


A/B测试(AB实验)的基础、原理、公式推导、Python实现和应用


A/B测试(A/B Testing),又称A/B实验(AB实验)、A/B试验(AB试验)、对照试验,双盲试验、正交试验。
A/B测试(AB实验)是数据驱动的重要手段,广泛应用于互联网产品、设计、搜索、推荐系统、广告系统、增长黑客、用户增长、数据分析、数字化运营、智能营销等领域。互联网从业者(产品、运营、设计、市场、营销、前端、后端、数据、算法、管理者、创始人)必须懂得或者掌握A/B测试,否者数据时代你还是传统互联网思维,没有数据思维,没有互联网思维。
A/B测试(AB实验)也广泛应用于自然科学、心理学、经济学、生物医药等领域,是开展科学研究的重要手段,比如国药新冠疫苗、辉瑞新冠疫苗、科兴新冠疫苗、康希诺新冠疫苗等的三期临床试验,其实也是A/B测试。
本文从0到1搭建A/B测试(AB实验)的知识体系。首先,回顾了A/B 测试的概念、本质、流程等基础知识,并且补充大样本、小样本、正态分布、Z分布、t 分布、卡方分布、中心极限定理、原假设、备择假设、第Ι类错误、第ΙΙ类错误、显著性水平、P值、统计功效、置信区间、效应量、MDE、MDES等A/B测试涉及的统计学基础知识;接着,从试验设计、抽样理论、假设检验等方面介绍A/B测试的原理;然后,介绍Microsoft A/B测试、Airbnb A/B测试、推荐系统的A/B测试、新冠疫苗的 A/B测试,A/B测试工具等;最后,对A/B测试进行总结,指出A/B测试的本质的本质、A/B测试的价值,不适用的场景和经验。
本文主要目录如下:
1. A/B测试基础
1.1. A/B测试的概念
1.2. A/B测试的本质
1.3. 伪A/B测试
1.4. A/B测试的流程
1.5. 统计学基础
1.5.1. 大样本、小样本
1.5.2. 正态分布
1.5.3. Z 分布
1.5.4. t 分布
1.5.5. χ^2 分布(卡方分布)
1.5.6. 中心极限定理
1.5.7. 原假设、备择假设
1.5.8. 第Ι类错误、第ΙΙ类错误
1.5.9. 显著性水平
1.5.10. p 值
1.5.11. 统计功效
1.5.12. 置信区间、置信水平
1.5.13. 效应量
1.5.14. MDE、MDES
2. A/B测试原理
2.1. 试验设计
2.1.1. 试验误差
2.1.2. 试验设计的基本原则
2.1.3. 试验设计的变量
2.1.4. 试验设计的方法
2.2. 抽样理论
2.2.1. 分层抽样
2.2.2. 确定样本量
2.3. 假设检验
2.3.1. Z 检验
2.3.2. t 检验
2.3.3..X^2 检验
3. A/B测试应用
3.1. Microsoft的A/B测试
3.2. Airbnb的A/B测试
3.3. 推荐系统的A/B测试
3.4. 新冠疫苗的A/B测试(双盲试验)
3.5. A/B测试的主要工具
4. A/B测试总结
4.1. A/B测试的本质的本质
4.2. A/B测试的价值
4.3. A/B测试不适用
4.4. A/B测试的经验
直接上PPT。


传统产品、运营、设计、营销、算法等总结式工作方式,慢而且错误概率大。
但以A/B测试为手段的数据驱动方式,速度快且科学,更高效发现商业机会。
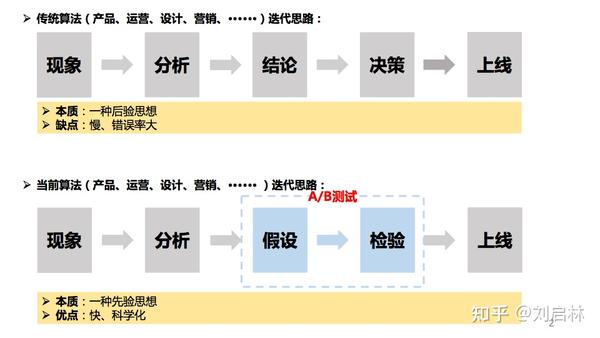
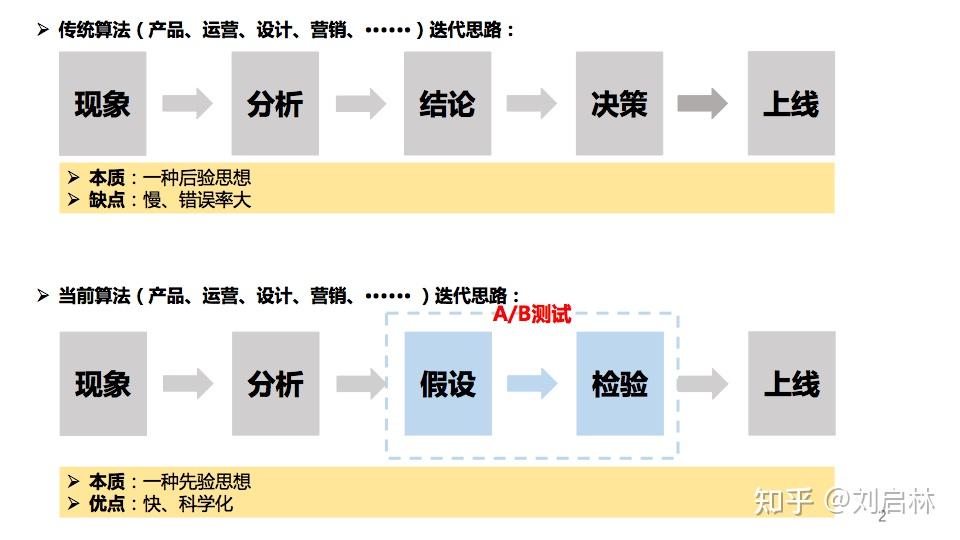
A/B测试是数据驱动的重要手段。


常见的A/B测试工具,它们的输入,输出都是什么?
powerandsamplesize 输入是: 样本量(Sample Size)、统计功效(Power)、显著性水平 (Type Ι error rate)。
字节跳动的 DataTester 输出是: 置信区间(confidence interval)、p值(p-value)、检验灵敏度(MDE)。


那么是怎样从输入到输出的吗?
即怎么实现A/B测试?
这就是本文核心内容,构建完整的A/B测试原理架构。
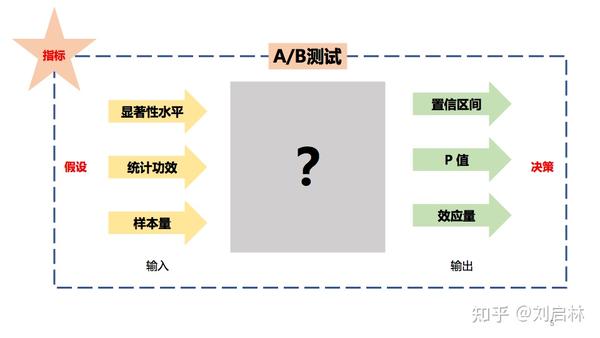
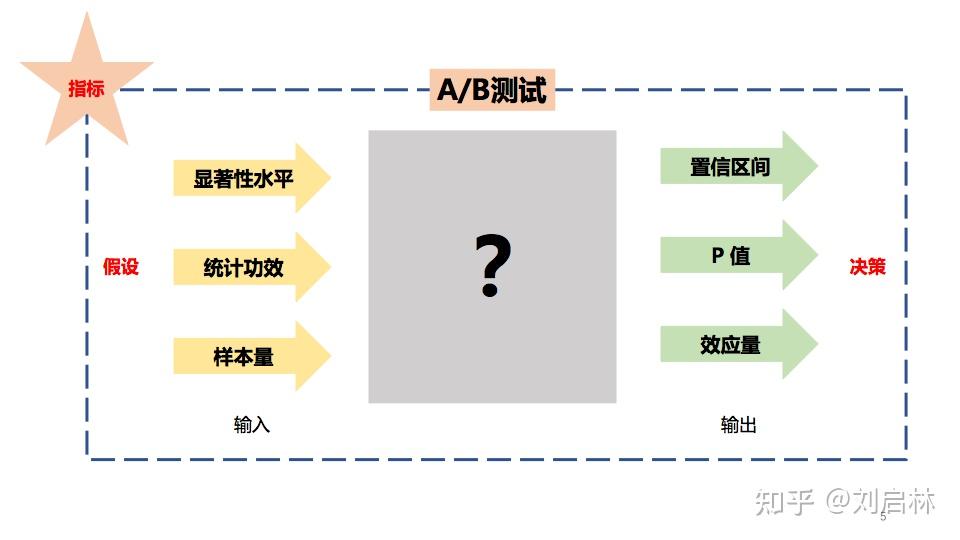
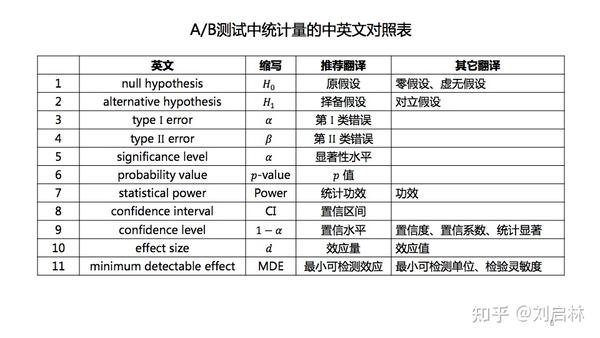
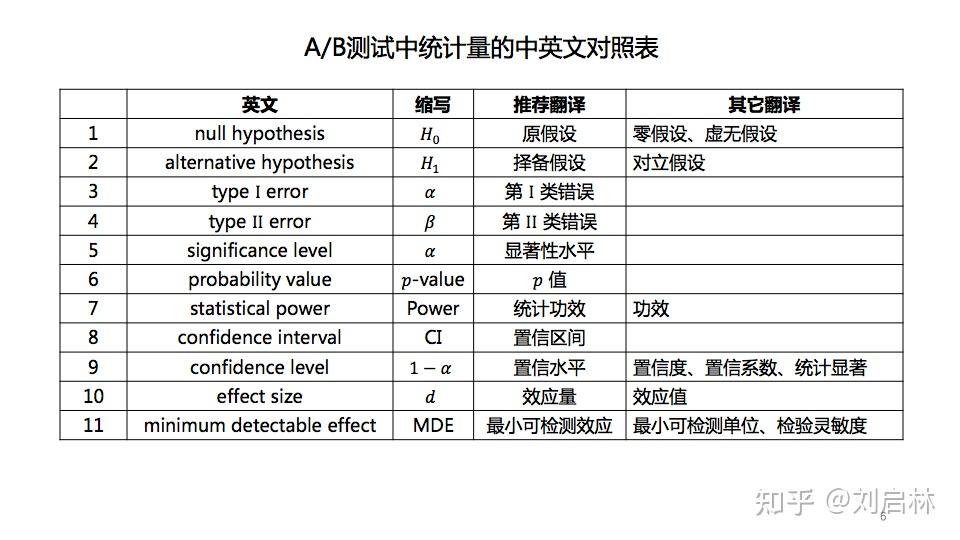
我们先给出A/B测试中常见的统计术语,统一度量衡便于沟通交流。
1. A/B测试基础
1.1. A/B测试的概念
什么是A/B测试?
A/B测试是一种随机测试(试验),将两个不同的东西(A、B)进行假设比较。


A/B测试也称对照试验(Controlled Experiments)、双盲试验(Double Blind Clinical Trial)。
A/B测试的核心步骤:假设、检验。


1.2. A/B测试的本质
A/B测试的本质是试验,具体就是对照试验。


那么试验与实验有什么区别?
试验是探索未知。比如空间试验、医药试验。
实验是测试已知。比如物理实验、化学实验。
但生活中人们常常不对“试验”与“实验”进行区分,统称“AB实验”。
为了简便,本文也不对实验和试验进行区分。


很多大型互联网公司都有试验文化,比如亚马逊、微软等。
你的老板有试验基因?
你的公司有试验文化?
你的 leader 有试验思维?


1.3. 伪A/B测试
那么从反面看,什么不是A/B测试?
比如:假设不清楚,与目标不相关,用户分流不科学等。


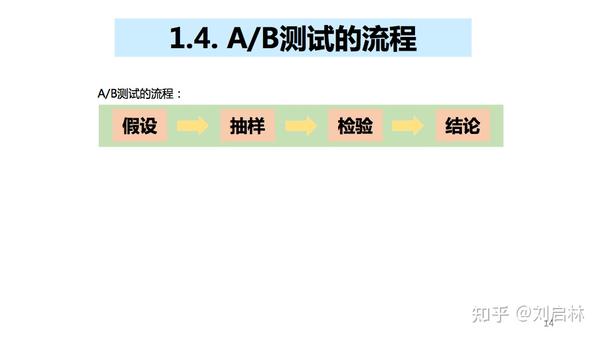
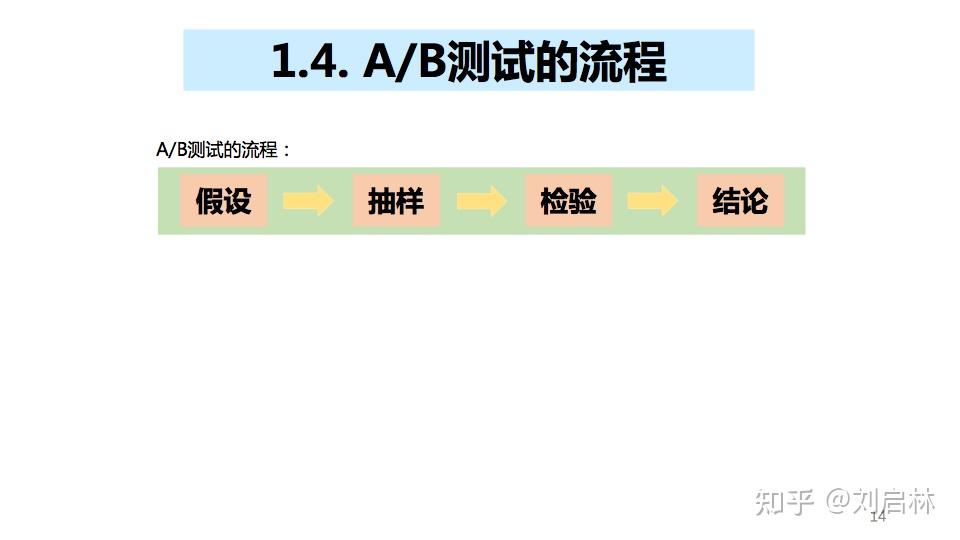
1.4. A/B测试的流程
A/B测试的流程:假设、抽样、检验、结论。
A/B测试的统计学基础:试验设计、抽样理论、假设检验。
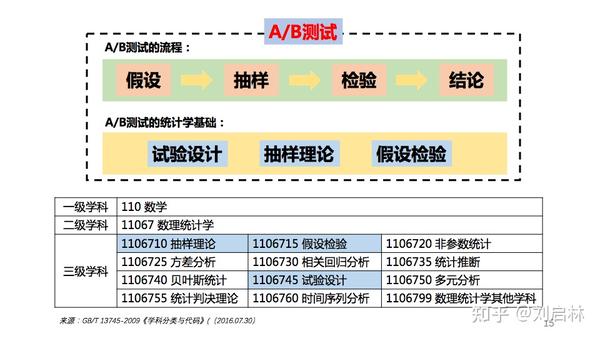
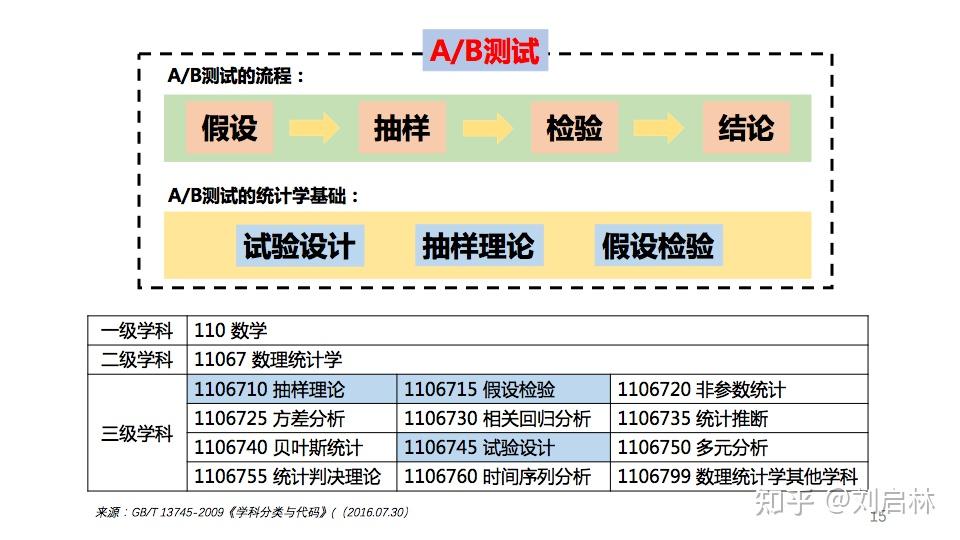
A/B测试串联统计学的基础知识。


为此,我们先补充一些统计学基础知识。
1.5. 统计学基础
A/B测试涉及的统计学基础知识的三级目录如下:
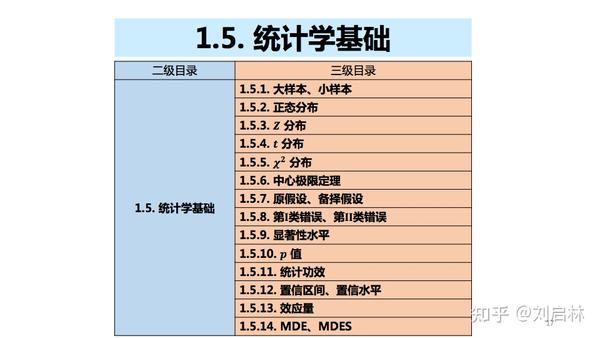
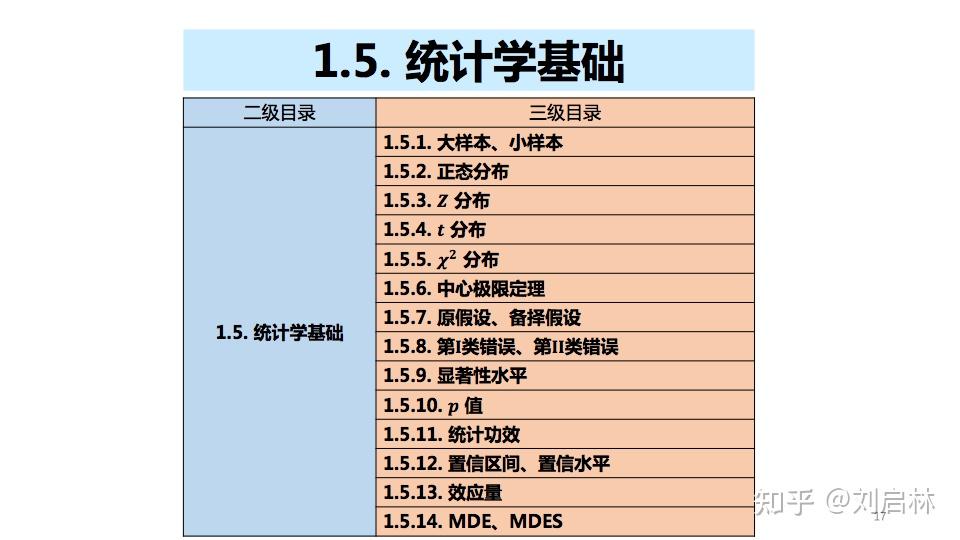
1.5.1. 大样本、小样本
大样本、小样本之间并不是以样本量大小来区分的。


1.5.2. 正态分布
什么是正态分布?


正态分布的期望不同、标准差不同的对比图如下:
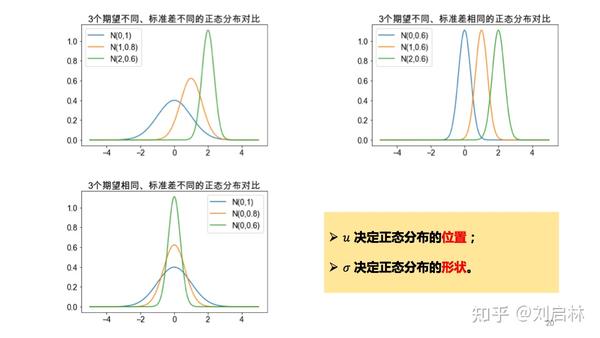
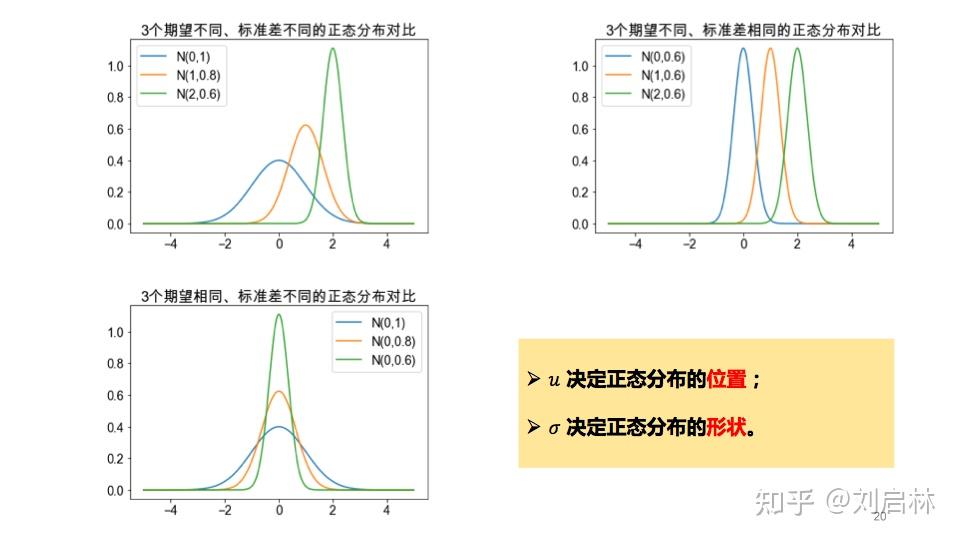
1.5.3. Z 分布
什么是Z分布?
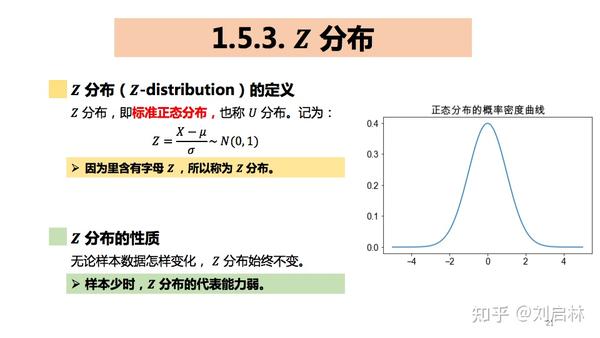
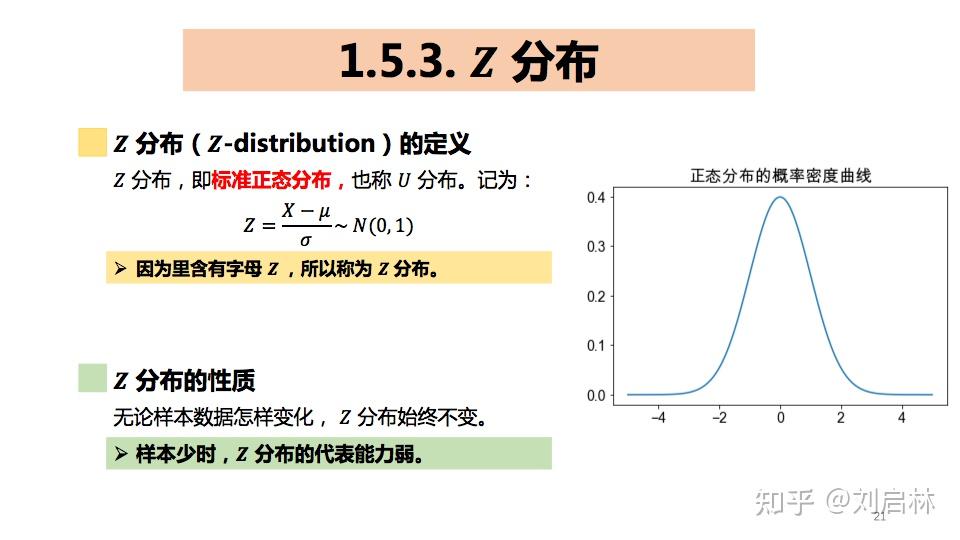
Z分布的Python实现如下:
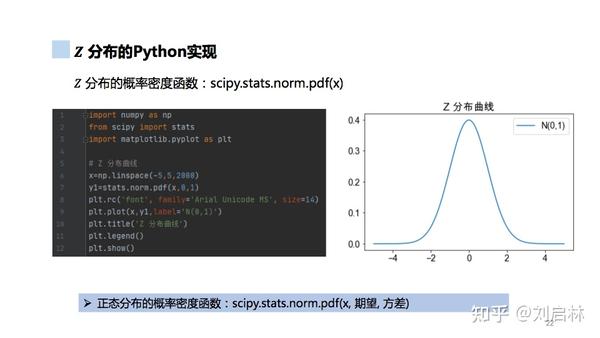
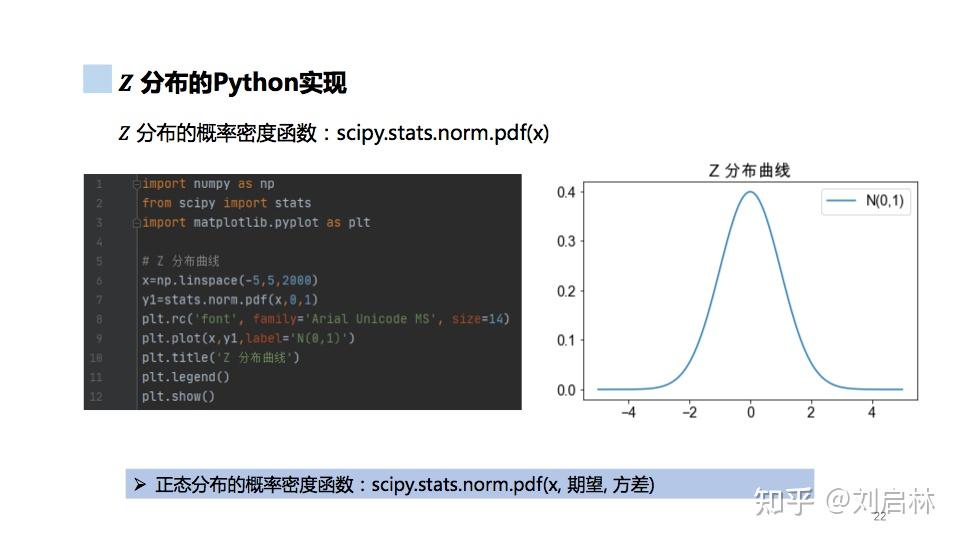
1.5.4. t 分布
什么是 t 分布?
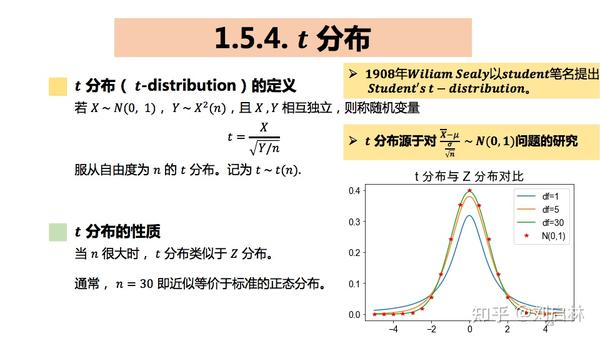
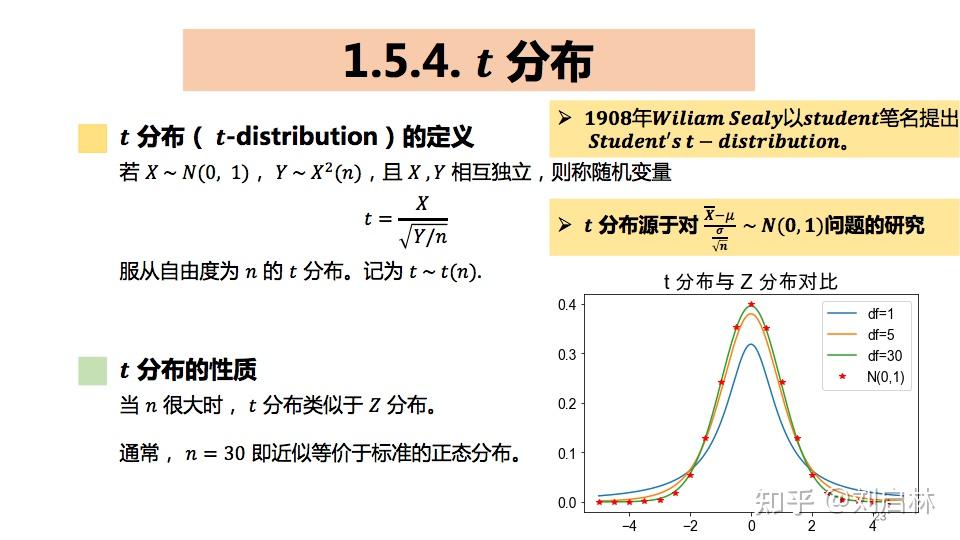
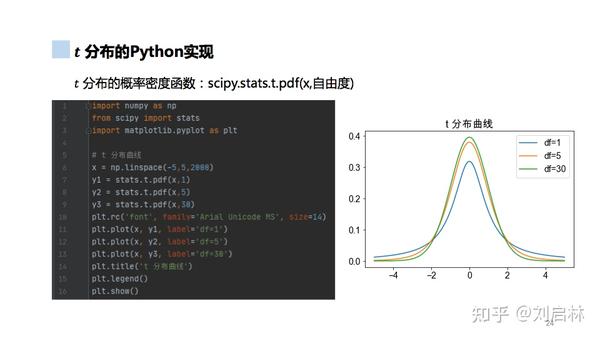
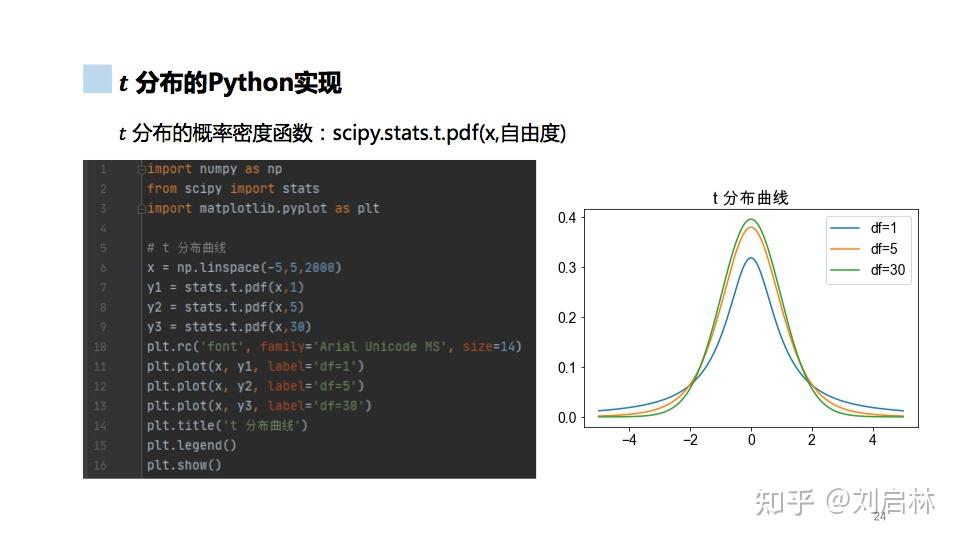
t 分布的Python实现如下:
从上图很容易发现:当 n=30 , t分布与Z分布近似。
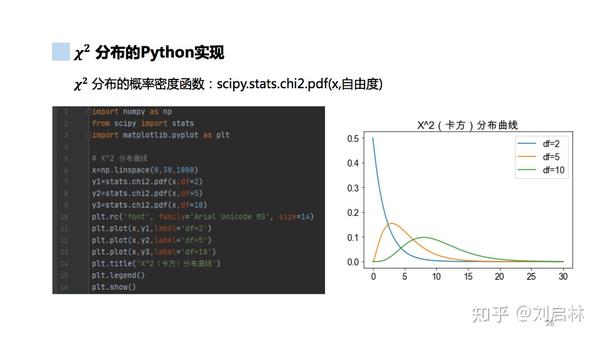
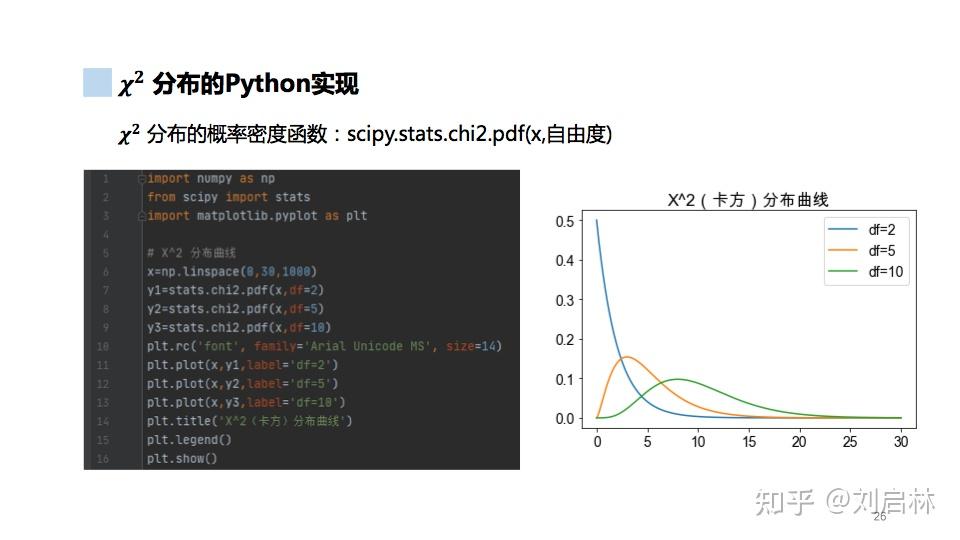
1.5.5. χ^2 分布
什么是卡方分布?


卡方分布的Python实现如下:
1.5.6. 中心极限定理
习惯于把 和的分布 收敛于 正态分布 的那 一类定理 都叫做“中心极限定理”。


1.5.7. 原假设、备择假设
统计学中, 假设是关于总体的陈述 ,可分为原假设和备择假设。


A/B测试中的 原假设是指AB组指标 无显著差异; 备择假设是指AB组指标 有显著差异 。


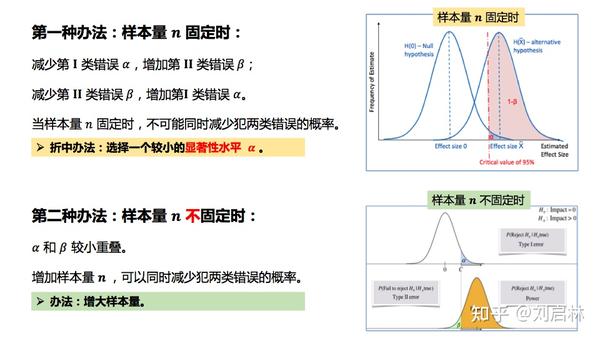
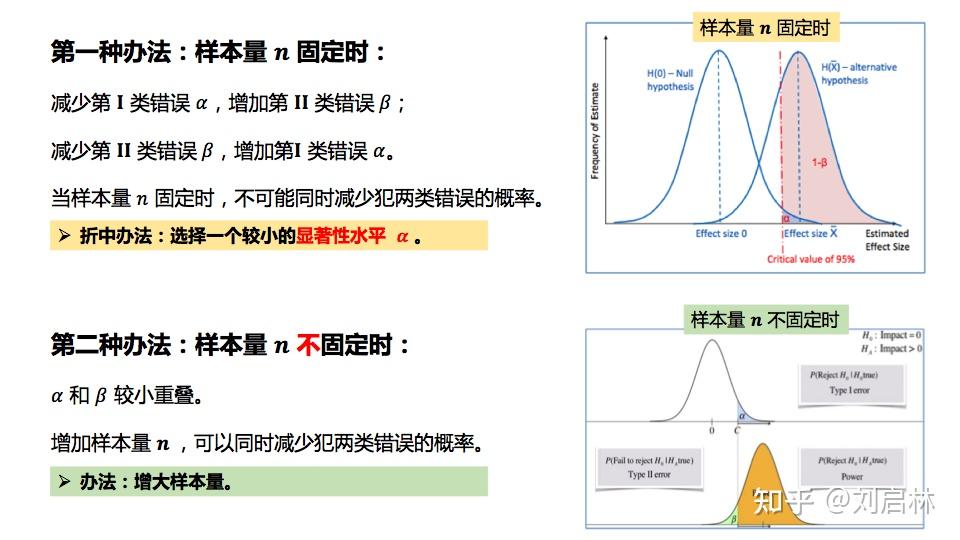
1.5.8. 第Ι类错误、第ΙΙ类错误
统计假设可能会存在两种决策错误(误判):真、伪。


什么是第Ι类错误、第ΙΙ类错误?


假设检验中各种可能结果的概率及统计意义如下:


怎样减少第Ι类错误、第ΙΙ类错误?
1.5.9. 显著性水平
显著性水平(significance level),使得犯第 Ι 类错误的概率 控制在一给定的水平下 ,这个水平就是显著性水平,在此基础上使犯第 ΙΙ 类错误的概率尽可能小。


1.5.10. p 值
定义1:p 值(probability value, p -value)在观测数据下拒绝原假设的最小 显著性水平 。
定义2:p 值是指拒绝原假设 犯第 Ι 类错误 的最小概率。
定义3:p 值代表观察到的 随机因素 产生的差异概率。


p 值的计算:


1.5.11. 统计功效
统计功效(statistical power),不犯 第ΙΙ类错误( 1-β ) 的概率。
A/B实验中的统计功效:当AB两组差异真的存在时,能正确判断的概率。


统计功效的计算:


从统计功效计算公式可知,统计功效的影响因素:两总体差异(效应量)、显著性水平 α、样本量 n。但是,在这 3 个影响因素中,显著性水平 α 是提前给定,只有样本量 n 是可以控制的。


1.5.12. 置信区间、置信水平
什么是置信区间(Confidence Interval)、 置信水平(Confidence Level) ?


置信水平也称为置信度、 置信系数、统计显著。
正态分布的置信区间的公式推导如下:


正态分布的置信区间的例子计算如下:


其中95%置信区间的含义 :若反复抽样多次,每个样本值确定一个区间,在这么多的区间中,包含 μ 的约占95%,不包含 μ 的约仅占 5%。
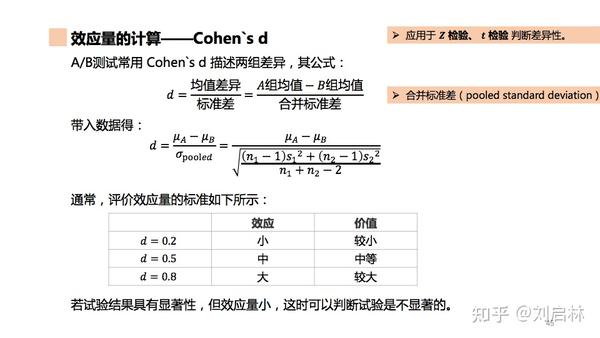
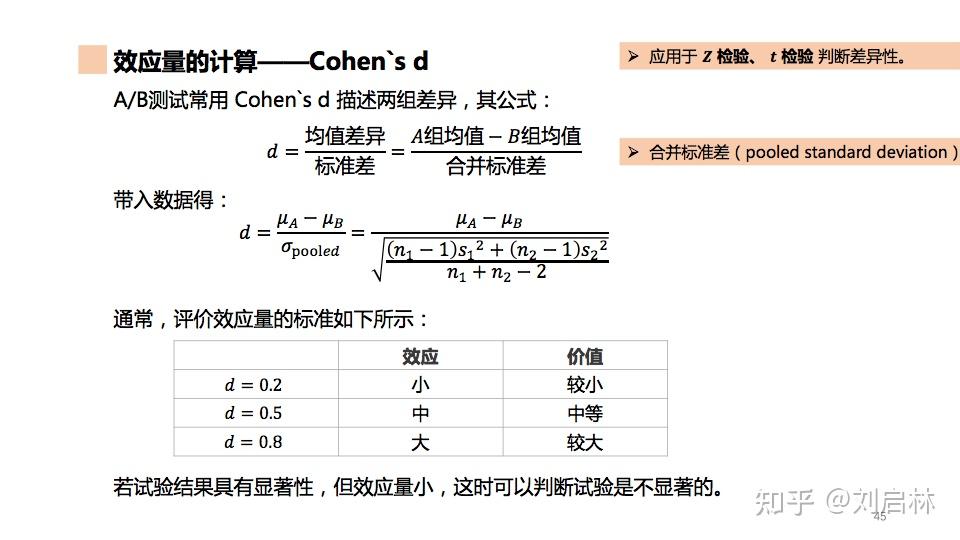
1.5.13. 效应量
效应量(Effect Size,又称效应值),提供了对效应大小的具体测量。


效应量的特征:不依赖样本量,不依赖测量尺度,效应量的正负号仅表示效应的方向,其绝对值才是实际的效应大小。


效应量的计算——Cohen`s d
效应量的计算——Cramer`s V


1.5.14. MDE、MDES
Minimum Detectable Effect (MDE) ,即最小检测效应,也称检验灵敏度。


Minimum Detectable Effect Size (MDES),MDE 与 MDES 是等价,但 MDE 的使用更普遍。
MDE 的计算公式可分为:Z 检验的 MDE 公式和 t 检验的 MDE 公式。


P值、置信区间、效应量是衡量试验结果的三个最重要的指标。


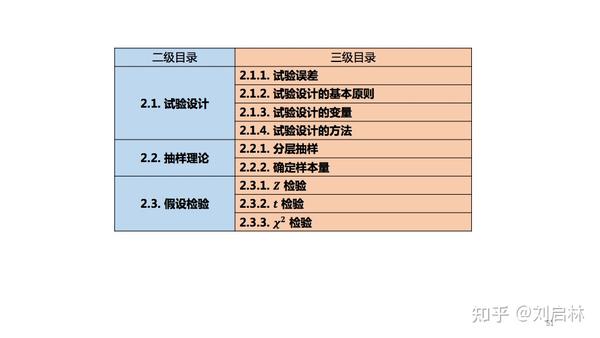
2. A/B测试原理
A/B测试原理的三级目录如下:

2.1. 试验设计
试验设计(Design of Experiment,DOE)。
利用数学和统计学的方法来设计试验方案,称为统计试验设计,简称试验设计。


2.1.1. 试验误差
试验误差可分为:随机误差、系统误差、过失误差。
什么是试验的随机误差?


什么是试验的系统误差、过失误差?


精心设计试验 ,可以减少系统误差,避免过失误差的干扰。所以,在科学试验前提下,我们忽略系统误差、过失误差。
2.1.2. 试验设计的基本原则
试验设计的基本原则:重复、随机化、分区组。
也可以说:不符合重复、随机化、分区组原则的,不是科学试验。


2.1.3. 试验设计的变量
试验中需考察的变量称为因素或因子。
在科学试验的前提下,影响试验只有:因素和随机。


2.1.4. 试验设计的方法
试验设计的方法有因子试验设计(Factorial Experimental Design)、正交试验设计(Orthogonal Experimental Design)等。
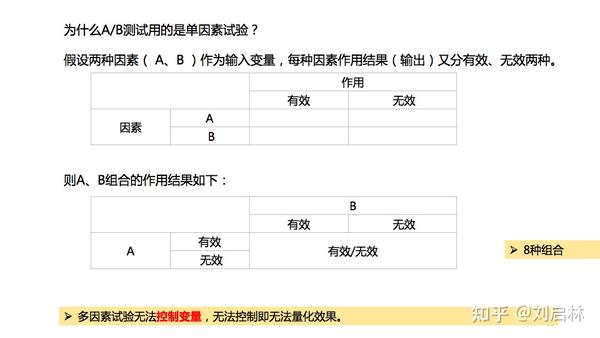
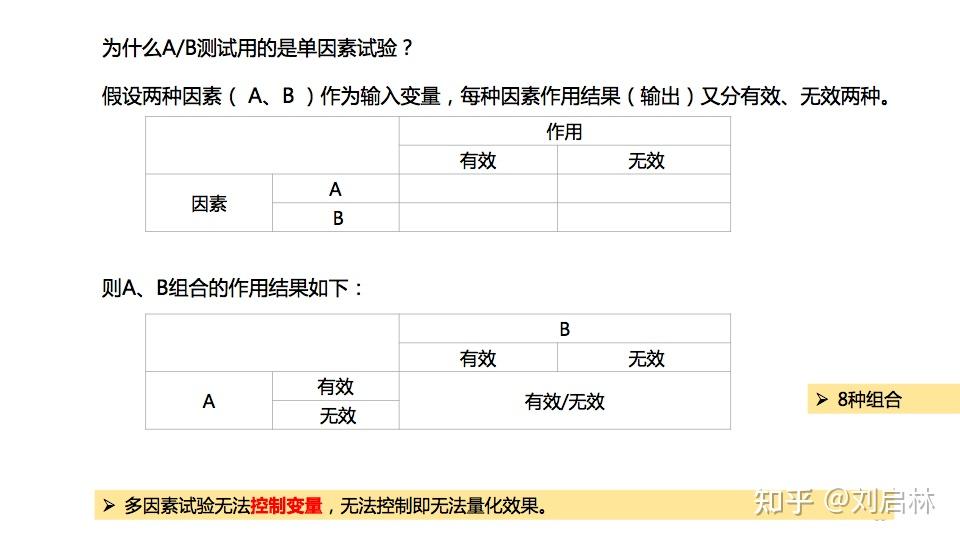
A/B测试用的是因子试验设计中的单因素试验方法。
单因素试验是指一个试验中只选择了一个要考虑的因素。


为什么A/B测试用的是单因素试验?
因为多因素试验无法 控制变量 ,无法控制即无法量化效果。
2.2. 抽样理论
抽样(Sampling)就是从研究总体中选取一部分 代表性样本 的方法。


2.2.1. 分层抽样
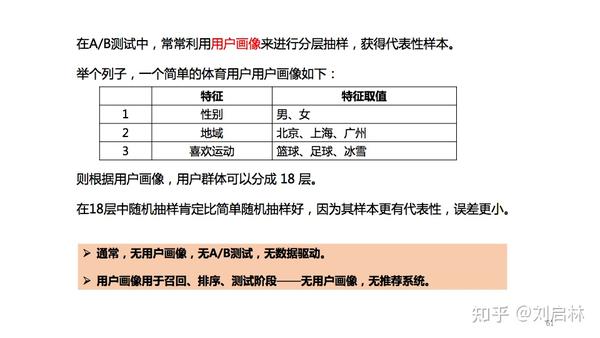
将抽样单元按某种 特征 或某种 规则 划分为不同的层,然后从不同的层中独立、随机地抽取样本。


A/B测试使用用户画像来进行分层抽样,获得代表性样本。
更多用户画像知识可参考:
举个利用用户画像进行抽样的例子。
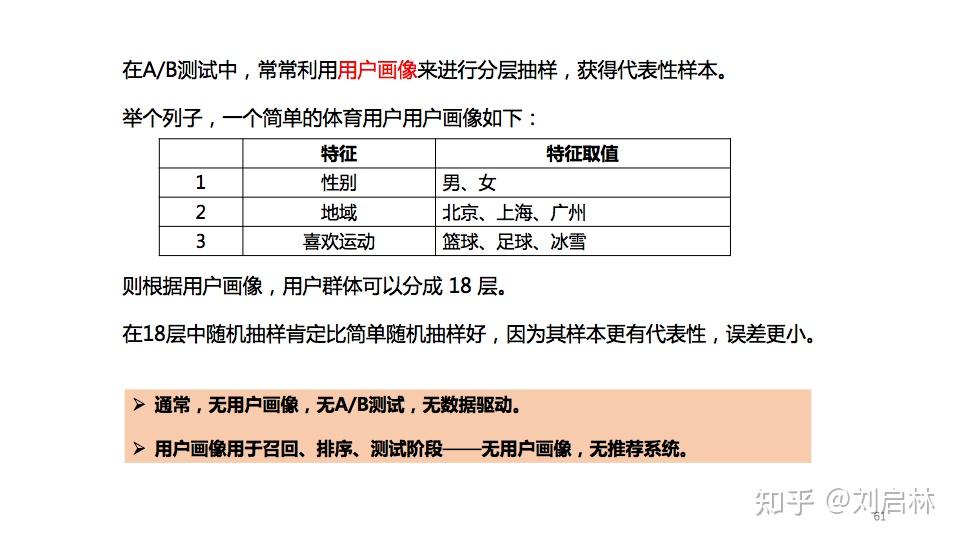
2.2.2. 确定样本量
试验前,通常要设置样本量大小。


举个计算样本量的例子。


2.3. 假设检验
假设检验(Hypothesis Testing)是用来判断样本与样本, 样本与总体的差异 是由抽样误差引起,还是由本质差别造成的统计推断方法。
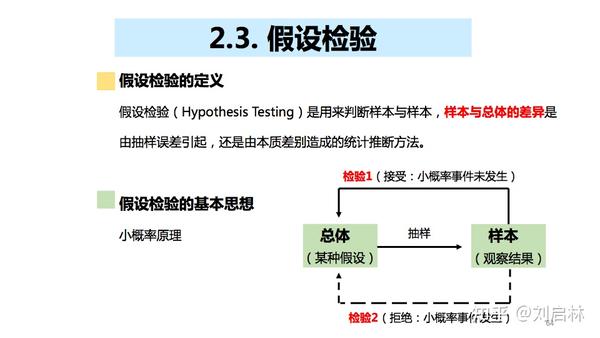
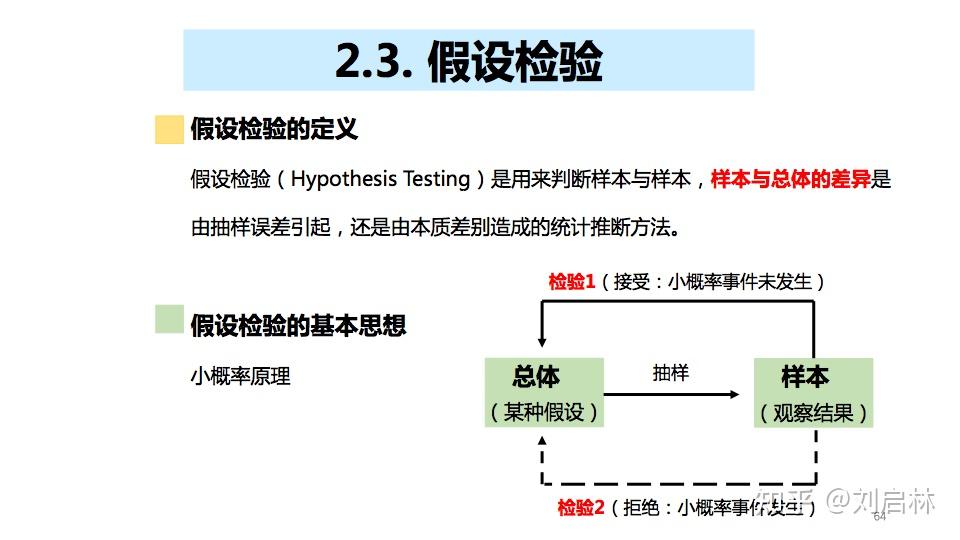
假设检验的步骤:
第一步:先对总体的特征作出某种假设;
第二步:然后通过抽样研究的统计推理;
第三步:对此假设应该被拒绝还是接受作出判断。


2.3.1. Z 检验
Z检验( z test)用 Z 分布 理论来 推断差异发生的概率 ,从而判定平均数的差异是否显著。


两个总体均值之差的估计(大样本的估计):


举个 Z 检验的例子:
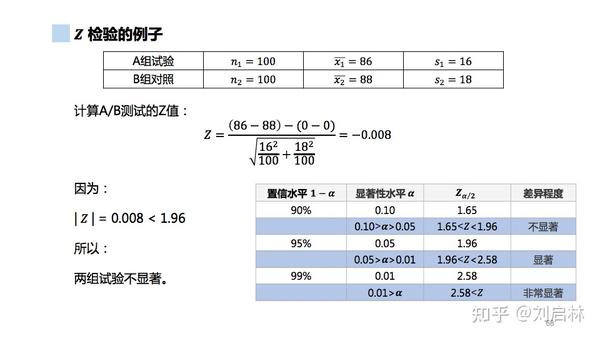
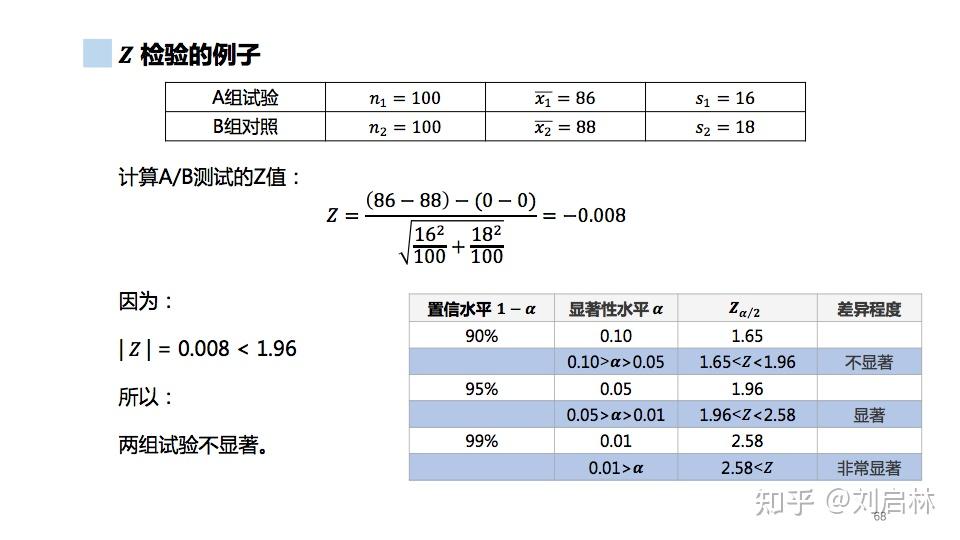
Z 检验的Python实现如下:
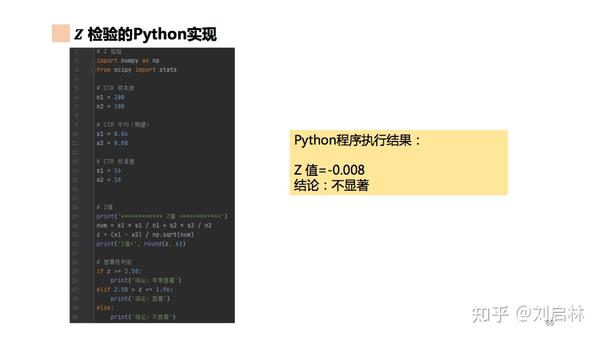
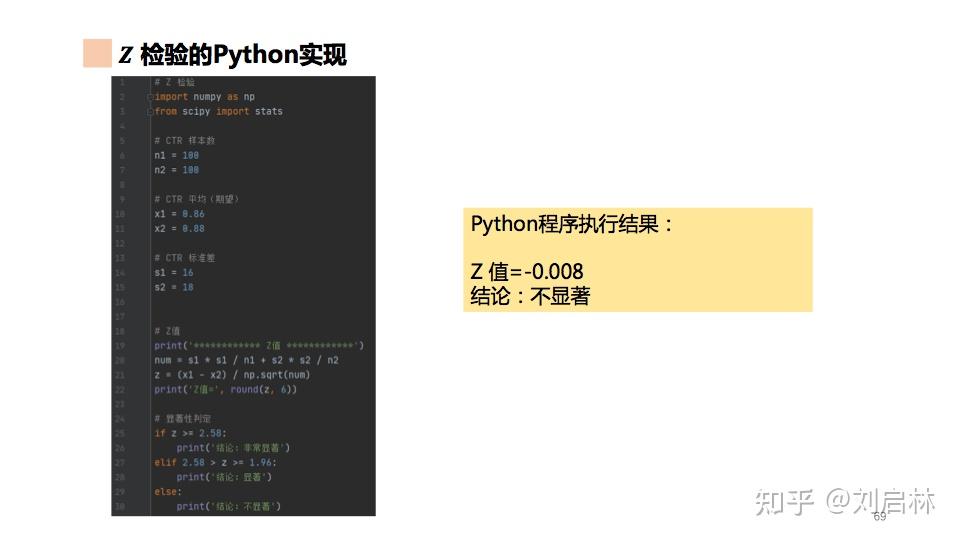
2.3.2. t 检验
t 检验(Student‘s t test)用 t 分布理论来 推断差异发生的概率 ,从而判定两个平均数的差异是否显著。


两个总体均值之差的估计(小样本的估计):


两组样本时, Z 检验与 t 检验的对比如下:
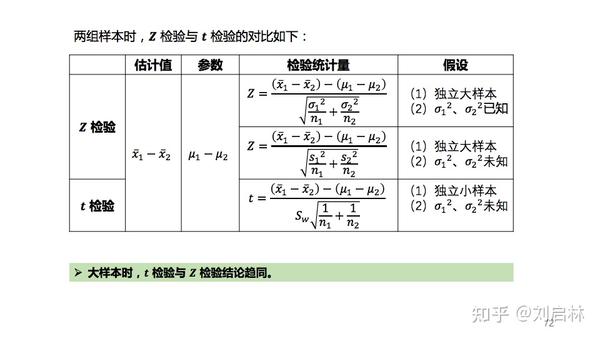

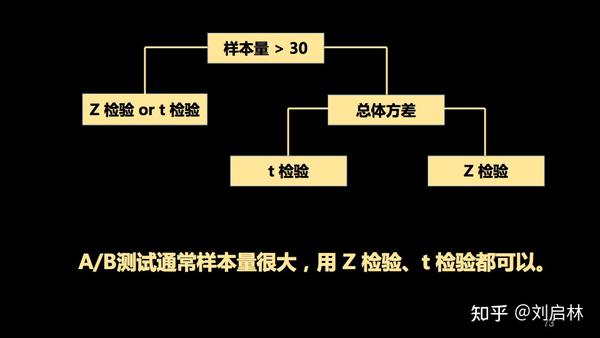
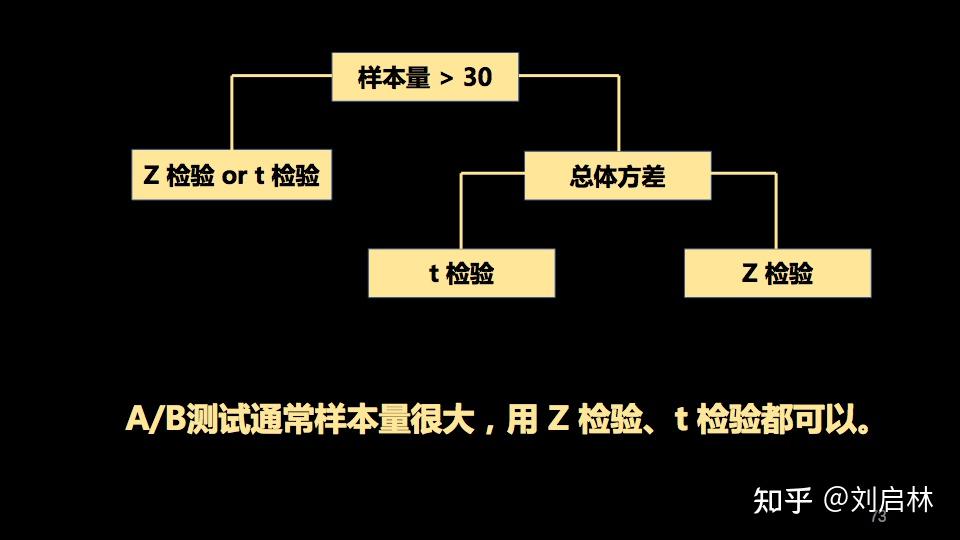
怎样选择 Z 检验和 t 检验?
A/B测试通常样本量很大,用 Z 检验、t 检验都可以。
注意,假设检验也有局限:
- 假设检验更多地关注数据而非假设
- 显著性并不能反应业务价值的大小


2.3.3..X^2 检验
卡方检验是指用 χ^2 分布 理论来检验样本数据与总体分布是否符合,从而判定样本偏差是否显著。可以用于检验抽样是否合理。

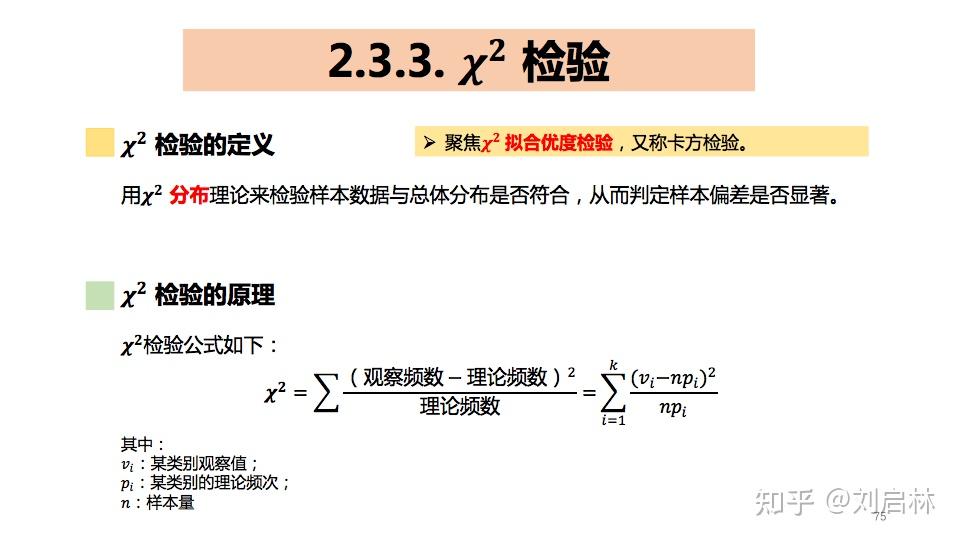
举个卡方检验的例子。


至此,我们知道A/B测试的理论基础:试验设计、抽样理论、假设检验。
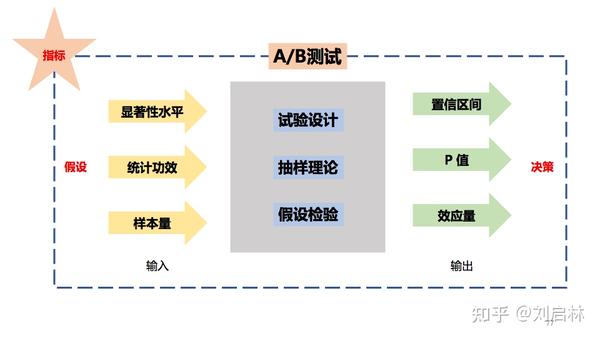
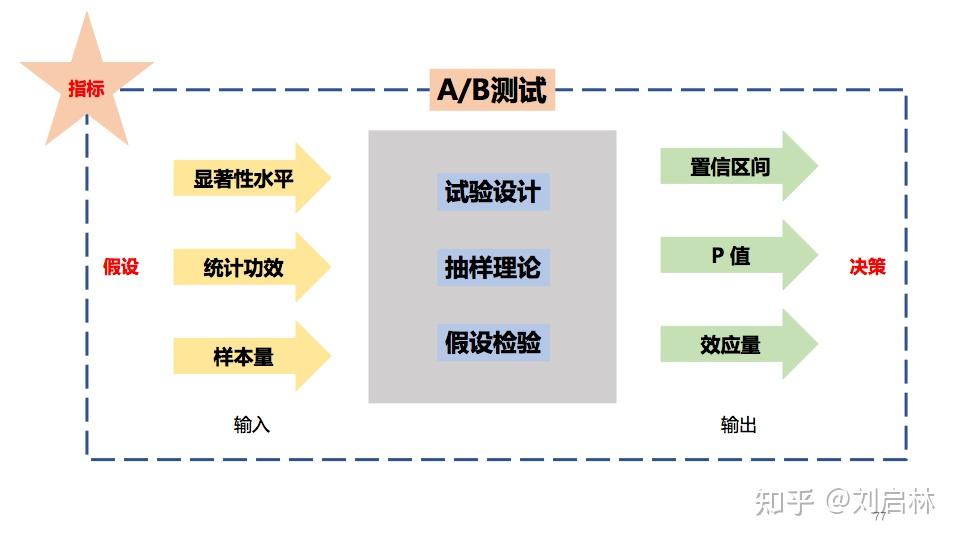
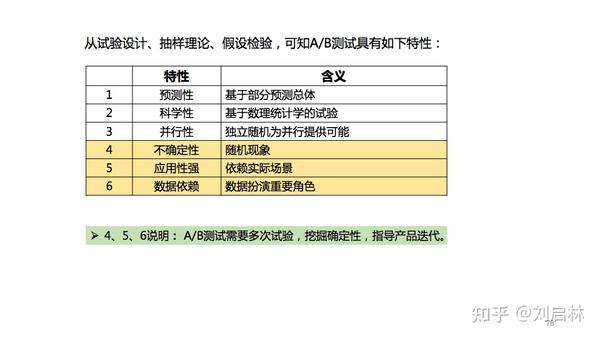
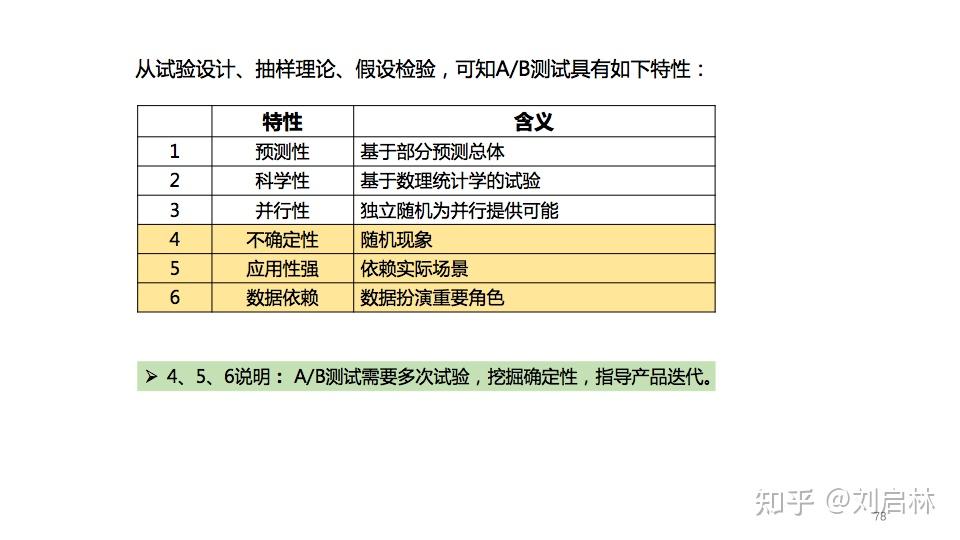
小结一下,从试验设计、抽样理论、假设检验,可知A/B测试具有如下:预测性、科学性、并行性、不确定性、应用性强、数据依赖等特点。
3. A/B测试应用
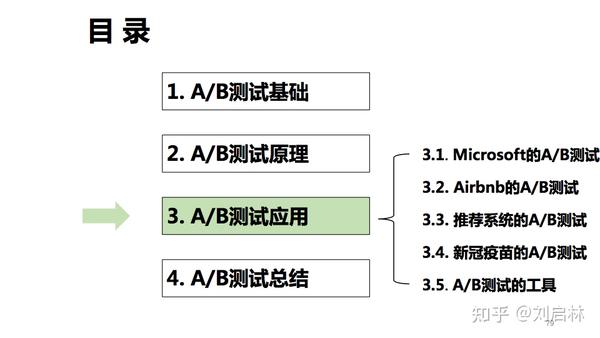
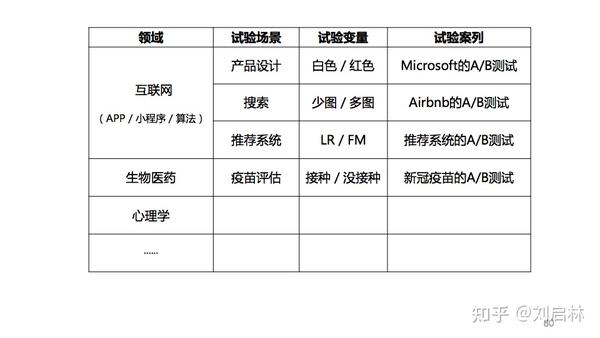
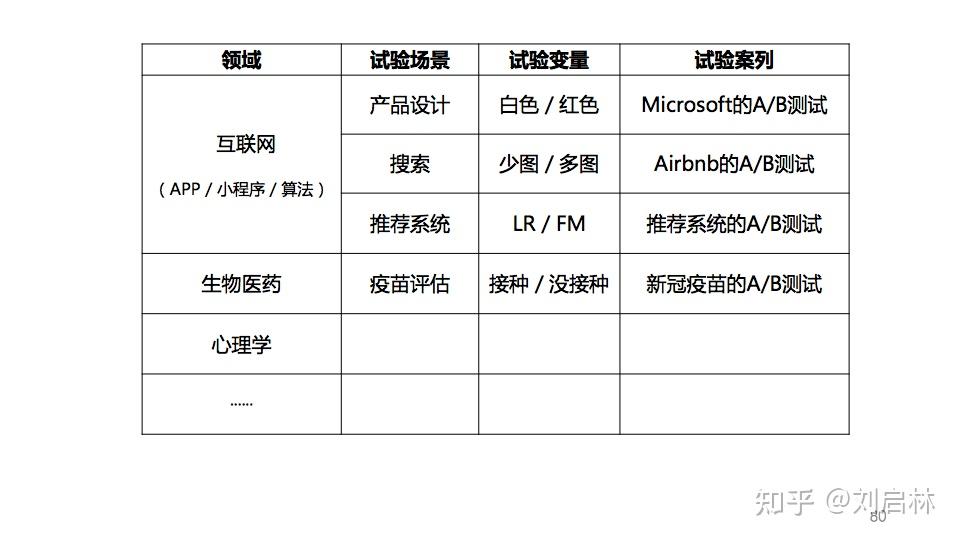
A/B测试广泛应用于互联网产品、设计、搜索、推荐、广告、增长、数据分析、运营、营销等领域。这里举几个典型的A/B测试实践应用的案列,比如:产品设计领域的Microsoft的A/B测试;搜索领域的Airbnb的A/B测试;推荐领域的推荐系统的A/B测试;生物医药领域的新冠疫苗的A/B测试等等。
3.1. Microsoft的A/B测试
假设:改变配色方案会增加点击率。


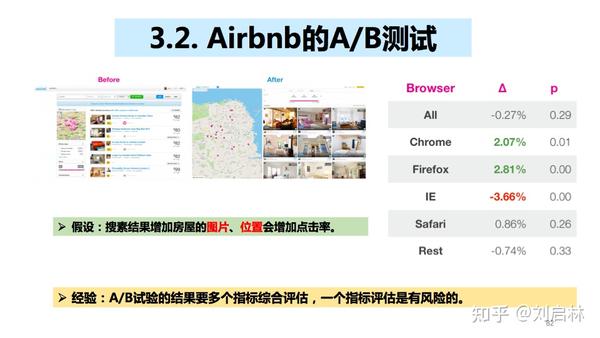
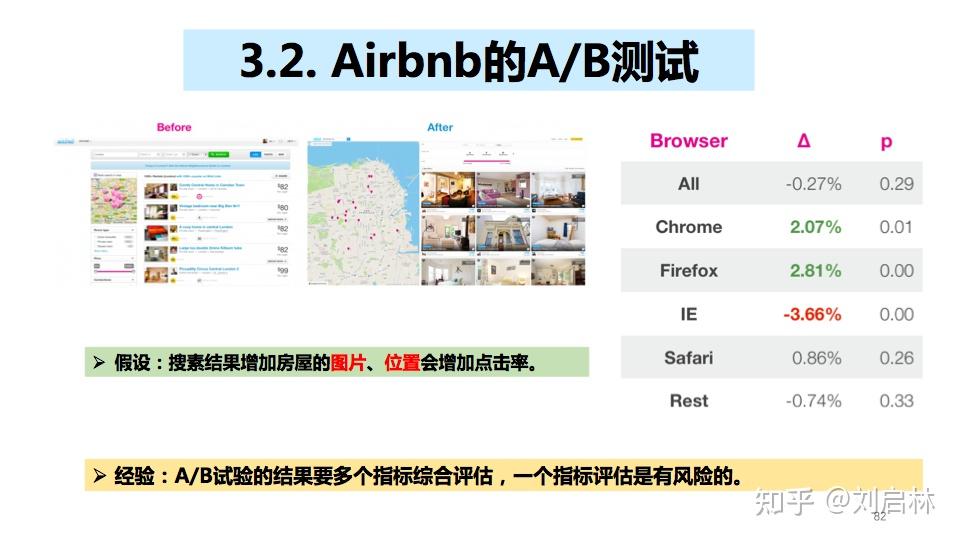
3.2. Airbnb的A/B测试
假设:搜素结果增加房屋的图片、位置会增加点击率。
3.3. 推荐系统的A/B测试
假设某APP的日活DAU是20万,最近上线一个新推荐模型FM(旧LR),现在进行A/B测试。
原假设 :LR 与 FM 推荐结果没有差异;
备择假设 :LR 与 FM 推荐结果有差异。
选择点击率 CTR 指标 来进行量化评估。
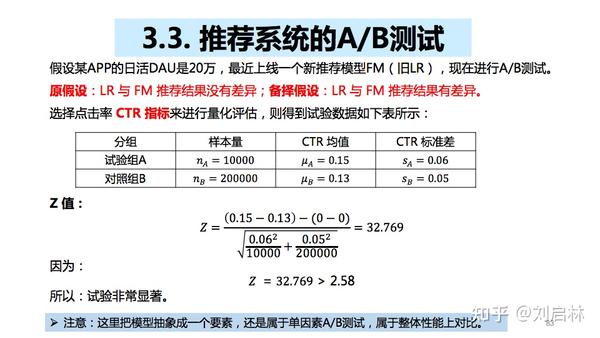
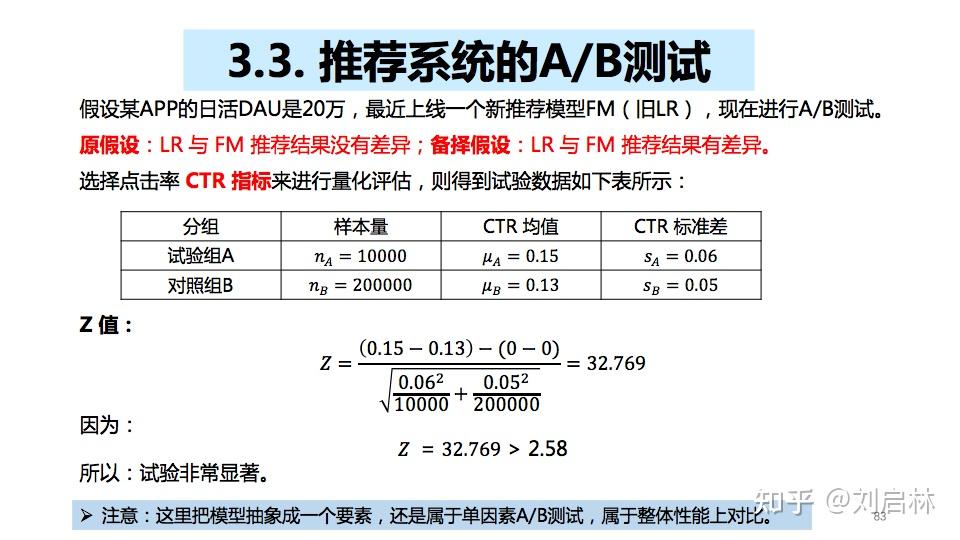
置信区间、p 值、效应量计算如下:


MDE的计算:
因为效应量 d > MDE,所以拒绝原假设, LR 与 FM 推荐结果有差异,而且非常显著。


即说明新的推荐模型FM效果提升明显。
更多FM内容可参考:
推荐系统的A/B测试的Python实现如下:


3.4. 新冠疫苗的A/B测试(双盲试验)
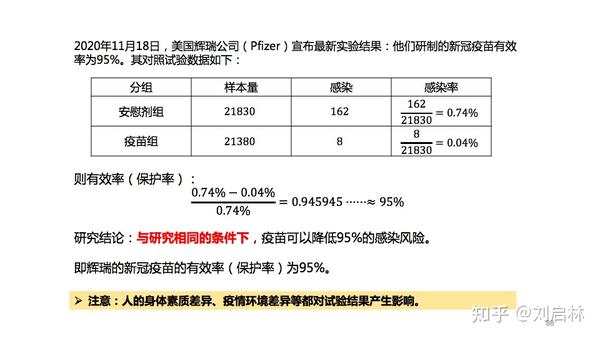
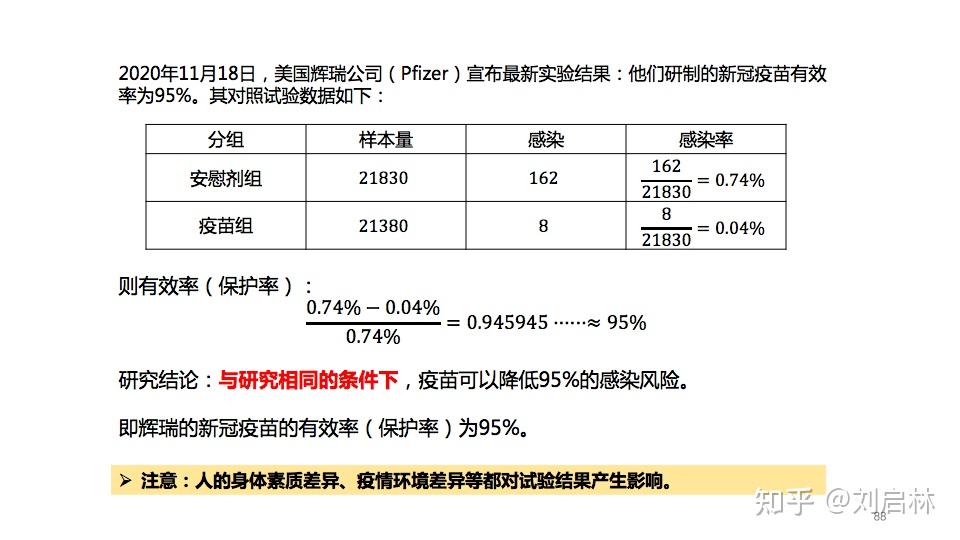
新冠疫苗需要进行三期试验,观察疫苗是否能够防止人感染,主要评估指标是保护率,也称有效率。那么,怎么计算疫苗的保护率(有效率)?


举个例子:2020年11月18日,美国辉瑞公司(Pfizer)宣布最新实验结果:他们研制的新冠疫苗有效率为95%。那么,这个95%有效率是怎么计算得到呢?
3.5. A/B测试的主要工具
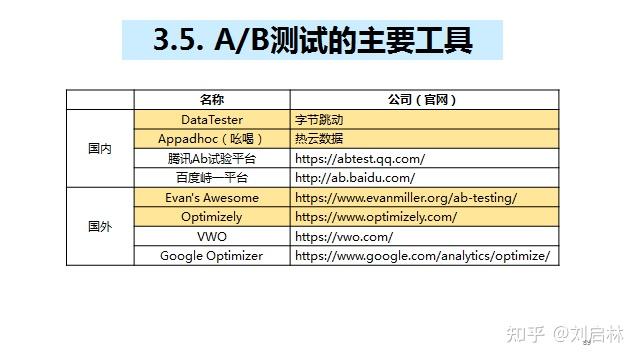
A/B测试工具有很多,比如国内的字节跳动的DataTester、热云的Appadhoc(吆喝)等;国外的 Evan's Awesome 、Optimizely 、VWO 等。国内外主要的A/B测试工具如下表所示:

4. A/B测试总结
4.1. A/B测试的本质的本质
实验是科学研究的主流方法,其背后的指导思想是什么?
是实证主义,还是证伪主义?


对照试验<——试验<——证伪主义
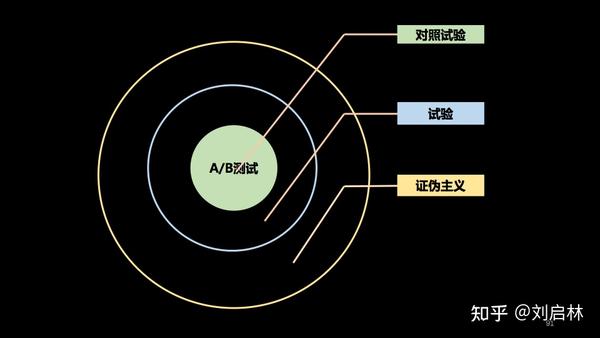
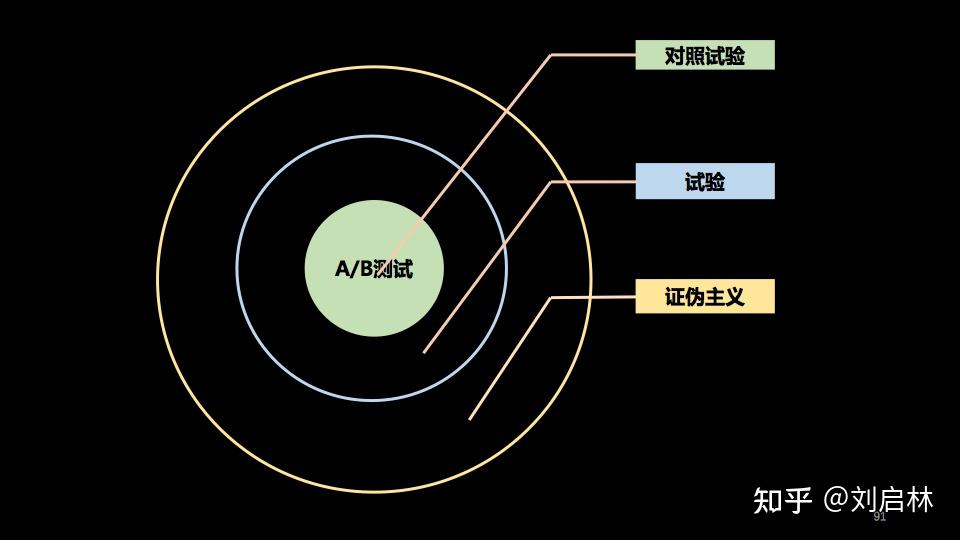
A/B测试的本质是对照试验。
A/B测试的本质的本质是证伪。
在A/B测试中,若试验没有统计显著性(差异),可以快速跳过继续下一个试验。


4.2. A/B测试的价值
A/B测试的价值:数据化驱动决策、降低风险、科学验证想法。


4.3. A/B测试不适用
A/B测试不适用:变量多、产品不成熟、缺乏统计思维。


4.4. A/B测试的经验
特别注意心理学对A/B测试的影响。因为人往往证明自己正确很容易,但证明自己错了很难。


A/B测试可能是消极的、或者不显现的。


A/B测试的参考文献(1)


A/B测试的参考文献(2)


A/B测试的参考文献(3)


总结:
互联网领域,A/B测试(AB实验)是一种实现用户增长、业务增长的重要手段。但是A/B测试(AB实验)的最终的目的是商业价值实现,所以要把A/B测试放在整个商业生态中考虑。
数据时代,频繁、大量的A/B测试(AB实验)有助于数据驱动增长,发现你的增长机会。
结束语:
由于个人的经历、能力和水平是有限的,我的可能是片面的,也可能是错的,这里抛砖引玉。


理论本身是务虚的,需要实践、实践、再实践。
你的反馈,正的负的都是有价值的,有助于我加速迭代升级——更深入、更全面。
你可能会有更好的理论、实践案列,欢迎在评论区留言,咱们一起讨论。

