input_str = 'Hello Python123 666 Hi jupyter notebook 1111'
result = re.sub(r'\d+', '', input_str)
print(result)
结果如下:

而在有些情况下,比如获取的数据中,招聘岗位信息里薪资是
15K
这样的,商品购买信息里商品购买人数是
8500+
人购买了此商品,这时我们需要从中提取出数字。
input_str = '薪资:15K 8500+人付款 3.0万+人付款'
result = re.findall("-?\d+\.?\d*e?-?\d*?", input_str)
print(result)
结果如下: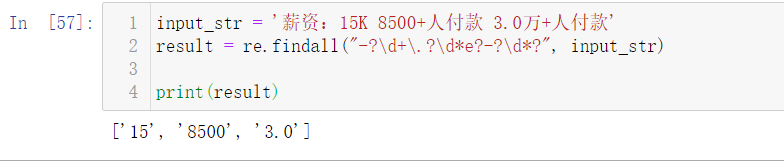
滤除文本中标点符号
import re
input_str = """This &is [an] example? \叶庭云<< 1""!。。;11???【】>>1 *yetingyun/p:?| {of} string. with.? punctuation!!!!"""
s = re.sub(r'[^\w\s]', '', input_str)
print(s)
结果如下:
可以看到文本中乱七八糟的符号都被滤除了,用正则表达式过滤文本中的标点符号,如果空白符也需要过滤,可以使用 r'[^\w]'。原理很简单:在正则表达式中,\w 匹配字母或数字或下划线或汉字(具体与字符集有关),^\w表示相反匹配。
删除两端无用的空格
input_str = " \t yetingyun \t "
input_str = input_str.strip()
input_str
结果如下:
中文分词,滤除停用词和单个词
# 从Github下载停用词数据 https://github.com/zhousishuo/stopwords
import jieba
import re
# 读取用于测试的文本数据 用户评论
with open('comments.txt') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词 精确模式
seg_list_exact = jieba.cut(new_data, cut_all=False)
# 加载停用词数据
with open('stop_words.txt', encoding='utf-8') as f:
# 获取每一行的停用词 添加进集合
con = f.read().split('\n')
stop_words = set()
for i in con:
stop_words.add(i)
# 列表解析式 去除停用词和单个词
result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1]
result_list
结果如下: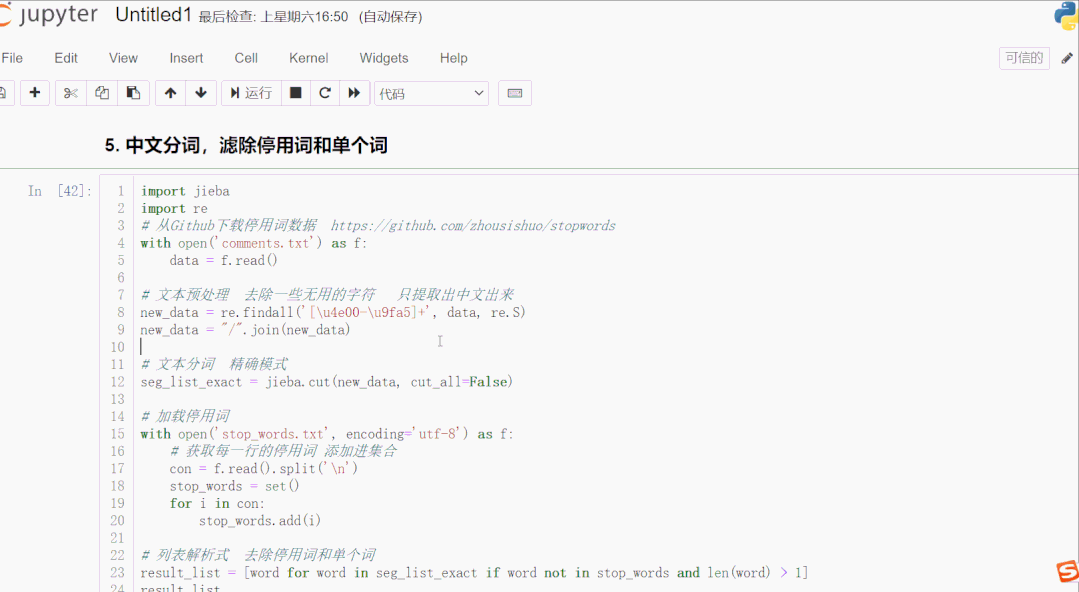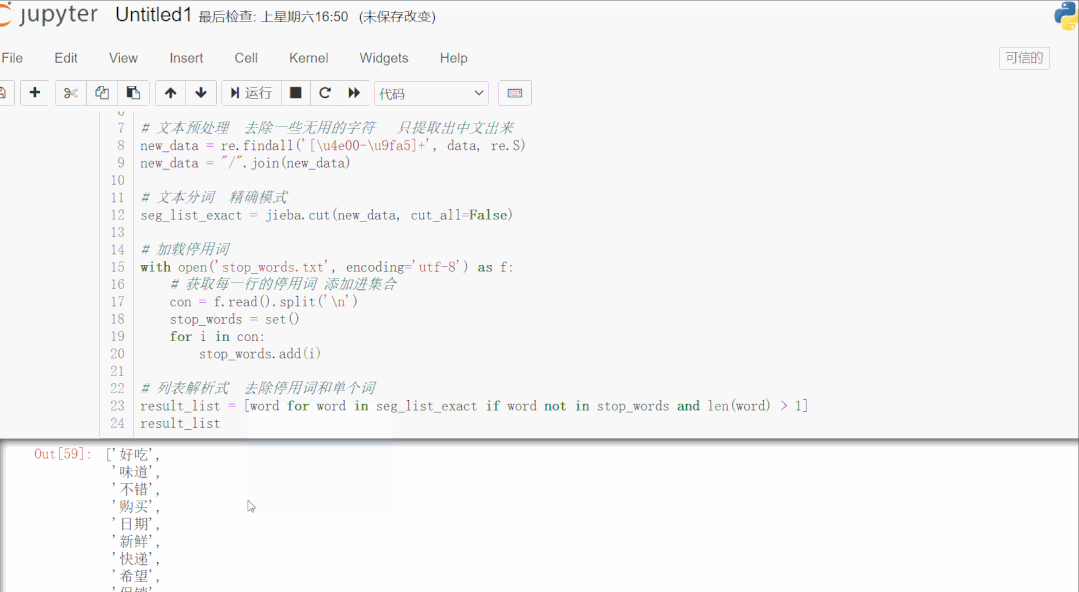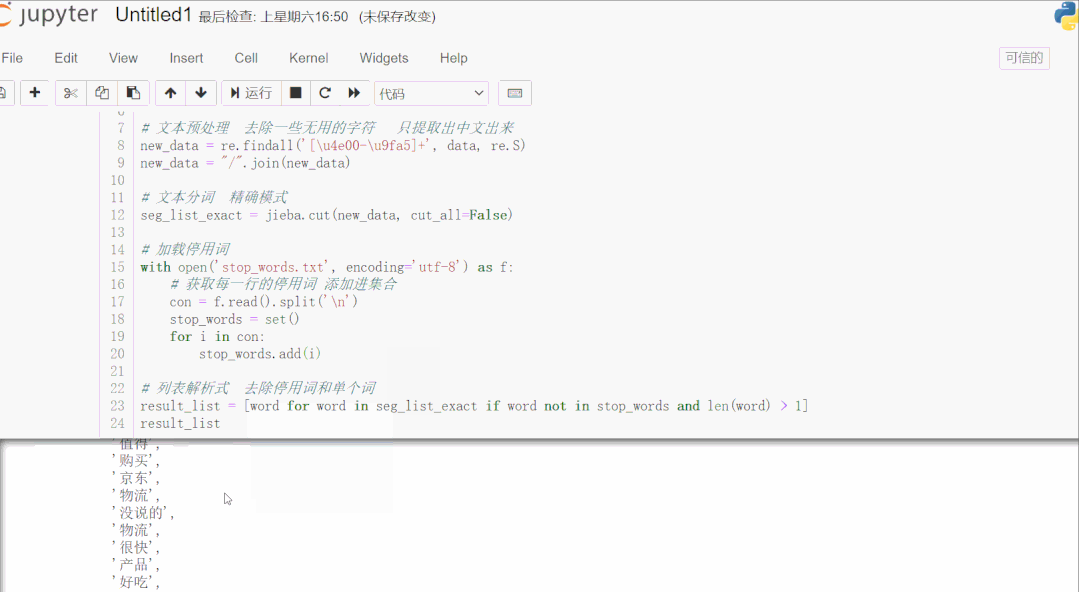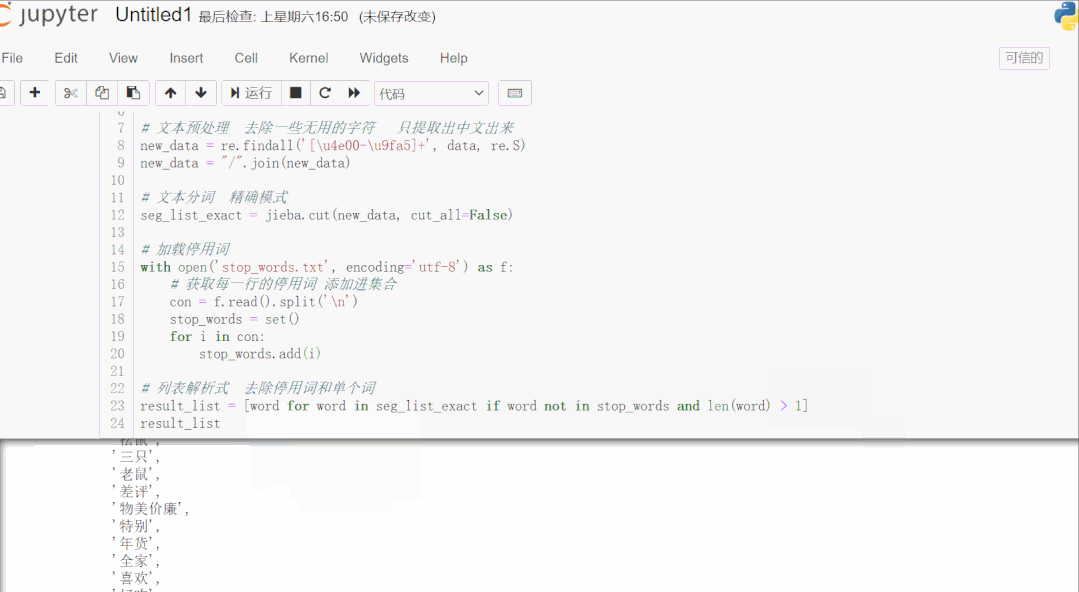
首先读取用于测试的文本数据,该数据是爬取的商品评论,这一类数据通常有很多无意义的字词和符号,通过正则表达式滤除掉无用的符号,只提取出中文出来。使用 jieba 库进行文本分词,加载停用词数据到集合,然后一行列表解析式滤除停用词和单个词,这样效率很高。停用词数据可以下载一些公开的,再根据实际文本处理需要,添加字词语料进去,使滤除效果更好。
Github下载停用词数据:https://github.com/zhousishuo/stopwords
SnowNLP是一个 Python 写的类库,可以方便的处理中文文本内容,是受到了 TextBlob 的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和 TextBlob 不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的 unicode 编码,所以使用时请自行 decode 成 unicode 编码。
使用 SnowNLP 处理中文文本数据非常方便,以词性标注和关键词提取为例:
from snownlp import SnowNLP
word = u'今天天气好 这个姑娘真好看'
s = SnowNLP(word)
print(s.words) # 分词
print(list(s.tags)) # 词性标注
from snownlp import SnowNLP
text = u'''
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,
而在于研制能有效地实现自然语言通信的计算机系统,
特别是其中的软件系统。因而它是计算机科学的一部分。
s = SnowNLP(text)
print(s.keywords(limit=6)) # 关键词提取
推荐阅读:
https://github.com/isnowfy/snownlp
https://docs.python.org/3/library/re.html
Python 工具链让你写的代码更规范
深入浅出 Python 中的递归算法
5分钟快速掌握 Adam 优化算法
点击下方阅读原文加入社区会员
在进行数据分析与可视化之前,得先处理好数据,而很多时候需要处理的都是文本数据,本文总结了一些文本预处理的方法。将文本中出现的字母转化为小写input_str=""...
在进行文本分析时,我们一大半的时间都会花在文本预处理上,而中文和英文的预处理流程稍有不同,本文就中文文本的预处理做一个总结。
文章目录1、文本数据准备2、去除指定无用的符号3、让文本只保留汉字4、文本中的表情符号去除5、繁体中文与简体中文转换
1、文本数据准备
使用已经有的语料库,按照Python读取文本内容的方法读取文本文件内容。此处为了一步步演示过程,所以先使用句子,最后再整合。
2、去除...
二、去除指定无用的符号
我们爬取到的文本有时候会有很多空格或者是其他一些无用的符号,如果保留这些符号,在分词的时候这些符号也会被分出来,就会导致分词的结果不是很好。这个时候我们就可以用replace()这个方法去掉所有你不想要的符号:
1. 去除空格
contents = ' 大家好, 欢迎一起来学习文本的空格...
收集和预处理文本数据集是开发智能模型的重要一步。下面是一些常用的方法技巧:
1. 数据收集:确定你的模型需要的文本类型,并选择合适的数据源进行收集。数据源可以包括已有的公开数据集、网页抓取、社交媒体数据、论坛帖子等。确保数据源的可靠性和合法性。
2. 数据清洗:对收集到的原始文本数据进行清洗,去除无关信息和噪声。常见的清洗操作包括去除HTML标签、URL链接、特殊字符、停用词等。可以使用Python的字符串处理和正则表达式库来实现。
3. 文本分词:将文本数据分割成单词或者其他语义单位。分词可以使用现有的分词工具,如jieba中文分词器、NLTK英文分词器等。
4. 词干化和词形还原:将单词还原为其原始形式,以减少词汇的多样性。可以使用词干化(stemming)和词形还原(lemmatization)技术,如Porter算法和WordNet词形还原工具。
5. 构建词汇表:通过统计文本数据中的词频,构建一个词汇表。词汇表包含数据中出现的所有词汇,可以用于后续的编码和特征提取。
6. 数据向量化:将文本数据转换为数值形式,以便机器学习模型进行处理。常见的向量化方法包括词袋模型(Bag of Words)、TF-IDF表示、词嵌入(Word Embedding)等。
7. 数据划分:根据需求,将数据集划分为训练集、验证集和测试集。训练集用于模型的训练和参数调整,验证集用于模型的选择和调优,测试集用于最终评估模型的性能。
以上是一些常见的文本数据集收集和预处理的步骤和技巧。具体的操作和方法会根据你的任务和数据特点而有所不同。在实际操作中,你可能需要结合领域知识和实践经验来进行调整和优化。

