

14.三剑客命令

1.grep命令
grep概述
Linux grep 命令用于查找文件里符合条件的字符串
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。grep语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]grep命令常见用法
-n, --line-number 在过滤出的每一行前面加上它在文件中的相对行号
-o, --only-matching 只显示匹配的内容
-q, --quiet, --silent 静默模式,没有任何输出,得用$?来判断执行成功没有,即有没有过滤到想要的内容
--color 颜色
-i, --ignore-case 忽略大小写
-A, --after-context=NUM 如果匹配成功,则将匹配行及其后n行一起打印出来
-B, --before-context=NUM 如果匹配成功,则将匹配行及其前n行一起打印出来
-C, --context=NUM 如果匹配成功,则将匹配行及其前后n行一起打印出来
-c, --count 如果匹配成功,则将匹配到的行数打印出来
-v, --invert-match 反向查找,只显示不匹配的行
-w 匹配单词
-E 等于egrep,扩展
-l, --files-with-matches 如果匹配成功,则只将文件名打印出来,失败则不打印
通常-rl一起用,grep -rl 'root' /etc
-R, -r, --recursive 递归(-r更准确一些,-R过滤出包含链接文件)
-f<规则文件> --- 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。操作例子
# 1.在文件中查找模式(单词),在/etc/passwd文件中查找单词www
[root@web01 ~]# grep www /etc/passwd
www:x:666:666::/home/www:/bin/bash
# 2.在多个文件中查找模式
[root@web01 ~]# grep www /etc/passwd /etc/shadow /etc/gshadow
/etc/passwd:www:x:666:666::/home/www:/bin/bash
/etc/shadow:www:!!:18720:0:99999:7:::
/etc/gshadow:www:!::
# 3.-l参数列出包含指定模式的文件的文件名。
[root@web01 ~]# grep -l www /etc/passwd /etc/shadow /etc/fstab /etc/mtab
/etc/passwd
/etc/shadow
# 4.-n参数,在文件中查找指定模式并显示匹配行的行号
[root@web01 ~]# grep -n www /etc/passwd
22:www:x:666:666::/home/www:/bin/bash
# 5.-v参数输出不包含指定模式的行
[root@web01 ~]# grep -v www /etc/passwd
# 6.^ 符号输出所有以某指定模式开头的行
[root@web01 ~]# grep ^root /etc/passwd
root:x:0:0:root:/root:/bin/bash
# 7.$ 符号输出所有以指定模式结尾的行
[root@web01 ~]# grep bash$ /etc/passwd
root:x:0:0:root:/root:/bin/bash
www:x:666:666::/home/www:/bin/bash
# 8.-r 参数递归地查找特定模式
[root@web01 ~]# grep -r www /etc/
/etc/grub.d/00_header:# along with GRUB. If not, see <http://www.gnu.org/licenses/>.
/etc/grub.d/10_linux:# along with GRUB. If not, see <http://www.gnu.org/licenses/>.
/etc/grub.d/20_linux_xen:# along with GRUB. If not, see <http://www.gnu.org/licenses/>.
/etc/grub.d/20_ppc_terminfo:# along with GRUB. If not, see <http://www.gnu.org/licenses/>.
/etc/grub.d/30_os-prober:# along with GRUB. If not, see <http://www.gnu.org/licenses/>.
/etc/rc.d/init.d/README: http://www.freedesktop.org/wiki/Software/systemd/Incompatibilities
/etc/virc:" http://www.linuxpowertop.org/known.php
/etc/selinux/targeted/contexts/dbus_contexts: "http://www.freedesktop.org/standards/dbus/1.0/busconfig.dtd">
...............................................................
# 9.查找文件中所有的空行
grep ^$ /etc/shadow
# 10.-e 参数查找多个模式
[root@web01 ~]# grep -e "www" -e "root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
www:x:666:666::/home/www:/bin/bash
# 11.-f 用文件指定待查找的模式
[root@web01 ~]# cat grep_pattern
bash$
[root@web01 ~]# grep -f grep_pattern /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
www:x:666:666::/home/www:/bin/bash
# 12.-c 参数计算模式匹配到的数量
[root@web01 ~]# grep -c -f grep_pattern /etc/passwd
# 13.输出匹配指定模式行的前或者后面N行
a)使用-B参数输出匹配行的前4行
[root@web01 ~]# grep -B 4 "games" /etc/passwd
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
b)使用-A参数输出匹配行的后4行
[root@web01 ~]# grep -A 4 "games" /etc/passwd
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
使用-C参数输出匹配行的前后各4行
[root@web01 ~]# grep -C 4 "games" /etc/passwd
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
# 14.打印出/etc/目录下所有文件中root的个数
[root@web03 ~]# grep -r -o -i 'root' /etc/ |wc -l
# 15.打印出/etc/目录下包含root的文件数
[root@web03 ~]# grep -ril 'root' /etc | wc -l
1082.sed命令
sed概述
sed命令: 字符流编辑工具(行编辑工具)==按照每行中的字符进行处理操作
全屏编辑工具 vi/vimsed命令作用
# 1). 擅长对行进行操作处理
# 2). 擅长将文件的内容信息进行修改调整/删除
具体功能作用:
1) 文件中添加信息的能力 (增)
2) 文件中删除信息的能力 (删)
3) 文件中修改信息的能力 (改)
4) 文件中查询信息的能力 (查)
# sed命令的语法信息
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
命令 参数 条件+处理= (指令) 处理文件信息sed命令原理图
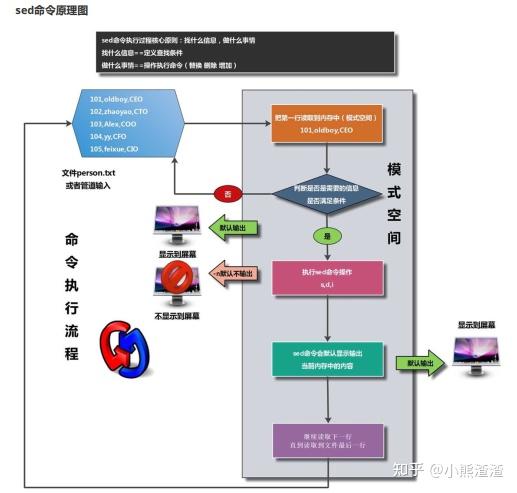
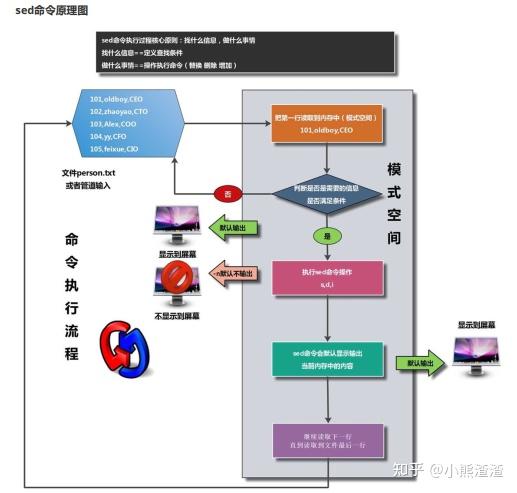
[root@web01 ~]# cat person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIOsed命令查询信息的方法
# 1.根据文件内容的行号进行查询
[root@web01 ~]# sed -n '3p' person.txt
103,allen,COO
[root@web01 ~]# sed -n '1,3p' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
[root@web01 ~]# sed -n '1p;3p' person.txt
101,kim,CEO
103,allen,COO
# 2.根据文件内容的信息进行查询
[root@web01 ~]# sed -n '/kim/p' person.txt
101,kim,CEO
[root@web01 ~]# sed -n '/kim/,/hebe/p' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
[root@web01 ~]# sed -n '/kim/p;/hebe/p' person.txt
101,kim,CEO
104,hebe,CFOsed命令添加信息的方法
# 1.默认每行都添加
[root@web01 ~]# sed 'i100,lili,UFO' person.txt
100,lili,UFO
101,kim,CEO
100,lili,UFO
102,job,CTO
100,lili,UFO
103,allen,COO
100,lili,UFO
104,hebe,CFO
100,lili,UFO
105,feifei,CIO
# 2.在第一行添加
[root@web01 ~]# sed '1i100,lili,UFO' person.txt
100,lili,UFO
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
# 3.在最后一行添加
[root@web01 ~]# sed '$a106,lili,UFO' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
106,lili,UFO
# 4.在第三行后面添加hello信息
[root@web01 ~]# sed '3ahello' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
hello
104,hebe,CFO
105,feifei,CIO
# 5.在第二行前面添加hello信息
[root@web01 ~]# sed '2ihello' person.txt
101,kim,CEO
hello
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
# 6.在有hebe行前面添加hello,后面添加world
[root@web01 ~]# sed -e '/hebe/ihello' -e '/hebe/aworld' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
hello
104,hebe,CFO
world
105,feifei,CIO
# 7.添加多行信息:sed ‘$a100\n101' person.txt
sed '$aIPaddress=10.10.10.1\nmask=255.255.255.0\ngateway=10.10.10.254' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
IPaddress=10.10.10.1
mask=255.255.255.0
gateway=10.10.10.254
# 总结:
# sed命令的指令信息
p 输出信息
i 插入信息,在指定信息前面插入新的信息
a 附加信息,在指定信息后名附加新的信息
# sed命令的参数信息
-n 取消默认输出
-r 识别扩展正则
-i 真实编辑文件(将内存中的信息覆盖到磁盘中)
-e 识别sed命令多个操作指令
# 文件中添加内容方法:
01.vim/vi
02.cat >>xxx<<EOF
03.echo -e "xxx\nxxx"
04.sed 'na/i xxxx\nxxxx\nsxxxx'sed命令删除信息方法
# 1.删除单行信息
[root@web01 ~]# sed '3d' person.txt
101,kim,CEO
102,job,CTO
104,hebe,CFO
105,feifei,CIO
# 2.删除多行信息(连续)
[root@web01 ~]# sed '2,4d' person.txt
101,kim,CEO
105,feifei,CIO
# 3.删除多行信息(不连续)
[root@web01 ~]# sed '2d;4d' person.txt
101,kim,CEO
103,allen,COO
105,feifei,CIO
# 4.删除有kim行的信息
[root@web01 ~]# sed '/kim/d' person.txt
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
# 5.利用sed命令取消空行显示
[root@web01 ~]# cat person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
[root@web01 ~]# sed -n '/^$/p' person.txt
[root@web01 ~]# sed -n '/^$/!p' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
[root@web01 ~]# sed -n '/./p' person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIOsed命令修改信息
# sed 's#原有内容#修改后内容#g' 文件信息
[root@web01 ~]# sed 's#kim##KIM#g' person.txt
sed: -e expression #1, char 8: unknown option to `s'
[root@web01 ~]# sed 's/kim/#KIM/g' person.txt
101,#KIM,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
# 1.利用sed命令取出ip地址
[root@web01 ~]# ip a s eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:27:02:75 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.7/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::8b8e:2d7:7920:1fec/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@web01 ~]# ip a s eth0|sed -n '3p'|sed -r 's#^.*net (.*)#\1#g'|sed -r 's#(.*)/24.*#\1#g'
10.0.0.7
# 将上面的命令整合
[root@web01 ~]# ip a s eth0|sed -n '3p'|sed -r 's#^.*net (.*)/24.*#\1#g'
10.0.0.7
# 再整合
sed -n '3 p'
sed -r 's#^.*net (.*)/24.*#\1#g'
sed -rn '3s#^.*net (.*)/24.*#\1#gp'
# 最终效果
[root@web01 ~]# ip a s eth0|sed -rn '3s#^.*net (.*)/24.*#\1#gp'
10.0.0.7
# 2.修改文件内容直接进行自动备份
[root@web01 ~]# sed -i.bak 's#kim#KIM#g' person.txt
[root@web01 ~]# ll
total 8
-rw-r--r-- 1 root root 66 Apr 9 20:23 person.txt
-rw-r--r-- 1 root root 66 Apr 9 19:38 person.txt.bak
[root@web01 ~]# cat person.txt
101,KIM,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
[root@web01 ~]# cat person.txt.bak
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
# 3.注意:在真实替换文件内容时候,一定不能让n和i参数同时出现
[root@web01 ~]# cat person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
[root@web01 ~]# sed -ni 's#kim#KIM#g' person.txt
[root@web01 ~]# cat person.txt
[root@web01 ~]#
# 文件内容已被清空
--------------------------------------------------------
[root@web01 ~]# sed -n 's#kim#KIM#gp' person.txt
101,KIM,CEO
[root@web01 ~]# cat person.txt
101,kim,CEO
102,job,CTO
103,allen,COO
104,hebe,CFO
105,feifei,CIO
[root@web01 ~]# sed -ni 's#kim#KIM#gp' person.txt
[root@web01 ~]# cat person.txt
101,KIM,CEO
# 4.批量修改文件的扩展名,将.txt改为.jpg
[root@web01 ~]# ls test*.txt
test01.txt test02.txt test03.txt test04.txt test05.txt test06.txt test07.txt test08.txt test09.txt test10.txt
[root@web01 ~]# ls test*.txt|sed -r 's#(.*)txt#\1#g'
test01.
test02.
test03.
test04.
test05.
test06.
test07.
test08.
test09.
test10.
[root@web01 ~]# ls test*.txt|sed -r 's#(.*)txt#\1jpg#g'
test01.jpg
test02.jpg
test03.jpg
test04.jpg
test05.jpg
test06.jpg
test07.jpg
test08.jpg
test09.jpg
test10.jpg
[root@web01 ~]# ls test*.txt|sed -r 's#(.*)txt#mv & \1jpg#g'
mv test01.txt test01.jpg
mv test02.txt test02.jpg
mv test03.txt test03.jpg
mv test04.txt test04.jpg
mv test05.txt test05.jpg
mv test06.txt test06.jpg
mv test07.txt test07.jpg
mv test08.txt test08.jpg
mv test09.txt test09.jpg
mv test10.txt test10.jpg
[root@web01 ~]# ls test*.txt|sed -r 's#(.*)txt#mv & \1jpg#g'|bash
[root@web01 ~]# ll
total 0
-rw-r--r-- 1 root root 0 Apr 9 20:44 test01.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test02.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test03.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test04.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test05.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test06.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test07.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test08.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test09.jpg
-rw-r--r-- 1 root root 0 Apr 9 20:44 test10.jpg
# 5.批量重命名专业命令: rename
rename .txt .jpg oldboy*.txt
命令 文件名称需要修改的部分信息 修改成什么信息 将什么样的文件进行修改
[root@web01 ~]# ls test* | xargs rename .jpg .txt
[root@web01 ~]# ll
total 0
-rw-r--r-- 1 root root 0 Apr 9 20:44 test01.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test02.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test03.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test04.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test05.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test06.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test07.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test08.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test09.txt
-rw-r--r-- 1 root root 0 Apr 9 20:44 test10.txt3.awk命令
①.概念说明
gawk - pattern scanning and processing language
模式扫描和处理文件语言
[root@web01 ~]# ll `which awk`
lrwxrwxrwx. 1 root root 4 Mar 3 17:36 /usr/bin/awk -> gawk②.作用说明
# 1.处理文件信息
文本文件信息
日志文件信息
配置文件信息
# 2.处理文件方式
替换信息③.语法原理
语法格式
# 1.标准格式
awk [选项] '模式{动作}' [文件信息]
# 2.模式说明(匹配信息)
1.普通模式
正则表达式作为普通模式:
* ^可以表示某一列的开始,$表示某一列的结尾
awk '/^Li/{print xx}'
* 利用比较模式匹配信息:
NR==2
NR>=2
NR<=2
NR==2,NR==10
--------------------------------------------------
2.特殊模式
* BEGIN{}:
概念说明:括号里面内容会在awk读取文件之前执行
[root@web01 ~]# awk 'BEGIN{print "姓","名","QQ号","捐款记录"}{print $0}' awk_test.txt |column -t
姓 名 QQ号 捐款记录
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 39032015 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Li Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Da Nanhai 918391635 :250:100:175
作用说明:用于测试,计算及修改内置变量
[root@web01 ~]# awk 'BEGIN{print 5/3}'
1.66667
[root@web01 ~]# awk 'BEGIN{print 5+3}'
[root@web01 ~]# awk 'BEGIN{print 5-3}'
修改内置分隔符变量:
awk -F ":" '{print $2}' awk_test.txt ==》awk 'BEGIN{FS=":"}{print $2}' awk_test.txt
* END{}:
概念说明:括号里面的内容会在awk读取文件之后执行
awk '{print $0}END{print "end of file"}' reg.txt
作用说明:用于计算及显示计算最终结果
# 3.内置变量
1.FS(field separator):字符分隔符变量
-F ":" == BEGIN{FS=":"} == -vFS=":"
2.NR(number records):表示行号信息
3.NF(number of fields):表示每一行有多少列命令执行过程
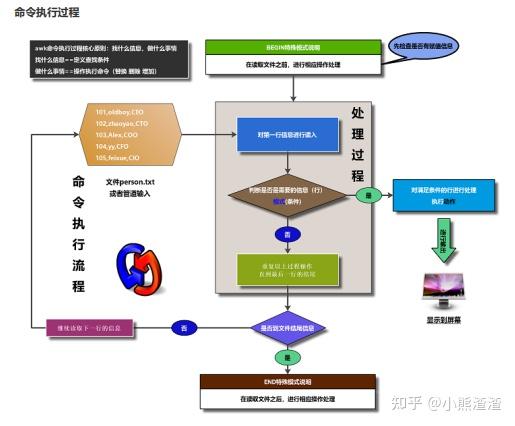
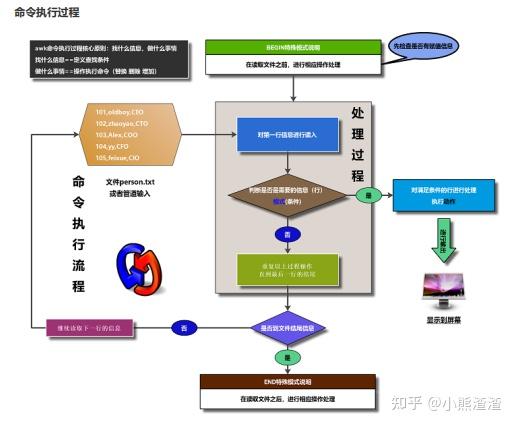
④.实践操作
实践环境
[root@web01 ~]# cat awk_test.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 39032015 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Li Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Da Nanhai 918391635 :250:100:175信息查询
# 1.awk命令查找参数
-F "":指定列的分隔符号(参数)
NR==:显示指定行号信息(模式)
print gsub:显示指定列的信息(动作)
# 其他格式
~:在awk中表示匹配或者包含什么信息
awk '$3~/0+/' reg.txt
!~:在awk中表示不匹配或者不包含什么信息
# 2.按照字符查询信息
[root@web01 ~]# awk '/Xiaoai/' awk_test.txt
Wang Xiaoai 3515064655 :50:95:135
[root@web01 ~]# awk '/Xiaoai/,/Youjiu/' awk_test.txt
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
[root@web01 ~]# awk '/Xiaoai/;/Youjiu/' awk_test.txt
Wang Xiaoai 3515064655 :50:95:135
Li Youjiu 918391635 :175:75:300
# 3.按行查询信息
[root@web01 ~]# awk 'NR==2' awk_test.txt
Zhang Xiaoyu 390320151 :155:90:201
[root@web01 ~]# awk 'NR==2,NR==4' awk_test.txt
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
[root@web01 ~]# awk 'NR==2;NR==4' awk_test.txt
Zhang Xiaoyu 390320151 :155:90:201
Wu Waiwai 70271111 :250:80:75
# 3.按列查询信息
[root@web01 ~]# awk '{print $1}' awk_test.txt
Zhang
Zhang
[root@web01 ~]# awk '{print $1 $3}' awk_test.txt
Zhang41117397
Zhang390320151
Meng80042789
Wu70271111
Liu41117483
Wang3515064655
Zi1986787350
Li918391635
Da918391635
[root@web01 ~]# awk '{print $1,$3}' awk_test.txt
Zhang 41117397
Zhang 390320151
Meng 80042789
Wu 70271111
Liu 41117483
Wang 3515064655
Zi 1986787350
Li 918391635
Da 918391635
[root@web01 ~]# awk '{print $1','$3}' awk_test.txt
Zhang 41117397
Zhang 390320151
Meng 80042789
Wu 70271111
Liu 41117483
Wang 3515064655
Zi 1986787350
Li 918391635
Da 918391635
[root@web01 ~]# awk '{print $1","$3}' awk_test.txt
Zhang,41117397
Zhang,390320151
Meng,80042789
Wu,70271111
Liu,41117483
Wang,3515064655
Zi,1986787350
Li,918391635
Da,918391635组合使用
# 1.显示xiaoyu的姓氏和ID号码
[root@web01 ~]# awk '/Xiaoyu/{print $1","$3}' awk_test.txt
Zhang,390320151
# 2.姓氏是zhang的人,显示他的第二次捐款金额及他的名字
[root@web01 ~]# awk '/Zhang/{print $2,$4}' awk_test.txt |awk -F ":" '{print $1","$3}'
Dandan ,100
Xiaoyu ,90
# 3.将上面的命令整合,同时以空格和:作为分隔符
[root@web01 ~]# awk -F "[ :]+" '/^Zhang/{print $1","$2","$(NF-1)}' awk_test.txt
Zhang,Dandan,100
Zhang,Xiaoyu,90
# 注意:以空格作为分隔符,空格的个数不确定,故需加+号;NF表示为最后一行,NF-1为倒数第二行
# 4.显示所有以41开头的ID号码的人的全名和ID号码
[root@web01 ~]# awk '$3~/^41/{print $1,$2,$3}' awk_test.txt
Zhang Dandan 41117397
Li Bingbing 41117483
# 5.显示所有ID号码最后一位数字是1或5的人的全名
[root@web01 ~]# awk '$3~/1$|5$/{print $1,$2}' awk_test.txt
Zhang Xiaoyu
Wu Waiwai
Wang Xiaoai
Li Youjiu
Da Nanhai
[root@web01 ~]# awk '$3~/1$|5$/{print $1,$2}' awk_test.txt|column -t
Zhang Xiaoyu
Wu Waiwai
Wang Xiaoai
Li Youjiu
Da Nanhai
[root@web01 ~]# awk '$3~/[15]$/{print $1,$2}' awk_test.txt|column -t
Zhang Xiaoyu
Wu Waiwai
Wang Xiaoai
Li Youjiu
Da Nanhai
[root@web01 ~]# awk '$3~/(1|5)$/{print $1,$2}' awk_test.txt|column -t
Zhang Xiaoyu
Wu Waiwai
Wang Xiaoai
Li Youjiu
Da Nanhai
# 6.显示Xiaoyu的捐款,每个钱数前面都有以$开头, 如$110$220$330
[root@web01 ~]# awk '$2~/Xiaoyu/{gsub(/:/,"$",$NF);print $NF}' awk_test.txt
$155$90$201
[root@web01 ~]# awk '$2~/Xiaoyu/{gsub(/:/,"$",$NF);print $0}' awk_test.txt
Zhang Xiaoyu 39032015 $155$90$201
# 注:gsub是一个函数
gsub(/需要替换的信息/,"修改成什么信息",将哪列信息进行修改)文件中空行进/注释行排除
1.grep -Ev "^#|^$" 文件信息
2.sed -n '/^#|^$/!p' 文件信息
3.awk '!/^#|^$/
[root@web01 ~]# awk '$0~/^#|^$/' awk_test.txt
#Liu Bingbing 41117483 :250:100:175
[root@web01 ~]# awk '$0!~/^#|^$/' awk_test.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300总结
$1 $2 $3 : 取第几列信息
$NF : 取最后一列
$(NF-n) : 取倒数第几列
$0 : 取所有列的信息
# 如何利用awk取出IP地址信息:
ip a s eth0|awk -F "[ /]+" 'NR==3{print $5}'
hostname -i⑤.awk数组
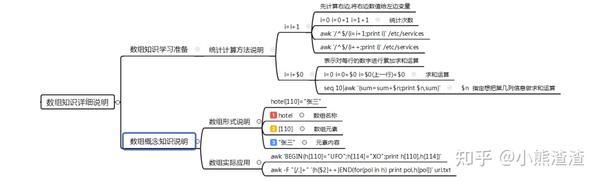
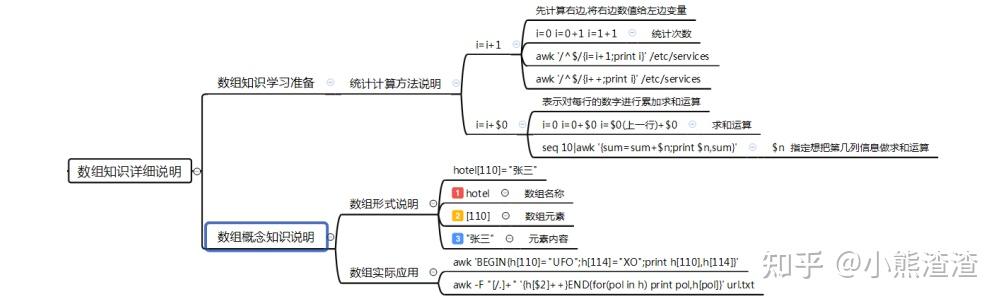
# 1. 统计/etc/services文件中有井号开头的行
[root@web01 ~]# awk '/^#/{i++}END{print i}' /etc/services
# 2.统计系统中有多少个虚拟用户 普通用户
普通用户:
[root@web01 ~]# awk '$NF~/bash/{i=i+1}END{print i}' /etc/passwd
虚拟用户:
[root@web01 ~]# awk '$NF!~/bash/{i=i+1}END{print i}' /etc/passwd
# 3.求和运算:sum=sum+$n(需要进行数值求和的列)
[root@web01 ~]# seq 10|awk '{sum=sum+$1;print sum}'
554.习题1
1、找出/proc/meminfo文件中以s开头的行,至少用三种方式忽略大小写
grep -i '^s' /proc/meminfo
egrep '^s|^S' /proc/meminfo
sed -nr '/^[sS]/p' /proc/meminfo
awk '/^[sS]/' /proc/meminfo
2、显示当前系统上的root,centos或者user的信息
3、找出/etc/init.d/function文件下包含小括号的行
egrep '\(|\)' /etc/init.d/functions
grep -E '(\(.*\))' /etc/init.d/functions
4、输出指定目录的基名
ls /etc | awk -F "/" '{print $NF}'
5、找出网卡信息中包含的数字
ip a | grep -oE '[0-9]+'
6.找出/etc/passwd下每种解析器的用户个数
#!/bin/bash
declare -A arrary
while read line
res=`echo $line |awk -F: '{print $NF}'`
let arrary[$res]++
done < 1.txt
for i in ${!arrary[*]}
echo $i:${arrary[$i]}
awk -F: '{print $NF}' /etc/passwd | sort | uniq -c
awk -F: '{num[$NF]++}END{for (i in num){printf "%-15s : %s\n",i,num[i]}}' /etc/passwd
7、过去网卡中的ip,用三种方式实现
ip a |grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}
8、搜索/etc目录下,所有的.html或.php文件中main函数出现的次数
find ./ -name "*.html" -o -name "*.php" -exec grep -R "main" {} \;
9、过滤php.ini中注释的行和空行
grep -vE '^$|^#' /etc/php.ini
grep -E "^[^#]" /etc/php.ini
10、找出文件中至少有一个空格的行
egrep '\ +' /etc/passwd
11、过滤文件中以#开头的行,后面至少有一个空格
grep -E '^#\ +' /etc/fstab
12、查询出/etc目录中包含多少个root
egrep -Ro 'root' /etc/| wc -L
13、查询出所有的qq邮箱
grep -Er "[0-9a-zA-Z-_\.]+\@qq\.com" wyr.txt
14、查询系统日志中所有的error
grep -iE 'error' /var/log/message
15、删除某文件中以s开头的行的最后一个词
grep -E '^s' 9.txt | sed -r 's/[0-9a-zA-Z]+$//g'
16、删除一个文件中的所有数学
sed -r 's/[0-9]+//g' 9.txt
17、显示奇数行
sed -n '1~2p' /etc/passwd
awk '{if (NR%2){print $0}}' /etc/passwd
awk 'BEGIN{count=1}{if(count%2==1){print $0};count++}' a.txt
18、删除passwd文件中以bin开头的行到nobody开头的行
sed -n '/^bin/,/^nobody/d' /etc/passwd
19、从指定行开始,每隔两行显示一次
awk -F: '{if(NR>3){num=(NR-3)%2; if(num){print $0}}}' /etc/passwd
20、每隔5行打印一个空格
awk 'BEGIN{count=1}{print $0;if(count%5==0){print " "};count++}' a.txt
awk -F: '{print $0;num=NR%5;if(!num){print ""}}' /etc/passwd
21、不显示指定字符的行
grep -v 'root' /etc/passwd
22、将文件中1到5行中aaa替换成AAA
sed -r '1,5s/aaa/AAA/g' a.txt
23、显示用户id为奇数的行
awk -F: '{if($3%2==1){print $0}}' /etc/passwd
awk -F: '{if($3%2){print $0}}' /etc/passwd
24、显示系统普通用户,并打印系统用户名和id
awk -F: '{if($3>1000){print $1","$3}}' /etc/passwd
25、统计nginx日志中访问量(ip唯独计算)
grep -Ec '([0-9]{1,3}\.){3}[0-9]{1,3}' /var/log/nginx/access.log
26、实时打印nginx的访问ip
tail -f /var/log/nginx/access.log | grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}'
27、统计php.ini中每个词的个数
grep -Eow '[0-9a-zA-Z]+' /etc/php.ini | awk '{words[$1]++}END{for (i in words){print i,words[i]}}'
28.统计1分钟内访问nginx次数超过10次的ip
#!/bin/bash
NGINX_LOG=/var/log/nginx/access.log
TIME=`date +%s`
DATE=`echo $TIME - 3600 | bc`
declare -A IP
while read line
timestamp=`echo $line | grep -oE '[0-9]{4}.*T[0-9]{2}:[0-9]{2}:[0-9]{2}'`
timestamp=`date -d "$timestamp" +%s`
if (( $TIME >= $timestamp && $DATE <= $timestamp ));then
ip=`echo $line| grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}'`
number=`echo ${IP["$ip"]} | wc -L`
[ $number -eq 0 ] && IP["$ip"]=0
num=${IP["$ip"]}
IP["$ip"]=`echo "$num + 1" | bc`
done < $NGINX_LOG
for i in ${!IP[*]}
if (( ${IP[$i]} >= 10 ));then
echo $i
while read line
timestamp=`echo $line | grep -oE '[0-9]{4}.*T[0-9]{2}:[0-9]{2}:[0-9]{2}'`
timestamp=`date -d "$timestamp" +%Y%m%d%H`
number=`echo ${IP["$timestamp"]} | wc -L`
[ $number -eq 0 ] && IP["$timestamp"]=0
num=${IP["$timestamp"]}
IP["$timestamp"]=`echo "$num + 1" | bc`
done < $NGINX_LOG
for i in ${!IP[*]}
if (( ${IP[$i]} >= 10 ));then
echo "$i ${IP[$i]}"
30、统计访问nginx前10的ip
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr -k1 | head -n 10
awk '{ print $1}':取数据的低1域(第1列)
sort:对IP部分进行排序。
uniq -c:打印每一重复行出现的次数。(并去掉重复行)
sort -nr -k1:按照重复行出现的次序倒序排列,-k1以第一列为标准排序。
head -n 10:取排在前5位的IP 。
grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}' /var/log/nginx/access.log | sort | uniq -c | sort -r | head5.习题2
1、显示/proc/meminfo文件中以不区分大小的s开头的行
[root@www1 ~]# grep -i "^s" /proc/meminfo
SwapCached: 0 kB
SwapTotal: 1048572 kB
SwapFree: 1048572 kB
Shmem: 9788 kB
Slab: 65684 kB
SReclaimable: 34188 kB
SUnreclaim: 31496 kB
2、显示/etc/passwd中以nologin结尾的行
[root@www1 ~]# grep -i "nologin$" /etc/passwd
3、显示/etc/inittab中以#开头,且后面跟一个或多个空白字符,而后又跟了任意字符的行
grep -E "^\ *#\ +[^ ]" 1.txt
4、显示/etc/passwd中包含了:一个数字:(即两个冒号中间一个数字)的行
[root@www1 ~]# grep -E ":[0-9]:" /etc/passwd
5、显示/boot/grub/grub.conf文件中以一个或多个空白字符开头的行
grep -E "\ +" 2.txt
6、显示/etc/inittab文件中以一个数字开头并以一个与开头数字相同的数字结尾的行
grep -E "(^[0-9]).*\1$" 3.txt
7、ip a命令可以显示当前主机的IP地址相关的信息等,要求不包括127.0.0.1
ip a | grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}" | grep -v "127.0.0.1"
8、显示/etc/sysconfig/network-scripts/ifcfg-eth0文件中的包含了类似IP地址点分十进制数字格式的行
grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}" /etc/sysconfig/network-scripts/ifcfg-eth0
9、删除配置文件中用井号#注释的行
grep -Ev "^\ *#" 3.txt
sed -r -i '/^\ *#/d' 3.txt
10、删除配置文件中用双斜杠//注释的行
sed -r -i "/^\ *\/\//d" 3.txt
11、删除无内容空行
grep -Ev "^$" 5.txt
sed -i "/^$/d" 5.txt
12、删除#号注释和无内容的空行
grep -Ev "^$" 5.txt | grep -Ev "^\ *#"
grep -Ev "^$|^\ *#" 5.txt
13、追加一行,\可有可无,有更清晰
sed -i '$a\fsdfsdagdfbsdfbja' 5.txt
14.给文件每行加注释
[root@www1 ~]# cat 3.txt
daasdg
,fdgsfg
.dsgagf
;';'.dsdafag
[root@www1 ~]# sed -i -r 's/^/#/' 3.txt
[root@www1 ~]# cat 3.txt
#daasdg
#,fdgsfg
#.dsgagf
#;';'.dsdafag
15、给指定行加注释
[root@www1 ~]# sed -i '3s/^/#/' 3.txt
[root@www1 ~]# cat 3.txt
#daasdg
##,fdgsfg
#.dsgagf
#;';'.dsdafag
16、取得网卡IP(除ipv6以外的所有IP)
ip a | grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}"
17、获得内存使用情况(算出百分比)
[root@www1 ~]# free -m | awk '{if(/Mem/){total=$2; free=$4}}END{print free/total*100}'
71.2121
18、获得磁盘使用情况
[root@www1 ~]# df -h | grep -E "\/$" | awk '{print $(NF-1)}'
19、打印出/etc/hosts文件的最后一个字段(按空格分隔)
[root@www1 ~]# awk '{print $NF}' /etc/hosts
localhost4.localdomain4
localhost6.localdomain6
www.baidu.com