


什么是嵌入式AI开发?人工智能芯片指什么?STM32、树莓派、Jetson TX2、华为昇腾部署神经网络区别在哪?

1. 什么是人工智能(AI)芯片?
广义上讲,能运行AI算法的芯片都叫AI芯片。目前通用的CPU、GPU都能执行AI算法,只是效率不同的问题。但狭义上讲一般将AI芯片定义为“专门针对AI算法做了特殊加速设计的芯片”。学术上,人工智能芯片(简称AI芯片)是指含有专门处理人工智能应用中大量计算任务模块的芯片,属于集成电路和人工智能的交叉领域。
2. 什么是嵌入式?ARM、MCU、DSP、FPGA定义区别
首先,“嵌入式”这是个概念,准确的定义没有,各个书上都有各自的定义。但是主要思想是一样的,就是相比较PC机这种通用系统来说,嵌入式系统是个专用系统,结构精简,在硬件和软件上都只保留需要的部分,而将不需要的部分裁去。所以嵌入式系统一般都具有便携、低功耗、性能单一等特性。然后,MCU、DSP、FPGA这些都属于嵌入式系统的范畴,是为了实现某一目的而使用的工具。
2.1 MCU
MCU俗称”单片机“,指将计算机的CPU、RAM、ROM、定时计数器和多种I/O接口集成在一片芯片上,形成的芯片级的计算机。经过这么多年的发展,早已不单单只有普林斯顿结构的51了,性能也已得到了很大的提升。因为MCU必须顺序执行程序,所以适于做控制,较多地应用于工业。而ARM本是一家专门设计MCU的公司,由于技术先进加上策略得当,这两年单片机市场份额占有率巨大。
MCU做得好的厂商:瑞萨(Renesas)、恩智浦(NXP)、新唐、微芯(Microchip)、意法 半导体(ST)、爱特梅尔(Atmel)、英飞凌(Infineon)、德州仪器(TI)、东芝(Toshiba)、三星(Samsung)、赛普拉斯(Cypress)、亚德诺半导体(ADI)、高通(Qualcomm)、富士通(Fujitsu)、超威半导体(AMD)、盛群/合泰半导体(Holtek)、中颖电子、炬力、华润微、沛城、义隆、宏晶、松翰、凌阳、华邦电子、爱思科微、十速科技、佑华微、应广、欧比特、贝岭、东软载波微、君正、中微、兆易、晟矽微、芯海、联华、希格玛、汇春、建荣科技、华芯微、神州龙芯、紫光微、时代民芯、国芯科技、中天微等等。
基于ARM的单片机有很多种类,从低端M0(小家电)到高端A8、A9(手机、平板电脑)都很吃香,所以也不是ARM的单片机一定要上系统,关键看应用场合。
2.2 DSP
DSP叫做数字信号处理器,它的结构与MCU不同,加快了运算速度,突出了运算能力。可以把它看成一个超级快的MCU。低端的DSP,如C2000系列,主要是用在电机控制上,不过TI公司好像称其为DSC(数字信号控制器)一个介于MCU和DSP之间的东西。高端的DSP,如C5000/C6000系列,一般都是做视频图像处理和通信设备这些需要大量运算的地方。
2.3 FPGA
FPGA叫做现场可编程逻辑阵列,本身没有什么功能,就像一张白纸,想要它有什么功能完全靠编程人员设计(它的所有过程都是硬件,包括VHDL和Verilog HDL程序设计也是硬件范畴,一般称之为编写“逻辑”。)。
如果你够NB,你可以把它变成MCU,也可以变成DSP。由于MCU和DSP的内部结构都是设计好的,所以只能通过软件编程来进行顺序处理,而FPGA则可以并行处理和顺序处理,所以比较而言速度最快。
2.4 MCU、DSP、FPGA区别与联系
那么为什么MCU、DSP和FPGA会同时存在呢?那是因为MCU、DSP的内部结构都是由IC设计人员精心设计的,在完成相同功能时功耗和价钱都比FPGA要低的多。而且FPGA的开发本身就比较复杂,完成相同功能耗费的人力财力也要多。
所以三者之间各有各的长处,各有各的用武之地。但是目前三者之间已经有融合的态势,ARM的M4系列里多加了一个精简的DSP核,TI的达芬奇系列本身就是ARM+DSP结构,ALTERA和XINLIX新推出的FPGA都包含了ARM的核在里面。所以三者之间的关系是越来越像三基色的三个圆了。
3. AI芯片的发展现状和趋势?
自2016年以来,谷歌、百度、阿里、腾讯等互联网巨头以及多家知名的风险投资基金疯狂涌入人工智能行业,大力推动各初创算法(方案)公司在多个应用领域商业化落地。随着人工智能在视觉识别、语音识别等领域明确的商业化应用不断涌现,人工智能算法及方案芯片化、硬件化的趋势日益明显,具有深度学习算法加速功能的芯片需求快速提升。

人工智能领域的高速发展,取决于对前沿算法的研究、落地应用场景的积极探索及通过先进的芯片设计、制造技术来满足日益明确的商业需求三个关键因素。商汤科技、旷视科技、科大讯飞、思必驰、华为、寒武纪等多家中国公司对于前沿算法的研究已经走在全球前列,各个公司的产品也都是独特的,功耗、性能、应用场景都有自己的风格,可以在中国的广大的市场中占有一席之地,与美国齐头并进。中国对于落地应用的探索更是全球领先,已经出现包括人脸识别、智能安防、智能音箱、智能家居等多个落地的商业场景。新一代的AI芯片创业公司结合应用特点,采用了合理的先进芯片设计、制造技术,与美国同类公司相比位于同一起跑线上。业界普遍认为,AI芯片之争是中美两国公司间的竞争,中国目前暂时落后。但由于在应用探索上更加积极,未来中国AI芯片有可能超越竞争对手,成为全球领军力量。
4. AI芯片的划分?
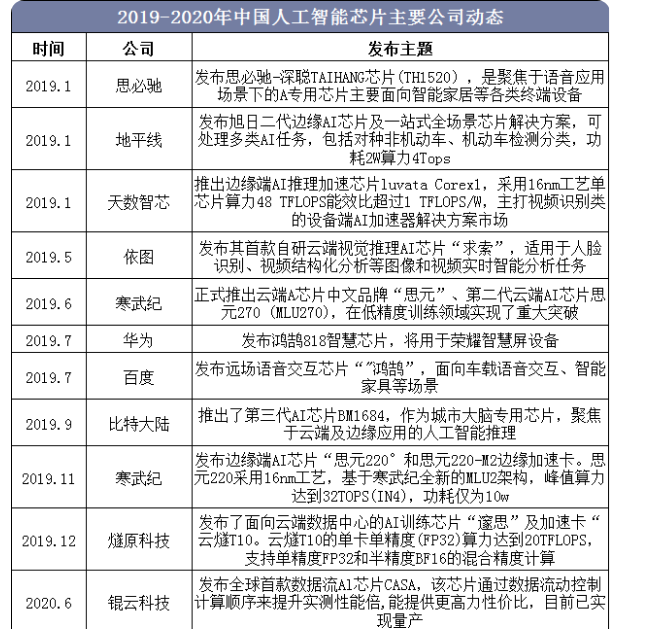
目前芯片发展开始面临一个矛盾的窘境:一方面处理器性能面临物理极限,无法按照摩尔定律进行增长;另一方面数据体量随着云、深度学习、AI等新应用兴起,对计算性能要求超过了“摩尔定律”增长的速度。处理器自然发展本身无法满足高性能应用的需求,出现了技术缺口。在这种情况下,采用专用协处理器的异构计算方式来提升处理性能成为最为理想便利的解决方案。

异构芯片在应用中通常有CPU、GPU、FPGA、ASIC四种架构选择,可提供专门的硬件加速实现各种应用中需要的关键处理功能,足以满足AIoT平台下对于芯片个性化需求。CPU与GPU是常见的通用型芯片,CPU适合逻辑控制、串行运算与通用类型数据运算,GPU拥有大规模并行计算架构,擅长处理诸如图形计算等多重任务。由于深度学习通常需要大量的但并不复杂的训练算法,因此相比CPU而言,GPU更适合深度学习运算。FPGA(现场可编程门阵列)是一直可编程的半定制芯片,具有并行处理优势,并且也可以设计成具有多内核的形态。FPGA最大的优势在于其可编程的特性,用户可以根据需要的逻辑功能对电路进行快速烧录来实现自定义硬件功能。
相较于CPU、GPU等通用型芯片以及半定制的FPGA来说,ASIC芯片的计算能力和计算效率都直接根据特定的算法的需要进行定制的,因此ASIC芯片具有体积小、功耗低、可靠性高、计算性能高、计算效率高等优势。所以在其所针对的特定的应用领域,ASIC芯片的能效表现要远超CPU、GPU等通用型芯片以及半定制的FPGA。GPU属于通用型芯片,ASIC属于专用型芯片,而FPGA则是介于两者之间的半定制化芯片,CPU更多是应用与终端设备。
AI芯片按照应用场景又可以分为云端芯片和终端芯片,按照功能可以分为训练芯片和推理芯片。云端指服务器端,终端指包括手机、电脑、监控摄像头、家电、消费电子等在内的电子终端产品。训练指通过大量的数据输入,运用增强学习等非监督学习方法,训练出一个复杂深度神经网络模型的过程,其对芯片运算和存储的综合性能要求很高。推理指利用训练好的模型,使用新的数据去得出各种结论、完成各种任务的过程,其对芯片的速度、能耗、安全和硬件成本要求较高。
在云中运行代码意味着你使用的CPU、GPU和TPU都是通过浏览器和服务器提供的。在云中运行代码的主要优点是,你可以为特定的代码分配必要的计算能力(训练大型模型可能需要大量的计算)。边缘与云相反,意味着你是在本地运行代码(也就是说你能够实际接触到运行代码的设备)。在边缘运行代码的主要优点是没有网络延迟。由于物联网设备通常要频繁地生成数据,因此运行在边缘上的代码非常适合基于物联网的解决方案
按照以上两个维度,可以将AI芯片划分至四个象限。整体算力由高到低包括服务器端训练和推理(如TPU和NPU)、云端推理、终端训练(如英伟达的Jetson tx2)和终端/嵌入式设备以推断应用为主的嵌入式部署芯片(如STM32、恩智浦的i.MX 8系列、max78000等)。
5. 对比 CPU、GPU,深度剖析 TPU
TPU(Tensor Processing Unit, 张量处理器)是类似于CPU或GPU的一种处理器。不过,它们之间存在很大的差异。最大的区别是TPU是ASIC,即专用集成电路。ASIC经过优化,可以执行特定类型的应用程序。对于TPU来说,它的特定任务就是执行神经网络中常用的乘积累加运算。CPU和GPU并未针对特定类型的应用程序进行优化,因此它们不是ASIC。
下面我们分别看看 CPU、GPU 和 TPU 如何使用各自的架构执行累积乘加运算:
CPU 通过从内存中读取每个输入和权重,将它们与其 ALU 相乘,然后将它们写回内存中,最后将所有相乘的值相加,从而执行乘积累加运算。现代 CPU 通过其每个内核上的大量缓存、分支预测和高时钟频率得到增强。这些都有助于降低 CPU 的延迟。
GPU 的原理类似,但它有成千上万的 ALU 来执行计算。计算可以在所有 ALU 上并行进行。这被称为 SIMD (单指令流多数据流),一个很好的例子就是神经网络中的多重加法运算。然而,GPU 并不使用上述那些能够降低延迟的功能。它还需要协调它的数千个 ALU,这进一步减少了延迟。简而言之,GPU 通过并行计算来大幅提高吞吐量,代价是延迟增加。
TPU 的运作方式非常不同。它的 ALU 是直接相互连接的,不需要使用内存。它们可以直接提供传递信息,从而大大减少延迟。神经网络的所有权重都被加载到 ALU 中。完成此操作后,神经网络的输入将加载到这些 ALU 中以执行乘积累加操作。神经网络的所有输入并不是同时插入 ALU 的,而是从左到右逐步地插入。这样做是为了防止内存访问,因为 ALU 的输出将传播到下一个 ALU。这都是通过脉动阵列 (systolic array) 的方式完成的。这种脉动阵列显著提高了 TPU 的性能。
6. STM32与树莓派、英伟达的Jetson TX2区别在哪?
Stm32和树莓派是两个不同的领域,从性能上来看,stm32是MCU,树莓派是MPU。
MCU和MPU的区别简单来说就是:MPU适合做需要复杂运算的大型程序,这种一般需要外挂RAM和ROM。MCU适合做一些运算比较简单的中小型程序,一般用来用于硬件管理和控制,所以这一般不需要外挂RAM和ROM,都集成在芯片内部,也称为单片机。stm32之前大多数型号属于Cortex-M系列的单片机,树莓派一般是Cortex-A系列处理器。除了Cortex-M以外,还有Cortex-M、Cortex-A、Cortex-R架构的处理器。当然, STM32现在也出了基于Cortex-A架构的STM32MP157处理器。


在嵌入式系统中,低成本和低功耗的要求比性能更为重要。但是随着移动计算和IoT边缘计算的出现,许多嵌入式系统现在需要复杂的处理,这样就产生了面向嵌入式领域看起来更像MPU的MCU产品,为带有外部存储器和高速缓存的器件提供了更高的性能和可配置性。这种情况下,术语MCU和MPU之间的差异仅取决于是否集成CPU系统。近年来,MCU和MPU之间的界限已经模糊。MCU和MPU之间的主要区别之一是软件和开发。MPU将支持丰富的OS,如Linux和相关的软件堆栈,而MCU通常将专注于裸机和RTOS。在决定哪种硬件平台、MCU或MPU最有效之前,由软件开发人员决定哪个软件环境和生态系统最适合他们的应用。
如果说树莓派是一款“即插即用”的单板计算机,那Jetson TX2则是一款功能强大的小型人工智能计算机。 除带有256个CUDA核心的GPU,这款功能强大的开发者套件能够使主板的硬件功能和接口充分发挥效用,预装 Linux 开发环境。同时,它还支持 NVIDIA Jetpack SDK,包括 BSP、深度学习库、计算机视觉、GPU 计算、多媒体处理等众多功能。NVIDIA JetPack SDK是构建AI应用程序的最全面的解决方案。它捆绑了所有Jetson平台软件,包括TensorRT,cuDNN,CUDA工具包,VisionWorks,Streamer和OpenCV,这些都是基于LTS Linux内核的L4T。


树莓派4B 采用的VideoCore VI是经典的双重Shader架构(全功能的 + 简化的),性能只有几十GFlops,Jetson TX2的GPU性能可以到41.33TFLOPS,8 GB 128 位 LPDDR4,单主频1866Mhz – 59.7 GB/s就比stm32整整大了10倍。
7. 国内新闻常看到的麒麟,鲲鹏,骁龙,天机,紫霄,昇腾又是些什么呢?

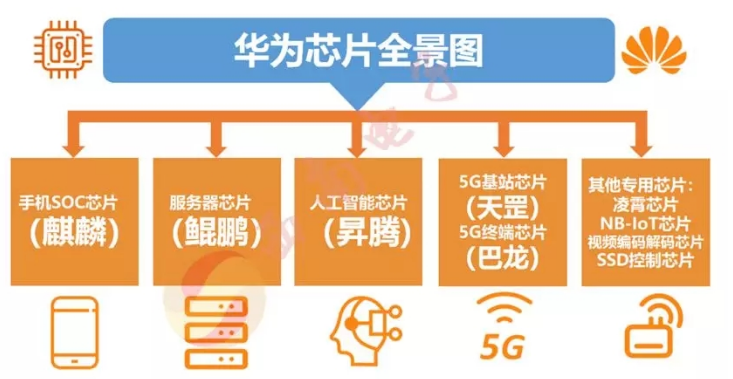
上面概图其实已经说明一切。其实就是针对不同领域的不同类型的芯片:
7.1 SoC芯片
所有手机芯片方案的核心都是两块:AP和BP。AP即Application Processor(应用处理器),包括CPU(中央处理器)和GPU(图形处理器),BP即Baseband Processor (基带处理器),负责处理各种通信协议,如GSM、3/4/5G等。此外,还有射频等核心单,它们组合在一起构成了SoC芯片集成电路的芯片。
7.2 服务器芯片
服务器是一种高性能计算机,作为网络的节点,存储、处理网络上80%的数据、信息,因此也被称为网络的灵魂。服务器最核心的部位就是服务器芯片,可以说是整个服务器的大脑。但是正是因为它的重要性,也决定了它的技术难度是不容小觑的。
7.3 AI芯片
AI芯片上面介绍已经足够多了,2018年,华为发布了两颗云数据中心AI芯片:单芯片计算密度最大的昇腾910和极致高效计算低功耗的AI SoC昇腾310。昇腾910属于Ascend Max系列,用于数据中心服务器,性能表现超过英伟达最强芯片AI V100,是全球已发布的单芯片计算密度最大的AI芯片。基于昇腾910华为还将推出大规模分布式训练系统昇腾Cluster,链接1024个昇腾910芯片,构成AI计算群,提供超高级AI计算能力,计算能力最高可达256P,使AI的训练速度达到崭新的水平。昇腾系列AI芯片采用了华为开创性的统一、可扩展的架构,即“达芬奇架构”,实现了从极致的低功耗到极致的大算力场景的全覆盖,目前全球市场上还没有其它架构能做到。
7.4 5G芯片
5G是指第五代移动通信技术,是4G之后的延伸,其峰值理论传输速度可达每秒数十Gb,相对于4G的网络传输速度快了数百倍,同时,5G还拥有毫秒级的传输时延和千亿级的连接能力,是开启万物互联、人机深度交互的通讯基础。5G通信的技术底层是5G芯片,5G芯片主要分为射频芯片和基带芯片。
天罡芯片——业界首款5G基站核心芯片。华为天罡是全球第一个超强集成、超强算力、超宽频谱的芯片,为AAU 带来了革命性的提升,实现基站尺寸缩小超55%,重量减轻23%,功耗节省达21%,安装时间比标准的4G基站,节省一半时间,有效解决站点获取难、成本高等挑战。同时天罡芯片可以让市场上存在的大多数基站直接升级到5G,这就意味着4G升5G可以在不更改供电或者是断电的情况下直接升级,极大的方便了更新5G。
巴龙5000——全球第一个支持5G的3GPP标准的商用芯片组。Balong 5000具备5项世界之最,1个世界领先:全球领先的集成2G、3G、4G的多模单芯模组;速度世界最快,@Sub-6 GHz 200MHz:下行链路速度4.6Gbps,上行速度2.5Gbps;世界首个上行/下行解耦多模终端芯片;世界首个同时支持NSA和SA架构的芯片组;世界最快的高峰下行速度@毫米波 800MHz Gbps;世界首个5G芯片上的R14 V2X。
8. AI芯片值得关注的问题
8.1 AI芯片是不是比CPU要难以设计?
恰恰相反,AI芯片很容易实现,因为AI芯片要完成的任务,绝大多是是矩阵或向量的乘法、加法,然后配合一些除法、指数等算法。AI算法在图像识别等领域,常用的是CNN卷积网络,一个成熟的AI算法,就是大量的卷积、残差网络、全连接等类型的计算,本质是乘法和加法。如果确定了具体的输入图形尺寸,那么总的乘法加法计算次数是确定的。在神经网络的训练过程中,用到的后向传播算法,也可以拆解为乘法和加法。
AI芯片可以理解为一个快速计算乘法和加法的计算器,而CPU要处理和运行非常复杂的指令集,难度比AI芯片大很多。CPU与GPU并不是AI专用芯片,为了实现其他功能,内部有大量其他逻辑,这些逻辑对于目前的AI算法来说是完全用不上的,自然造成CPU与GPU并不能达到最优的性价比。
8.2 在AI任务中,AI芯片到底有多大优势?
以4GHz 128bit的POWER8的CPU为例,假设是处理16bit的数据,该CPU理论上每秒可以完成16X4G=64G次。再以大名鼎鼎的谷歌的TPU1为例,主频为700M Hz,有256X256=64K个乘加单元,每个时间单元可同时执行一个乘法和一个加法。那就是128K个操作。该YPU论述每秒可完成=128K X 700MHz=89600G=大约90T次。
可以看出在AI算法处理上,AI芯片比CPU快1000倍。如果训练一个模型,TPU处理1个小时,放在CPU上则要41天。
8.3 AI芯片怎么用?
如果是电脑的话,这个东西直接插在 SATA硬盘接口上。手机的话,也是一样焊在主板上,手机上主要用于图像处理,如AI美颜、人脸识别等任务,如果系统设计得好的话,AI芯片的存储模块可以大大减少,直接调用摄像头底层存储数据,留出来的空间可以增加更多的计算单元。
8.4 谷歌的TPU 怎么样?
谷歌在《In-Datacenter Performance Analysis of a Tensor Processing Unit》中披露了第一代TPU的架构以及性能。根据新闻报道,2017年发布的第二代TPU芯片,第二代TPU包括了四个芯片,每秒可处理180万亿次浮点运算;如果将64个TPU组合到一起,升级为所谓的TPU Pods,则可提供大约11500万亿次浮点运算能力。
8.5 国内寒武纪AI芯片怎么样?
国内寒武纪成为名副其实的AI芯片设计领域的独角兽,受到投资界的追捧。寒武纪的NPU,也是专门针对神经网络的,与谷歌的TPU类似。在《DianNao:A Small-Footprint High-Throughput Accelerator》一文中提到,DianNao的内部结构如下。分为三个部分,NFU-1,NFU-2,NFU-3. NFU-1全是乘法单元。16X16=256个乘法器。这些乘法器同时计算,也就是说,一个周期可以执行256个乘法。NFU-2是加法树。16个。每个加法树是按照8-4-2-1这样组成的结构。每个加法数有15个加法器。NFU-3是激活单元。16个。看起来也不复杂,但是因为是ASIC,少了许多不必要的逻辑功能,所以速度就是快,功耗就是低,效果就是好。
这种架构,只能适用特定的算法类型,比如深度学习(CNN,DNN,RNN)等。但是,深度学习只是机器学习中的某一类,整个机器学习,有很多其他种类的算法,和深度学习的不太一样,甚至经常用到除法等计算类型。这些算法,目前的应用范围也很广。为了加快常用机器学习算法的运算,寒武纪后续又设计出专门针对这些算法的处理器方案:PuDianNao.PuDianNao,内部实现了7种常用的机器学习算法:k-means, k-nearest neighbors , naive bayes , support vector machine , linear regression , and DNN。
8.6 AI芯片也像CPU一样有指令集吗?
有,寒武纪就搞出一个Cambricon指令集架构。为了神经网络计算加速而设计的。但是不要高估指令集的作用,指令集这个东西是谁的市场大,谁就掌握绝对话语权,想当年英特尔搞X86指令集,市面上还有很多比X86更好的指令集,全都挂了,因为Intel绑定了微软,X86指令集向前兼容是个大杀器啊,古老程序在最新的CPU和windows系统上都可以兼容运行,一下子奠定了市场的基石。AI芯片的指令集想要成为行业的标准,那得靠市场拼杀才能成功,不是简简单单比较一下性能就能成功的。
9. 盘点一些AI增强型芯片和平台,哪款是嵌入式项目最佳选择?
AI芯片通常分为三个关键应用领域:云端训练、云端推理和边缘推理。训练方面的大拿是Nvidia的GPU,它已经成为训练机器学习算法的热门选择。训练过程要分析数万亿个数据样本,GPU的并行计算架构在这方面是一大优势。云端推理可以构建许多AI应用的机器学习模型,这些任务需要密集的计算而无法部署在边缘设备上。FPGA类的处理器具有低延迟特点,并可执行计算密集型任务,在这些应用方面具有优势。但并非所有AI计算任务都可以在云端完成,无论成熟公司还是初创公司,很多芯片开发商都在开发自己的AI芯片,并为其处理器添加AI功能。
9.1 IC厂商
Intel:Nervana NNP-I、Mobileye EyeQ、Movidius、Arria 10 FPGA、Loihi
是世界上第一大的半导体公司,也是第一家推出x86架构处理器的公司,总部位于美国加利福尼亚州圣克拉拉,成立于1968年7月18日。目前英特尔主要有五大类AI芯片产品,包括Nervana处理器;还有Mobileye正在开发其第五代SoC EyeQ5,以充当视觉中央计算机;针对AI推理和分析性能的Intel视觉加速器设计产品Movidius视觉处理器阵列和Arria 10 FPGA;首款自主学习芯片Loihi测试。
联发科技NeuroPilot AI平台
NeuroPilot平台专为AI边缘计算而设计,可提供一系列的硬件和软件、AI处理单元和NeuroPilot软件开发套件(SDK)。它所支持的主流AI框架包括Google TensorFlow、Caffe、Amazon MXNet和Sony NNabla,并且在操作系统方面支持Android和Linux。
联发科技表示,该平台“使AI更接近芯片组级别,适用于边缘计算设备,即深度学习和智能决策需要更快完成的场景”,开创了一个从边缘到云端的AI计算方案混合体。
Qualcomm骁龙845
高通的第三代AI移动平台据称在AI性能上比上一代SoC提升了3倍。除了支持Google TensorFlow和Facebook Caffe / Caffe2框架外,骁龙神经处理引擎(NPE)SDK现在还可以支持Tensorflow Lite和新的开放式神经网络交换(ONNX)标准,可让开发人员轻松选择自己喜欢的AI框架,包括Caffe2、CNTK和MxNet等。此外,它还支持谷歌的Android NN API。骁龙845目标应用包括智能手机、XR耳机和始终联网的PC等。
高通的AI Engine包括几个硬件和软件组件,其设备端AI处理性能已经在骁龙845上体现出来,将支持包括845、835、820和660在内的移动平台。AI Engine支持Snapdragon系列核心硬件架构,即Hexagon矢量处理器、Adreno GPU和Kryo CPU。其软件组件包括Snapdragon神经网络处理引擎、Android神经网络API和Haxagon神经网络。
由于采用了异构计算,骁龙845的新架构带来了显著的性能改进。例如,高通声称新的相机和视觉处理架构在视频捕捉、游戏和XR应用方面,功耗比上一代降低了30%,新的Adreno 630也让图形处理性能和功效提升高达30%。
三星Exynos 9系列
2018年初,三星电子发布了最新的高端应用处理器(AP)Exynos 9系列9810,主要面向AI应用和富媒体内容。这款移动处理器是三星的第三代定制CPU(2.9 GHz),内置超高速千兆LTE调制解调器和深度学习增强的图像处理功能模块。
该处理器采用新的八核CPU,其中四个是第三代定制内核,频率可以达到2.9 GHz,另外四个针对效能进行了优化。“通过扩展流水线并改善高速缓存的架构,单核性能提升了两倍,多核性能也比其前代产品提高了约40%,”三星表示。该芯片还增加了一些新功能,包括通过神经网络深度学习来增强用户体验,并通过单独的安全处理单元来提高安全性,以保护个人数据安全,比如面部、虹膜和指纹信息。Exynos 9系列的9810目前已经量产。
9.2 技术巨头和HPC厂商
谷歌:TPU
2016年,谷歌I/O开发者大会上,谷歌正式发布了首代TPU,这是一种专门针对tensorflow'开发的芯片,至今已发布到第三代。Google的原始TPU在GPU方面拥有领先优势,并帮助deepmind的AlphaGo在Go锦标赛中击败了Lee Sedol。近期,Google 推出了可在Google Cloud Platform中使用的Cloud TPU。谷歌还有专用于在边缘的AI专用ASIC Edge TPU,它以较小的物理和电源占用空间提供了高性能,从而可以在边缘部署高精度AI。
微软:Brainwave
微软是美国一家跨国电脑科技公司,以研发、制造、授权和提供广泛的电脑软件服务为主。公司于1975年由比尔·盖茨和保罗·艾伦创立,总部位于美国华盛顿州的雷德蒙德。2017年8月,微软宣布推出一套基于FPGA的超低延迟云端的深度学习系统-Brainwave,以具有竞争力的成本以及业界最低的延时或延迟时间进行实时AI计算,Brainwave旨在加速实时AI计算的硬件体系结构。据悉,微软正在招聘工程师为其云进行AI芯片设计。
华为海思:昇腾910、昇腾310、麒麟980、麒麟990 5G、Hi3559A
昇腾有四大系列,昇腾310是目前面向计算场景最强算力的AI SoC;昇腾910是目前已发布的单芯片计算密度最大的 AI 芯片;麒麟980,是世界上第一个7纳米工艺手机SoC芯片组,世界上第一个cortex-A76架构芯片组,世界上第一个双NPU设计以及世界上第一个支持LTE Cat.21的芯片组;麒麟990 5G是目前晶体管数最多、功能最完整、复杂度最高的 5G SoC,也是首个采用达芬奇架构NPU的旗舰芯片;Hi3559A是一个移动摄像机SoC,具有双核CNN 700 MHz神经网落加速引擎。
百度:昆仑、鸿鹄
据了解,百度从2011年开始开发现场可编程门阵列AI加速器,2018年7月,百度发布自主研发的中国第一款云端全功能AI芯片“昆仑”。2019年7月,百度又发布了智能语音芯片——鸿鹄,主打低功耗和高精度。2019年12月18日,三星官方宣布,百度首款AI芯片昆仑已经完成研发,将由三星代工,最早将于2020年初实现量产。
阿里:含光800、TG6100N
2018年10月31日阿里成立平头哥半导体有限公司,平头哥半导体将打造面向汽车、家电、工业等诸多行业领域的智联网芯片平台。2019年9月阿里首款AI云端推理芯片含光800正式推出,在业界标准的ResNet-50测试中,含光800推理性能比目前业界最好的AI芯片性能高4倍。除此之外,阿里还推出了TG6100N,这款芯片将用于天猫精灵等产品中。
9.3 半导体厂商
NPX面向边缘处理的机器学习(ML)环境

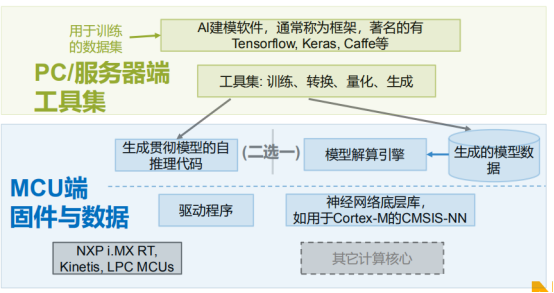
为证明利用现有的CPU可以在边缘运行机器学习模型,NXP半导体公司推出了嵌入式AI环境,可让设计人员基于NXP的产品系列部署机器学习,从低成本微控制器到i.MX RT处理器,直到高性能应用处理器。NXP表示,ML环境提供了简便的交钥匙方案,可让设计人员选择正确的执行引擎(Arm Cortex内核或高性能GPU/DSP)和工具,以便在其上部署机器学习模型(包括神经网络)。
此外,NXP还表示,该环境包括一些免费软件,允许用户导入他们自己训练过的TensorFlow或Caffe模型,将它们转换为优化的推理引擎,并将它们部署在NXP从低成本的MCU到i.MX,以及Layerscape处理器解决方案上。
“在嵌入式应用中实施机器学习,一切都要平衡成本和最终用户体验,”恩智浦AI技术负责人Markus Levy在一份声明中表示。“例如,许多人仍然感到惊讶,即使在低成本MCU上,他们也可以部署具有足够性能的推理引擎。另一方面,我们的高性能混合交叉和应用处理器具有足够的处理资源,可在许多客户应用中运行快速推理和训练。随着AI应用的扩大,我们将继续通过下一代专用机器学习加速器来推动这一领域的增长。”
NXP的EdgeScale套件提供了一套基于云的工具和服务,用于物联网和边缘计算设备的安全制造与注册。该解决方案为开发人员提供了一套安全机制,供他们在应用中利用主流的云计算框架,远程部署和管理无限数量的边缘设备。NXP的合作伙伴生态系统还包括ML工具、推理引擎,解决方案和设计服务等。
瑞萨集成DRP的e-AI方案:
e-AI即嵌入式人工智能解决方案。从端点智能入手,而不能只靠在云端使用大数据来解决。面向未来提供实时低功耗人工智能处理解决方案,以满足端点嵌入式设备人工智能应用的特定需求。
E-AI开发环境是一种将学习后的模型嵌入到MCU/MPU中的有效工具。在MCU/MPU上实现学习结果存在一些困难:MCU/MPU不支持Python,与MCU/MPU现有的ROM/RAM管理工具不兼容,而且在许多人工智能框架中使用Python作为描述语言,而MCU的控制程序通常使用C/C++。

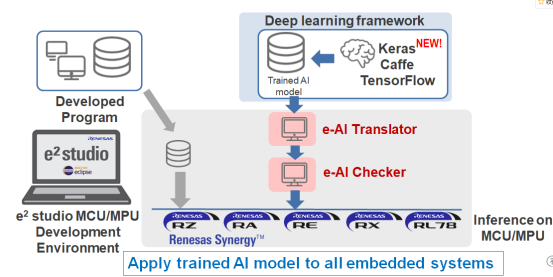
瑞萨电子提供了一整套e-AI解决方案,包括:ue-AI translator:将Caffe或者TensorFlow 网络以及其他深度学习框架导入至MCU/MPU开发环境中;ue-AI checker:基于输出结果,计算出MCU/MPU中的ROM/RAM安装尺寸以及推理执行时间;ue-AI importer:连接专门用于嵌入式系统的新AI框架,在MCU/MPU的开发环境中实现实时性能和较小的资源。
通过将所学的人工智能输入翻译器中,提取网络结构、功能和学习参数,并将其转换为E~2演播室C/C++项目的可用形式。
当然还有我们此前已经反复介绍过的 STM32 支持的cube-ai系列, maxim的max78000 , 平头哥的TG6100N ,详情参考文后推荐链接。
9.4 中国的初创企业
寒武纪:MLU100/270/220;
地平线:征程(Journey)、旭日(Sunrise)
比特大陆:BM1680/1682/1684/1880
云天励飞:DeepEye1000
清微智能:TX101/210/510
黑芝麻:华山一号
思必驰:TAIHANG
等
10. 更多精彩内容
嵌入式AI开发系列教程推荐:
【嵌入式AI部署&基础网络篇】轻量化神经网络精述--MobileNet V1-3、ShuffleNet V1-2、NasNet
【嵌入式AI开发】篇六|实战篇二:深度学习模型的压缩、量化和优化方法
stm32篇:
【嵌入式AI开发】篇五|实战篇一:STM32cubeIDE上部署神经网络之pytorch搭建指纹识别模型.onnx
【嵌入式AI开发】篇四|部署篇:STM32cubeIDE上部署神经网络之模型部署
平头哥篇:
【嵌入式AI开发&平头哥篇二】玄铁开发板AI部署流程初探(使用yoctools实现cifar10的迁移部署)
美信篇:
【嵌入式AI开发&美信问题篇一】Maxim78000 AI实战开发-训练与测试评估精度差距大
【嵌入式AI开发&Maxim篇二】美信Maxim78000Evaluation Kit AI开发环境
【嵌入式AI开发&Maxim篇四】美信Maxim78000Evaluation Kit AI实战开发二
11.
参考文章
什么是嵌入式AI开发?人工智能芯片指什么?STM32、树莓派、Jetson TX2、华为昇腾部署神经网络区别在哪?
华为芯片20年 麒麟、昇腾、鲲鹏、巴龙、天罡等5大系列成长史揭密
weixin_30294021的博客_CSDN博客-领域博主
2020人工智能芯片行业现状,通用人工智能的人工智能芯片成大趋势
盘点九款AI增强型芯片和平台,哪款是嵌入式项目最佳选择?-EDN 电子技术设计
