


【R语言】tidyverse之六:修改列


修改数据框的列,计算新列。
一. 创建新列
用 dplyr 包中的 mutate() 创建或修改列:
iris %>%
as_tibble(iris) %>%
mutate(new_column = "recycle_me")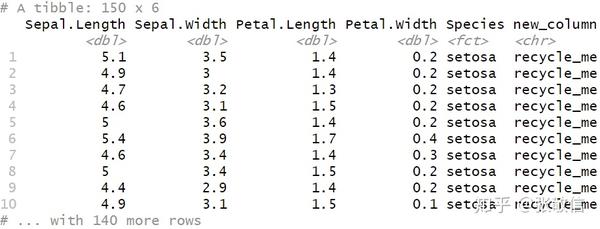
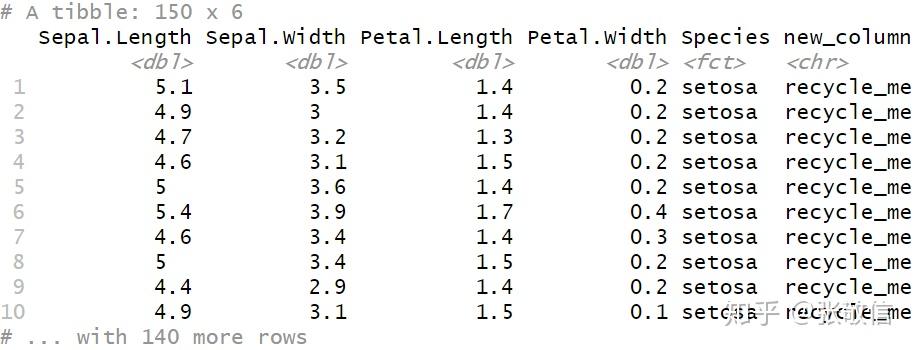
若只给新列提供长度为 1 的向量,则循环使用得到值相同的一列;正常是以长度等于行数的向量赋值:
iris %>%
as_tibble(iris) %>%
mutate(new_column = rep_len(month.name, length.out=n()))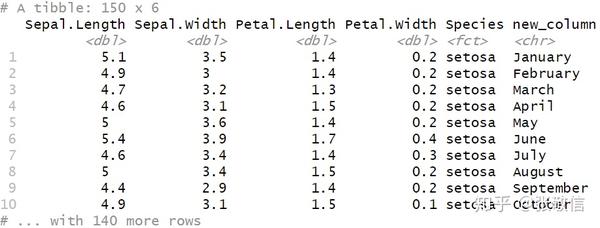
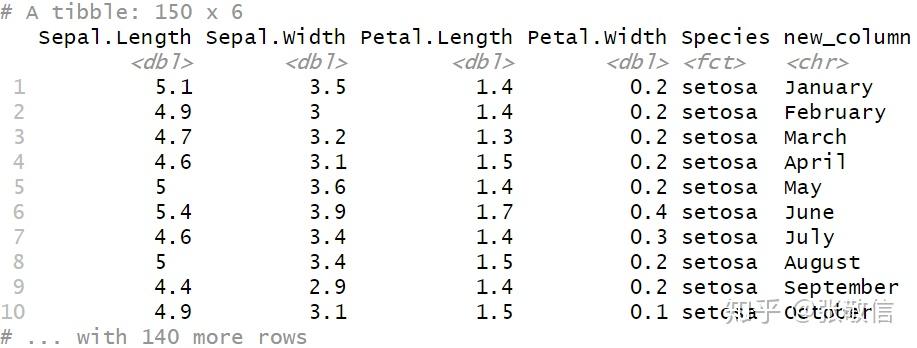
注: n() 返回group size, 未分组则为总行数。
二. 计算新列
用数据框的列计算新列,若修改当前列,只需要赋值给原列名。
iris %>%
as_tibble(iris) %>%
mutate(add_all = Sepal.Length + Sepal.Width + Petal.Length + Petal.Width)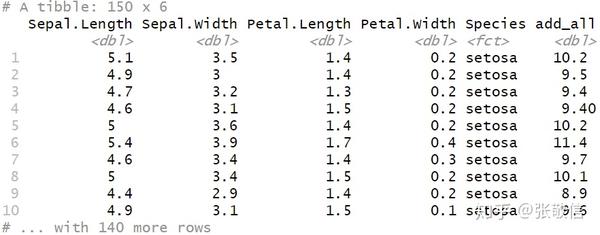
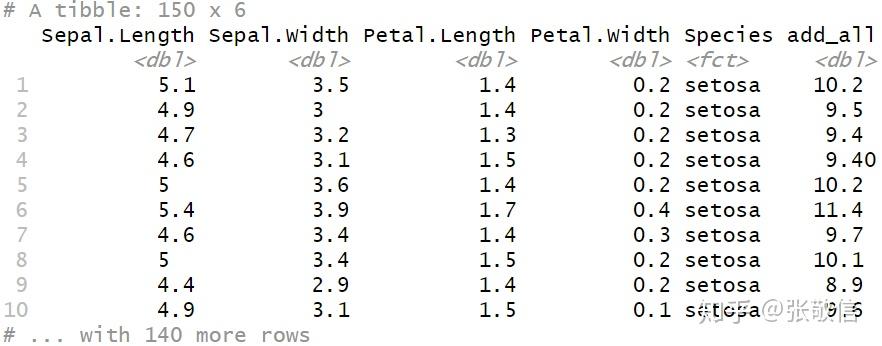
注意 ,不能用sum(), 它会将整个列的内容都加起来,类似的还有 mean().
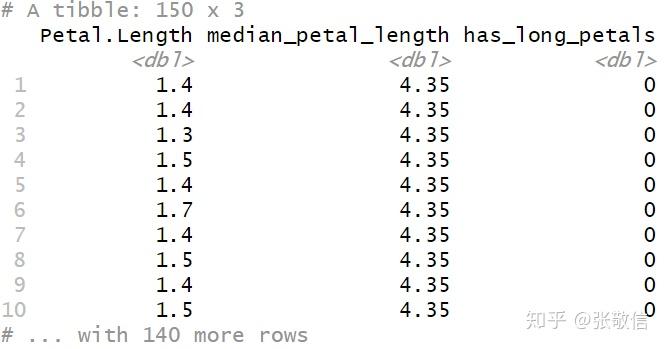
在同一个 mutate() 中可以同时创建或计算多个列,它们是从前往后依次计算,所以可以使用前面新创建的列。例如,
- 计算 iris 中所有 Petal.Length 的中位数;
- 创建标记列,若 Petal.Length 大于中位数则为 TRUE,否则为 FALSE;
- 用 as.numeric() 将 TRUE/FALSE 转化为 1/0
iris %>%
as_tibble() %>%
mutate(median_petal_length = median(Petal.Length),
has_long_petals = Petal.Length > median_petal_length,
has_long_petals = as.numeric(has_long_petals)) %>%
select(Petal.Length, median_petal_length, has_long_petals) 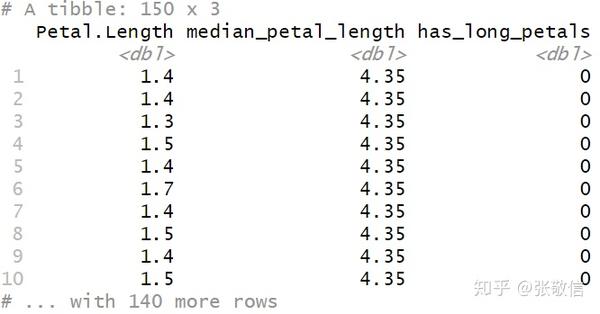
三. 修改多列
实现应用函数到数据框的多列。
- mutate_all()——应用函数到所有列
将所有列转化为小写:
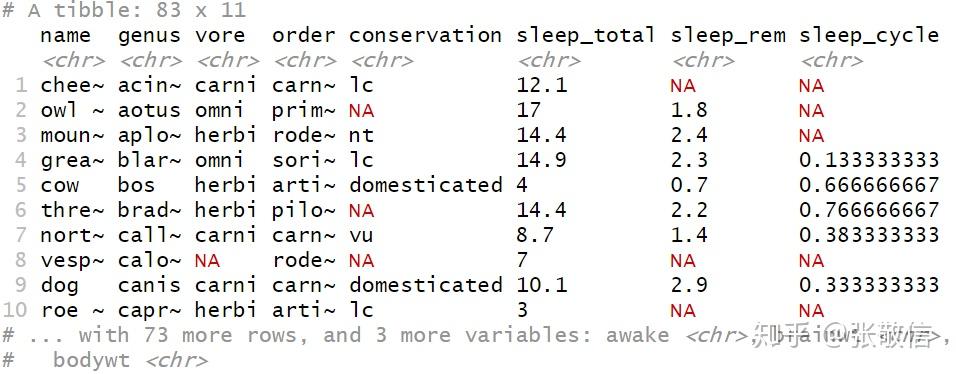
msleep %>%
mutate_all(tolower)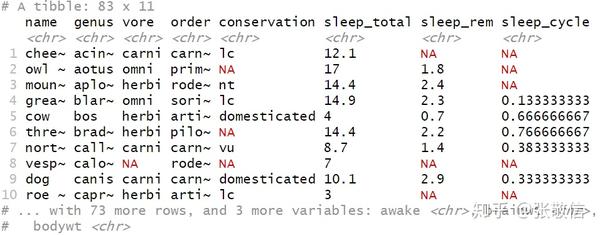
2. mutate_if()——应用函数到满足条件的列
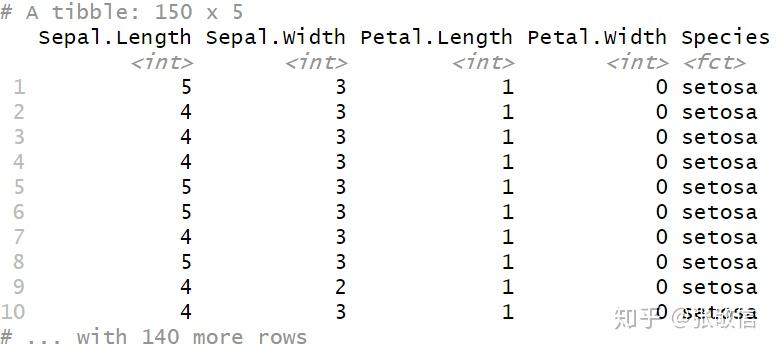
将所有 Double 型的列,转化为 Integer:
iris %>%
mutate_if(is.double, as.integer)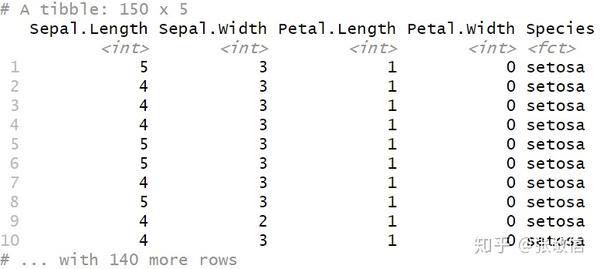
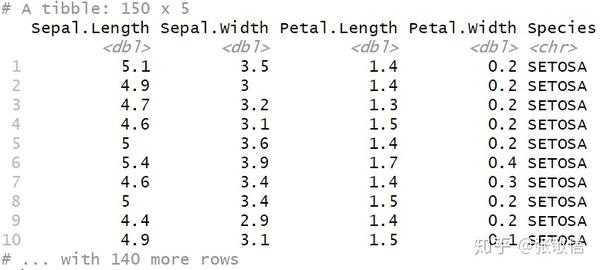
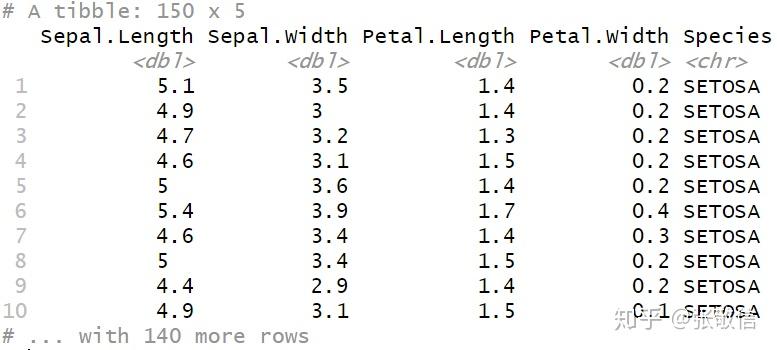
也可以对满足条件的列应用自定义函数,用更简洁的匿名函数写法,还可以使用管道操作。例如,将所有因子列,转化为 Character 型,再变成大写:
iris %>%
as_tibble() %>%
mutate_if(is.factor,
~ as.character(.) %>%
str_to_upper()
)
3. mutate_at()——应用函数到指定的列
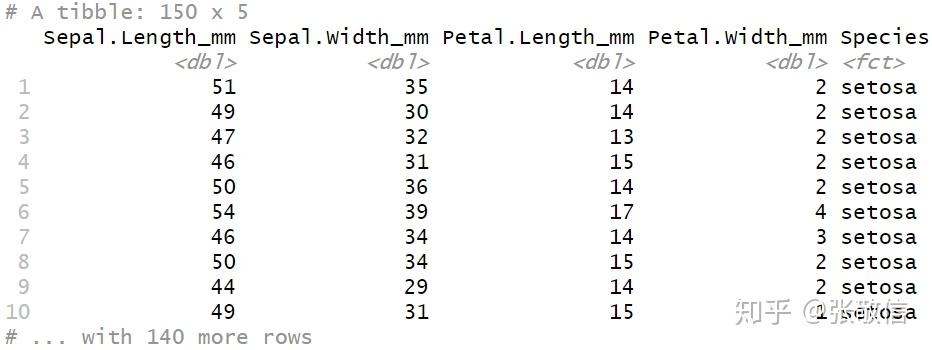
通常借助辅助选择函数 contains() 和 matches(),再套了一个 vars() 来选择列。常用来对某些测量列作单位转换。
例如,在不影响其它数值列的情况下,将 iris 中的 length 和 width 测量单位从厘米变成毫米:
iris %>%
as_tibble() %>%
mutate_at(vars(contains("Length"), contains("Width")), ~ .*10) %>%
rename_at(vars(matches("Length|Width")), ~ paste0(., "_mm"))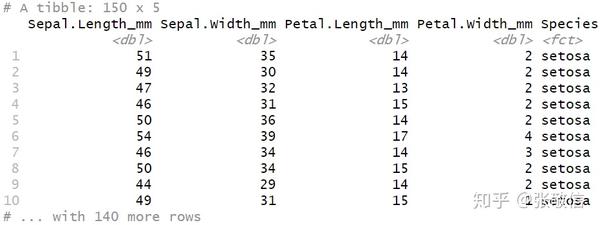
四. 替换 NA
- replace_na()
实现用同一个值替换一列中的所有 NA 值,该函数接受一个命名列表,其成分为“列名=替换值”:
starwars %>%
replace_na(list(hair_color = "UNKNOWN",
birth_year = 99999))

2. fill()
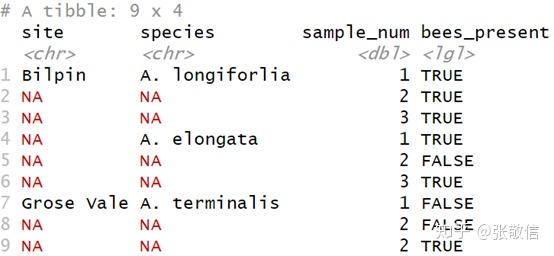
用前一个(或后一个)非缺失值填充 NA。有些表在记录时,会省略与上一条记录相同的内容,如下表:
gap_data <- tribble(
~site, ~species, ~sample_num, ~bees_present,
"Bilpin", "A. longiforlia", 1, TRUE,
NA, NA, 2, TRUE,
NA, NA, 3, TRUE,
NA, "A. elongata", 1, TRUE,
NA, NA, 2, FALSE,
NA, NA, 3, TRUE,
"Grose Vale", "A. terminalis", 1, FALSE,
NA, NA, 2, FALSE,
NA, NA, 2, TRUE
gap_data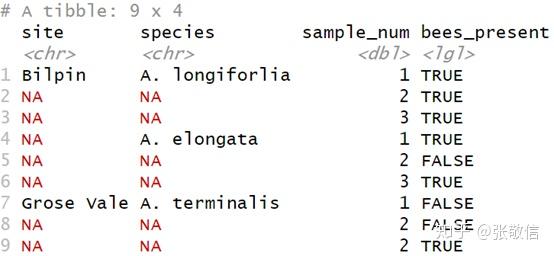
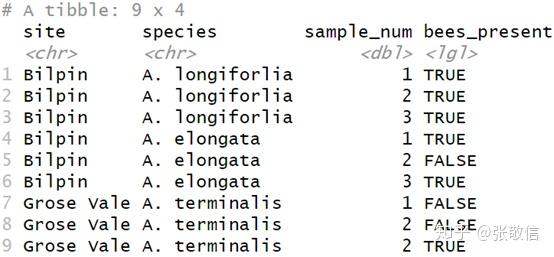
Tidyr 包中的 fill() 适合处理这种结构的 NAs, 默认是向下填充,用上一个非缺失值填充这些 NAs:
gap_data %>%
fill(site, species)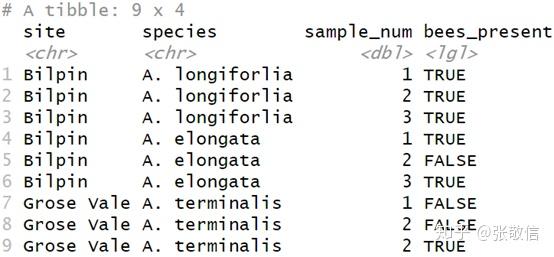
五. 重新编码
经常需要对列中的值进行重新编码。
- 两类别情形:if_else()
用 if_else() 作 yes / no 决策以确定用哪个值做替换:
warpbreaks %>%
mutate(breed = if_else(wool == "A",
true = "Merino",
false = "Corriedale")) %>%