


在Python中评估分类模型

作者|Sadrach Pierre, Ph.D.
编译|VK
来源|Towards Data Science
原文链接: https:// towardsdatascience.com/ evaluating-classification-models-in-python-6b5277e3d524
分类是一种有监督学习,其中一种算法将一组输入映射到离散输出。
分类模型在不同的行业有着广泛的应用,是监督学习的支柱之一。这是因为,跨行业,许多分析性问题都可以通过将输入映射到一组离散的输出来构建。
定义分类问题的简单性使得分类模型具有多功能性和行业不可知性。
分类模型的一个重要组成部分是评价模型的性能。简而言之,数据科学家需要一种可靠的方法来测试一个模型对结果的正确预测能力。许多工具可用于评估模型性能;根据你要解决的问题,有些可能比其他更有用。
如果数据是平衡的,那么混淆矩阵就足以作为性能度量。相反,如果你的数据显示不平衡,意味着一个或多个结果的代表性明显不足,你可能需要使用类似精度的度量。
如果你想了解你的模型在决策阈值上的健壮性,那么AUROC和AUPRC等度量可能更合适。
考虑到选择合适的分类度量取决于你试图回答的问题,每个数据科学家都应该熟悉这套分类性能度量。Python中的Scikit学习库有一个metrics模块,使快速计算准确率、精确度、AUROC和AUPRC变得容易。此外,了解如何通过ROC曲线、PR曲线和混淆矩阵可视化模型性能也同样重要。
在这里,我们将考虑建立一个简单的分类模型来预测客户流失的可能性。客户流失是指客户离开公司、退订或一段时间后不再购买的事件。
我们将处理电信公司的客户流失数据,其中包含有关一家虚构电信公司的信息。我们的任务是预测客户是否会离开公司,并评估我们的模型执行此任务的效果。
建立分类模型
让我们从将电信公司的客户流失数据读入数据帧开始:
df = pd.read_csv(‘telco_churn.csv’)
现在,让我们显示前五行数据:
df.head()

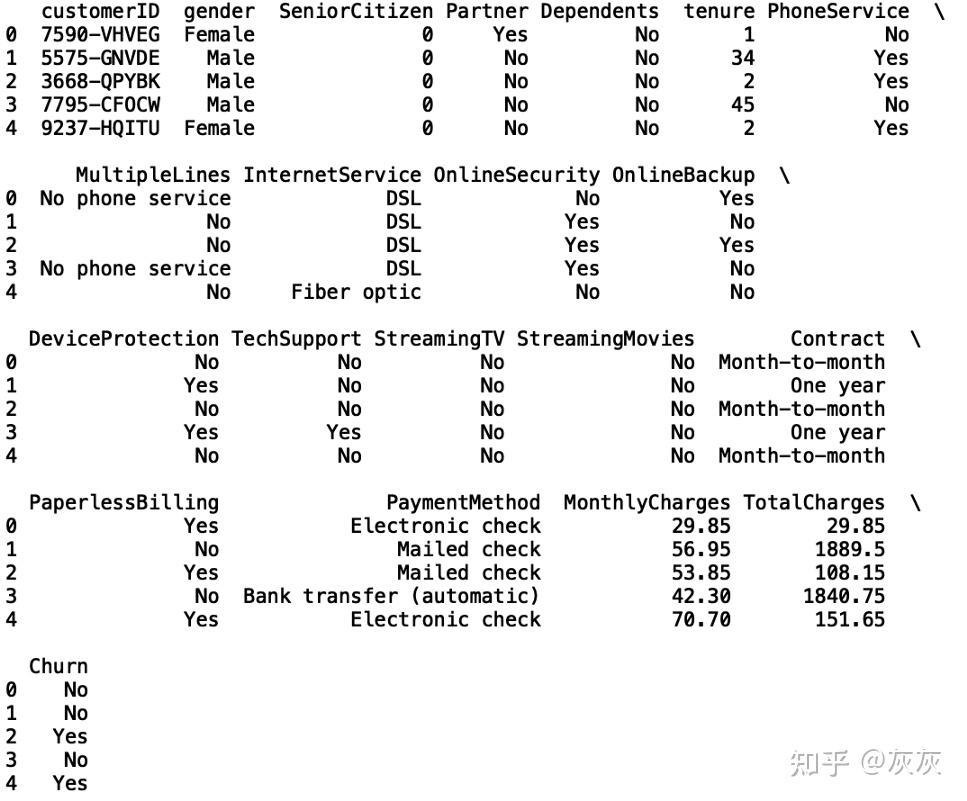
我们看到数据集包含21列,其中既有分类值,也有数值值。数据还包含7,043行,对应7,043个惟一客户。
让我们建立一个简单的模型,以任期(即客户在公司的时间长度和MonthlyCharges)作为输入,并预测客户流失的概率。输出列将是Churn列,其值为yes或no。
首先,让我们修改目标列,使其具有机器可读的二进制值。我们将为Churn列指定,1表示yes,0表示no。我们可以使用numpy中的where方法来实现这一点:
import numpy as np
df[‘Churn’] = np.where(df[‘Churn’] == ‘Yes’, 1, 0)
接下来,让我们定义输入和输出:
X = df[[‘tenure’, ‘MonthlyCharges’]]
y = df[‘Churn’]
然后我们可以分割数据进行训练和测试。为此,我们需要从sklearn的model_selection模块中导入 train_test_split方法。
让我们生成一个占数据67%的训练集,然后使用剩余的数据进行测试。测试集由2325个数据点组成:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
对于我们的分类模型,让我们使用一个简单的逻辑回归模型。让我们从Sklearn中的线性模型模块导入logistic回归类:
from sklearn.linear_models import LogisticRegression
现在,让我们定义logistic回归类的一个实例,并将其存储在一个名为clf_model的变量中。然后,我们将使我们的模型拟合我们的训练数据:
clf_model = LogisticRegression()
clf_model.fit(X_train, y_train)
最后,我们可以对测试数据进行预测,并将预测存储在一个名为y_pred的变量中:
y_pred = clf_model.predict(X_test)
现在我们已经训练了我们的模型,并对测试数据进行了预测,我们需要评估我们的模型做得有多好。
准确率和混淆矩阵
简单而广泛使用的性能指标是准确率。这只是正确预测的总数除以测试集中数据点的数量。我们可以从Sklearn的metric模块中导入accuracy_score方法,并计算准确率。
准确度评分的第一个参数是实际的标签,它们存储在y_test中。第二个参数是预测,它存储在y_pred中:
from sklearn.metrics import accuracy_score
print(“Accuracy: “, accuracy_score(y_test, y_pred))

我们发现我们的模型有79%的预测准确率。尽管这很有用,但我们并不太清楚我们的模型具体预测客户流失或无客户流失的程度。混淆矩阵可以为我们提供更多关于我们的模型在每个结果中表现如何的信息。
如果你的数据不平衡,则必须考虑此度量。例如,如果我们的测试数据有95个“无客户流失”标签和5个“客户流失”标签,通过猜测每个客户的“无客户流失”,它可能会错误地给出95%的准确率。
现在让我们从我们的预测中生成一个矩阵。让我们从Sklearn中的metrics模块导入混淆矩阵包:
from sklearn.metrics import confusion_matrix
让我们生成混淆矩阵数组并将其存储在一个名为conmat的变量中:
conmat = confusion_matrix(y_test, y_pred)
让我们从混淆矩阵数组中创建一个数据帧,称为df_cm:
val = np.mat(conmat)
classnames = list(set(y_train))
df_cm = pd.DataFrame(
val, index=classnames, columns=classnames,
print(df_cm)

那么,这个数字究竟说明了我们模型的性能如何?沿着混淆矩阵的对角线看,让我们注意数字1553和289。数字1553对应于模型正确预测的不流失的客户数量(意味着他们留在公司)。数字289对应于模型正确预测的客户流失数量。
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure()
heatmap = sns.heatmap(df_cm, annot=True, cmap=”Blues”)
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha=’right’)
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha=’right’)
plt.ylabel(‘True label’)
plt.xlabel(‘Predicted label’)
plt.title(‘Churn Logistic Regression Model Results’)
plt.show()

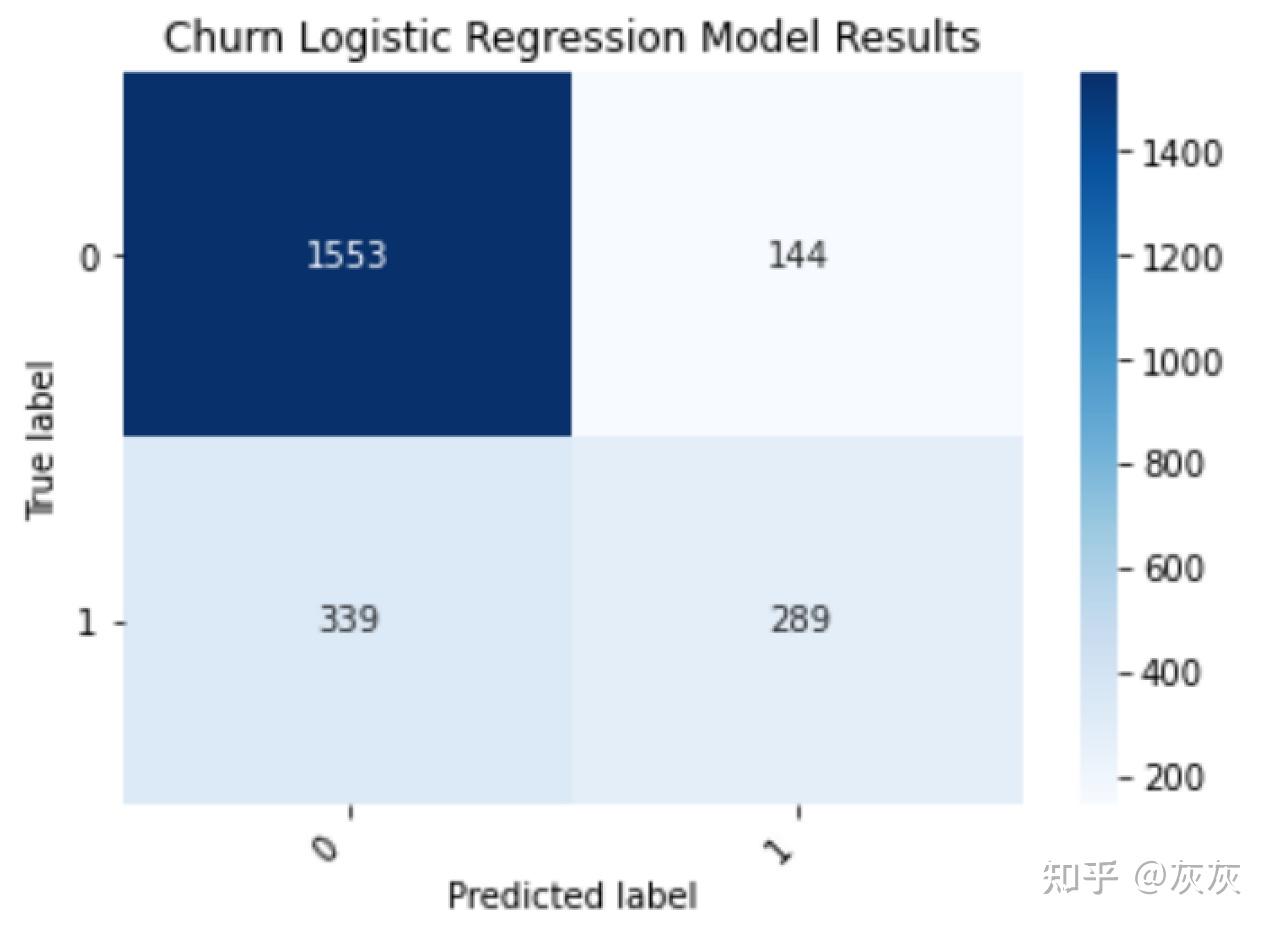
如果我们能把它们显示为总数的百分比,那就更有用了。例如,了解289位正确预测的客户在所有客户流失中所占的百分比是很有用的。我们可以通过在热图之前添加以下代码行来显示每个结果的百分比:
df_cm = df_cm.astype(‘float’) / df_cm.sum(axis=1)[:, np.newaxis]

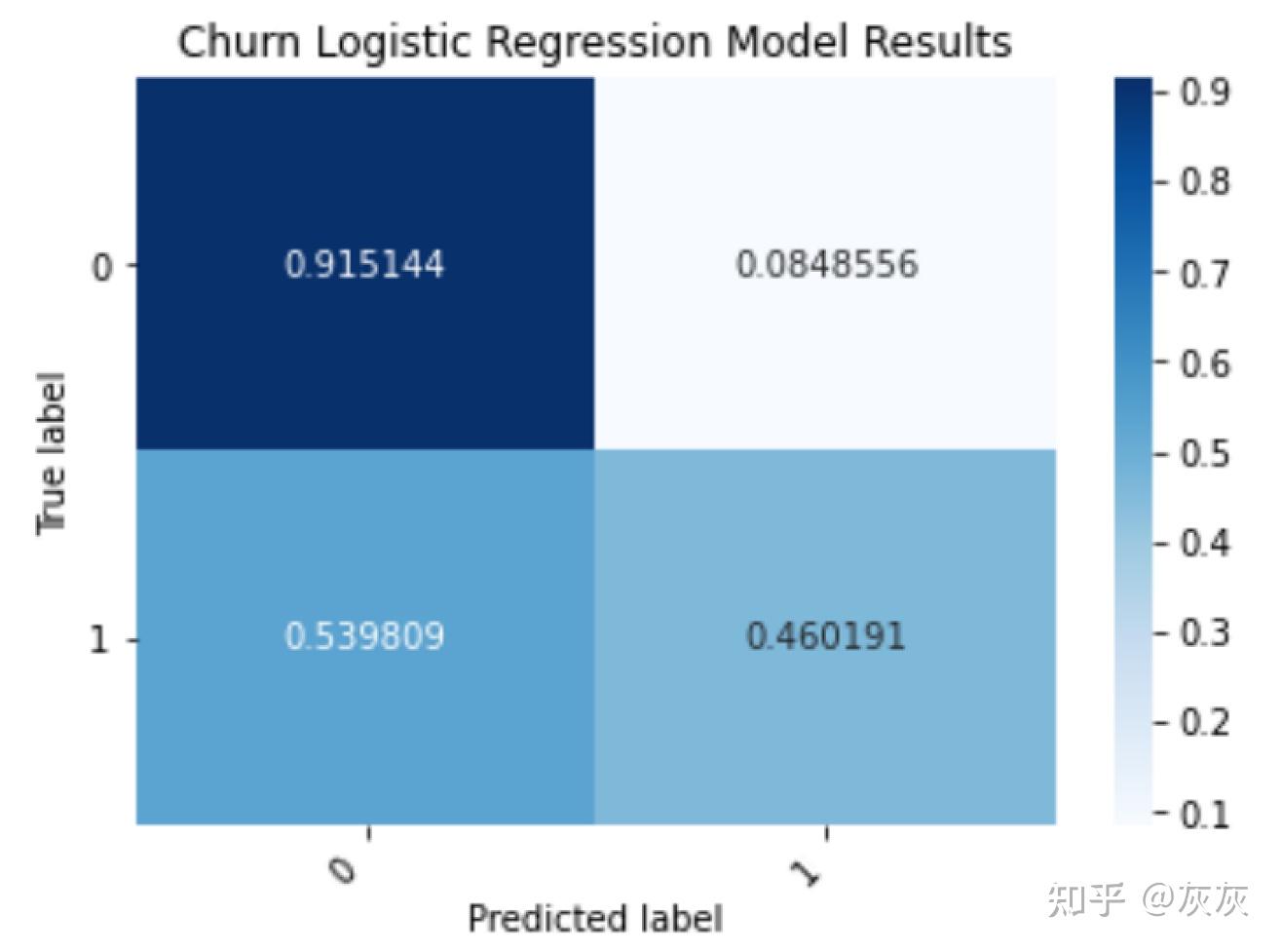
正如我们所见,我们的模型正确预测了91%的不流失客户和46%的流失客户。这清楚地说明了使用准确率的局限性,因为它没有给我们关于正确预测结果百分比的信息。
ROC曲线和AUROC
通常情况下,公司希望使用预测的概率,而不是离散的标签。这允许他们选择阈值,将结果标记为阴性或阳性。
在处理概率时,我们需要一种方法来衡量模型在概率阈值上的泛化程度。到目前为止,我们的算法已经使用默认阈值0.5分配了二元标签,但是根据用例的不同,理想的概率阈值可能更高或更低。
在平衡数据的情况下,理想的阈值是0.5。当我们的数据不平衡时,理想的阈值通常不是0.5。此外,公司有时更喜欢使用概率,而不是完全离散的标签。考虑到预测概率的重要性,了解使用哪些度量来评估它们是很有用的。
AUROC是一种度量模型跨决策阈值的健壮性的方法。它是真阳性率与假阳性率曲线下的面积。真阳性率(TPR)为(真阳性)/(真阳性+假阴性)。假阳性率为(假阳性)/(假阳性+真阴性)。
让我们从计算AUROC开始。让我们从metrics模块导入roc_curve和roc_auc_score方法:
from sklearn.metrics import roc_curve, roc_auc_score
接下来,让我们使用经过训练的模型在测试集上生成预测概率:
y_pred_proba = clf_model.predict_proba(np.array(X_test))[:,1]
然后我们可以计算不同概率阈值的假阳性率(fpr)、真阳性率(tpr):
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
最后,我们可以绘制ROC曲线:
sns.set()
plt.plot(fpr, tpr)
plt.plot(fpr, fpr, linestyle = ‘ — ‘, color = ‘k’)
plt.xlabel(‘False positive rate’)
plt.ylabel(‘True positive rate’)
AUROC = np.round(roc_auc_score(y_test, y_pred_proba), 2)
plt.title(f’Logistic Regression Model ROC curve; AUROC: {AUROC}’);
plt.show()

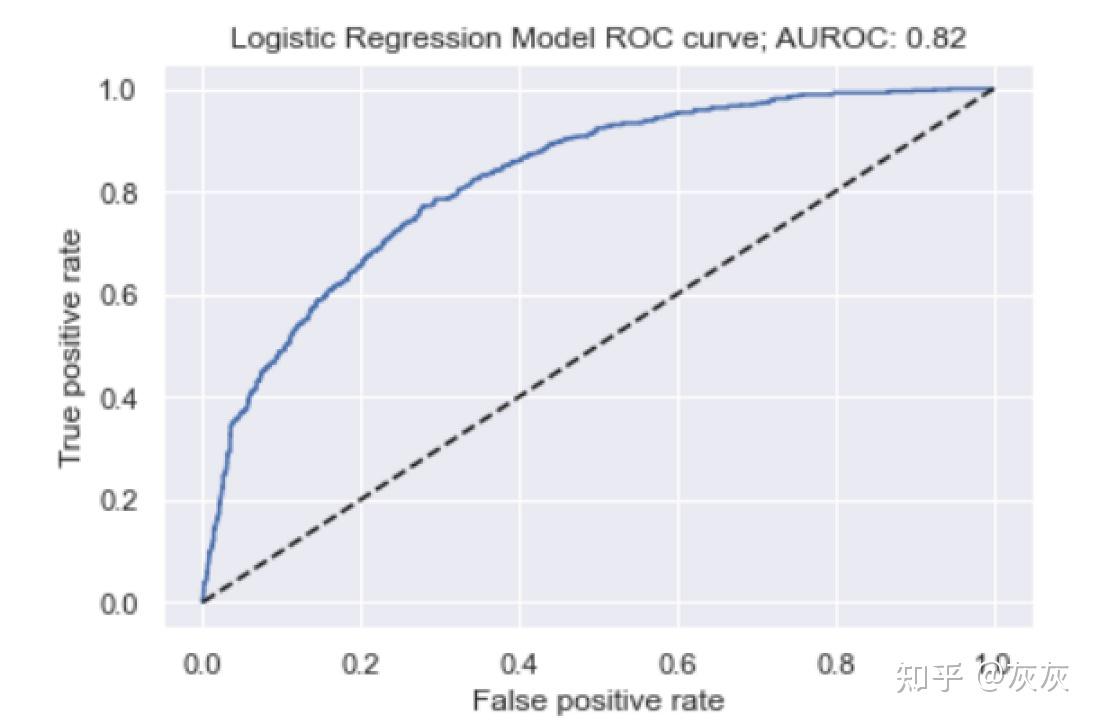
真正速率越快,ROC曲线的行为越好。
因此,我们的模型在ROC曲线方面表现得很好。此外,0.82的AUROC非常好,因为一个完美的模型的AUROC为1.0。我们看到,在使用0.5的默认阈值时,我们的模型正确预测了91%的阴性情况(即不发生翻腾),因此这不应该太令人吃惊。
AUPRC(平均精度)
精确召回曲线下的区域可以很好地理解我们在不同决策阈值之间的精度。精度为(真阳性)/(真阳性+假阳性)。召回率是真正例率的另一个词。
在客户流失的情况下,AUPRC(或平均精度)是衡量我们的模型在多大程度上正确地预测了客户将离开公司。生成精度/召回率曲线并计算AUPRC与我们为AUROC所做的类似:
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
average_precision = average_precision_score(y_test, y_test_proba)
precision, recall, thresholds = precision_recall_curve(y_test, y_test_proba)
plt.plot(recall, precision, marker=’.’, label=’Logistic’)
plt.xlabel(‘Recall’)
plt.ylabel(‘Precision’)