


深入理解Presto中的Group By查询


在 Presto中的分组聚合查询流程 中介绍了Presto中的HashAgg的大体流程,本文对Presto中的Agg再次进行更进一步的介绍。
Group By操作是分析型数据库中非常重要的一个操作,在分布式计算系统中又有着特殊的实现,这和数据入库后的存储方式有着非常大的关系,首先来看比较流程的shared disk存储架构,这种架构比较典型和流行的就是HDFS,在MapReduce框架下,groupby的数据流转可以用下图表示:
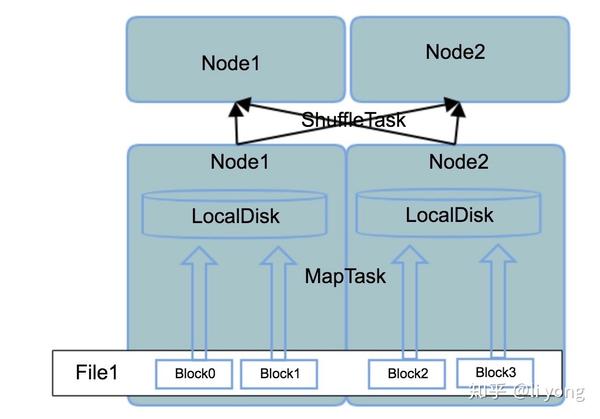
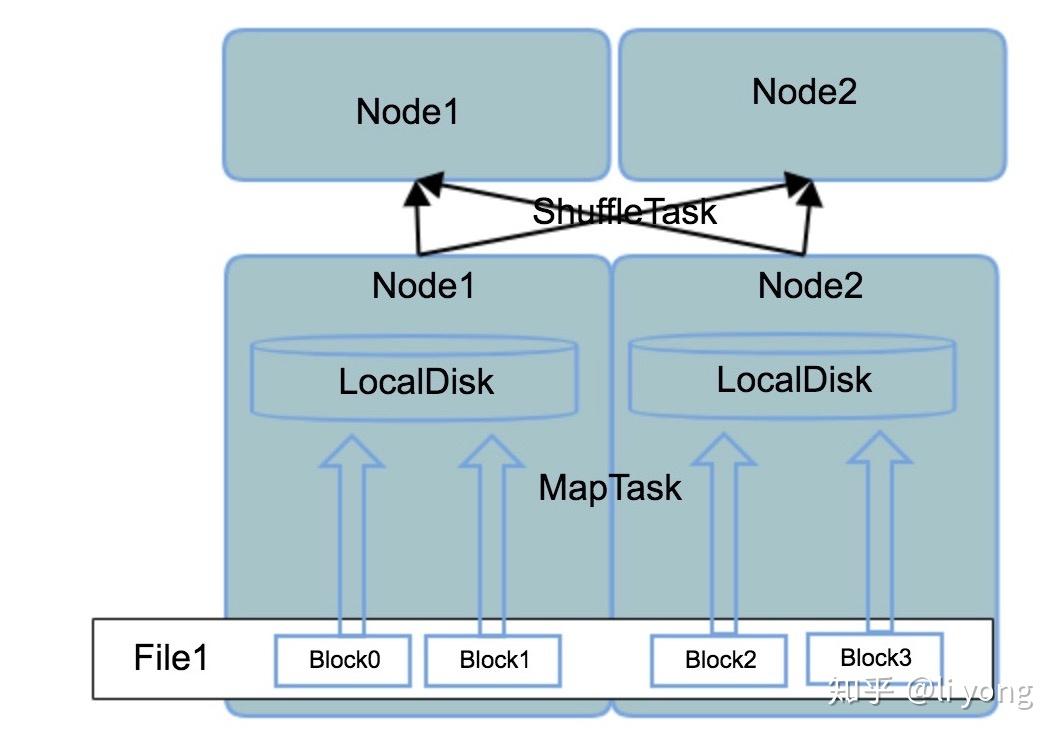
首先组成一个文件的block可能分散在不同的物理节点上,但这对客户端是透明的,客户端看到的就是一个文件名,同时NameNode存储了这个文件名对应的文件的block存储在哪些DataNode上,在MapReduce任务启动后,一个MapTask处理一个文件的一个Block,把这个BLock中的分组字段(groupby字段)和聚合字段(例如需要sum或者avg的字段)“挑捡”出来写入文件,如果这些临时文件还是写在HDFS上,那客户端看到的还是统一的文件视图,在聚合时就非常简单。但是这一步其实会产生非常大和多的临时文件,如果这些临时文件都写在HDFS上,会对NameNode产生很大的压力。所以在MapReduce框架下,MapTask产生的临时文件都写入本地磁盘,那么产生的问题就是相同的分组字段可能分布在不同的机器的本地磁盘里,所以这就需要ShuffleTask根据分区字段对临时文件做一次网络间的shuffle,把相同的分组值聚集在一个节点上,最后才能得到正确的聚合结果。
再来看看shared nothing架构,Presto可以通过扩展connector来读取这种架构下的数据源,比如ES、Mysql等,那么在这种场景下,对于每个分区的数据从数据源读出来之后,MPP的架构下不需要做一次写磁盘的操作,对于不在同一个节点或者同一个分区的相同的分组值,可以通过网络间的数据shuffle聚在在一起:
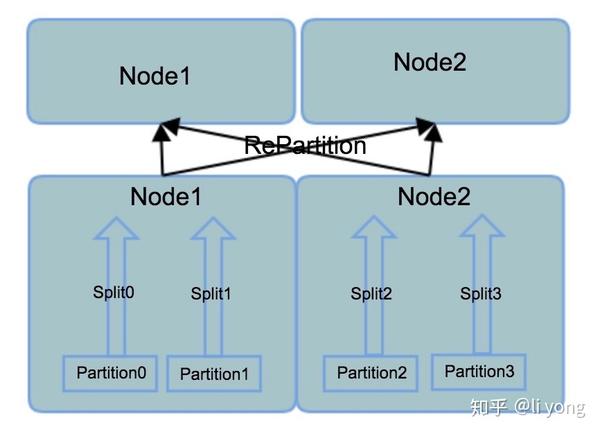

但是,如果数据在入库时根据一定的规则做过分区,而分区字段刚好就是这个分区字段,那么意味着一个分组值所属的数据已经可以确保100%在一个节点的一个分区内了,那么这种情况下其实是不需要中间的网络suffle那个阶段的,巴特,这种情况并不多见,因为对原始数据做分区然后入库的目的是为了把原始的数据均匀的分散在各个节点上,那么这个分区字段的唯一值一般比较多,这样才能保证不会有热点的产生,所以对这个分区字段做group by的查询的情况也比较少见。
但是如果像上图那样:读取数据+shuffle+聚合,那么会带来一个问题就是中间的shuffle那一步可能需要通过网络传输的数据量非常大,所以Presto在实现时,增加了一步Partial聚合,也就是说虽然这一步可能并不能把一个分组的数据全部集中在一起聚合,但是通过Partial聚合,可能极大的减少网络间的数据传输,之所以说是“可能”,而不是一定,是因为在对于某些数据分布来说,可能并不能通过Paritial聚合减少多少数据量,假设在一个Partition的数据如下:
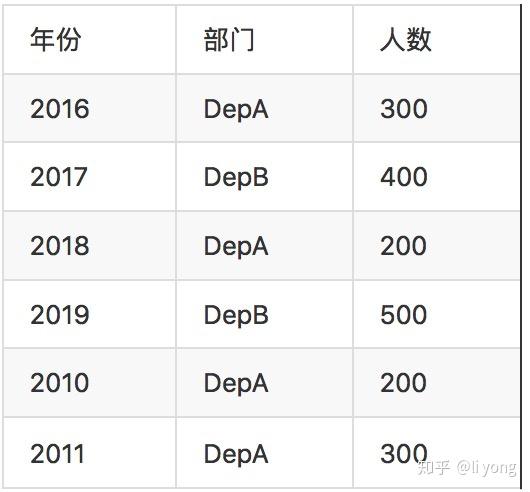

假设根据部门分组,那么可以看到Partial阶段可以完成效果极佳的聚合工作,聚合结果如下:
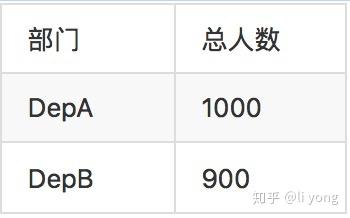
本来需要通过网络传输6行数据,现在做了Partial聚合后只需要传输两条了。但是如果是根据年份做分组聚合,那么Partial聚合想要减少数据量的效果就不理想了:
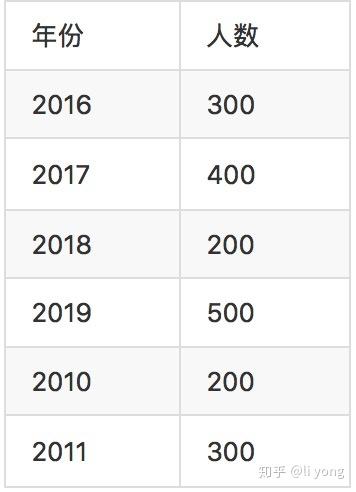
可以看到,聚合之前是6行,聚合后还是6行。在Presto中对聚合算子的类型进行区分的代码如下:
public enum Step{
PARTIAL(true, true),
FINAL(false, false),
INTERMEDIATE(false, true),
SINGLE(true, false);
}可以看到,每个步骤有两个boolean类型标志,分别表示是否处理的是原始数据以及是否需要对处理结果进行序列化:
- PARTIAL
第一个true:输入是原始数据,那么调用的聚合函数的接口就是input接口,这个接口的实现会把原始数据进行聚合,例如:如果是count,那么会对同一个分组进行"+1"操作,如果是sum,那么会进行累加操作
第二个true:需要对聚合结果进行序列化处理,这也意味着聚合结果需要通过网络传输,这一步不会调用聚合函数的接口,而是调用序列化方法对已经聚合的结果进行序列化处理
- FINAL:
第一个false:表示输入并不是原始的数据了,而是通过网络传输过来的“半聚合”数据,那么这一步调用的聚合函数接口是combine,对多个“半聚合”结果进行合并,注意这里的合并不同于partial阶段调用input时的操作,例如对应count,这里并不再进行“+1”操作,而是执行的累加操作,例如(DepA -> 23), (DepA -> 34),那么调用了combine后的结果就是(DepA -> 57)
第二个false:是否需要对聚合结果进行序列化,因为这一步就是最终的聚合结果,所以这里不需要再对聚合结果进行序列化处理,而是要调用聚合函数的final接口,对于count和sum来说,final接口的实现很简单,其实就是上一步执行combine的结果,但是对于avg来说,这里就需要一个额外的操作,那就是用总和除以总数,即:sum/count。
- INTEMEDIATE
这个目前没有用到
- SINGLE
这个类型的操作其实可以理解为前边提到的分区字段做groupby,因为这一步在执行完数据源的扫描后,一个分组的所有数据都已经聚集在一起了,不需要通过网络shuffle后再去对“半聚合”结果进行合并,所以其第一个第二个标志位为fasle,表示不需要调用序列化方法。
那么再来讨论另外一个问题,那就是Partial能否达到预期的减少数据量的效果,答案是不确定,因为数据的分布情况很难在执行前了解到很清楚,这里的数据分布指的就是分组字段的唯一值的个数,前边提到过,Presto的某些数据源会对入库的数据做分区,来起到把热点数据打散的目的,但这种方法有时并不总能达到理想的效果。例如如下的数据分布:


虽然根据USER_ID进行了分区,数据分布很均匀,每个节点上有6行数据,但是如果是用FLAG进行分组查询,那么在Node1上,Partial聚合的结果只有一行,而在Node2上仍然是6条,并没有起到任何的减少数据传输的目的,更为严重的是,Node2上的Partial聚合的整个计算过程白做了(hash计算,hash比较,hash碰撞的处理等),而且在Partial阶段消耗了非常多的内存资源(分区数据没有处理完会一直积攒数据在内存中,因为不确定读出来的数据是否还能和前边读出来的数据进行聚合)。那么Presto中是怎么来处理这个问题的呢?
阅读代码我们发现,在构造HashAggregationOperator时,有一个参数maxPartialMemory,Presto正是使用这个阈值来控制Partial聚合阶段所能聚合的数据量,一旦超过这个阈值,Presto的HashAggregationOperator算子会把当前的“半成品”输出到下一个算子,清空这个算子占用的内存,代码如下:
@Override
public void updateMemory()
long memorySize = getSizeInMemory();
if (partial) {
systemMemoryContext.setBytes(memorySize);
full = (memorySize > maxPartialMemory);
else {
operatorContext.setMemoryReservation(memorySize);
}可以看到,如果内存大小超过了maxPartialMemory,full标志位会被置为true,进而控制getOutput方法把积攒的内存数据进行输出,腾出内存空间。
再来看看计算结果的输出,前边提到不管是在Partial阶段还是在Final阶段,数据都会被积攒在内存中,达到一定的条件再输出,在Presto中,数据的输出都是通过写入PageBuilder来完成的,一个PageBuilder有一定的大小限制,而被积攒在内存中的数据可能已经非常多了,远远大于一个PageBuilder的大小,Presto中的处理方式是构造一个迭代器:
private Iterator<Page> buildResult(IntIterator groupIds)
final PageBuilder pageBuilder = new PageBuilder(buildTypes());
return new AbstractIterator<Page>()
@Override
protected Page computeNext()
if (!groupIds.hasNext()) {
return endOfData();
pageBuilder.reset();
List<Type> types = groupByHash.getTypes();
while (!pageBuilder.isFull() && groupIds.hasNext()) { //如果PageBuilder满了或者已经没有需要聚合的数据,
//则跳出循环
int groupId = groupIds.nextInt();
groupByHash.appendValuesTo(groupId, pageBuilder, 0);//把group by的key值写入PageBuilder
pageBuilder.declarePosition();
for (int i = 0; i < aggregators.size(); i++) {//把聚合结果写入PageBuilder
Aggregator aggregator = aggregators.get(i);
BlockBuilder output = pageBuilder.getBlockBuilder(types.size() + i);
aggregator.evaluate(groupId, output);