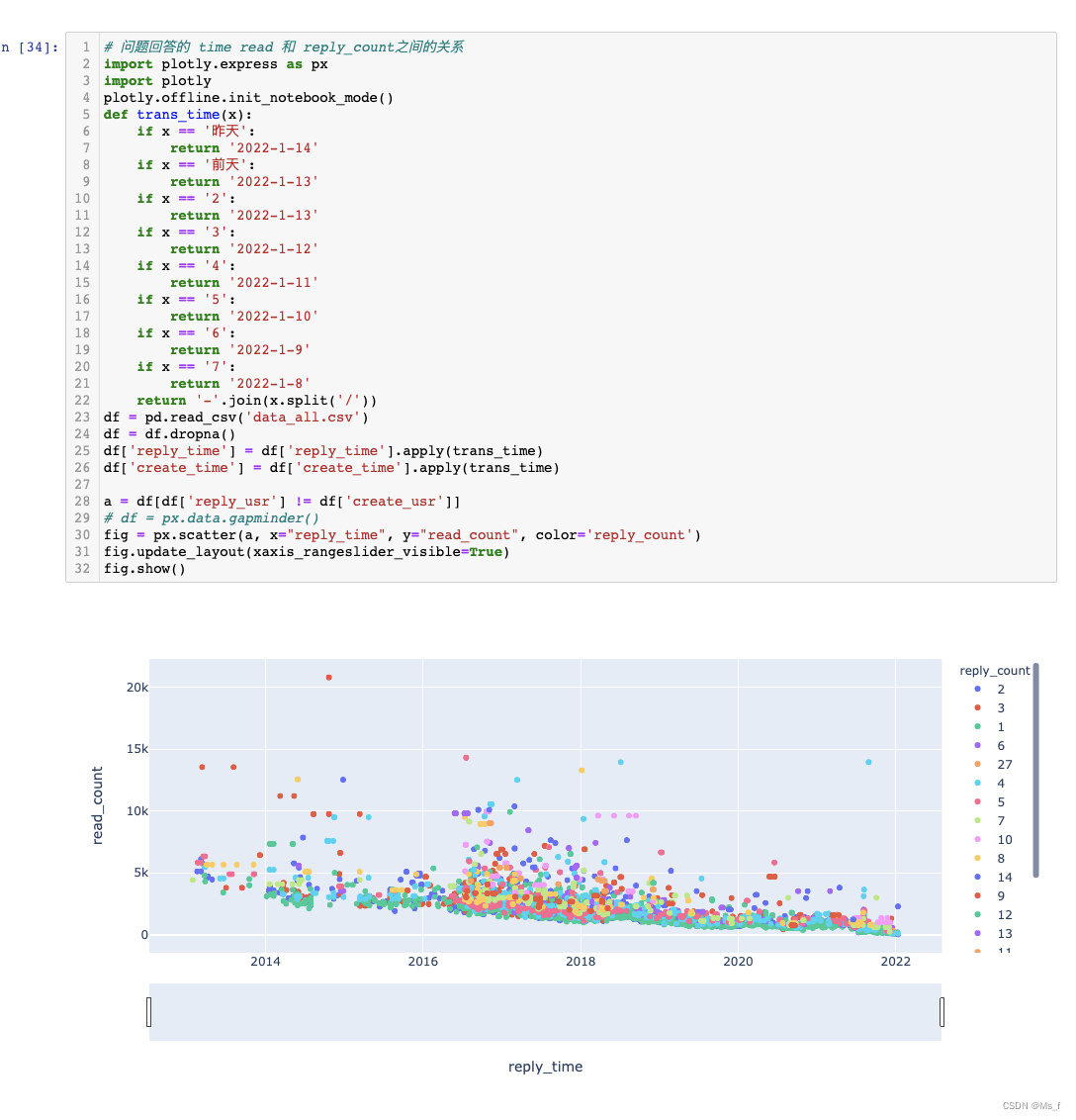
上述分析完成后,结论自己说即可。
需要数据分析by设计 联系v:km_0224
前言: 这也是一篇毕业论文的数据
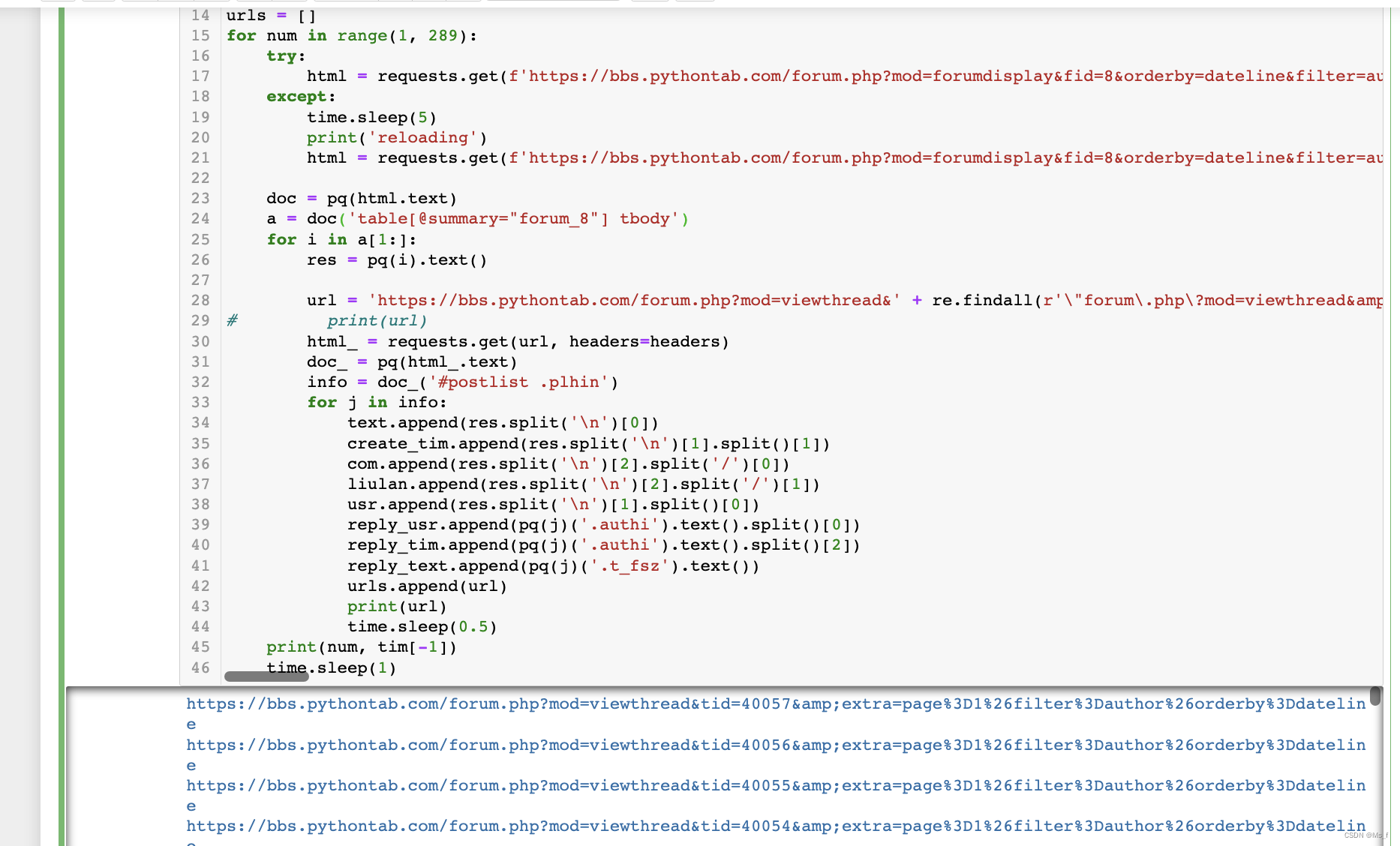
爬虫
,我第一次看见《太平洋汽车》的点评信息时,检查它的网页元素,发现并没有像《汽车之家》那样的字体反爬技术,所有就初步判断它没有很强的反
爬虫
技术,大不了就使用selenium库自动化实现
爬虫
呗。但是我确因为这样一个网页写了6种
爬虫
手段,一直在与它的反
爬虫
技术对抗,虽然最后我完成了任务,但是感觉并不是很完美,和其他网站的
爬虫
相比起来,它的运行速度有点慢,也不敢快。就这样收手吧,通过它也学到了很多的知识,如果你也想学习
爬虫
,这篇文章可以帮你解决90%以上的网页,简单的梳理一下吧,希望对你的学习有所帮助!
文章目录1、最快的30行代码1.1、
python
库的基础介绍1
python
3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写
数据分析
代码 专业性
pycharm 专业代码编辑器 按照年份与月份划分版本的
爬虫
完整代码
import requests # 发送网络请求模块
import json
import pprint # 格式化
论坛
数据库设计还是挺有意思的,按照业务逻辑进行拆分的数据库设计。
首先,如果是一个博客就一个post表记可以了。然后考虑到
论坛
数据量比较大,所以在设计上有优化。
论坛
把数据库分成3个数据表,这样在访问不同页面的时候都查询很快。
数据库表参考discuz 数据库设计:
只是挑了些相关字段,没有把所有字段列出了。
百度网盘下载地址(957):点击下载
本文使用
Python
编写
爬虫
,通过向端口传送请求并且抓取传输过来的json字符串来获取招聘职位信息,并且分类保存为csv格式的表格文件。最后通过长时间的爬取,最终得到37.7MB的表格数据,共计314093个招聘信息。之后通过SPSS对数据进行预处理和统计,再进行深度
数据分析
。
【关键词】: 拉勾网 招聘信息
爬虫
数据挖掘
数据分析
Python
SPSS
使用
Python
编写
爬虫
,通过向端口传送请求并且抓取传输过来的json字符串来获取招聘职位信息,
from lxml import etree
headers = ('Referer','http://bbs.tianya.cn/post-funinfo-2325132-1.shtml')#防盗链,修改访问来源
opener = urllib.request.build_opener()
opener.addheaders = [headers]...
### 回答1:
Python
数据
爬虫
及
可视化
分析
案例的意思是,使用
Python
编写程序获取互联网上的数据,并通过
可视化
分析
工具将数据处理成易于理解和
分析
的图表和图形。这种方法可以用于各种行业和领域,例如金融、医疗、营销和社交媒体等。具体案例包括但不限于股票数据爬取和图表
分析
、医疗数据爬取和
可视化
分析
等。
### 回答2:
近年来,
Python
成为了一种重要的数据
爬虫
和
分析
工具
语言
。
Python
作为一种动态
语言
,存在许多的技术框架和库,能够很好地支持数据爬取和
分析
。在本文中我们将介绍
Python
数据
爬虫
和
可视化
分析
的案例。
案例1:
python
数据
爬虫
在数据爬取方面,
Python
最常使用的框架是
爬虫
框架 Scrapy。 数据
爬虫
的一般流程是首先使用 Scrapy 的 Request 对象获取相关网页内容,然后使用 Scrapy 的解析器解析网页并提取数据。接着,我们可以使用 Pandas 将这些数据转化为 DataFrame 格式,便于后续的
数据分析
。
案例2:
python
可视化
分析
在
Python
可视化
分析
方面,最常用的库是 matplotlib 和 seaborn。这两个库都能够快速生成通用的统计图形,并可以针对处理数据进行高度
可视化
的定制。其中 Matplotlib 是
Python
专业绘图库,可以制作常见的统计的
可视化
图形。但是在图形美观和可定制方面,Matplotlib 的表现并不算突出。而 seaborn 是建立在 Matplotlib 之上的高层封装库,能够让我们更加容易地制作美观、概括性好的
可视化
图形。这使得 seaborn 可以在很短的时间内,制作出高品质的
可视化
图形。
综上所述,通过
Python
爬虫
框架 Scrapy 和
数据分析
库 Pandas,我们可以方便快捷地将数据爬取到本地,并进行数据处理。而通过 Matplotlib 和 seaborn 这两个高质量的
可视化
库,可以将完成的数据操作结果呈现为更优美可读的图形。因此,
Python
绝对是数据科学中优秀的选择之一。
### 回答3:
Python
数据
爬虫
及
可视化
分析
已成为当今大数据时代必备的技能之一,因为数据的爬取和
分析
是实现商业智能和数据驱动的重要工具。它不仅能帮助企业收集和
分析
消费者行为数据,优化产品设计和推广战略,还能帮助政府部门进行社会经济
分析
、政策设计和监管,提高决策的科学性和准确性。
下面以爬取和
分析
国家统计局的数据为例:
1. 数据爬取
使用
Python
第三方库BeautifulSoup来爬取国家统计局的数据。首先要了解国家统计局网站的结构,选择需要爬取的数据链接。代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 获取国家统计局主页的HTML
html = urlopen("http://www.stats.gov.cn/")
soup = BeautifulSoup(html, "html.parser")
# 找到国家统计局发布的数据链接
data_links = soup.select("#sjxw li a")
for link in data_links:
if "href" in link.attrs:
# 打印数据链接
print(link.attrs["href"])
2. 数据清洗
刚爬下来的数据常常包含一些无用的信息,需要进行数据清洗。使用
Python
第三方库Pandas来清洗数据。例如,我们想要爬取中华人民共和国城镇居民人均可支配收入,但实际上爬下来的表格里包含了很多其他指标,需要通过Pandas进行数据清洗。代码如下:
import pandas as pd
# 读入数据表格
df = pd.read_html("http://data.stats.gov.cn/easyquery.htm?cn=C01&zb=A0M01&sj=2019")[-1]
# 清除无用的行和列
df.drop([0, 1, 2, 3, 4, 5, 6], inplace=True)
df.drop(["地区", "指标", "单位"], axis=1, inplace=True)
# 重命名列名
df.columns = ["income"]
# 去掉行头和行尾的空格
df["income"] = df["income"].apply(lambda x: str(x).strip())
# 转换数据类型
df["income"] = pd.to_numeric(df["income"], errors="coerce")
# 打印清洗后的数据表格
print(df.head())
3.
数据可视化
使用
Python
第三方库Matplotlib进行
数据可视化
。例如,我们想要对不同城市的居民人均收入进行
可视化
分析
。代码如下:
import matplotlib.pyplot as plt
# 按照收入大小降序排列
df.sort_values(by="income", ascending=False, inplace=True)
# 绘制柱状图
plt.barh(df.index, df["income"])
# 设置轴标签
plt.yticks(df.index, df.index)
plt.xlabel("Income")
# 显示图形
plt.show()
以上就是一个简单的
Python
数据
爬虫
及
可视化
分析
的案例。当然,实际应用中还有很多细节问题和技巧需要掌握,需要不断学习和实践。