


Pandas面对大数据集,如何将内存占用降低90% (附实例)

第一部分:无从下手的数据集
六个月前,我看到一个不错的“英语学习关键期”的数据集:
但是面对几百兆的文件,用Python的Pandas跑起来时,机器显得力不从心。于是,这块数据就暂时搁置在我的收藏夹里。
最近由于工作中的实际需要,对类似大小的文件做数据分析,成为了一个逃避不了任务。趁着周末搜了一些资料和方法,发现一篇不错的文章:
如何在使用Pandas库时,将内存占用降低90%。
该文在知乎上也有纯翻译的版本: 简单实用的pandas技巧:如何将内存占用降低90%
我自己结合了感兴趣的数据集,将该文章中的代码和方法又细细过了一遍。不仅学了一个新技能,对于Pandas存储数据类型又有了新的认识。
嘿喂狗。
先提一下,怎么才算大数据(Big Data)?
比较粗浅地分类:以100 MB为界限,大于此,我们就归为大数据。单个机器在跑的时候,速度通常会比较慢 — — 甚至会出现由于内存不足,而导致代码运行故障。
虽然有像Spark这样的工具,专门对付超大的数据集(从100 GB到TB级),但是要充分利用好,还需要配套较贵的硬件。况且,这种工具在清理、分析数据时没有Pandas那么好用。如果只是面对中等量的数据,不建议换装备。
以下文章的核心思想,是通过调整数据类型,来大幅度(90%)降低数据运行时对内存的占用。
先来看一下,我手上的数据集:
这是一项对英语学习做的研究。数据存储为csv文件(data.csv),320.4MB。
我们来看一下,
# 导入Python库;导入数据文件为 sll
import csv
import pandas as pd
import numpy as np
sll = pd.read_csv('...data.csv')
# 瞥一眼数据集的前5列
sll.head()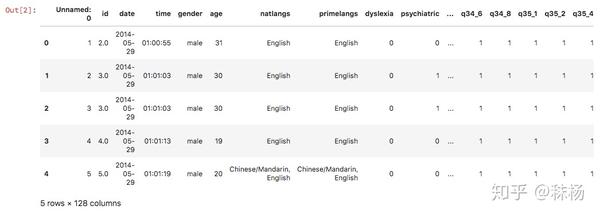
date 实验开始日期
time 实验开始时间
gender 性别
age 年龄
natlangs 测试者母语
dyslexia 测试者是否有阅读障碍?
education 最高教育水平
Eng_start 开始学习英语的年龄
Eng_country_yrs 在英语国家生活年数
countries 生活的国家
correct 题目正确比例
q1, q2, etc.: 题号, “1”回答正确;“0”回答错误
……
有兴趣的,可以在这里看到对所有行的注释:
具体的每一题长什么样,请见在线测试网址:
接下来,我们用 http:// DataFrame.info ( ) 来对整个数据集的形态,数据类型,占据内存大小做一个宏观的了解:
默认情况下,为了节省时间,Pandas在这里会对内存占用做一个粗略估计,但是这正是我们关心的一个特征,所以将memory_usage 设置为“deep”,以得到精确的数值。
sll.info(memory_usage = 'deep')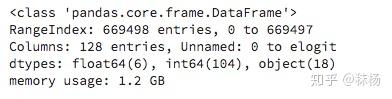
第二部分 Pandas存储数据的类型(开始动手!)
重头戏来了 — —
通过了解Pandas如何存储数据,我们来理解如何调整数据类型,从而降低内存的使用率。
对Python熟悉的读者会知道,数据主要存储为数值型和字符型。前者又分为 int 和 float两种。
以刚才提到的举例:
int型:年龄,是否阅读障碍(0或1),开始学习英语的年龄,等等……
float型:正确题数比例,参与者id,等等……
object型:性别,最高教育水平,生活国家,等等……
在Pandas中,由不同的Block来存储上述三种数据类型:IntBlock, FloatBlock 和 ObjectBlock —— 这样可以加速数据处理的效率。
既然不同的数据类型是独立存储的,那我们来看一下,现有的数据集三种类型的数据(int,float,object)平均占用内存是多少?
for dtype in ['float','int','object']:
selected_dtype = sll.select_dtypes(include=[dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b / 1024 ** 2
print("Average memory usage for {} columns: {:03.2f} MB".format(dtype,mean_usage_mb))
首先,来看一下如何调整数值型数据:Int和Float
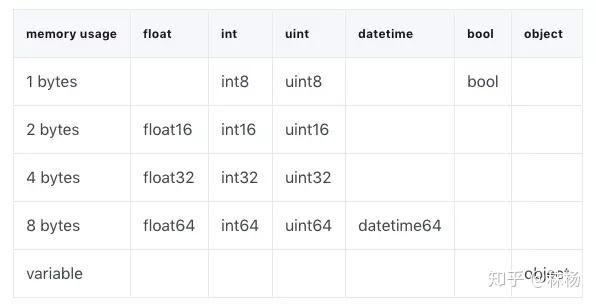

正如上图所示,不同的数据类型包含各自的子类:
比如,一个int8数据占用1byte的内存。在二进制下,它可以代表256,这意味着可以用它来表示十进制下-128到127(包含 0)的数值。
我们用numpy.iinfo看一下不同int子类所能代表的数值范围:
int_types = ["uint8", "int8", "uint16","int16"]
for it in int_types:
print(np.iinfo(it))

我们发现,uint(unsigned integers) 和 int(singed integers)所能覆盖的数值范围是一样的,但是当我们的数值只有正数时,uint类型更有效率。
通过以上知识,我们先对int数据进行调整,看看调整之后的内存占用量有无明显下降:
# 写个function,因为后面还可以重复用到。
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # 我们假设这不是一个df,而是一个 Series
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # 将 bytes 转化成 megabytes
return "{:03.2f} MB".format(usage_mb)
sll_int = sll.select_dtypes(include=['int']) # 用 DataFrame.select_dtypes 来选中表中的 int数据
converted_int = sll_int.apply(pd.to_numeric,downcast='unsigned') # 用pd.to_numeric()来降低我们的数据类型
print(mem_usage(sll_int))
print(mem_usage(converted_int))
compare_ints = pd.concat([sll_int.dtypes,converted_int.dtypes],axis=1)
compare_ints.columns = ['before','after']
compare_ints.apply(pd.Series.value_counts)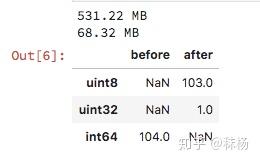
接下来,将刚才的方法应用到float类数据:
sll_float = sll.select_dtypes(include=['float'])
converted_float = sll_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(sll_float))
print(mem_usage(converted_float))
compare_floats = pd.concat([sll_float.dtypes,converted_float.dtypes],axis=1)
compare_floats.columns = ['before','after']
compare_floats.apply(pd.Series.value_counts)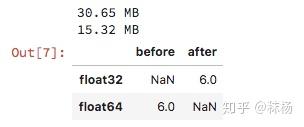
下面,我们把调整完的数据复制,替换原先表中的位置。
看看整体内存占用下降了多少:
optimized_sll = sll.copy()
optimized_sll[converted_int.columns] = converted_int
optimized_sll[converted_float.columns] = converted_float
print(mem_usage(sll))
print(mem_usage(optimized_sll))
真不错!不过降低的比例不到50% — — 那是因为我们还没对object类数据动手呢!
在此之前,我们先看看Pandas是如何存储Object数据的:
Python对字符串的存储方式很碎片化,从而会占用更多内存,访问速度也更慢。
下面这幅图给出了以 NumPy 数据类型存储数值数据和使用 Python 内置类型存储字符串数据的方式:
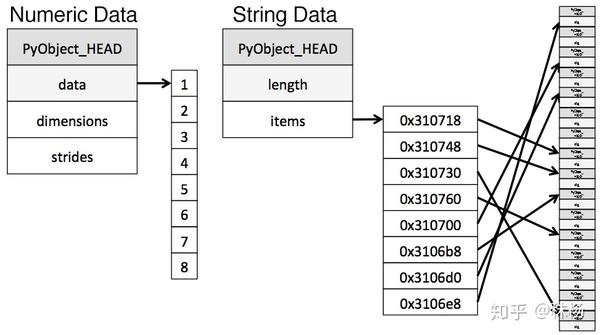
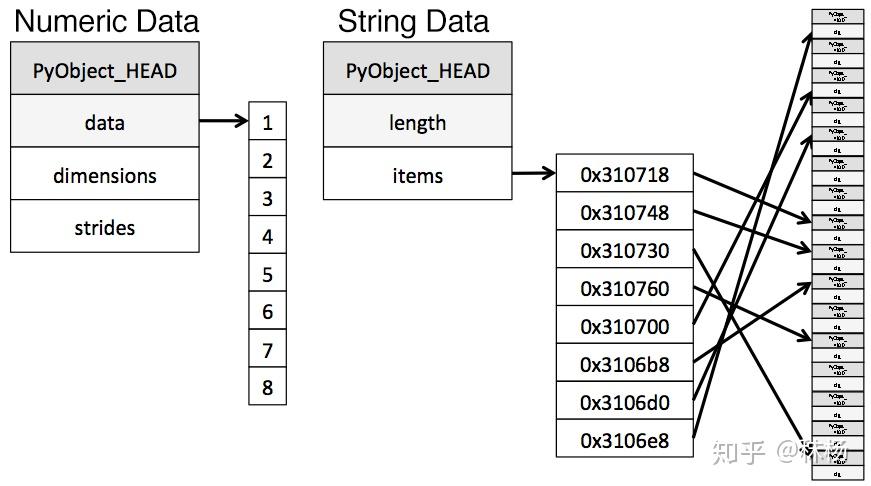
解决思路:在之前的表格中,你可能已经注意到,和数值类数据不同, object 类型的内存使用是可变的。尽管每个指针仅占用 1 字节的内存,但如果每个字符串在 Python 中都是单独存储的,那就会占用实际字符串那么大的空间。我们可以使用 sys.getsizeof() 函数来证明这一点。
from sys import getsizeof
s1 = 'working out'
s2 = 'memory usage for'
s3 = 'strings in python is fun!'
s4 = 'strings in python is fun!'
for s in [s1, s2, s3, s4]:
print(getsizeof(s))
上面的四个数是字符串 s1, s2, s3, s4 占用的内存。我们再看,
obj_series = pd.Series(['working out',
'memory usage for',
'strings in python is fun!',
'strings in python is fun!'])
obj_series.apply(getsizeof)
可以看到,存储在 pandas series 时,字符串的大小与用 Python 单独存储的字符串的大小是一样的。
解决方法:
pandas 在 0.15 版引入了 Categorials。category 类型在底层使用了int值来表示一个列中的值,而不是使用原始值。pandas 使用一个单独的映射词典将这些int值映射到原始值。只要当一个列包含有限的值的集合时,这种方法就很有用。当我们将一列转换成 category dtype 时,pandas 就使用最节省空间的 int 子类型来表示该列中的所有不同值。
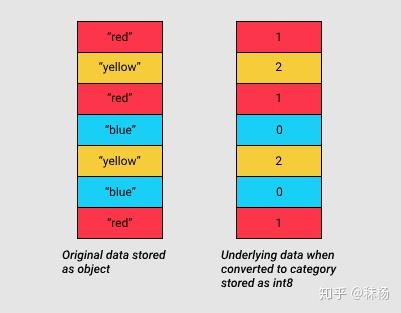
这个方法是否适用于我们手上的数据,要看各个object列内,独立(unique)值的比例如何。
sll_obj = sll.select_dtypes(include=['object']).copy()
sll_obj.describe()

在我们将所有object数据都做调整之前,先挑“gender”列试一下,看看内存改善的效果如何:
我们用.astype()方法将gender列中的数据转换成category。
gd = sll_obj.gender
print(gd.head())
gd_cat = gd.astype('category')
print(gd_cat.head())
你会发现,数据类型变了,但是数值似乎没有任何变化。我们接着用Series.cat.codes看看category用什么样的int类数值来代表原先的object数据:
gd_cat.head().cat.codes
顺便说一句,如果这一列中有空缺值,category会将其处理为-1。
最后,激动人心的时间到了,我们来看看这种调整能降低多少内存空间的占用。
print(mem_usage(gd))
print(mem_usage(gd_cat))
不过,别太得意,该列近66万条数据只有3个值,所以转化后的效果非常漂亮。但是,假设一种极端情况,某一列的所有数值都是独立的,那么如果再转化成category,占用的内存空间反而会更大。这是因为除了原始数据之外,计算机还需要存储int类数据。关于category的局限性,可以看它的文档:
综上,我们遍历所有的object列,如果某一列的unique值少于总数值量的50%,我们就将该列转化为category:
converted_obj = pd.DataFrame()
for col in sll_obj.columns:
num_unique_values = len(sll_obj[col].unique())
num_total_values = len(sll_obj[col])
if num_unique_values / num_total_values < 0.5:
converted_obj.loc[:,col] = sll_obj[col].astype('category')
else:
converted_obj.loc[:,col] = sll_obj[col]
print(mem_usage(sll_obj))
print(mem_usage(converted_obj))
compare_obj = pd.concat([sll_obj.dtypes,converted_obj.dtypes],axis=1)