


OpenVINO推理简介(最新)

一. 概要介绍
1.1 OpenVINO 2.0介绍
该篇介绍 OpenVINO 2.0主要原因是OpenVINO的API更新到2.0,对应的发布版本号是2022.1及以后版本。想了解OpenVINO能做什么事情可以参考另一篇 简介 ,不管你是否用过OpenVINO,都应该认真阅读一下该文。
先看一下OpenVINO 2022.1版本包含什么内容,如下图所示:
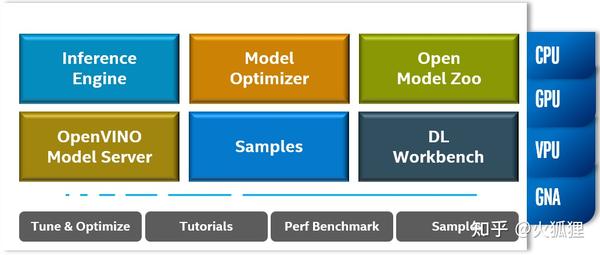
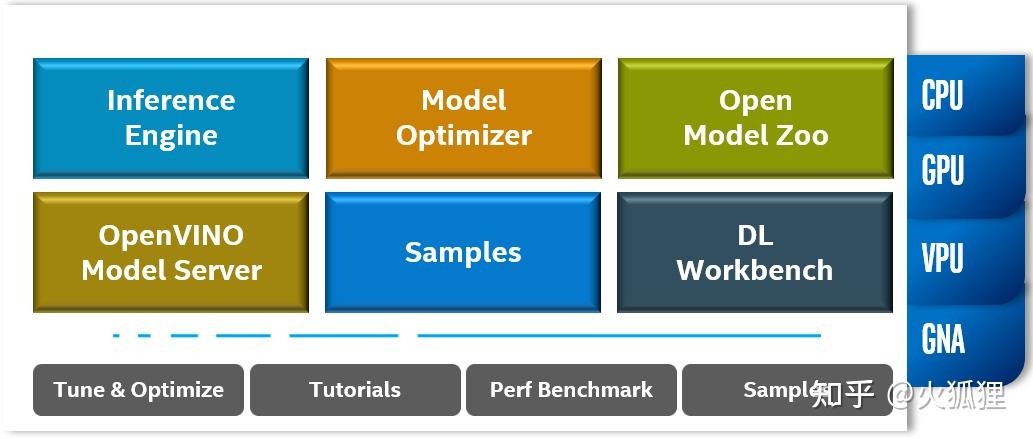
主要模块简要做个介绍:
- Inference Engine: 推理引擎,这次升级到API 2.0,也是下面要重点介绍的部分,目前支持python,C,C++三种语言。
- Model Optimizer: 模型优化器,将各种开源框架训练好的模型经过各种算子融合和内存优化转为统一的IR格式,这一步是 加速优化的关键步骤 ,目前也支持 模型加密功能 。
- Open Model Zoo: OpenVINO提供了大量场景的超过200+个预训练好的模型的一个 仓库 ,可以直接使用这些模型做原型开发,也可以根据自己数据继续精调模型。
- OpenVINO Model Server:英特尔开发的 模型服务工具 ,如果大家熟悉TensorFlow Serving,就不会对这个工具太陌生,以简单而不简约的方式快速部署AI服务。
- Samples: OpenVINO提供了很多示例程序,包括python,C++脚本,以及图像分类,目标检测,以及语音等程序示例。
- DL Workbench: OpenVINO的可视化工作台,以可视化的方式进行模型管理,训练后量化,可视化网络结构等,支持 docker安装 。
下面四个是辅助工具和示例脚本,以方便我们学习和开发。
新版本变化最大的就是API了,升级后的接口更清爽自然,下面会专门做介绍。OpenVINO加速推理的流程如下图所示:
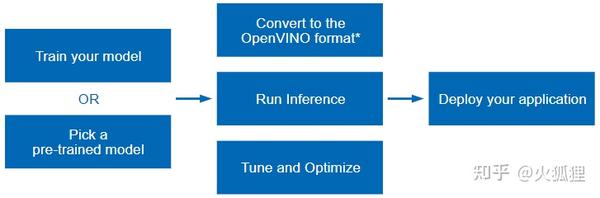

虽然支持直接装载onnx格式,但是经过“模型优化器”处理后性能会更好。
1.2 版本兼容性
以往版本的InferenceEngine和nGraph接口还会保留,如果你基于之前版本部署,更可以继续使用。2022.1及以后版本支持的IR版本是11,而IR10会被新接口以传统的方式支持。最后就是训练后量化(POT)和可视化工作台(DL Workbench)不再支持IR10。
具体迁移方法见 2.4节 或 OpenVINO 2.0 Transition Guide .
二. OpenVINO API 2.0
这里以图像识别来介绍新的API接口
2.1 Python接口示例
python接口变得更想开源框架风格了,使得从框架推理迁移过来没有太大的违和感,加上重新修订的预处理模块,使得推理输入变得自然,就是读图并扩充batch这一维度即可。下面展示了同步模式推理ResNet50做图像识别的推理过程,代码清爽且简洁。
1 import cv2
2 import numpy as np
3 from openvino.preprocess import PrePostProcessor, ResizeAlgorithm
4 from openvino.runtime import Core, Layout, Type
6 def main():
7 model_path = "resnet50.xml"
8 image_path = "test.jpg"
9 device_name = "CPU"
11 # 初始化OpenVINO运行时引擎
12 core = Core()
13 # 装载模型
14 model = core.load_model(model_path)
15 # 读取图像
16 image = cv2.imread(image_path)
17 input_tensor = np.expand_dims(image, 0)
18 # 预处理流程
19 ppp = PrePostProcessor(model)
20 _,h,w,_ = input_tensor.shape
21 # 设置输入节点信息,如输入类型为U8,通道顺序为NHWC,设置静态输入尺寸用于Resize操作
22 ppp.input().tensor() \
23 .set_element_type(Type.u8) \
24 .set_layout(Layout('NHWC')) \
25 .set_spatial_static_shape(h, w)
27 # 增加预处理步骤
28 ppp.input.preprocess().resize(ResizeAlgorithm.RESIZE_LINEAR)
29 # 假设模型输入的通道顺序为"NCHW"
30 ppp.input().model().set_layout(Layout('NCHW'))
31 # 设置输出节点精度类型
32 ppp.output().tensor().set_element_type(Type.f32)
33 # 将预处理流程应用到原始模型
34 model = ppp.build()
36 # 将模型装载到设备
37 compiled_model = core.compile_model(model, device_name)
38 # 创建推理请求并进行同步模式推理
39 results = compiled_model.infer_new_request({0: input_tensor})
40 # 处理推理结果
41 predictions = next(iter(results.values()))
42 probs = predictions.reshape(-1)
43 top_10 = np.argsort(probs)[-10:][::-1] 2.2 C++接口示例
与Python接口一样,C++接口也更加简洁,所有变量都统一到一个命名空间ov,函数命名法也更贴近开源框架风格,这套新的接口兼顾了间接性和扩展性,预计会稳定很长一段时间。
1 #include <vector>
2 #include <string>
3 #include "openvino/openvino.hpp"
4 #include "format_reader_ptr.h"
6 int main(int argc, char** argv[])
8 model_path = "./resnet50.xml";
9 image_path = "./test.jpg";
10 device_name = "CPU";
12 // 初始化运行时引擎
13 ov::Core core;
14 // 载入模型
15 std::share_ptr<ov::Model> model = core.read_model(model_path);
16 // 设置输入
17 FormatReader::ReaderPtr reader(image_path.c_str());
18 ov::element::Type input_type = ov::element::u8;
19 ov::shape input_shape = {1, reader->height(), reader->width(), 3};
20 std::shared_ptr<unsigned char> input_data = reader->getData();
21 // 转换图像数据为ov::Tensor,但不用重新分配内存
22 ov::Tensor input_tensor = ov::Tensor(input_type, input_shape, input_data.get());
23 const ov::shape tensor_shape = input_tensor.get_shape();
24 const ov::Layout tensor_layout{"NHWC"};
25 // 配置预处理
26 ov::preprocess::PrePostProcessor ppp(model);
27 ppp.input()
28 .tensor()
29 .set_element_type(ov::element::u8)
30 .set_layout(tensor_layout)
31 .set_spatial_static_shape(tensor_shape[ov::layout::height_idx(tensor_leyout)],
32 tensor_shape[ov::layout::width_idx(tensor_layout)]);
33 ppp.input().propresess().resize(ov::preprocess::ResizeAlgorigthm::RESIZE_LINEAR);
34 ppp.input().model().set_layout("NCHW");
35 // 设置输出精度
36 ppp.output().tensor().set_element_type(ov::element::f32);
37 // 将预处理融入原始模型
38 model = ppp.build();
40 // 建模型载入设备
41 ov::CompiledModel compiled_model = core.compile_model(model, device_name);
42 // 创建请求
43 ov::InferRequest infer_request = compiled_model.create_infer_request();
44 // 准备输入
45 infer_request.set_input_tensor(input_tensor);
46 // 推理
47 infer_request.infer();
48 // 处理推理结果
49 const ov::Tensor& output_tensor = infer_request.get_ouput_tensor();
50 // 接业务部分...
52 return 0;
53 }
2.3 预处理功能模块
做AI工程化的都做过模型推理之前的预处理,如图像的通道变换,数据类型变换,归一化处理等,自然语言处理的tokenize,embedding等。一般情况下,会引入第三方包或模块,如OpenCV。如果仅仅是简单的预处理,应用那么大的三方包,有点太重,OpenVINO提供了预处理功能模块,能很好的解决这些问题。
该模块在以往版本上也是支持的,只不过现在单独拉出来,做了一些规范和功能增强,大大提高了代码的可读性。
下面看看该功能模块到底可以干多少事情,如果能满足大部分的预处理需求,自然是再好不过了。
- 转换数据精度类型(如:u8转f32)
- 通道转换(如: NHWC转为NCHW)
- 归一化(mean/scale)
- Resize
- 颜色空间转换(NV12,I420,RGB,BGR等)
- 客户自定义操作
比如,图像载入后先转fp32,然后去均值,再取绝对值
def custom_preprocess(output: Output):
return ops.abs(output)
ppp = PrePostProcessor(model)
ppp.input().preprocess().convert_element_type(Type.f32).mean(1.).custom(custom_preprocess
)2.4 旧版本迁移到新版本
如果你已经使用OpenVINO做的优化加速,想迁移到新的API 2.0,因为以后开发的新特性只有2.0的API才会支持,下面以C++为例,展示一下新旧版本接口差异。
- 创建Core
Inference Engine API
InferenceEngine::Core core;OpenVINO Runtime API 2.0
ov::Core core;
- 装载模型
Inference Engine API
InferenceEngine::CNNNetwork network = core.ReadNetwork("model.xml");OpenVINO Runtime API 2.0
std::shared_ptr<ov::Model> model = core.read_model("model.xml");- 装载模型到设备
Inference Engine API
InferenceEngine::ExecutableNetwork exec_network = core.LoadNetwork(network, "CPU");OpenVINO Runtime API 2.0
ov::CompiledModel compiled_model = core.compile_model(model, "CPU");- 创建推理请求
Inference Engine API
InferenceEngine::InferRequest infer_request = exec_network.CreateInferRequest();OpenVINO Runtime API 2.0
ov::InferRequest infer_request = compiled_model.create_infer_request();- 准备输入Tensor
Inference Engine API(支持I32精度的输入,会和原始模型不一致)
InferenceEngine::Blob::Ptr input_blob1 = infer_request.GetBlob(inputs.begin()->first);
// fill first blob
InferenceEngine::MemoryBlob::Ptr minput1 = InferenceEngine::as<InferenceEngine::MemoryBlob>(input_blob1);
if (minput1) {
// locked memory holder should be alive all time while access to its
// buffer happens
auto minputHolder = minput1->wmap();
// Original I64 precision was converted to I32
auto data = minputHolder.as<InferenceEngine::PrecisionTrait<InferenceEngine::Precision::I32>::value_type*>();
// Fill data ...
InferenceEngine::Blob::Ptr input_blob2 = infer_request.GetBlob("data2");
// fill first blob
InferenceEngine::MemoryBlob::Ptr minput2 = InferenceEngine::as<InferenceEngine::MemoryBlob>(input_blob2);
if (minput2) {
// locked memory holder should be alive all time while access to its
// buffer happens
auto minputHolder = minput2->wmap();
// Original I64 precision was converted to I32
auto data = minputHolder.as<InferenceEngine::PrecisionTrait<InferenceEngine::Precision::I32>::value_type*>();
// Fill data ...
}OpenVINO Runtime API 2.0(支持I64精度,和原始模型对齐)
// Get input tensor by index
ov::Tensor input_tensor1 = infer_request.get_input_tensor(0);
// Element types, names and layouts are aligned with framework
auto data1 = input_tensor1.data<int64_t>();
// Fill first data ...
// Get input tensor by tensor name
ov::Tensor input_tensor2 = infer_request.get_tensor("data2_t");
// Element types, names and layouts are aligned with framework
auto data2 = input_tensor1.data<int64_t>();
// Fill first data ...- 启动推理
Inference Engine API
infer_request.Infer();OpenVINO Runtime API 2.0
infer_request.infer();- 处理推理结果
Inference Engine API
InferenceEngine::Blob::Ptr output_blob = infer_request.GetBlob(outputs.begin()->first);
InferenceEngine::MemoryBlob::Ptr moutput = InferenceEngine::as<InferenceEngine::MemoryBlob>(output_blob);
if (moutput) {
// locked memory holder should be alive all time while access to its
// buffer happens
auto minputHolder = moutput->rmap();
// Original I64 precision was converted to I32
auto data =
minputHolder.as<const InferenceEngine::PrecisionTrait<InferenceEngine::Precision::I32>::value_type*>();
// process output data
}OpenVINO Runtime API 2.0
// model has only one output
ov::Tensor output_tensor = infer_request.get_output_tensor();
// Element types, names and layouts are aligned with framework
auto out_data = output_tensor.data<int64_t>();
// process output data三. 模型优化
3.1 模型优化
上文提到,OpenVINO虽然支持直接装载ONNX格式,但是性能没转为IR格式更好,本节主要介绍如何将其他开源框架训练好的模型转换为IR格式。
目前支持的开源框架包括TensorFlow, PyTorch等共5种,加上对ONNX格式的支持,基本上全覆盖了当前各种需求。如下图所示,PyTorch框架可以导出onnx格式,再用OpenVINO优化加速。
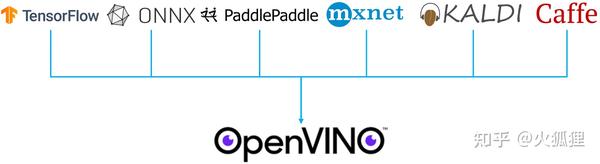
模型优化转换是一个离线转换脚本,是基于Python实现的一套工具,如果你以pip方式安装,都会有一个mo的命令,如果是Docker,发布包或源码安装,则会有个<INSTALL_DIR>/deployment_tools/model_optimizer目录,下面有个mo.py脚本。安装方式就不在这里赘述,有这方面需求的直接去看 Guide 。
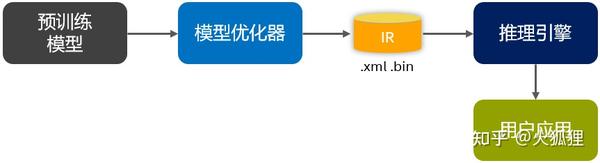
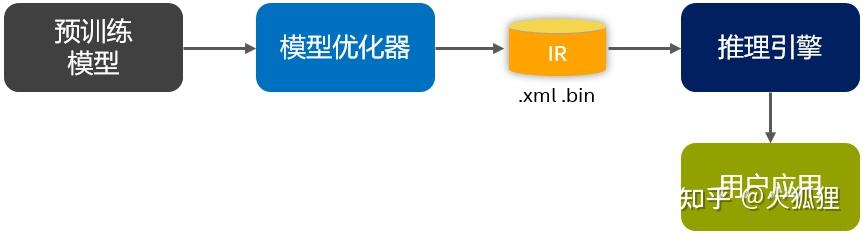
模型优化在整个流程的位置如下图蓝色部分所示:
这里仅以pip安装方式来做几个示例:
mo --input_model INPUT_MODEL --output_dir <OUTPUT_MODEL_DIR>TensorFlow模型转换
mo --input_model FaceNet.pb --input "phase_train->False" --output_dir <OUTPUT_MODEL_DIR>ONNX模型转换
mo --input_model ResNet50.onnx --input_shape [1,3,224,224] --output_dir <OUTPUT_MODEL_DIR>常用的通用参数有:
- -- input_model - 输入预训练好的模型
- -- input_shape - 指定模型输入尺寸,对于TensorFlow是NHWC,对与Caffe是NCHW
- -- mean_values - 去均值,给每个通道指定一个均值
- -- scale_values - 归一化,每个通道除一个常数
- -- data_type - 数据类型,支持FP32, FP16, half, float四种精度,根据处理器支持的情况而定
- -- batch - 批处理大小
- -- freeze_placeholder_with_value - 给某些节点赋予常数
- -- reverse_input_channels - 反转通道顺序,如从RGB反转成BGR,应用于mean_values和scale_values后面
不同框架还有Special的处理参数,详情请参考 官方说明 。
3.2 模型加密
OpenVINO的IR模型可以看到模型的网络结构,会部署在”云-边-端“模型加密和保护是一些用户场景的强需求或者痛点,尤其对于技术输出型或者解决方案供应商来说,有大量的2B或2G的业务,还会涉及到私有化部署,使用OpenVINO时的模型保护方案如下图所示:
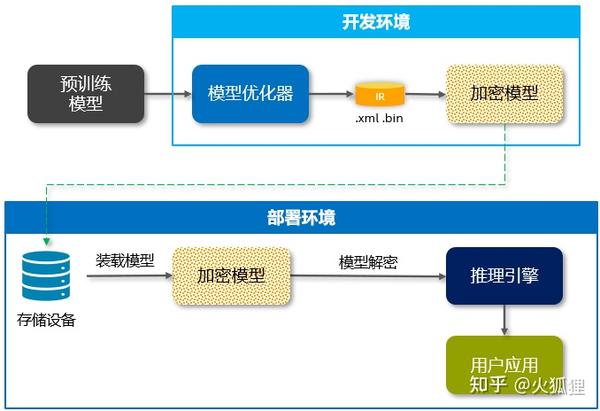
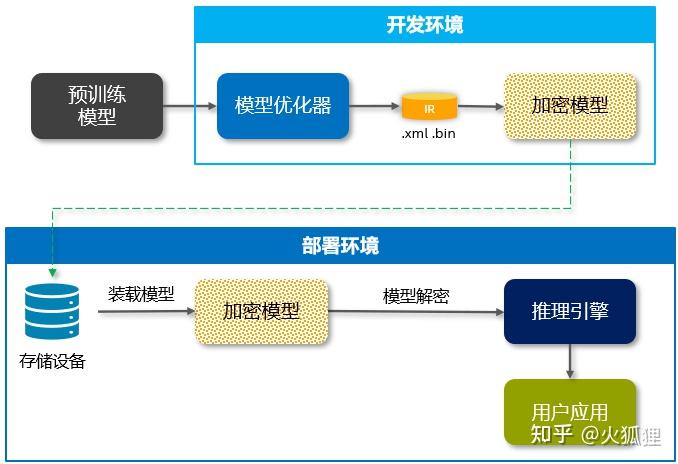
在模型开发阶段,用户可以加密自己的xml和bin文件,然后将加密后的模型落盘。在部署阶段,读盘加密的模型文件,通过用户的解密函数回复xml和bin文件,再load到OpenVINO的推理引擎里。
装载模型阶段代码如下所示:
std::vector<uint8_t> model;
std::vector<uint8_t> weights;
std::string passwd;
std::ifstream model_file("moidel.xml"), weights_file("model.bin");
// 读取模型文件,然后解密到内存空间
decrpyt_file(model_file, password, model);
decrypt_file(weight_file, password, weights);
四. 推理性能调优
4.1 推理性能指标
推理服务主要有2种模式:Latency模式和Throughput模式,如下图所示:
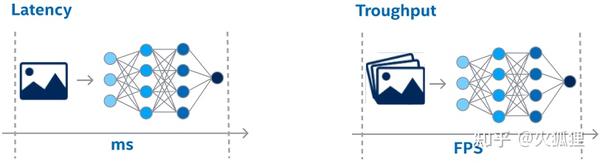

Latency模式主要用于实时处理,比如监控场景,需要实时的跟上摄像头的帧率。Throughput模式主要是非实时模式的吞吐模式,主要考核指标是每秒推理的图像数目,互联网的2C业务,一半都是吞吐率模式。
支持设备情况请参考 官方文档
4.2 性能调优
性能调优分2部分: 模型优化和引擎优化 。模型优化也有2种手段:同样精度下的模型转换优化和以可接受的精度损失的低精度推理。引擎优化主要是底层算力的选择,分配和异/同步模式。如下图所示过程。
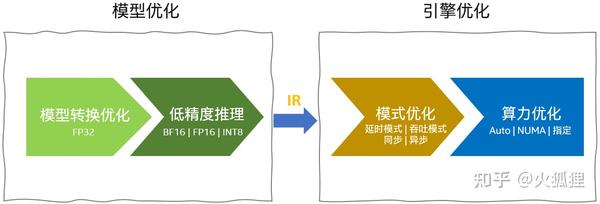

下面分别对上述优化策略进行详细介绍:
4.2.1 模型转换优化
模型转换过程可参考3.1节,这里介绍模型转换优化。
虽然2022.1版本开始支持动态输入尺寸了,但是相对于固定尺寸输入是有开销的(性能和内存),如果你的模型本身就是固定输入尺寸,就需要设定一个固定的输入,拿RN50为例,--input_shape [1,3,224,224]。
4.2.2 低精度推理
在利用低精度推理之前,想要了解清楚目标机的指令集支持情况,目前支持BF16的XEON,已经发布的有第三代CooperLake,该型号只有4路和8路服务器,一些公有云上有定制化的双路服务器。还有今年要发布的第四代XEON处理器Sapphire Rappids。BF16精度的推理不需要额外的精度矫正工作,直接转换模型时指定数据精度即可。支持FP16的比如英特尔之前的VPU神经计算棒,以及今年要发布的SG2,也只需要指定数据类型即可。
# CooperLake, Sapphire Rappids
mo --input_model INPUT_MODEL --data_type BF16
# VPU, SG2
mo --input_model INPUT_MODEL --data_type FP16而对于INT8低精度推理,则很多处理器型号都是支持的,该精度下推理需要利用一部分训练集来矫正模型的精度。所有支持INT8的设备分为2类,一类是支持 VNNI指令集 的,比如第二代XEON及以后型号,另一个是不支持的以往设备。这两类在矫正的时候的方式有微弱差别。对于支持VNNI指令集的设备,可以基于8bit来量化,否则只能按照7bit进行,否则量化出来的模型精度下降会较大,具体原因是乘累加出现溢出而导致计算偏差。具体信息大家可以了解一下 量化原理 。
量化过程如下图所示:
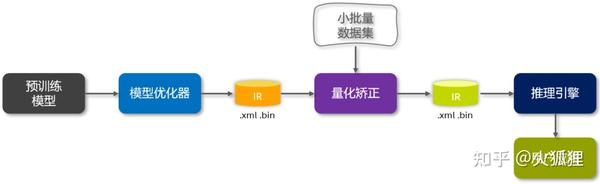

矫正数据集选择一些质量好点的,100张足够,比如做目标检测模型的量化,选一些threshold高一点的图作为矫正数据集,矫正后的模型泛化测试也是稳定的。
由于量化过程有时需要coding一下,回头单独写一篇量化实战的,此处略过。
4.2.3 模式优化
模式优化主要是业务相关,业务上要求是否要实时处理,比如视频监控,发现异常需要立即报警的,这种需要实时返回每一帧的结果,比如无人驾驶,需要实时处理道路和交通标识,有非常高的实时要求。而对于很多互联网的业务,只要在用户可忍受的时间内返回结果即可,注重大用户并发量,大吞吐率等指标。前者就要使用延时模式,否则使用吞吐模式,具体设置如下所示:
ov::Core core;
// 吞吐模式
core.set_property("CPU", ov::hint::performance_mode(ov::hint::PerformanceMode::THROUGHPUT));
// 时延模式
core.set_property("CPU", ov::hit::performance_mode(ov::hint::PerformanceMode::LATENCY));或者在模型载入设备时设置:
// 将模型装载到设备,并设置为吞吐率模式
ov::CompiledModel compiled_model = core.compile_model(model, "CPU",
ov::hint::performance_mode(ov::hint::PerformanceMode::THROUGHPUT));
// 将模型装载到设备,并设置为时延模式
ov::CompiledModel compiled_model = core.compile_model(model, "CPU",
ov::hint::performance_mode(ov::hint::PerformanceMode::LATENCY));除此之外,还可以设置处理请求的并发数,比如你要同时处理4个摄像头的视频分析,可以设置num_requests数。
auto compiled_model = core.compile_model(model, "GPU",
ov::hint::performance_mode(ov::hint::PerformanceMode::THROUGHPUT),
ov::hint::num_requests(4));4.2.4 算力优化
有时为了得到稳定的推理服务性能,需要设置推理并发实例数,这对业务来说至关重要,同时也是你在满足业务需求的前提下深度挖掘算力的有效手段。
ov::Core core;
// 设置推理实例并发数为5个
core.set_property("CPU", ov::streams::num(5));