def gen_stylecloud(text=None,
file_path=None,
size=512,
icon_name='fas fa-flag',
palette='cartocolors.qualitative.Bold_5',
colors=None,
background_color="white",
max_font_size=200,
max_words=2000,
stopwords=True,
custom_stopwords=STOPWORDS,
icon_dir='.temp',
output_name='stylecloud.png',
gradient=None,
font_path=os.path.join(STATIC_PATH,
'Staatliches-Regular.ttf'),
random_state=None,
collocations=True,
invert_mask=False,
pro_icon_path=None,
pro_css_path=None):
使用 Font Awesome 提供的免费图标更改词云的形状。
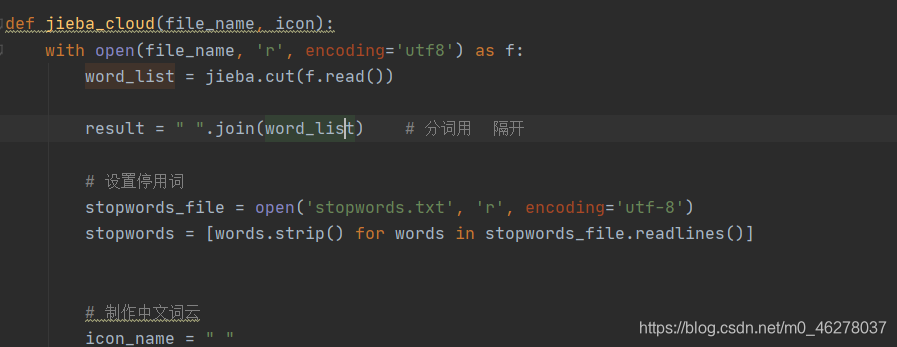
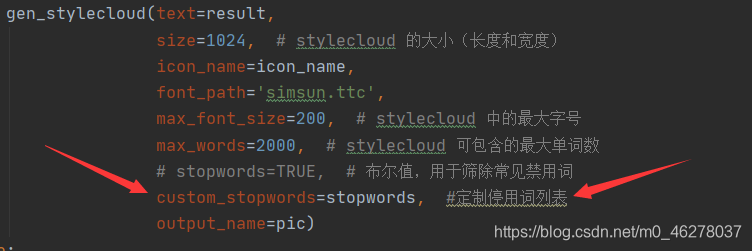
对已爬取的京东商品评论数据进行预处理、文本分词、词频统计、词云展示。分别利用wordcloud库、pyecharts库的WordCloud和stylecloud库绘制词云,熟悉简单制作词云的方法。
词云图可以让我们方便地识别出文本中的关键词,其中单词的大小代表它们的频率。有了这个,我们甚至在阅读之前就可以很好地了解文本的内容。
在本文中,我们将使用第三方 Python 库 stylecloud,有了该库,可以通过简短的几行代码来制作漂亮的词云图。本文来自技术群的小伙伴的分享,在此表示感谢。喜欢点赞、收藏、关注。
【注】文末可以加入我们的技术群
闲话少说,我们直接开始吧。
接下来,我们将用来制作词云图的文本是偶像乔布斯在斯坦福大学演讲的一部分。文末链接可以获得对应的 .txt 文件,当然你也可以使
text=None, #输入字体
file_path=None, # 输入文本/CSV 的文件路径
gradient=None, #渐变方向(梯度方向),默认是horizontal
size=512,
首先是爬取豆瓣影评的短评,保存下来
豆瓣影评每页显示20条评论,我爬取了前面50页的评论,先浏览找到翻页规律,批量生成网页url链接,然后解析每个页面,用的BeautifulSoup,提取评论文字,保存为txt文件
然后将评论生成词云
代码里注释的很清晰了,就不赘述了
爬取评论的代码
#引用time库、random库、requests库、BeautifulSoup4
import time
import ran
注:虽然在短评首页显示《你好,李焕英》共有41万多条短评,但是当浏览时,却发现只能查看前25页的短评,也就是说用户只能看到500条短评评论。发现这个问题后,查阅了一些相关资料,原来是
# 请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'}
1.获得豆瓣影评接口按浏览器F12调试,点开参数,查看url一栏:所有评论:url:https://movie.douban.com/subject/27119724/comments?status=P某一页的评论:url: https://movie.douban.com/subject/27119724/comments?start=40&limit=20&sort=new_score&sta...
爬取过程:
你好,李焕英 短评的URL:
https://movie.douban.com/subject/34841067/comments?start=20&limit=20&status=P&sort=new_score
分析要爬取的URL;
34841067:电影ID
start=20:开始页面
limit=20:每页评论条数
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limi
最近比较火的电影《你好,李焕英》莫名戳中了大家的泪点,应用评论中的一句“妈妈永远比想象中的要爱我们”
虽然我没哭,但看大家都哭了,说明电影不在于多有深意,而是能引起大家共鸣的电影,才是好电影。
(完全瞎编的)
下面我们就来看一下《你好,李焕英》在豆瓣影评中都有哪些优质的评论以及出现最多的词是哪些。
1.确定数据所在的url
https://movie.douban.com/subject/34841067/comments?percent_type=h&limit=20&status=P&a
本文将从何为爬虫、网页结构、python代码实现等方面逐步解析网络爬虫。1. 何为爬虫如今互联网上存储着大量的信息。作为普通网民,我们常常使用浏览器来访问互联网上的内容。但若是想要批量下载散布在互联网上的某一方面的信息(如某网站的所有图片,某新闻网站的所有新闻,又或者豆瓣上所有电影的评分),人为的使用浏览器挨个打开网站搜查则过于费时费力。人为统计过于耗时耗力。因此,编写程序来自动抓取互联网上我们想...