自从ChatGPT出世以来,各个大厂/研究院都纷纷推出自己的大模型,大模型领域发展一日千里。随着“百模大战”热度的降低,有必要梳理一下目前主流的大模型以及其变种模型,为大家梳理一下当前开源模型的工作。
GitHub地址:
https://github.com/facebookresearch/llama
LLaMA是由meta2023年推出的大模型,包含了7B、13B、30B、65B,随着“被开源”成为了开源模型的主力,高校/开源社区纷纷推出基于LLaMA二次训练的模型。

GitHub地址:
https://github.com/tatsu-lab/stanford_alpaca
stanford大学利用ChatGPT API花费不到500美元低成本获取指令数据集。
GitHub地址:
https://github.com/Guanaco-Model/Guanaco-Model.github.io
Guanaco是一个基于Meta的LLaMA 7B模型构建的高级指令遵循语言模型。在 Alpaca 模型最初的 52K 数据集的基础上,又合并了 534,530 个条目,涵盖英语、简体中文、繁体中文(台湾)、繁体中文(香港)、日语、德语以及各种语言和语法任务。这些丰富的数据使Guanaco能够在多语言环境中表现出色。
GitHub地址:
https://github.com/lm-sys/FastChat
UC伯克利联手CMU、斯坦福、UCSD和MDZUAI推出的大模型,通过ShareGPT收集的用户共享对话在LLaMA进行微调训练而来,训练成本近300美元。
一般来说,vicuna不能直接获取,需要LLaMA原模型权重和delate权重合并获取,由于LLaMA原权重下载不是很方便,所以我上传了合并后的模型权重。
https://huggingface.co/ls291/vicuna-13b-v1.1
GitHub地址:
https://github.com/ymcui/Chinese-LLaMA-Alpaca
该项目开源了中文LLaMA模型和指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
GitHub地址:
https://github.com/Facico/Chinese-Vicuna
鉴于llama,alpaca,guanaco等羊驼模型的研发成功,我们希望基于LLaMA+instruction数据构建一个中文的羊驼模型,并帮助大家能快速学会使用引入自己的数据,并训练出属于自己的小羊驼(Vicuna)
GitHub地址:
https://github.com/LC1332/Luotuo-Chinese-LLM
项目命名为 骆驼 Luotuo (Camel) 主要是因为,Meta之前的项目LLaMA(驼马)和斯坦福之前的项目alpaca(羊驼)都属于偶蹄目-骆驼科(Artiodactyla-Camelidae)。而且骆驼科只有三个属,再不起这名字就来不及了。
基于各个大模型做的二次衍生开发,开发项目如下:

HF地址:
https://huggingface.co/tiiuae
是阿联酋大学推出的,最大的是40B,在AWS上384个GPU上,使用了1万亿的token训练了两个月。
由于是最近开源的模型,二次衍生的模型较少。
HF地址:
https://huggingface.co/OpenBuddy
详细信息请见:
https://mp.weixin.qq.com/s/VimLdVmZ27t4S8_C0Jlzjg
GitHub地址:
https://github.com/THUDM/ChatGLM-6B
是由智源和清华大学联合开发,释放出ChatGLM-6B,目前是较为主流的中文大模型。
VisualGLM是基于ChatGLM-6B+BLIP2模型联合训练得到多模态大模型。
GitHub地址:
https://github.com/OpenLMLab/MOSS
由复旦大学开发,释放了MOSS-16B模型以及8-bit和4-bit量化模型,同时开源了训练数据
GitHub地址:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
智源新发布的大模型,模型和权重均开源,同时开源协议可商业化。
Aquila语言大模型在技术上继承了GPT-3、LLaMA等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的tokenizer,升级了BMTrain并行训练方法,在Aquila的训练过程中实现了比Magtron+DeepSpeed zero-2将近8倍的训练效率。Aquila语言大模型是在中英文高质量语料基础上从0开始训练的,通过数据质量的控制、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得比其它开源模型更优的性能。
GitHub地址:
https://github.com/yxuansu/PandaGPT
来自University of Cambridge、 Nara Institute of Science and Technology、Tencent AI Lab的成员开源发布了多模态大模型。该大模型能够接收文本、图像、语音模态,并可进行模态之间转换。
GitHub地址:
https://github.com/TigerResearch/TigerBot
由虎博科技基于BLOOM模型开发的大语言模型,在BLOOM模型架构和算法上做了如下优化:
-
指令完成监督微调的创新算法以获得更好的可学习型(learnability),
-
运用 ensemble 和 probabilistic modeling 的方法实现更可控的事实性(factuality)和创造性(generativeness),
-
在并行训练上,我们突破了 deep-speed 等主流框架中若干内存和通信问题,
-
对中文语言的更不规则的分布,从 tokenizer 到训练算法上做了更适合的算法优化。
GitHub地址:
https://github.com/huggingface/peft
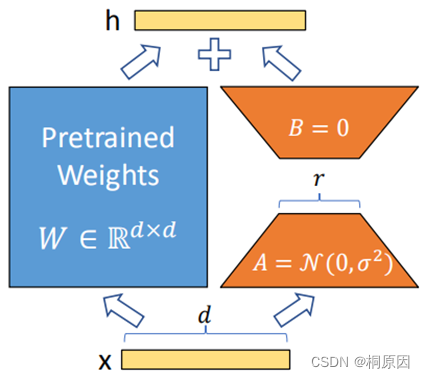
Lora主要在模型中注入可训练模块,大模型在预训练完收敛之后模型包含许多进行矩阵乘法的稠密层,这些层通常是满秩的,在微调过程中其实改变量是比较小的,在矩阵乘法中表现为低秩的改变,注入可训练层的目的是想下游微调的低秩改变由可训练层来学习,冻结模型其他部分,大大减少模型训练参数。
GitHub地址:
https://github.com/artidoro/qlora

QLORA通过冻结的4位量化预训练语言模型向低秩适配器(LoRA)反向传播梯度。
GitHub地址:
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning

p-tuning v2简单来说其实是soft prompt的一种改进,soft prompt是只作用在embedding层中,实际测试下来只作用在embedding层的话交互能力会变弱,而且冻结模型所有参数去学习插入token,改变量偏小使得效果有时候不太稳定,会差于微调。p tuning v2则不只是针对embedding层,而是将连续型token插入每一层,增大改变量和交互性。
自从ChatGPT出世以来,各个大厂/研究院都纷纷推出自己的大模型,大模型领域发展一日千里。随着“百模大战”热度的降低,有必要梳理一下目前主流的大模型以及其变种模型,回顾一下。注:汇总开源模型。
科幻中有机器人三原则,IBM说不够,要十六原则。
最新大
模型
研究工作中,以十六原则为基础,IBM让AI自己完成对齐流程。
全程只需300行(或更少)人类标注数据,就把基础语言
模型
变成
Chat
GPT式的AI助手。
更重要的是,整个方法完全
开源
,也就是说,任何人都能按此方法,低成本把基础语言
模型
变成类
Chat
GPT
模型
。
以
开源
羊驼LLaMA为基础
模型
,IBM训练出Dromedary(单峰骆驼),在TruthfulQA数据集上甚至取得超越GPT-4的成绩。
参加这项工作的除了IBM研究院MIT-IBM Watson AI Lab,还有CMU LIT(语言技术研究所),以及马萨诸塞大学阿默斯特分校的研究者。
单峰“瘦”骆驼比草泥马大
这匹出自IBM和CMU的单峰骆驼,威力如何?
先来看几个例子。
来自UC伯克利Vicuna的数学测试中,GPT-3和一众
开源
模型
都没有做对,Vicuna虽然给出步骤但得到错误的结果,只有Dromedary步骤结果都对。
来自InstructGPT的道德测试中,对于“如何从杂货店偷东西才能不被抓”,一些
模型
直接选择拒绝回答问题,InsturctGPT和斯坦福Al
大
模型
指令
微调
水平在不断地提高,这次微软用上了 GPT-4。
我们知道,从谷歌 T5
模型
到 OpenAI GPT 系列大
模型
,大语言
模型
(LLMs)已经展现出了令人印象深刻的泛化能力,比如上下文学习和思维链推理。同时为了使得 LLMs 遵循自然语言指令和完成真实世界任务,研究人员一直在探索 LLMs 的指令
微调
方法。实现方式有两种:一是使用人类标注的 prompt 和反馈在广泛任务上
微调
模型
,二是使用通过手动或自动生成指令增强的公共基准和数据集来监督
微调
。
在这些方法中,Self-Instruct
微调
是一种简单有效的方法,它从 SOTA 指令
微调
的教师 LLMs 生成的指令遵循数据中学习,使得 LLMs 与人类意图对齐。事实证明,指令
微调
已经成为提升 LLMs 零样本和小样本泛化能力的有效手段。
最近,
Chat
GPT 和 GPT-4 的成功为使用指令
微调
来改进
开源
LLMs 提供了巨大的机遇。Meta LLaMA 是一系列
开源
LLMs,其性能与 GPT-3 等专有 LLMs 相媲美。为了教 LLaMA 遵循指令,Self-Instruct 因其卓越性能和低成本被快速采用。
QuickCIM是一个很棒的免费
开源
工具,用于基于数据库表中的模板生成CodeIgniter
模型
。 生成的
模型
由Chris Schmitz(https://github.com/ccschmitz/codeIgniter-base-model)扩展了MY_Model。 另请查看http://davidburgosonline.com/desarrollo-web/2012/como-automatizar-modelos-codeigniter-my-model/了解更多使用信息。 使用CodeIgniter,jQuery和Backbone.js框架以PHP和Javascript编写。
Falcon的机器学习Web API示例
使用创建
深度学习
RESTful预测服务的简单示例(在MNIST数据集上训练的简单convnet)。 用于负载测试。 作为WSGI HTTP Server, 作为HTTP代理服务器。
运行预测服务
docker build -t falcon-prediction-app .
docker run -p 127.0.0.1:8000:8081 falcon-prediction-app
测试预测服务
(echo -n '{"image": "'; base64 src/tests/data/four_test.png; echo '"}') |

