|
|
|


应用监控提供了基于指标的自定义告警配置,您可以通过预置的告警指标快速创建告警。另外,由于 ARMS 应用监控数据源会默认集成至 可观测监控 Prometheus 版 ,您还可以使用 Prometheus 告警,通过 PromQL 语句完成更高阶的自定义告警配置。本文会基于预置的告警指标提供一套常用的运维应急体系配置,并提供常用告警对应的 PromQL 语句。
前提条件
已接入应用监控,具体操作,请参见 应用监控接入概述 。
基础告警
告警配置思路
为确保业务稳定运行,达成预期 SLA 目标,告警作为事中环节,对快速响应有很重要的意义。快速响应、快速定位需要有明确的分层定义,本文提供一套基础的设计,从业务、应用到底层基础进行了垂直的拆分。

本文提供的配置场景涉及以下告警指标,应用监控所有预置的告警指标请参见 告警规则指标说明 。
|
指标名称 |
指标说明 |
|
调用次数 |
应用入口调用(包括调用 HTTP 入口、调用 Dubbo 入口等)的次数。可以根据该指标分析当前应用调用量的大小,从而判断业务量的大小,以及通过调用量是否偏大或偏小判断应用是否存在异常。 |
|
调用错误率(%) |
应用入口调用的调用错误次数总和/入口的调用次数总和*100%。 |
|
调用响应时间 |
应用入口调用(包括调用 HTTP 入口、调用 Dubbo 入口等)的响应时间。可以根据该指标判断是否有慢请求出现,从而判断应用是否存在异常。 |
|
异常发生次数 |
在软件系统运行过程中发生的各种异常的次数,如空指针异常、数组越界异常、IO 异常等。可以根据该指标判断调用堆栈是否抛错,从而判断是否存在应用调用异常。 |
|
HTTP 接口状态码 5xx 调用次数 |
客户端向服务器发送请求时,服务器返回的标准响应状态码为 5xx 的调用次数,例如服务器内部错误、系统繁忙等,常见的 5xx 状态码有 500 和 503。 |
|
数据库调用响应时间 |
从应用程序发送请求,到数据库返回响应结果的时间。调用数据库响应时间的快慢直接影响应用程序的性能和用户体验。如果响应时间过长,用户可能会感到应用程序卡顿或无响应,降低用户满意度。 |
|
应用依赖服务调用错误率(%) |
该应用依赖的下游接口的错误次数除以总请求数,用于判断下游依赖服务报错是否增多,进而影响当前应用。 |
|
应用依赖服务调用响应时间(单位:毫秒) |
该应用依赖的下游接口的平均响应时间,用于判断下游依赖服务耗时是否增多,进而影响当前应用。 |
|
JVM FullGC 次数(瞬时值) |
最近 N 分钟 JVM 执行了 Full GC(Full Garbage Collection)的次数。可以根据该指标判断应用是否过于频繁发生 FullGC,从而判断应用是否存在异常。 |
|
JVM 可运行线程数 |
JVM 在运行时支持的最大线程数量。如果创建线程数量过多,会占用大量的内存资源,导致系统变慢或者崩溃。 |
|
线程池使用率 |
线程池中正在使用的线程数与线程池总线程数之比,反映了当前线程池的使用情况。 |
|
节点机 CPU 使用率(%) |
节点机(服务器)上 CPU 处理器的使用率,过高的 CPU 使用率会导致系统响应变慢、服务不可用等问题。 |
|
节点机磁盘利用率(%) |
节点机中硬盘的使用情况,即已使用的磁盘空间占总磁盘空间的比例。磁盘利用率越高,表示节点机的存储容量越紧张。 |
|
节点机内存利用率(%) |
当前节点机已经使用的内存占总内存的比例。如果节点机的内存利用率超过了 80%,就需要考虑调整节点机配置或者优化任务使用内存的方式来降低内存压力。 |
业务
您可以选择核心业务的接口作为告警的标准,例如电商业务可以配置下单接口作为告警的基准,游戏业务可以选择登录入口,具体可以根据实际情况选择。
这里以 ARMS 的电商 Demo 为例,选择添加购物车接口。
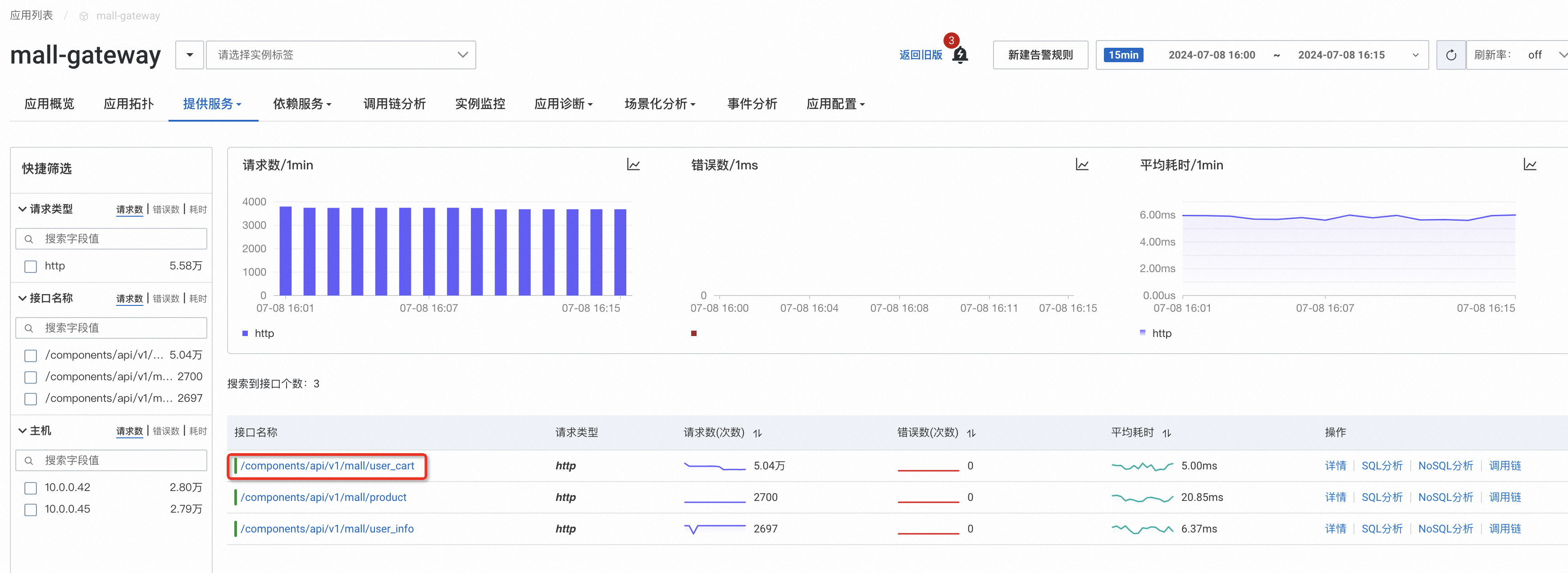
-
常用的告警指标为调用次数,业务受到影响时流量通常会下跌,突发流量上涨超过容量也会对业务造成影响。通过多条件可以设置业务量的上下边界,当业务量大于或者小于预设值时进行告警。

流量下跌推荐使用下限+下跌环比组合,业务在半夜时可能处于低谷期,仅设置一个下限就很容易触发,应用出问题时流量往往会断崖式下跌,因此可以增加一个环比作为补充。

-
配置完流量,可以再补充下错误调用,对错误率设置告警上限。
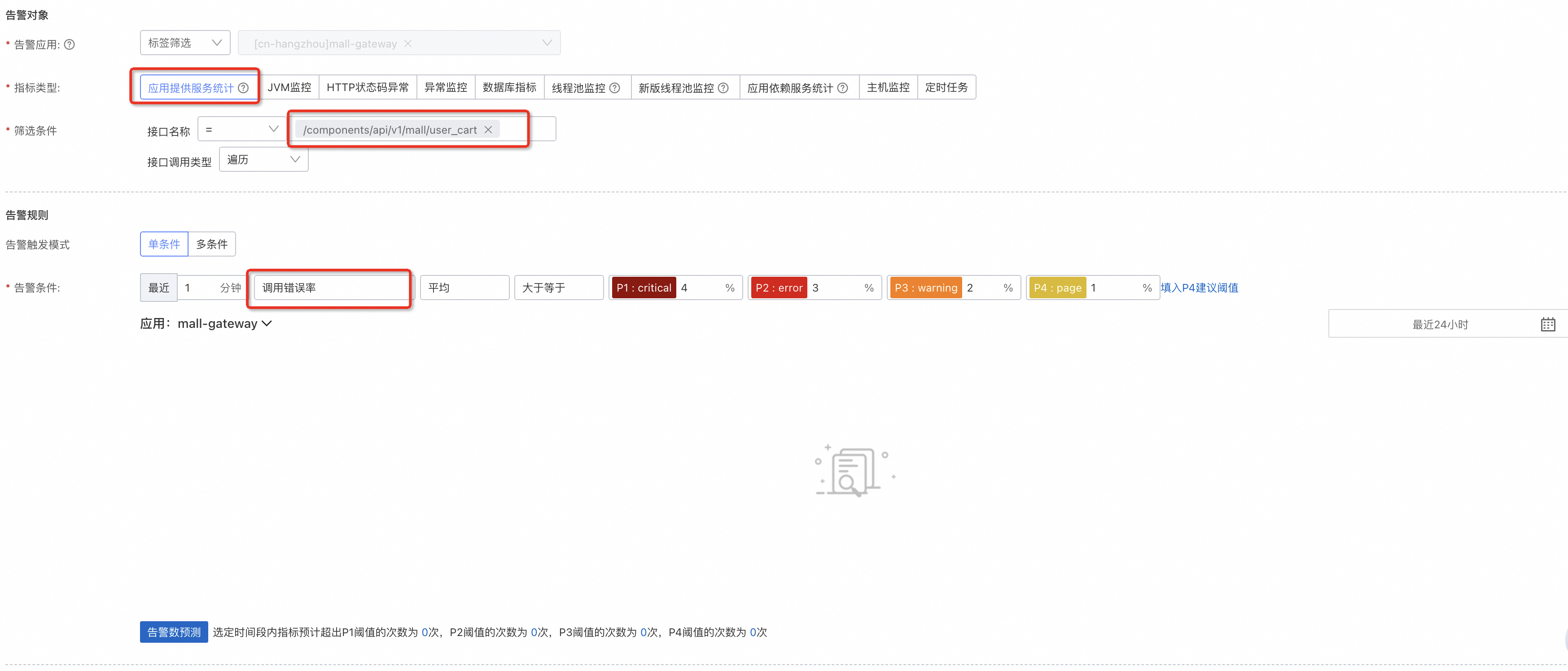
-
此外,其他条件可以根据实际情况定制,例如对耗时敏感的可以使用响应时间或者慢调用次数指标。

应用
当业务受到影响时,依靠应用的各个指标可以快速定位或者辅助发现问题。
-
首先最能发现问题的指标是异常,无论是发版更新出了 Bug,还是依赖的下游应用出了问题,通常都伴随着异常的突增。理想中的应用在正常运行时是没有异常的,那么只需要配置一个大于等于的告警即可,而现实中应用多多少少都有异常,所以可以通过配置一个异常的次数上限+环比上升的组合,用于反馈突增的异常。
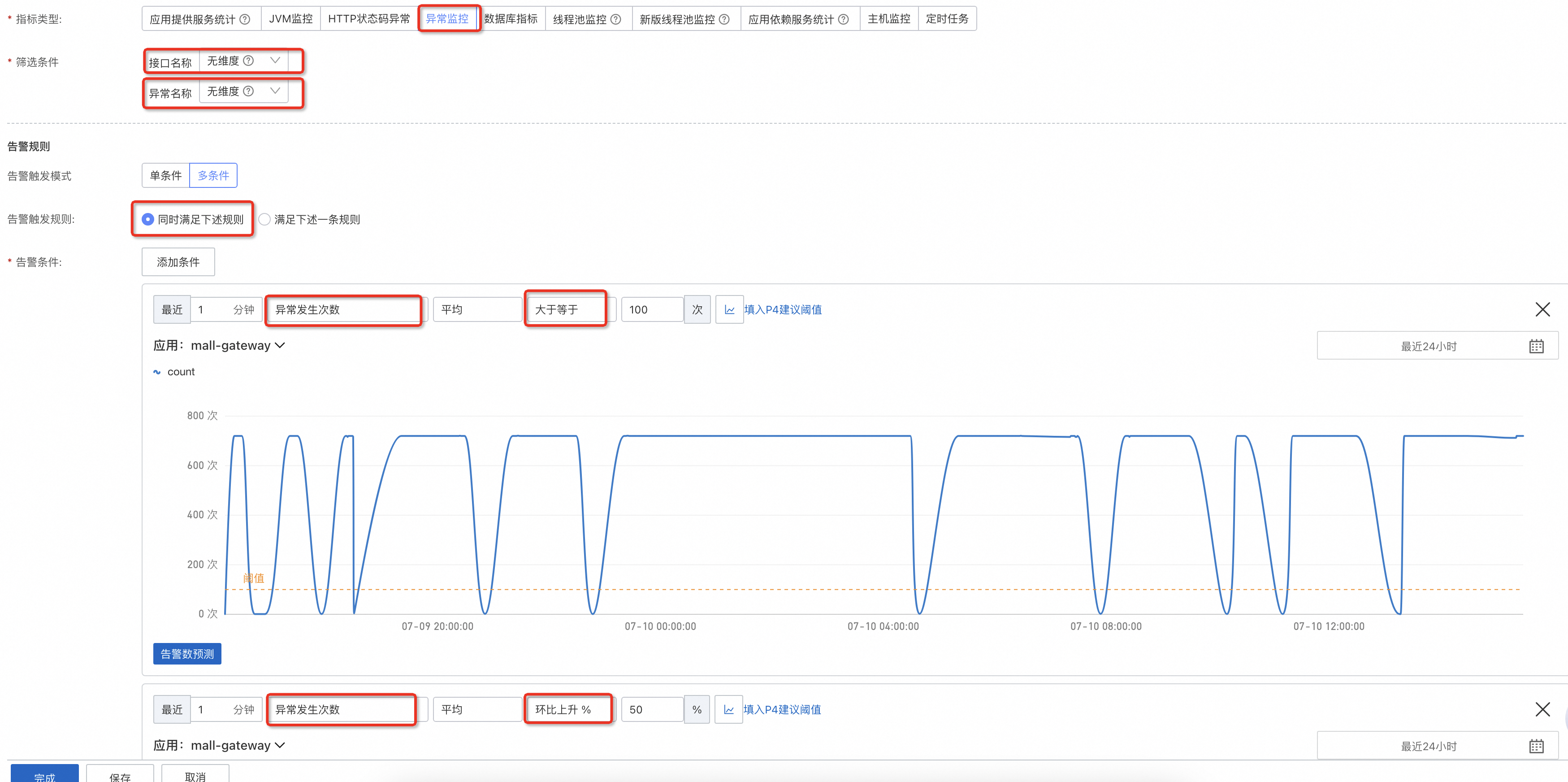
-
异常数上升不一定代表当前应用存在问题,被捕获的异常通过良好的异常处理形成的降级机制能够保证应用仍然可用,但没有被捕获的异常影响到了一次接口调用的返回结果,从而构成一次错误,因此可以直接为错误率配置上限。

-
在错误率的基础上,针对 HTTP 服务的应用,可以选择 HTTP 状态码异常,通常 4xx 是外部异常,因此推荐配置 5xx,建议配置次数上限+环比上升的组合。
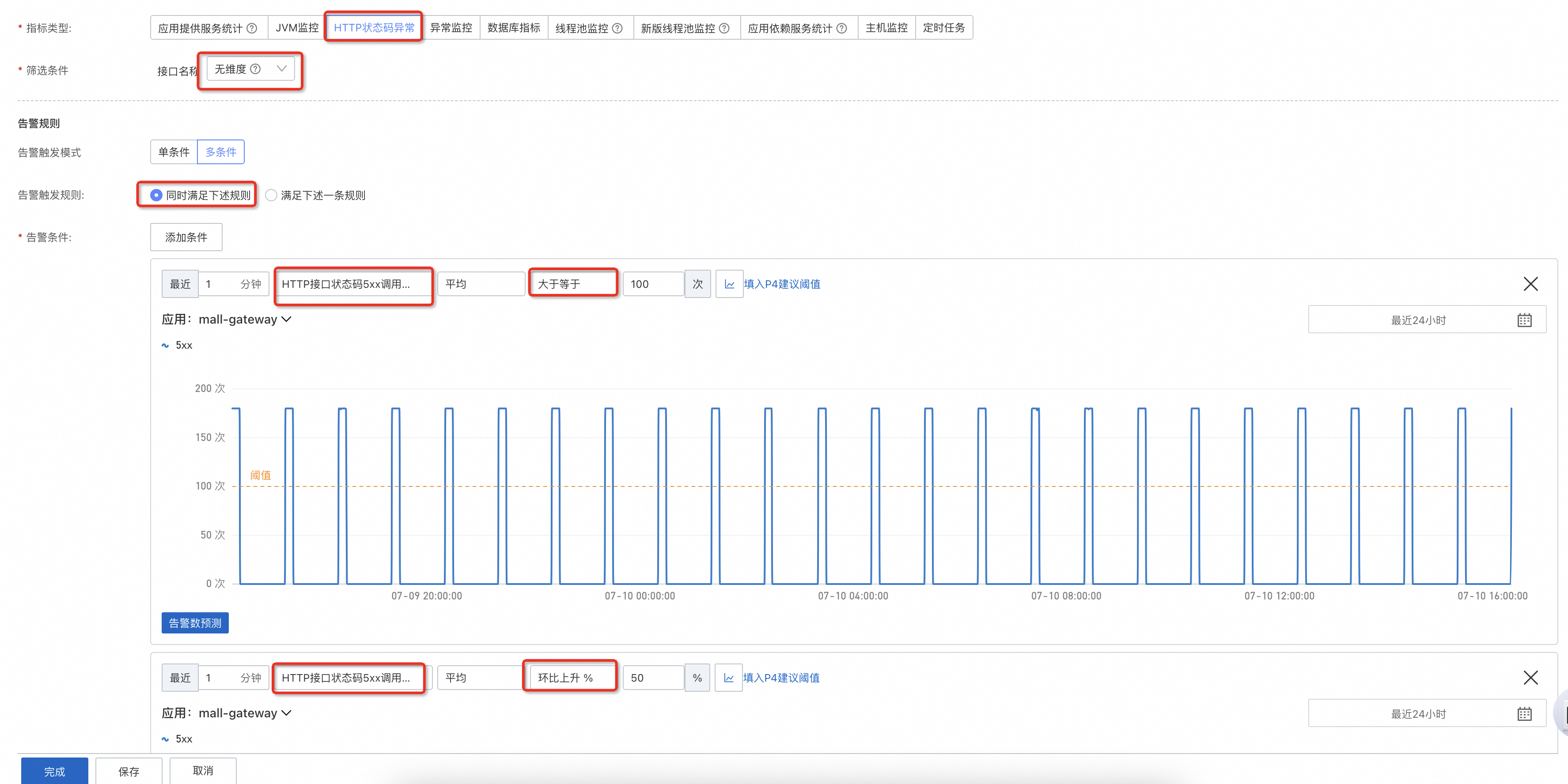
-
在应用发生问题或流量增大时,整体的耗时往往会有较大提升,所以可以根据实际情况配置一个耗时的上限,如图所示配置的是一分钟的平均值。如果业务本身就是有较大的起伏波动,可以调整最近 x 分钟的最大值,例如 5 分钟、10 分钟,这里的 x 分钟并非延迟 x 分钟,是指当前这一分钟向前 x 分钟内的值。
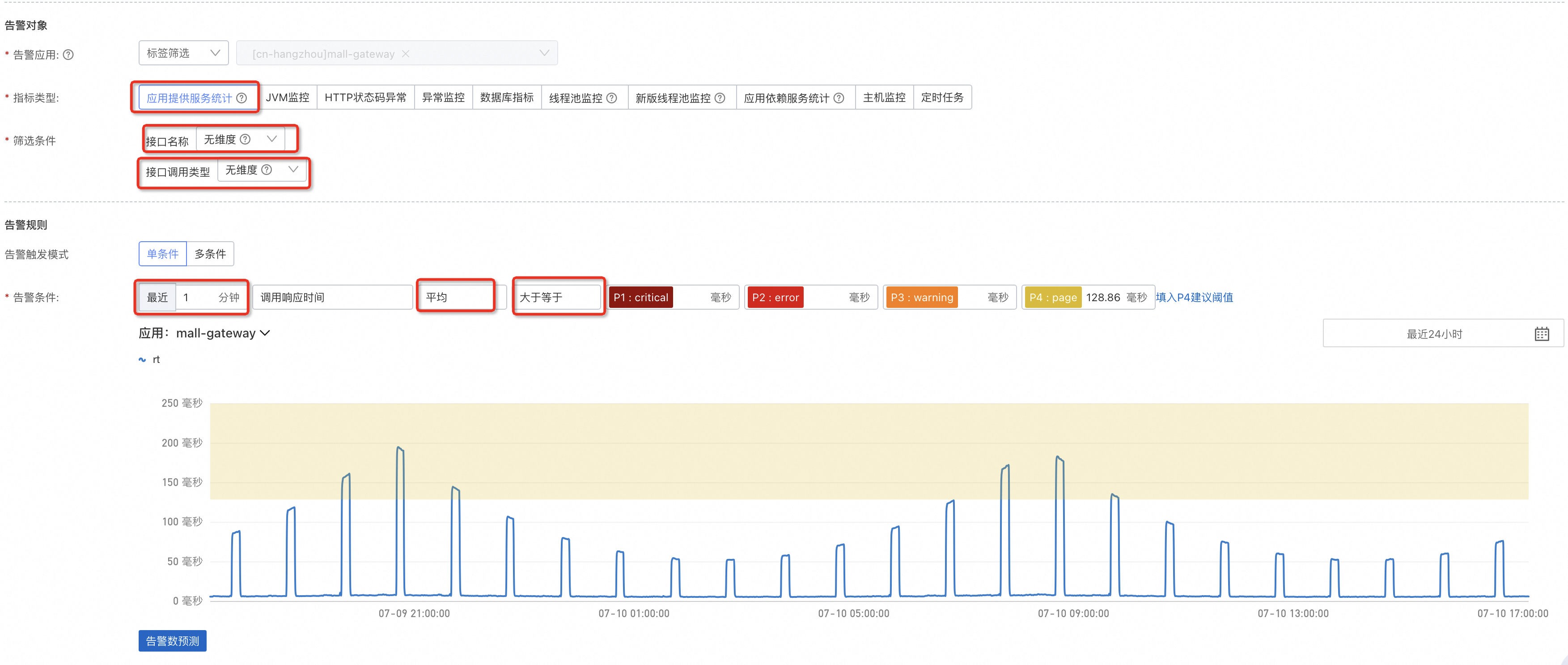
-
提供服务耗时的上升,分为内部原因和外部原因,外部原因指依赖方,可以是依赖的数据库,也可以是依赖的服务。
一般的情况下可以为数据库设置一个耗时的上限,耗时上限可以设置大一些,数据库有问题时往往会导致调用超时,耗时会十倍百倍地增长,很容易触发告警。

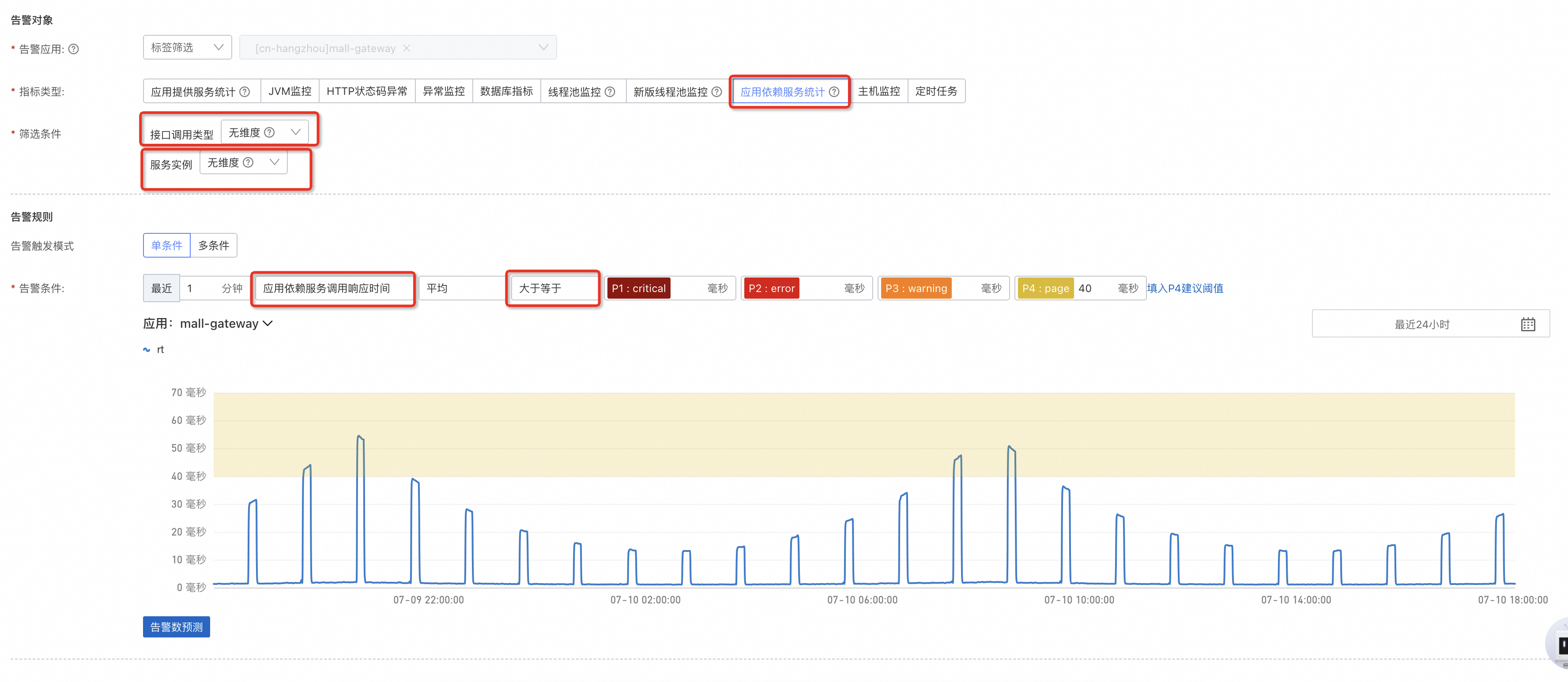
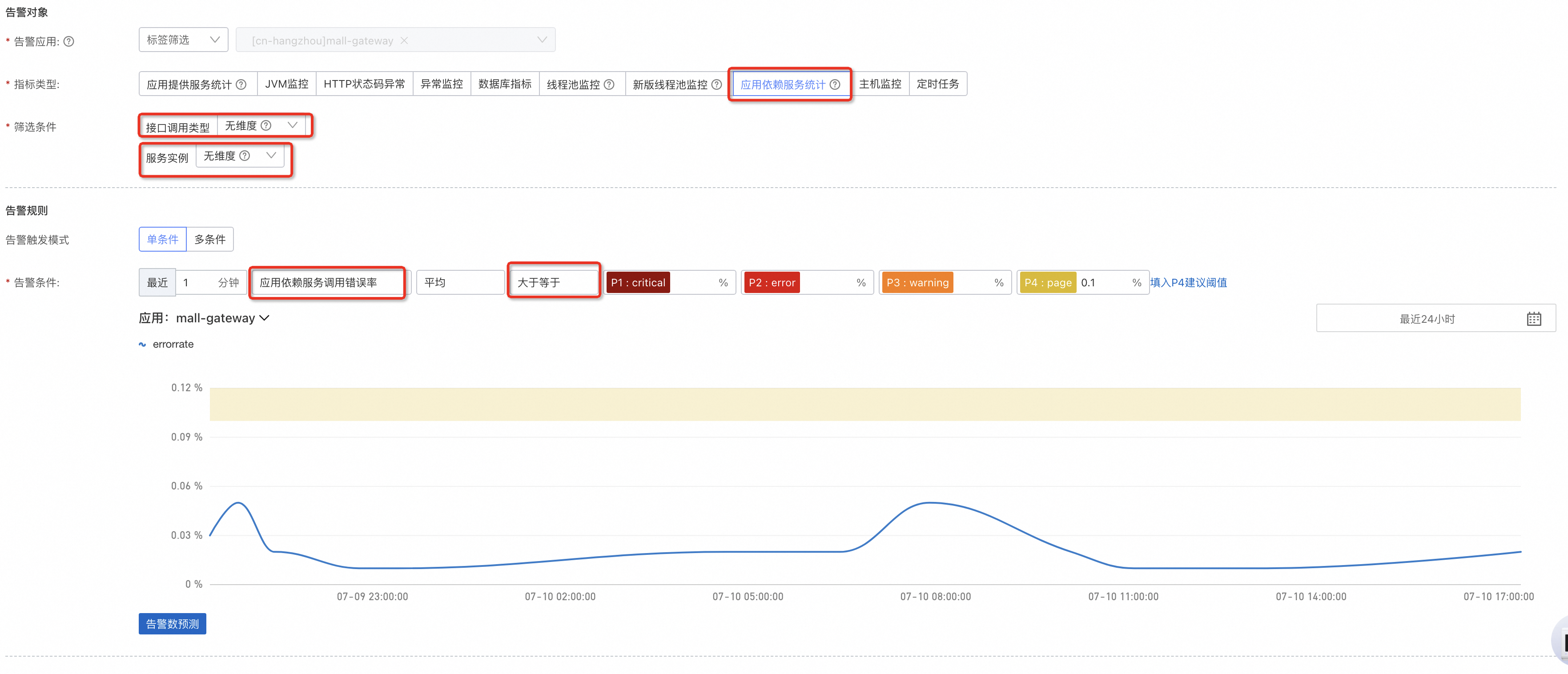
对于依赖的服务,可以分别设置耗时以及错误率的上限。
应用依赖服务调用响应时间:
应用依赖服务调用错误率:
-
应用内部自身原因引起的问题,可以配置 JVM 监控和线程池监控。
JVM 监控的指标非常多,建议主要配置一个 FGC 告警。选择单机维度,持续的 FGC 和短时间内多次 FGC 都是不合理的,对应配置两个 FGC 次数的条件告警。

JVM 可运行线程数过多会占用大量的内存资源,相反如果值为 0 时,代表 Java 虚拟机里没有可运行线程,服务也就有问题,所以可以配置一个线程数小于 1 的告警。

线程池监控可以设置线程池使用率、活跃线程数或最大线程数,线程池存在打满或者高水位的情况,持续打满的情况意味着容量达到上限,所以这里配置的是持续时间。由于部分线程池未设置最大值,最大值会变成 int 的最大值 2147483647,这种情况下,需要修改指标为活跃线程数。
说明指标类型 的 线程池监控 和 新版线程池监控 分别对应 3.x 和 4.x 版本探针。

基础
常规的 ECS 环境下,ARMS 会采集对应节点主机上的信息用于告警。核心的告警需要配置 CPU 利用率、内存利用率、磁盘利用率三项,分别按照实际情况设置上限。
节点机 CPU 利用率:由于 CPU 波动比较大,设置上限的前置可以选择 持续 。

节点机内存利用率:

节点机磁盘利用率:
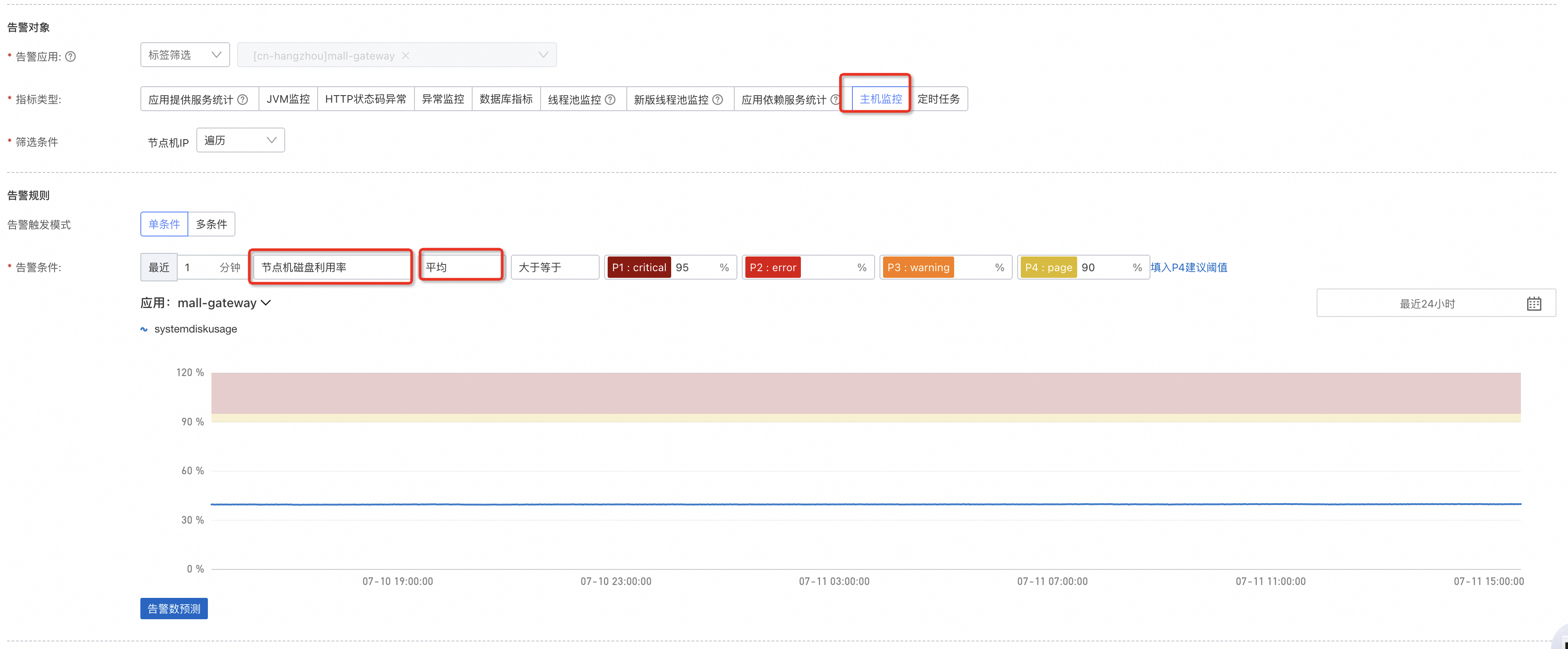
针对容器应用,如果容器接入了 可观测监控 Prometheus 版 ,建议优先配置 Prometheus 告警,具体操作请参见 设置告警 。
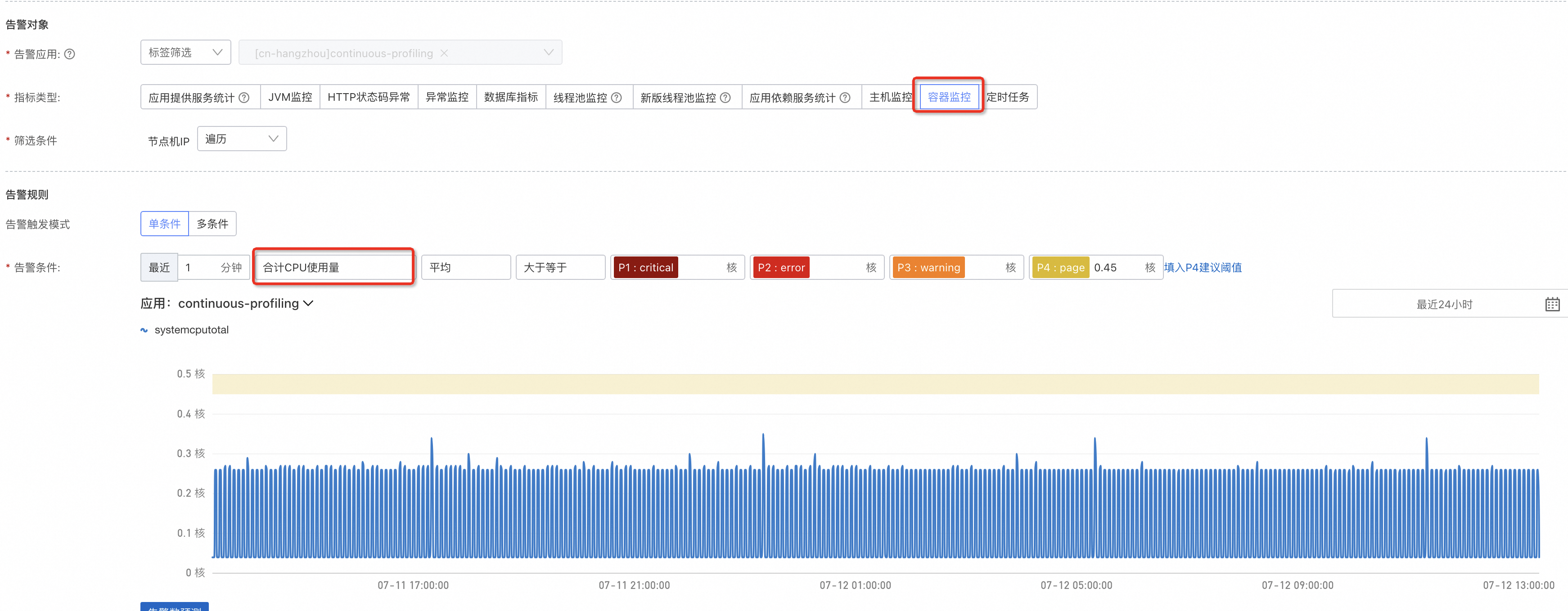
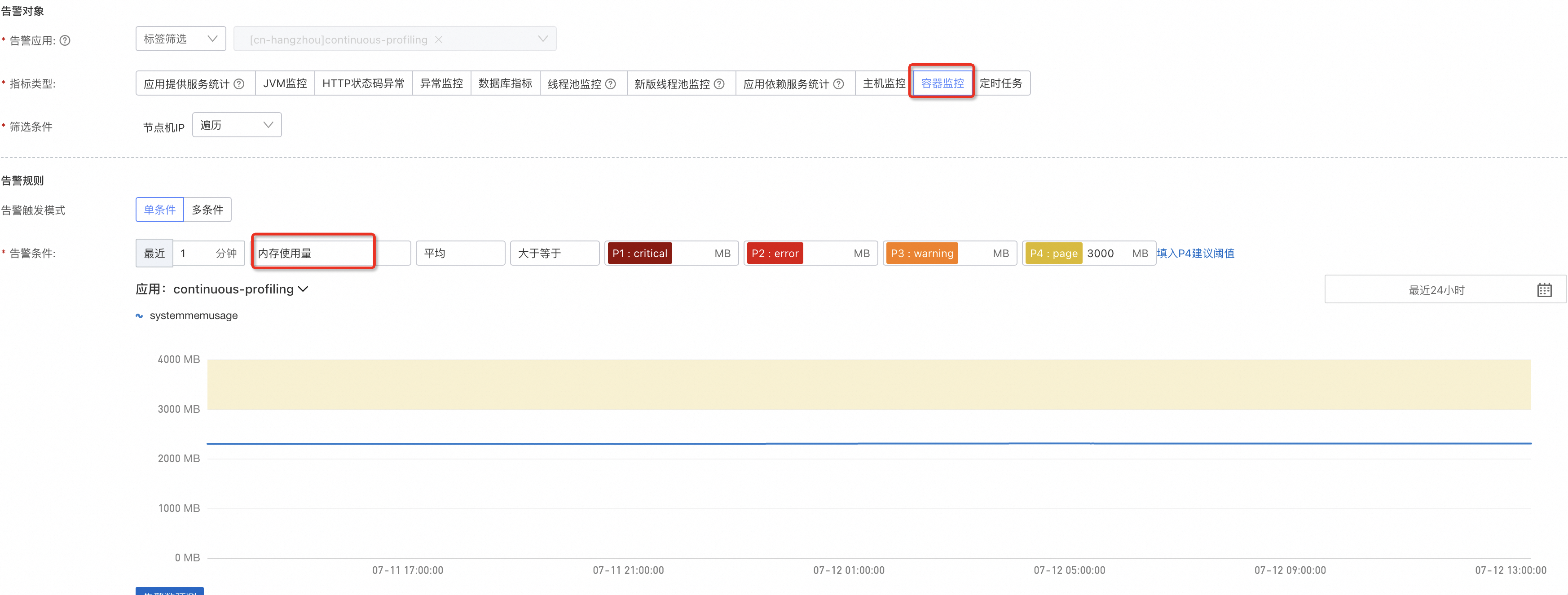
对于未接入 可观测监控 Prometheus 版 的容器应用,应用监控(4.1.0 及以上探针版本)会采集容器的 CPU、内存用于监控、告警。您可以分别给 CPU 和内存用量设置上限,由于容器设置资源 Limit 非必需,此处不会提供百分比的换算,可以基于容器实际的 Request、Limit 做上限阈值设定。
容器 CPU 使用量:
容器内存使用量:
其它
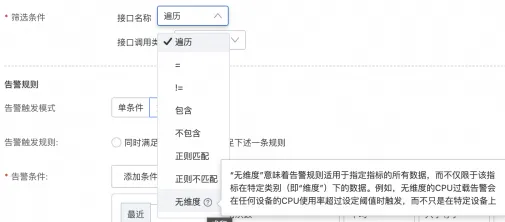
常见筛选条件
-
遍历:遍历每个节点机 IP、接口等,相当于 SQL 里的
group by,一般对单机做遍历,很多接口不适合遍历。 -
=:指定固定的几台节点机、接口,相当于是 SQL 里的
where条件,一个应用往往有多个接口,可以用来选择需要被监控的核心接口。 -
无维度:不做过滤,不做分组,看整体。如果是 CPU 利用率这类主机性质的指标,会取 CPU 利用率最高的一台主机;如果是提供服务流量指标,则看总量;如果是 RT 指标,则看平均值。
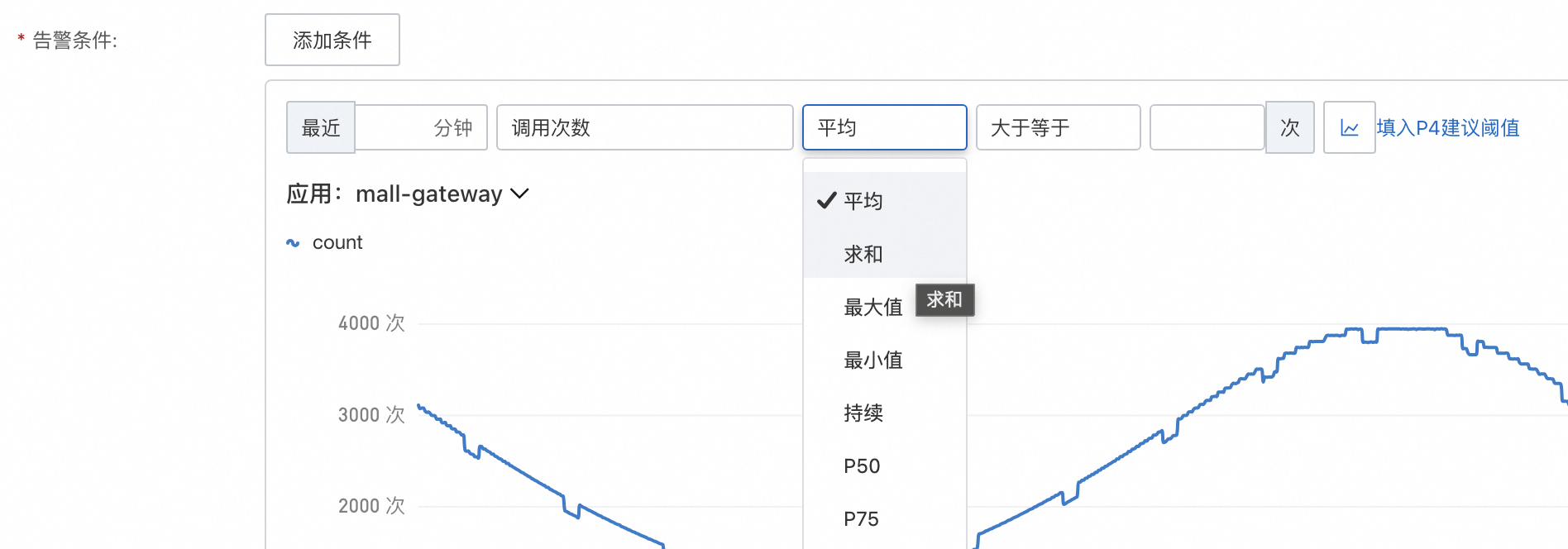
告警条件
-
平均/求和/最大值/最小值:最近 x 分钟的平均/求和/最大值/最小值。
-
持续:在 x 分钟内,x 次匹配则触发告警。常用于波动比较大的场景,例如 CPU 利用率,1 分钟超过 50%,但是下一分钟低于 50%,说明计算处理完成并没有持续高水位,则不需要每次都告警。
-
Pxx:分位数,常用于耗时场景。
说明
告警指标的最小时间颗粒度为 1 分钟,所以在最近 1 分钟条件下,平均、求和、最大、最小、持续这些条件没有区别。
阈值
不同业务不同场景下,阈值也是不同的,需要结合实际找到应用合适的点位,经历多次打磨来逐步优化。
对于首次设置告警不确定阈值时,可以使用建议阈值功能。
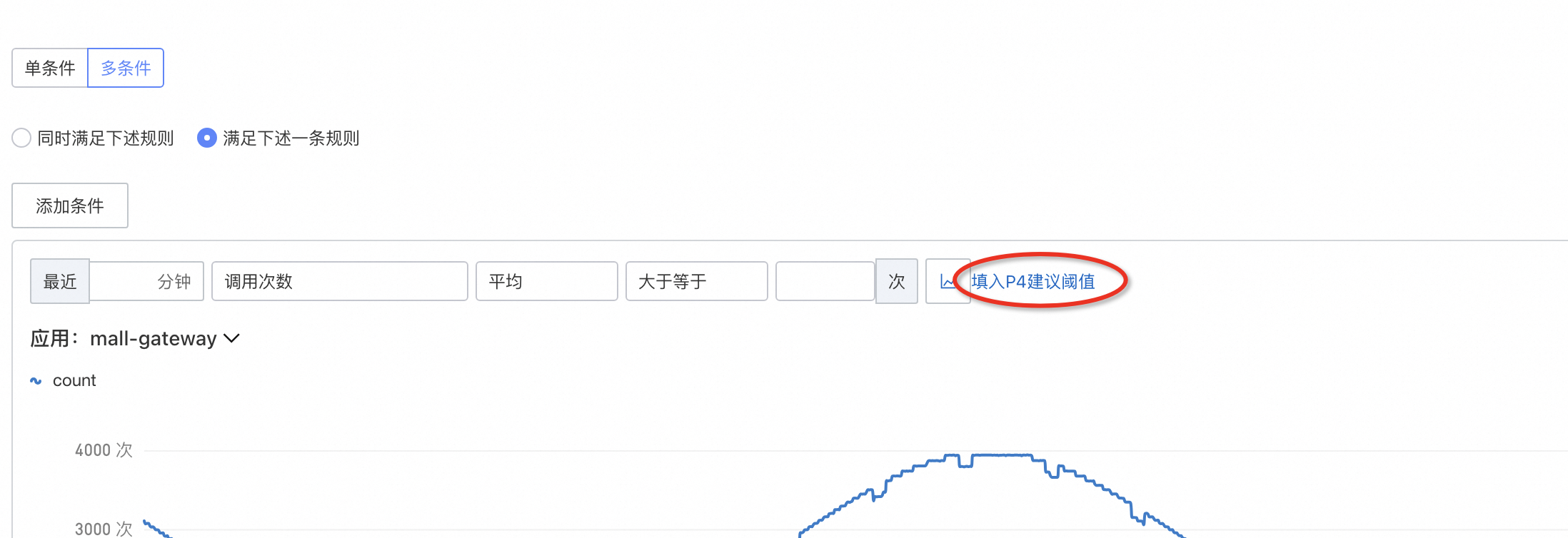
高阶告警
应用告警做了很多封装,其本质还是基于 Prometheus 做指标的查询,所以使用阿里云 可观测监控 Prometheus 版 告警同样可以通过 PromQL 配置告警指标。
应用接入 ARMS 应用监控后, 可观测监控 Prometheus 版 会在每个地域下为应用监控自动创建一个专用的存储实例。
通过创建 Prometheus 告警可以配置更多预设规则之外的告警。

以
JVM
堆内使用内存量
指标为例,应用监控里限制了单个应用,但在
Prometheus
告警里可以突破单个应用限制,查看当前地域下全部应用的单机值,对应的
PromQL
为
max by (serverIp,pid) (last_over_time(arms_jvm_mem_used_bytes{area="heap",id="eden"}[1m]))
。

目前可用的稳定指标请参见 应用监控指标说明 ,不在文档里的指标在后续升级中可能会导致不兼容,因此不推荐使用。
常用模板
业务类
指标 PromQL:
|
模板 |
PromQL |
|
HTTP 接口调用次数 |
sum by ($dims) (sum_over_time_lorc(arms_http_requests_count{$labelFilters}[1m])) |
|
HTTP 接口调用耗时 |
sum by ($dims) (sum_over_time_lorc(arms_http_requests_seconds{$labelFilters}[1m])) / sum by ($dims) (sum_over_time_lorc(arms_http_requests_count{$labelFilters}[1m])) |
|
HTTP 接口错误次数 |
sum by ($dims) (sum_over_time_lorc(arms_http_requests_error_count{$labelFilters}[1m])) |
|
HTTP 接口慢请求次数 |
sum by ($dims) (sum_over_time_lorc(arms_http_requests_count{$labelFilters}[1m])) |
维度使用说明:
-
$dims用于分组,相当于 SQL 里的group by。 -
$labelFilters用于过滤,相当于 SQL 里的where。
|
维度名称 |
维度 Key |
|
服务名称 |
service |
|
服务 PID |
pid |
|
机器 IP |
serverIp |
|
接口 |
rpc |
示例:
-
IP 为 127.0.0.1 的机器上的 HTTP 接口调用次数,按接口分组。
sum by (rpc) (sum_over_time_lorc(arms_http_requests_count{"serverIp"="127.0.0.1"}[1m])) -
接口名称为 mall/pay 的 HTTP 接口调用次数,按机器分组。
sum by (serverIp) (sum_over_time_lorc(arms_http_requests_count{"rpc"="mall/pay"}[1m]))
JVM 指标
指标 PromQL:
|
模板 |
PromQL |
|
JVM 堆内总内存量 |
max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="old",$labelFilters}[1m)) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="eden",$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="survivor",$labelFilters}[1m])) |
|
JVM YoungGC 次数 |
sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_delta{gen="young",$labelFilters}[1m])) |
|
JVM FullGC 次数 |
sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_delta{gen="old",$labelFilters}[1m])) |
|
YoungGC 耗时 |
sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_seconds_delta{gen="young",$labelFilters}[1m])) |
|
FullGC 耗时 |
sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_seconds_delta{gen="old",$labelFilters}[1m])) |
|
活跃线程数 |
max by ($dims) (last_over_time_lorc(arms_jvm_threads_count{state="live",$labelFilters}[1m])) |
|
堆内存使用率 |
(max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="old",$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="eden",$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="survivor",$labelFilters}[1m])))/max by ($dims) (last_over_time_lorc(arms_jvm_mem_max_bytes{area="heap",id="total",$labelFilters}[1m])) |
维度:
|
维度名称 |
维度 Key |
|
服务名称 |
service |
|
服务 PID |
pid |
|
机器 IP |
serverIp |
系统指标
指标 PromQL:
|
模板 |
PromQL |
|
CPU 利用率 |
max by ($dims) (last_over_time_lorc(arms_system_cpu_system{$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_system_cpu_user{$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_system_cpu_io_wait{$labelFilters}[1m])) |
|
内存利用率 |
max by ($dims) (last_over_time_lorc(arms_system_mem_used_bytes{$labelFilters}[1m]))/max by ($dims) (last_over_time_lorc(arms_system_mem_total_bytes{$labelFilters}[1m])) |
|
磁盘利用率 |
max by ($dims) (last_over_time_lorc(arms_system_disk_used_ratio{$labelFilters}[1m)) |
|
系统负载 |
max by ($dims) (last_over_time_lorc(arms_system_load{$labelFilters}[1m])) |
|
接受错误报文数 |
max by ($dims) (max_over_time_lorc(arms_system_net_in_err{$labelFilters}[1m])) |
维度:
|
维度名称 |
维度 Key |
|
服务名称 |
service |
|
服务 PID |
pid |
|
机器 IP |
serverIp |
线程池/连接池指标
指标 PromQL:
4.1.x
及以上探针版本
PromQL
线程池已使用百分比
avg by ($dims) (avg_over_time_lorc(arms_thread_pool_active_thread_count{$labelFilters}[1m]))/avg by ($dims) (avg_over_time_lorc(arms_thread_pool_max_pool_size{$labelFilters}[1m]))
连接池已使用百分比
avg by ($dims) (avg_over_time_lorc(arms_connection_pool_connection_count{state="used",$labelFilters}[1m]))/avg by ($dims) (avg_over_time_lorc(arms_connection_pool_connection_max_count{$labelFilters}[1m]))
4.1.x 以下探针版本
旧版探针的线程池和连接池指标相同,自定义配置时需要指定 ThreadPoolType,例如 Tomcat、apache-http-client、Druid、SchedulerX、okhttp3、Hikaricp,支持的线程池、连接池框架参见 线程池和连接池监控 。
|
模板 |
PromQL |
||
|
线程池已使用百分比 |
avg by ($dims) (avg_over_time_lorc(arms_threadpool_active_size{ThreadPoolType="$ThreadPoolType",$labelFilters}[1m]))/avg by ($dims) (avg_over_time_lorc(arms_threadpool_max_size{ThreadPoolType="$ThreadPoolType",$labelFilters}[1m])) |
维度 Key |
service |
|
服务 PID |
|||
|
机器 IP |
serverIp |
||
|
线程池名称(4.1.x 以下探针版本支持) |
|||
|
线程池类型(4.1.x 以下探针版本支持)
文档内容是否对您有帮助?
|