


强化学习AC、A2C、A3C算法原理与实现!

作者:石晓文 Python爱好者社区专栏作者
个人公众号:小小挖掘机 添加微信sxw2251,可以拉你进入小小挖掘机技术交流群哟!
博客专栏: wenwen
跟着李宏毅老师的视频,复习了下AC算法,新学习了下A2C算法和A3C算法,本文就跟大家一起分享下这三个算法的原理及tensorflow的简单实现。
视频地址: https://www. bilibili.com/video/av24 724071/?p=4
1、PG算法回顾
在PG算法中,我们的Agent又被称为Actor,Actor对于一个特定的任务,都有自己的一个策略π,策略π通常用一个神经网络表示,其参数为θ。从一个特定的状态state出发,一直到任务的结束,被称为一个完整的eposide,在每一步,我们都能获得一个奖励r,一个完整的任务所获得的最终奖励被称为R。这样,一个有T个时刻的eposide,Actor不断与环境交互,形成如下的序列τ:
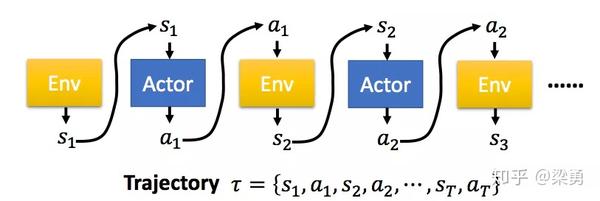
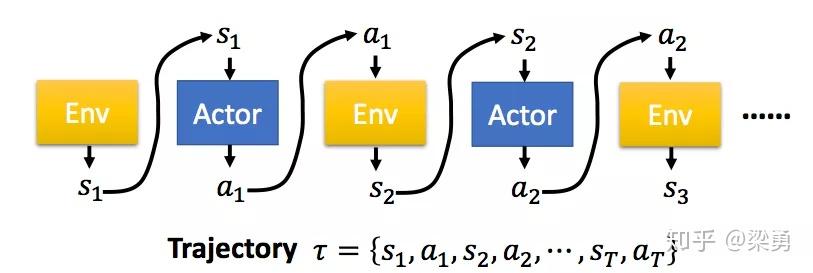
这样一个序列τ是不确定的,因为Actor在不同state下所采取的action可能是不同的,一个序列τ发生的概率为:
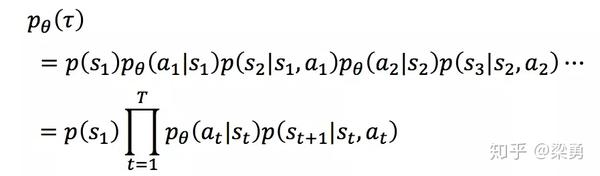
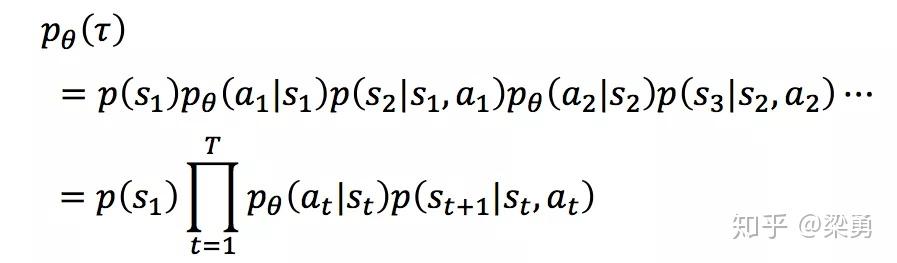
序列τ所获得的奖励为每个阶段所得到的奖励的和,称为R(τ)。因此,在Actor的策略为π的情况下,所能获得的期望奖励为:
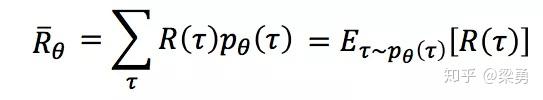
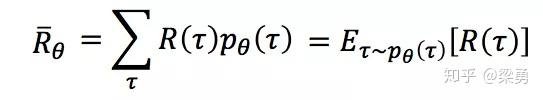
而我们的期望是调整Actor的策略π,使得期望奖励最大化,于是我们有了策略梯度的方法,既然我们的期望函数已经有了,我们只要使用梯度提升的方法更新我们的网络参数θ(即更新策略π)就好了,所以问题的重点变为了求参数的梯度。梯度的求解过程如下:


上面的过程中,我们首先利用log函数求导的特点进行转化,随后用N次采样的平均值来近似期望,最后,我们将pθ展开,将与θ无关的项去掉,即得到了最终的结果。
所以,一个PG方法的完整过程如下:
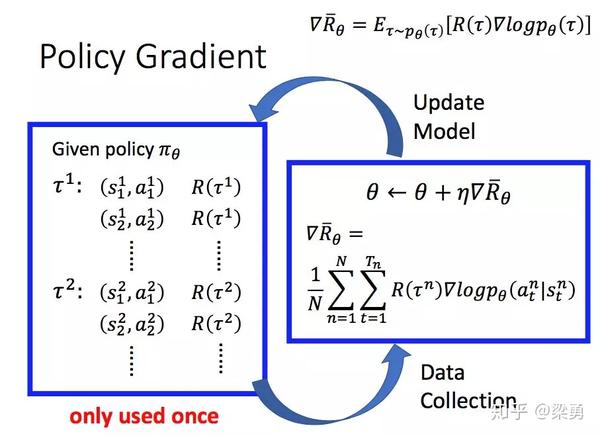
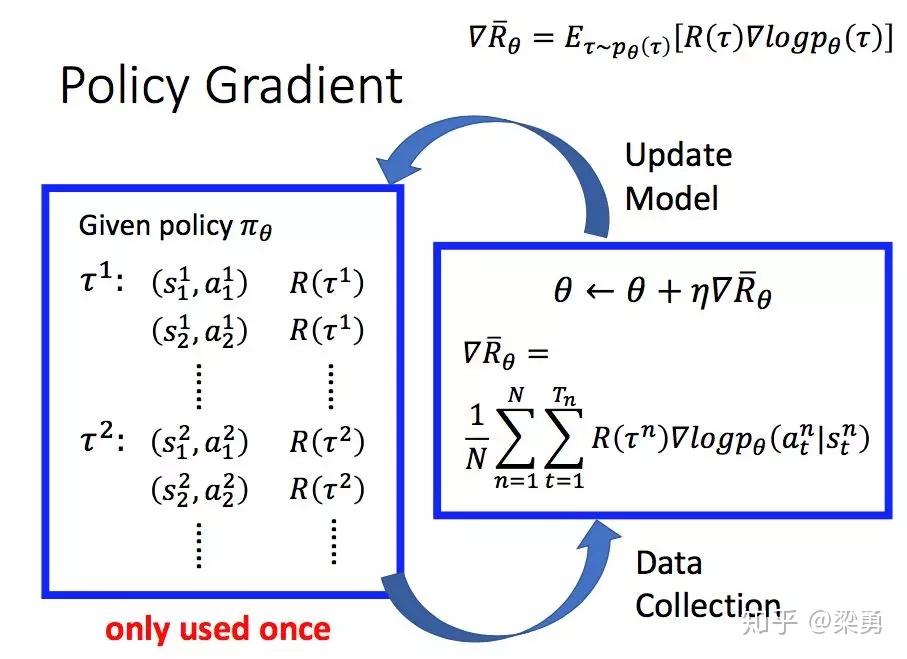
我们首先采集数据,然后基于前面得到的梯度提升的式子更新参数,随后再根据更新后的策略再采集数据,再更新参数,如此循环进行。注意到图中的大红字only used once,因为在更新参数后,我们的策略已经变了,而先前的数据是基于更新参数前的策略得到的。
2、Actor-Critic(AC)
在PG策略中,如果我们用Q函数来代替R,同时我们创建一个Critic网络来计算Q函数值,那么我们就得到了Actor-Critic方法。Actor参数的梯度变为:
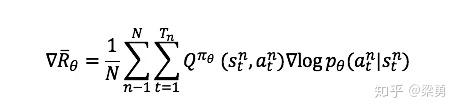
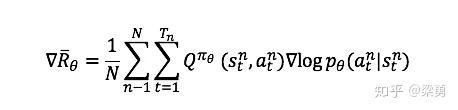
此时的Critic根据估计的Q值和实际Q值的平方误差进行更新,对Critic来说,其loss为:
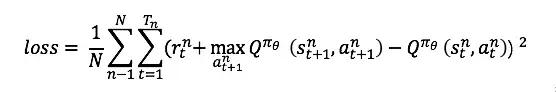
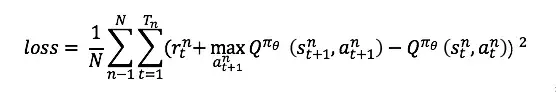
AC代码的实现地址为: https:// github.com/princewen/te nsorflow_practice/tree/master/RL/Basic-AC-Demo
3、Advantage Actor-Critic(A2C)
我们常常给Q值增加一个基线,使得反馈有正有负,这里的基线通常用状态的价值函数来表示,因此梯度就变为了:
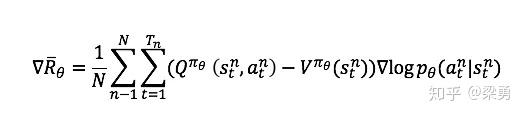
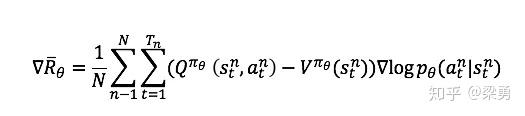
但是,这样的话我们需要有两个网络分别计算状态-动作价值Q和状态价值V,因此我们做这样的转换:
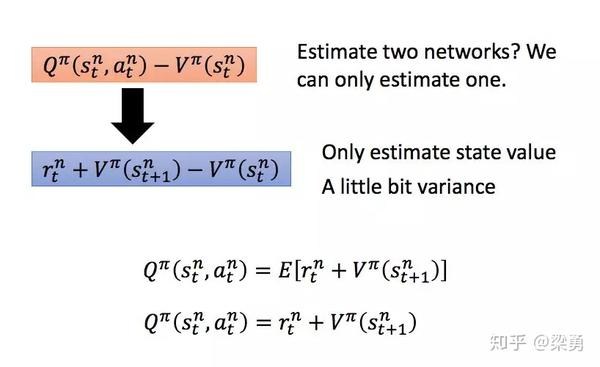
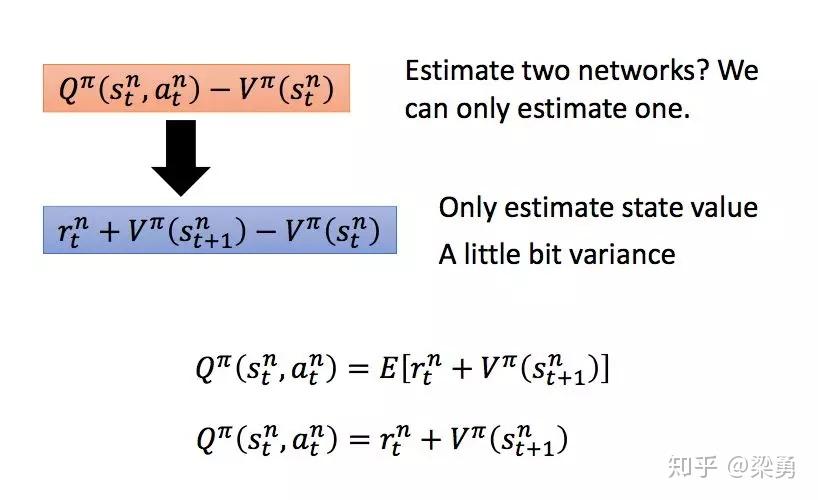
这样会是增加一定的方差,不过可以忽略不计,这样我们就得到了Advantage Actor-Critic方法,此时的Critic变为估计状态价值V的网络。因此Critic网络的损失变为实际的状态价值和估计的状态价值的平方损失:
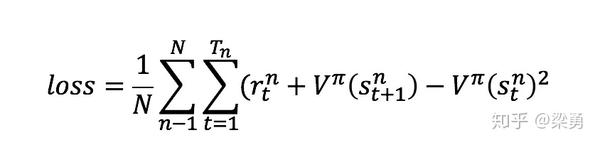
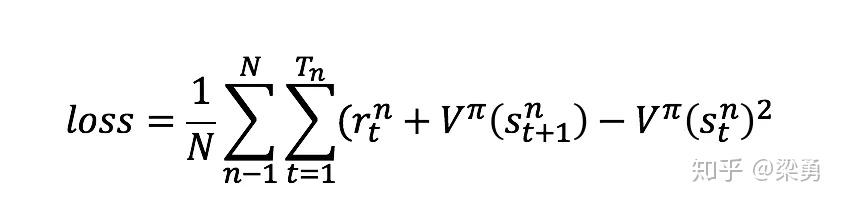
A2C代码的实现地址为: https:// github.com/princewen/te nsorflow_practice/tree/master/RL/Basic-A2C-Demo
4、Asynchronous Advantage Actor-Critic (A3C)
我们都知道,直接更新策略的方法,其迭代速度都是非常慢的,为了充分利用计算资源,又有了Asynchronous Advantage Actor-Critic 方法,拿火影的例子来说,鸣人想要修炼螺旋手里剑,但是时间紧迫,因此制造了1000个影分身,这样它的学习速度也可以提升500倍:


A3C的模型如下图所示:
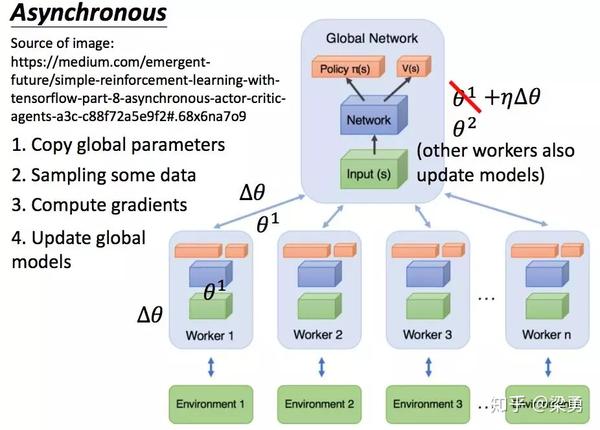

可以看到,我们有一个主网络,还有许多Worker,每一个Worker也是一个A2C的net,A3C主要有两个操作,一个是pull,一个是push:
pull:把主网络的参数直接赋予Worker中的网络
push:使用各Worker中的梯度,对主网络的参数进行更新
A3C代码的实现地址为: https:// github.com/princewen/te nsorflow_practice/tree/master/RL/Basic-A3C-Demo
推荐阅读:强化学习系列
