

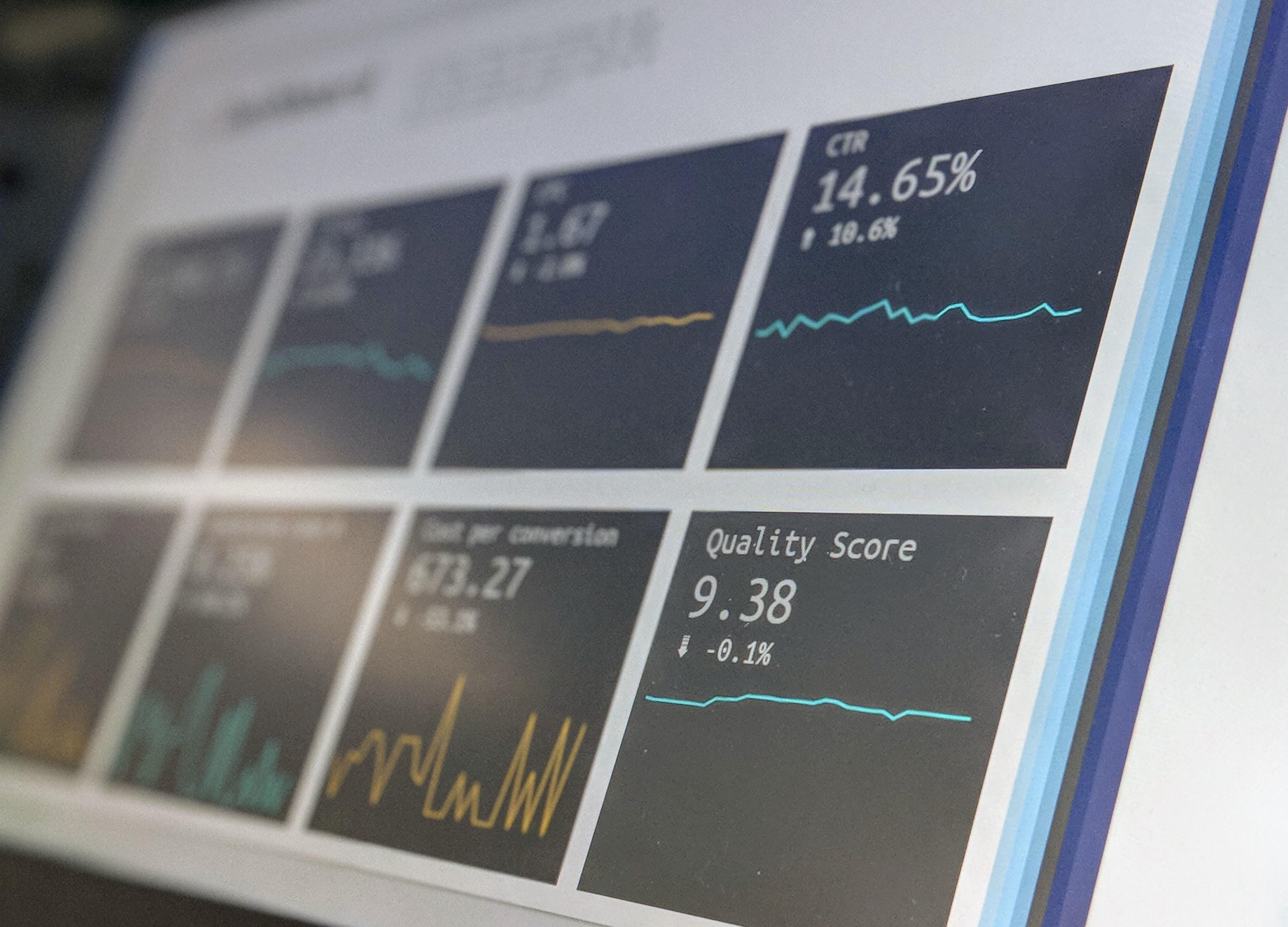
如何用 Pandas 存取和交换数据?


本文为你介绍 Pandas 存取数据的3种主要格式,以及使用中的注意事项。
问题
在数据分析的过程里,你已经体会到 Python 生态系统的强大了吧?
数据采集、整理、可视化、统计分析……一直到深度学习,都有相应的 Python 包支持。
但是你会发现,没有任何一个 Python 软件包,是全能的。
这是一种非常好的设计思维——用优秀的工具,做 专业 的事儿;用许多优秀工具组成的 系统 ,来有条不紊地处理 复杂问题 。
所以,在这个过程中,你大概率会经常遇到数据的 交换 问题。
有时候,是把分析结果存起来,下次读取回来继续使用。
更重要的时候,是把一个工具的分析结果导出,导入到另一个工具包中。
这些数据存取的功能,几乎分布在每一个 Python 数据科学软件包之内。
但是,其中有一个最重要的枢纽,那就是 Pandas 。


我不止一次跟你提起过,学好 Pandas 的 重要性 。
很多情况下,看似复杂的数据整理与可视化,Pandas 只需要一行语句就能搞定。
回顾我们的教程里,也曾使用过各种不同的格式读取数据到 Pandas 进行处理。
然而,当你需要 自己独立 面对软件包的格式要求时,也许仅仅是因为不了解如何正确生成或读取某种格式,结果导致出错,甚至会使你丧失探索的信心与兴趣。
这篇教程里,我以咱们介绍过多次的情感分类数据作为例子,用 最小化的数据集 ,详细为你介绍若干种常见的存取数据格式。
有了这些知识与技能储备,你就可以应对大多数同类数据分析问题的场景了。
环境
为了方便你完整重现我教程中的代码,我使用 Google Colab 撰写和运行,并且存储副本到了 Github 里面。
请在我的公众号“玉树芝兰”(nkwangshuyi)后台输入“export”,就可以获得本教程相应的 Github 链接,以及代码运行环境的使用说明了。
数据
为了尽量简化问题,我们这里手动输入两条文本,构建一个 超小型 的评论情感数据集。
str1 = "这是个好电影,\n我喜欢!"
str2 = "这部剧的\t第八季\t糟透了!"
(猜猜看,其中
str2
里面的“这部剧”是哪一部?)
你看到了,这里我加了一些特殊符号进去。
其中:
-
\n:换行符。有时候原始评论是分段的,所以出现它很正常; -
\t:制表符。对应键盘上的 Tab 键,一般在代码里用于 缩进 。用在评论句子中其实很奇怪。这里只是举个例子,下文你会看到它的特殊性。
我们打印一下两个字符串,看是否正确输入:
print(str1)
这是个好电影,
换行符正确显示了。下面我们看看制表符。
print(str2)
这部剧的 第八季 糟透了!
好了,下面我们分别赋予两句话情感标记,然后用 Pandas 构建数据框。
import pandas as pd
我们建立了一个
字典
(dict),分别将文本和标记列表放到
text
和
label
下面。然后,用 Pandas 的默认构建方式,自动将其转化为
数据框
(Dataframe)。
df = pd.DataFrame({'text': [str1, str2], 'label': [1, 0]})
显示效果如下:


好了,数据已经正确存储到 Pandas 里面了。下面我们分别看看几种输出格式如何导出,以及它们的特点和常见问题。
CSV/TSV
我们来看最常见的两种格式,分别是:
-
csv:逗号分隔数据文本文件; -
tsv:制表符分隔数据文本文件;
先尝试把 Pandas 数据框导出为 csv 文件。
df.to_csv('data.csv', index=None)
注意这里我们使用了一个
index=None
参数。
回顾刚才的输出:


上图中标红色的地方,就是索引(index)。如果我们不加入
index=None
参数说明,那么这些数值型索引也会一起写到 csv 文件里面去。对我们来说,这没有必要,会白白占用存储空间。
将生成的 csv 文件拖入文本编辑器内,效果如下:


你可以清楚地看到, 逗号 分割了表头和数据。
有意思的是,因为第一句评论里包含了换行符,所以就真的记录到两行上面。而文本的两端,有 引号包裹 。
第二句话,制表符(缩进)也是正确显示了。但是这句话两端,却 没有引号 。
这么乱七八糟的结果,Pandas 还能够正确读回来吗?
我们试试看。
pd.read_csv('data.csv')


一切正常。
看来,在读取 csv 的过程里,Pandas 还是很有 适应能力 的。
下面我们来看看颇为类似的 tsv 格式。
Pandas 并不提供一个单独的
to_tsv
选项。我们依然需要利用
to_csv
方法。
只不过,这次我们添加一个参数
sep='\t'
。
df.to_csv('data.tsv', index=None, sep='\t')
生成的文件名为
data.tsv
。我们还是在编辑器里面打开它看看。
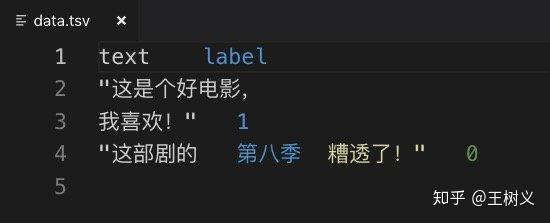
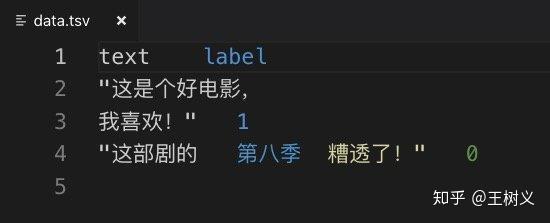
对比一下刚刚的 csv 格式,你发现了什么?
大体上二者差不多。
只是逗号都变成了制表符缩进而已。
但是不知你是否发现,第二句话此时也被引号包裹起来了。
为什么呢?
对,因为这句话里面含有制表符。如果不包裹,读取的时候可就要出问题了。程序就会傻乎乎地把 “第八季” 当成标记,扔掉后面的内容了。
你看现在编辑器的着色,实际上已经错误判断分列了。


我们试着用 Pandas 把它读取回来。
注意,这里我们依然指定了,分割符是
sep='\t'
。
pd.read_csv('data.tsv', sep='\t')
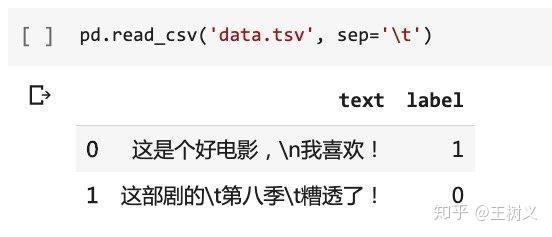
没有差别,效果依然很好。
这两种数据导出格式,非常直观简洁,用文本编辑器就可以打开查看。而且导出读取都很方便。
这是不是意味着,我们只要会用这两种格式就可以了呢?
别忙,我们再来看一个使用案例。
在处理中文文本信息时,我们经常需要做的一件事情,就是 分词 。
这里,我们把之前两句话进行分词后,再尝试保存和读取。
为了分词,我们先安装一个 jieba分词 包。
!pip install jieba
然后把它读取进来。
import jieba
前面我们给自己挖了个坑——为了说明特殊符号的存储,我们加了换行符和制表符。现在问题来了,分词之后,我们肯定不想要这些符号。
怎么办呢?
我们来编写一个定制化的分词函数就好了。
这个函数里,我们分别清除掉制表符和换行符,然后再用结巴分词切割。分词这里,我们用的是 默认参数 。
因为分词后的结果实际上是个生成器(generator),而我们是需要真正的列表(list)的,所以利用
list
函数强制转换分词结果成为列表。
def cleancut(s):
s = s.replace('\t', '')
s = s.replace('\n', '')
return list(jieba.cut(s))
我们生成一个新的数据框
df_list
,克隆原先的
df
。
df_list = df.copy()
然后,我们把分词的结果,存到新的数据框
df_list
的
text
列上面。
df_list.text = df.text.apply(cleancut)
看看分词后的效果:
df_list


怎么证明
text
上存储的确实是个列表呢?
我们来读取一下其中的第一个元素好了。
df_list.text.iloc[0][0]
结果显示为:
'这'
很好。此时的数据框可以正确存储预处理(分词)的结果。
下面我们还是仿照原先的方式,把这个处理结果数据导出,然后再导入。
先尝试 csv 格式。
df_list.to_csv('data_list.csv', index=None)
导出过程一切正常。
我们来看看生成的 csv 文件。


在存储的过程中,列表内部,每个元素都用 单引号 包裹。整体列表的外部,被 双引号 包裹。
至于分割符嘛,依然是 逗号 。
看着是不是很正常?
我们来尝试把它读取回来。当然我们希望读取回来的格式,跟当时导出的 一模一样 。
pd.read_csv('data_list.csv')
结果是这样的:


初看起来,很好啊!
但是,我们把它和导出之前的数据框对比一下,你来玩儿一个“大家来找茬”游戏吧。


注意,导出之前,列表当中的每一个元素,都没有引号包裹的。
但是重新读取回来的内容,每一个元素 多了 个单引号。
这看起来,似乎也不是什么大毛病啊。
然而,我们需要验证一下:
pd.read_csv('data_list.csv').text.iloc[0][0]
这次程序给我们返回的第一行文本分割的第一个元素,是这样的:
'['
不应该是“这”吗?
我们来看看下一个元素是“这”吗?
pd.read_csv('data_list.csv').text.iloc[0][1]
答案是:
"'"
看到这里,你可能已经恍然大悟。原来导出 csv 的时候,原先的分词列表被当成了 字符串 ;导入进来的时候,干脆就是个字符串了。
可是我们需要的是个列表啊,这个字符串怎么用?
来看看 tsv 格式是不是对我们的问题有帮助。
df_list.to_csv('data_list.tsv', index=None, sep='\t')
打开导出的 tsv 文件。
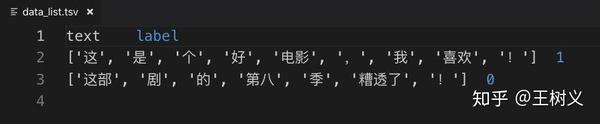
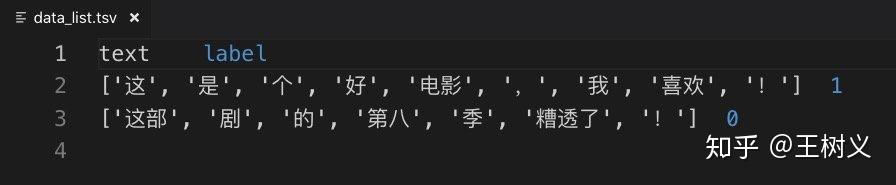
列表就是列表,两边并没有用双引号包裹。
这次兴许能成!
我们赶紧读回来看看。
pd.read_csv('data_list.tsv', sep='\t')
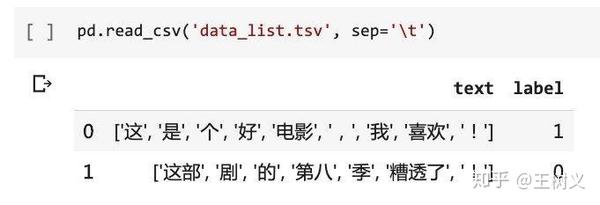
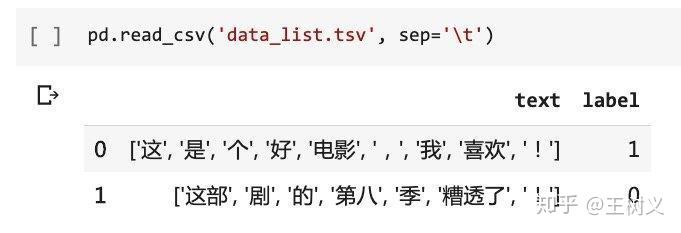
这结果,立刻让人心里凉了一半。
因为列表里面每个元素两旁的单引号都在啊。
抱着一丝侥幸的心理,我们尝试一下验证第一个元素。
pd.read_csv('data_list.tsv', sep='\t').text.iloc[0][0]


果不其然,还是 中括号 。
这意味着读回来的,还是一个字符串。
任务失败。
看来,依靠 csv/tsv 格式把列表导出导入,是不合适的。
那我们该怎么办呢?
pickle
好消息是,我们可以用 pickle 。
pickle 是一种二进制格式,在 Python 生态系统中,拥有广泛的支持。
例如 PyTorch 的预训练模型,就可以用它来存储和读取。
在 Pandas 里面使用 pickle,非常简单,和 csv 一样有专门的命令,而且连参数都可以不用修改添加。
df_list.to_pickle("data.pickle")
读取回来,也很方便。
df_list_loaded = pd.read_pickle("data.pickle")
我们来看看读取回来的数据是否正确:
df_list_loaded


这次看着好多了,那些让我们烦恼的引号都不见了。
验证一下第一行列表的第一个元素:
df_list_loaded.text.iloc[0][0]
结果是:
'这'