源代码:
https://github.com/julis-wolala/TextdataHandler
问题描述:
我有一个这样的数据集叫test_result_test.txt,大概几百上千行,两行数据之间隔一个空行。

N:505904X:0.969wsecY:0.694wsec
N:506038X:4.246wsecY:0.884wsec
N:450997X:8.472wsecY:0.615wsec
现在我希望能提取每一行X:和Y:后面的数字,然后保存进Excel做进一步的数据处理和分析
就拿第一行来说,我只需要0.969 和0.694。每一行三个数字的具体位置是不确定的,因此不能用固定的列数去处理,刚好发现split函数能对文本进行切片,所以这里我们用这个函数来提取需要的数字信息。
split函数语法如下:
1、split()函数
语法:str.split(str="",num=string.count(str))[n]
参数说明:
str:表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]:表示选取第n个分片
注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
于是对于我们这里的文本,我们可以先用“:”切片,把文本分成三份,比如对于第一行

以“:”进行切片得到
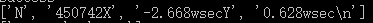
取第三个分片进行“w”切片,得到

这里的第一分片就是我们要的X坐标
最后我们分析一下思路:
- 首先定位文件位置
- 读取txt文件内容,去掉空行保存
- Excel准备工作,新建Excel表格,并编辑好标题为写入数据就位
- 对于每一行数据,首先用‘:’进行切片,再用‘w’切片得到想要的数字,然后写入Excel保存
工具:
安装好python模块的visual studio 2017
包:os,xlwt
操作:
先import我们所需要的包
import os
import xlwt
- 找到我们想要处理的文件,因此去到指定的位置,定位好文件
a = os.getcwd()
print (a)
os.chdir('D:/')
a = os.getcwd()
print(a)
- 打开我们的txt文件查看下里面的内容(这一步可有可无)
with open('test_result1.txt','r') as raw:
for line in raw:
print (line)
- 去除空白行并保存
with open('test_result1.txt','r',encoding = 'utf-8') as fr, open('output.txt','w',encoding= 'utf-8') as fd:
for text in fr.readlines():
if text.split():
fd.write(text)
print('success')
执行完毕同个位置下多了一个txt文件

4. 创建一个Excel文件
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
Workbook类初始化时有encoding和style_compression参数
encoding:设置字符编码,一般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。默认是ascii。
style_compression:表示是否压缩,不常用。
- 创建一个sheet对象
sheet = book.add_sheet('Output', cell_overwrite_ok=True)
- 在表格里添加好基本的数据标题,我这里是X和Y坐标
sheet.write(0, 0, 'X')
sheet.write(0, 1, 'Y')
- 多次切割数据并定位好需要的部分保存进Excel
n=1
with open('output.txt','r+') as fd:
for text in fd.readlines():
x=text.split(':')[2]
y=text.split(':')[3]
print (x.split('w'))
print (y.split('w'))
sheet.write(n,0,x.split('w')[0])
sheet.write(n,1,y.split('w')[0])
n = n+1
book.save('Output.xls')
现在定位到之前定义的文件位置,发现又多了一个Excel表格,打开Excel,想要的数据齐齐整整的排好躺在里面,舒服~

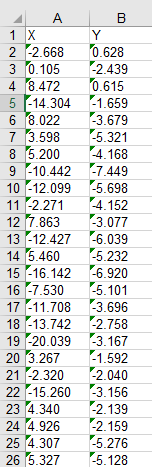
此时数据为文本格式,想要进一步的处理请用Excel转换成数字格式
Reference:
https://blog.csdn.net/sinat_28576553/article/details/81275650
我的问题:我有一个这样的数据集,大概几百上千行,两行数据之间隔一个空行。N:505904X:0.969wsecY:0.694wsecN:506038X:4.246wsecY:0.884wsecN:450997X:8.472wsecY:0.615wsec...现在我希望能提取每一行X:和Y:后面的数字,然后保存下来做进一步的数据处理和分析就拿第一行来说,我只需要-2.668 和...
(1)使用codecs库的open()方法按行读取txt数据。注意txt文件读取时,编码方式设置(例如:encoding='utf-8');
(2)选取txt数据特定列。使用append()方法对特定列数据进行存储;
(3)循环遍历得到的特定列数据,并保存到txt数据文件中;
二、以下案例以保存txt文件的前两列数据为例,使用该方法实现特定列数据保存:
import codecs
f = codecs.open('1.txt', mode.
项目介绍:
在PYTHON的计算机二级考试中有这么一个题,要求我们从一个文本中按照特定的格式提取指定内容。
文件名称为“论语-网络版.txt”,其内容采用如下格式组织:
1.11子曰:“父在,观其(1)志;父没,观其行(2);三年(3)无改于父之道(4),可谓孝矣。”
该版本通过【原文】标记《论语》原文内容,采用【注释...
首先要导入argparse模块
argparse模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后argparse将弄清如何从sys.argv解析出那些参数。argparse模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
import argparse
import os # 这里因为调用了os.getcwd()来获取当前路径
# 使用 argparse 的第一步是创建一个 ArgumentParser 对象:
parse_xls = ar...
平时工作中遇到很多用相同的EXCEL模板格式报上来的数据,但汇总时遇到了问题。因此编写了这个应用程序。安装后即可使用。
原本有个完整的安装包的,但因上传权限不够只能将应用程序安装包上传这里。程序需要DOT net3.5支持,共有几百M,上传不了,请大家自己在网上下载安装,完后再装应用程序。
程序支持:自定义单元格提取,自定义行提取,自定义列提取,解决了按同一类EXCEL模板上传来的报表分析问题,很实用。本来有一运行界面的,但没地方上传只好作罢。

