齐鲁网 ·闪电新闻4月24日讯 “五一”假期即将来临,为更好地满足乘客出行需求,青岛地铁将于4月30日至5月5日压缩行车间隔、延长运营时间,让市民和游客畅行无忧。
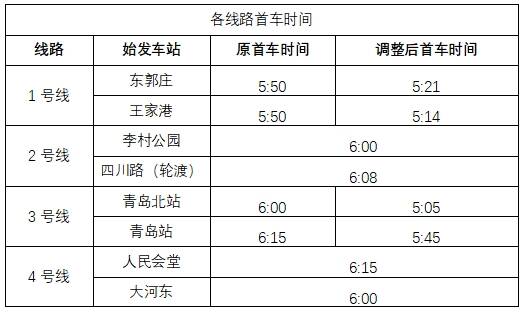
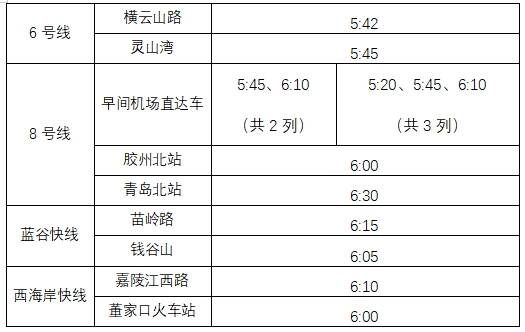
一、首车时间具体调整情况
首车时间调整日期:2025年5月1日至2025年5月5日。
(1)1号线东郭庄站首车时间由5:50提前至5:21,王家港站首车时间由5:50提前至5:14。
(2)3号线青岛北站首车时间由6:00提前至5:05,青岛站首车时间由6:15提前至5:45。
(3)8号线青岛北站至胶东机场早间机场直达列车在原5:45、6:10始发2列基础上,在5:20增加始发1列,共计开行3列。
(4)其他线路首车时间不做调整。
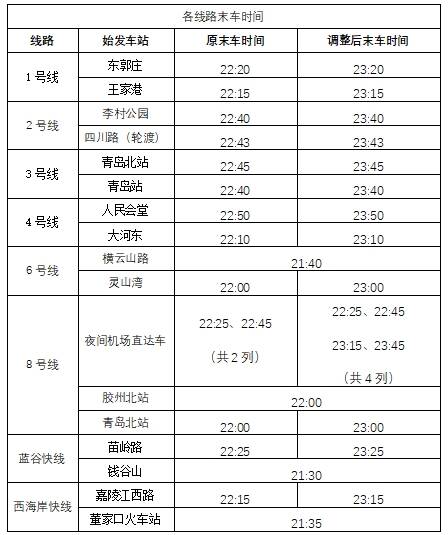
二、末车时间具体调整情况
末车时间调整日期:2025年4月30日至2025年5月5日。
(1)1号线东郭庄站末车时间由22:20延后至23:20,王家港站末车时间由22:15延后至23:15。
(2)2号线李村公园站末车时间由22:40延后至23:40,四川路(轮渡)站末车时间由22:43延后至23:43。
(3)3号线青岛北站末车时间由22:45延后至23:45,青岛站末车时间由22:40延后至23:40。
(4)4号线人民会堂站末车时间由22:50延后至23:50,大河东站末车时间由22:10延后至23:10。
(5)6号线灵山湾站末车时间由22:00延后至23:00,横云山路站末车时间不做调整。
(6)8号线青岛北站末车时间由22:00延后至23:00,胶州北站末车时间不做调整。8号线胶东机场至青岛北站夜间机场直达列车在原22:25、22:45始发2列的基础上,分别在23:15、23:45各增加始发1列,共计开行4列。
(7)蓝谷快线苗岭路站末车时间由22:25延后至23:25,钱谷山站末车时间不做调整。
(8)西海岸快线嘉陵江西路站末车时间由22:15延后至23:15,董家口火车站末车时间不做调整。