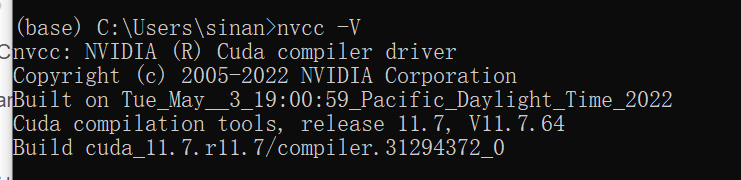
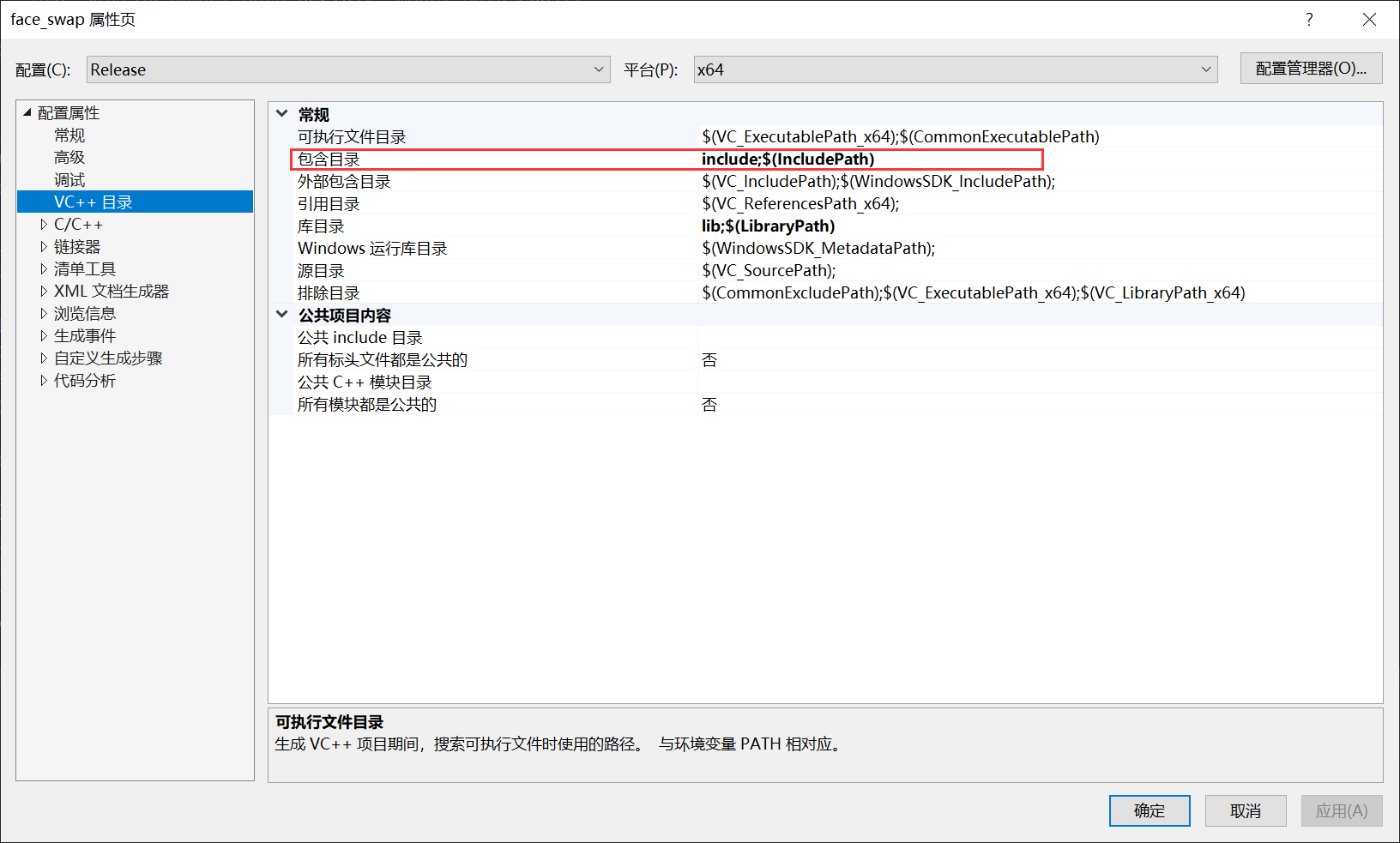
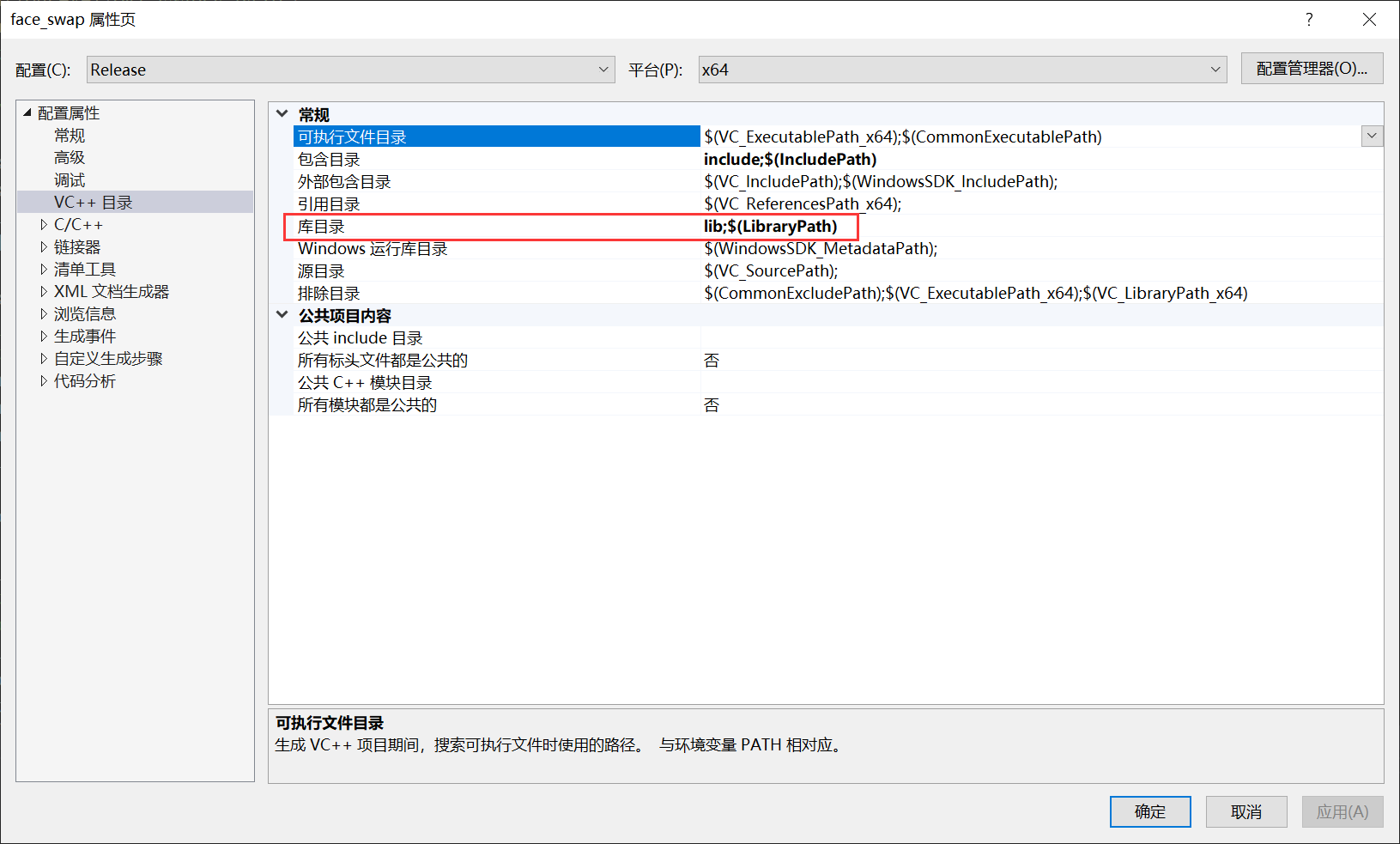
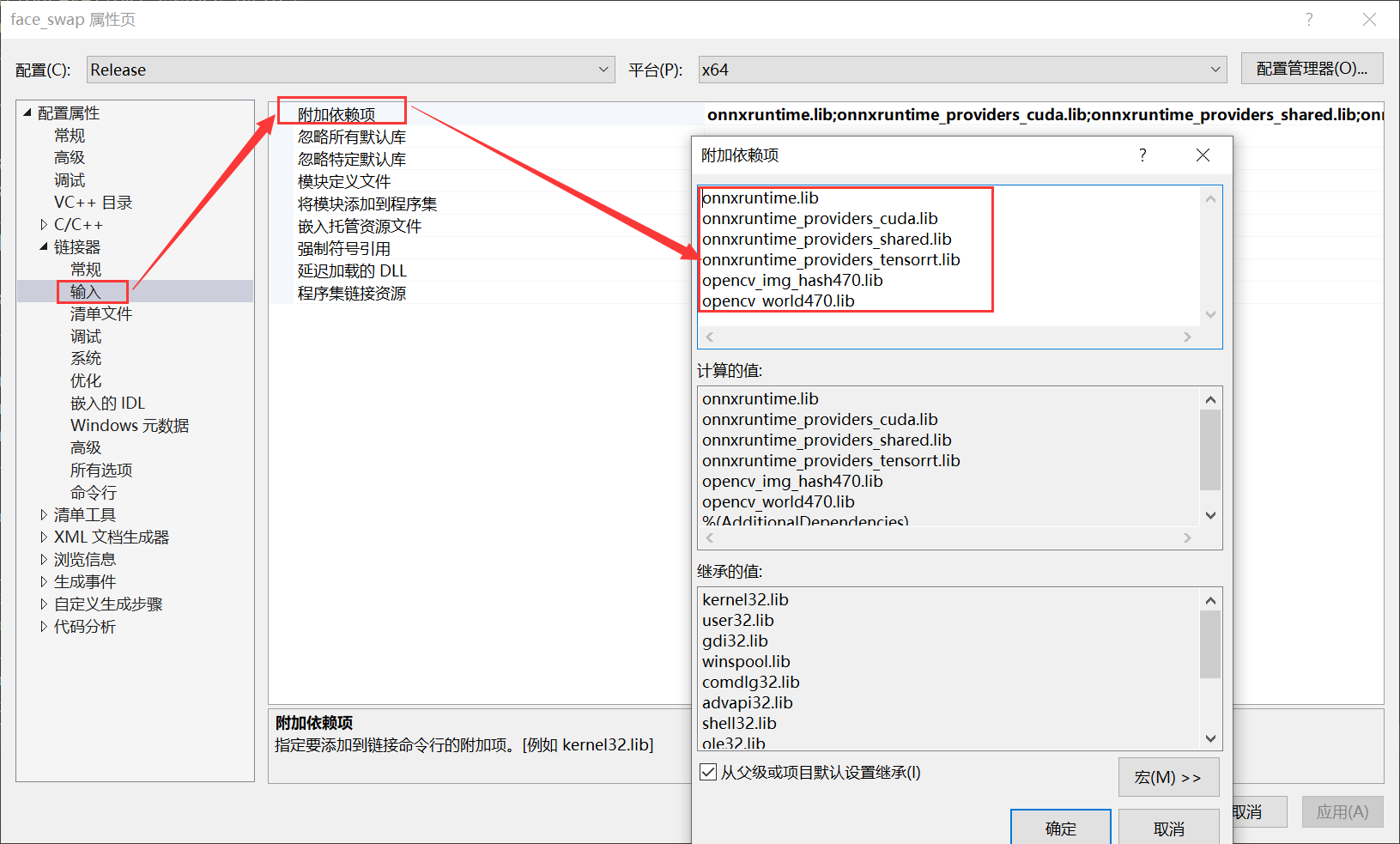
作用GPU推理设置参数如下:
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
- ORT_DISABLE_ALL:禁用所有图优化。
- ORT_ENABLE_BASIC:启用基本的图优化。
- ORT_ENABLE_EXTENDED:启用扩展的图优化,这通常包括基本优化加上一些更激进的优化策略,可能会提高模型的执行速度,但也可
能需要更多的时间来优化图。
使用GPU推理,运行代码,计算运行时间,可以看到每张图运行速度如下:
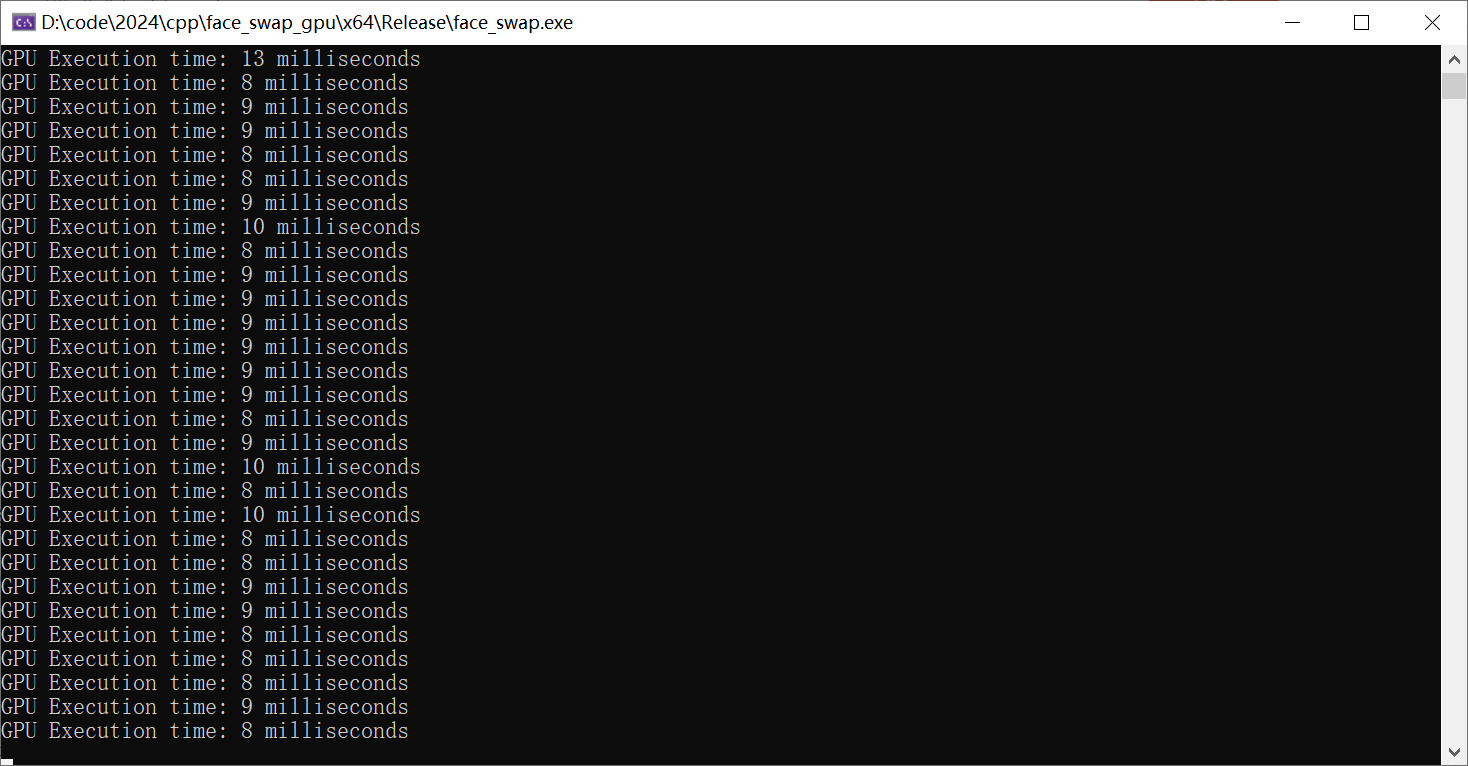
可以打开资源管理器看GPU的使用情况:

以上就是在win 10下使用Onnx Runtime用CPU与GPU来对onnx模型进行推理部署的对比,可以明显的看出来,使用GPU之后的推理速度,但在正式的大型项目中,在win下使用GPU部署模型是不建议,一般都会选择Linux,那样对GPU的利用率会高出不少,毕竟蚊腿肉也是肉。
ONNXRuntime是微软推出的一款推理框架,用户可以非常便利的用其运行一个onnx模型。ONNXRuntime支持多种运行后端包括CPU,GPU,TensorRT,DML等。可以说ONNXRuntime是对ONNX模型最原生的支持。
虽然大家用ONNX时更多的是作为一个中间表示,从pytorch转到onnx后直接喂到TensorRT或MNN等各种后端框架,但这并不能否认ONNXRuntime是一款非常优秀的推理框架。而且由于其自身只包含推理功能(最新的ONNXRuntime甚至已经可以训练),通过阅读其
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
step1. 使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
保存和加载整个模型 (
const char* INPUT_NAME = "input";
const char* OUTPUT_NAME = "output";
const std::vector<int64_t> INPUT_SHAPE = { 1, 3, 224, 224 };
const std::vector<int64_t> OUTPUT_SHAPE = { 1, 1000 };
int main(int argc, char* argv[])
if (argc != 2) {
std::cout << "Usage: " << argv[0] << " <model_path>" << std::endl;
return 1;
// 创建Ort::Env和Ort::SessionOptions对象
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "test");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
try {
// 创建Ort::Session对象
Ort::Session session(env, argv[1], session_options);
// 获取模型的输入和输出信息
Ort::AllocatorWithDefaultOptions allocator;
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();
std::cout << "Number of input nodes: " << num_input_nodes << std::endl;
std::cout << "Number of output nodes: " << num_output_nodes << std::endl;
// 创建模型输入数据
std::vector<float> input_data(INPUT_SHAPE[1] * INPUT_SHAPE[2] * INPUT_SHAPE[3], 1.0f);
// 创建Ort::Value对象,用于存储输入和输出数据
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(allocator, input_data.data(), input_data.size(), INPUT_SHAPE.data(), INPUT_SHAPE.size());
Ort::Value output_tensor = Ort::Value::CreateTensor<float>(allocator, OUTPUT_SHAPE.data(), OUTPUT_SHAPE.size());
// 运行模型
auto start = std::chrono::high_resolution_clock::now();
session.Run(Ort::RunOptions{ nullptr }, { INPUT_NAME }, { &input_tensor }, 1, { OUTPUT_NAME }, { &output_tensor }, 1);
auto end = std::chrono::high_resolution_clock::now();
std::cout << "Inference time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
// 获取输出数据
std::vector<float> output_data(OUTPUT_SHAPE[1]);
output_tensor.CopyTo<float>(output_data.data(), OUTPUT_SHAPE[1]);
// 输出前5个结果
std::cout << "Top 5 results:" << std::endl;
for (int i = 0; i < 5; i++) {
int max_index = std::distance(output_data.begin(), std::max_element(output_data.begin(), output_data.end()));
std::cout << max_index << ": " << output_data[max_index] << std::endl;
output_data[max_index] = -1.0f;
catch (const std::exception& ex) {
std::cerr << ex.what() << std::endl;
return 1;
return 0;
在使用该代码之前,你需要先安装OnnxRuntime库,并在代码中添加库的头文件和链接器选项。该代码读取命令行中的模型路径,并使用OnnxRuntime加载模型、运行推理并输出结果。