PUT /_cluster/settings
"persistent": {
"logger.org.elasticsearch.discovery": "DEBUG"
logger.org.elasticsearch.discovery: DEBUG
logger.discovery.name = org.elasticsearch.discovery
logger.discovery.level = debug
3、日志调到最低级别,看能否输出检索DSL?
问题来了?改成最低TRACE级别,日志能输出咱们的日期请求吗?试试看。
那怎么办?如何输出请求日志?此路已然不同,我们只能另寻他路。除了基础日志,我们还有slowlog日志。
4、Elasticsearch slowlog日志必知必会
4.1 Elasticsearc slowlog 用途
见名释义,本质是:慢日志,又可以分为:慢检索日志和慢写入日志。
slowlog 用于显示:query 阶段 和 fetch 阶段的日志。
Elasticsearch 查询请求如下图所示。
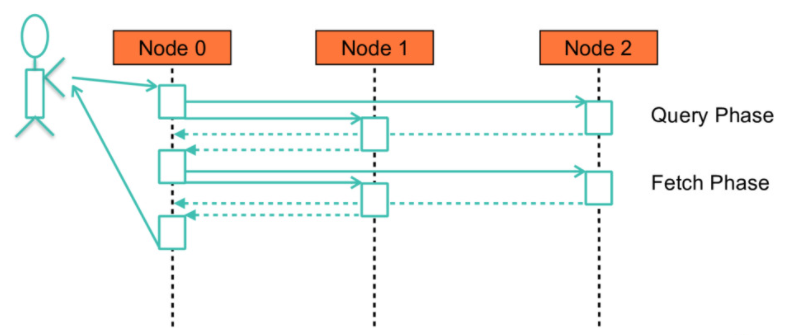 图片来自 Elastic 官方博客
图片来自 Elastic 官方博客
query 阶段的核心步骤:
fetch 阶段的核心步骤:
4.2 Elasticsearc slowlog 设置内容含义
如下所示,拿 query 阶段举例(以实测为准):
query 请求耗时超过 500ms,打印 trace 日志。
query 请求耗时超过 2s,打印 debug 日志。
query 请求耗时超过 5s,打印 info 日志。
query 请求耗时超过 10s,打印 warn 日志。
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
fetch 阶段设置如下,原理同上。
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
index 写入日志设置如下,原理同上。
index.indexing.slowlog.threshold.index.warn: 10s
index.indexing.slowlog.threshold.index.info: 5s
index.indexing.slowlog.threshold.index.debug: 2s
index.indexing.slowlog.threshold.index.trace: 500ms
index.indexing.slowlog.source: 1000
4.3 slowlog 中 source:1000 含义是?
"index.indexing.slowlog.source": "1000"
如下这个问题至少被问到三次,问题大致如下:
slowlog 日志显示不全、被截取了怎么办?
4.3 Elasticsearch slowlog 如何设置?
直接更新 setting 就可以,动态参数,支持动态更新。
PUT /my-index-000001/_settings
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms"
4.3 基于slowlog 打印请求日志
slowlog 既然可以基于阈值打印输出请求日志,阈值势必可以设置很低,最低设置为0,必然能打印出全部日志了。
如下是基于 packets-2022-12-14 进行的 index、fetch、query 的 debug 设置。
PUT packets-2022-12-14/_settings
"index.indexing.slowlog.threshold.index.debug": "0s",
"index.search.slowlog.threshold.fetch.debug": "0s",
"index.search.slowlog.threshold.query.debug": "0s"
设置完成后,在 kibana 控制台随意加个 query 请求。
日志存储在:elasticsearch_index_search_slowlog.json 文件下,如下图所示。
如下图标红所示,任意的请求 DSL 被打印出来。
开篇问题得以求解完成!
Elasticearch 日志协助排查集群故障,慢日志协助排查写入、查询层面的慢写入、慢查询问题。集群规模大,可以独立采集到 Kibana 可视化展示,更为方便和快捷!
你有没有使用 Elasticsearch 日志?欢迎留言讨论。如何使用的?
[1]https://www.elastic.co/guide/en/elasticsearch/reference/current/logging.html
[2]https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-slowlog.html
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单(2022年国庆更新版)
如何系统的学习 Elasticsearch ?
更短时间更快习得更多干货!
和全球 1800+ Elastic 爱好者一起精进!
比同事抢先一步学习进阶干货!
1、实战问题请问一下球主,es怎么配置可以把请求日志都打印出来。就是不管是调用借口,还是kibana查询数据,es能打印dsl的请求日志吗??求指导。怎么配置?——问题来源:https://t.zsxq.com/09vv8rqZj2、Elasticsearch 日志必知必会2.1 Elasticsearch 日志用途集群状态监测和故障诊断。2.2 Elasticsearch 日志缺省路径$ES_H...
本文主要介绍了如何使用ElasticSearch、Logstash、Kibana和Logspout技术栈来部署自动化的日志系统。You,too,couldLogstash.快速念五遍这个题目!不过说实话,我其实并不确定该给这篇文章起个什么样的名字才能确保人们可以找到它。这篇文章是基于EvanHazlett’sarticleonrunningtheELKstackinDocker和ClusterHQ’sarticleondoingitwithFig/DockerComposeandFlocker这两篇文章的。本文同时也受到了Borgpaper的影响,它在讨论使用『标准栈』做事情的时候提出了我们感
1.、修改配置文件。
需要在 logback-logstash.xml 中追加以下代码段:
<logger name="org.springframework.data.elasticsearch.core" level="DEBUG"/>
位置如下:
2、重新启动你的应用程序。
红色框后面的就是DSL
3、验证。
把DSL粘贴到Head中,执行查询操作。需要在URL指定索引,DSL中没有描述索引的。
4、排查问题
由于logstash内存占用较大,灵活性相对没那么好,ELK正在被EFK逐步替代.其中本文所讲的EFK是Elasticsearch+Fluentd+Kfka,实际上K应该是Kibana用于日志的展示,这一块不做演示,本文只讲述数据的采集流程.
docker
docker-compose
apache kafka服务
数据采集流程
数据的产生使用cadvisor采集容器的监控数据并将数据传输到Kafka.
数据的传输链路是这样: Cadvisor->Kafka->Fluentd->elasticsearch
每一个服务都可以横向扩展,添加服务到日志系统中.
Elasticsearch的Spring数据
项目的主要目标是使使用新数据访问技术(例如非关系数据库,map-reduce框架和基于云的数据服务)的使用Spring支持的应用程序更容易构建。
Spring Data Elasticsearch项目提供了与搜索引擎的集成。 Spring Data Elasticsearch的关键功能区域是一个以POJO为中心的模型,该模型用于与Elasticsearch文档进行交互并轻松编写存储库样式的数据访问层。
该项目由社区牵头并维护。
Spring配置支持使用基于Java的@Configuration类或ES客户端实例的XML名称空间。
ElasticsearchRestTemplate帮助程序类,可提高执行常规ES操作的效率。 包括文档和POJO之间的集成对象映射。
与Spring的转换服务集成的功能丰富的对象映射
基于注释的映射元数
之前测试同学启动es,用了root 没起来报错如下,
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:106) ~[elasticsearch-5.4.1.jar:5.4.1]
at org.elasticsearch.bootstrap.Boo
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。开源实时日志分析ELK平台能够完美的解决日志收集和日志检索、分析的问题,ELK就是指ElasticSearch、Logstash和Kiabana三个开源工具。
因为ELK是可以跨平台部署,因此非常适用于多平台部署的应用。
二 环境准备
1. 安装JDK1.8环境
2. 下载ELK软件包
logstash: https://artifacts.elastic.co/downloads/logstash/logstash-5.5.0.zip
elasticsearch:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.0.zip
kibana: https://artifacts.elastic.co/downloads/kibana/kibana-5.5.0-windows-x86.zip
分别解压下载的软件,elasticsearch,logstash,kibana 可以放在一个统一文件夹下
1.配置logstash
在logstash文件夹的下bin目录创建配置文件logstash.conf ,内容如下:
#定义数据的格式,正则解析日志(根据实际需要对日志日志过滤、收集)
grok {
match => { "message" => "%{IPV4:clientIP}|%{GREEDYDATA:request}|%{NUMBER:duration}"}
#根据需要对数据的类型转换
mutate { convert => { "duration" => "integer" }}
# 定义输出
output {
elasticsearch {
hosts => ["localhost:9200"] #Elasticsearch 默认端口
在bin目录下创建run.bat,写入一下脚本:
logstash.bat -f logstash.conf
执行run.bat启动logstash。
2. 配置Elasticsearch
elasticsearch.bat即可启动。
启动后浏览器访问 127.0.0.1:9200 ,出现以下的json表示成功。
3.配置kibana
Kibana启动时从文件kibana.yml读取属性。默认设置配置Kibana运行localhost:5601。要更改主机或端口号,或者连接到在其他机器上运行的Elasticsearch,需要更新kibana.yml文件。
kibana.bat启动Kibana。
1. 日志分析和监控:Elasticsearch可以收集、存储和分析大量服务器日志数据,帮助您监控系统性能和查找故障。
2. 搜索引擎:Elasticsearch可以构建高性能的搜索引擎,用于查询大量文档、网页和其他数据。
3. 商业智能和数据分析:Elasticsearch可以用于处理和分析大量实时数据,以帮助企业做出更明智的决策。
4. 安全性分析:Elasticsearch可以用于收集、存储和分析安全日志数据,帮助您检测安全事件和预防攻击。
5. 互联网中间件:Elasticsearch可以作为互联网应用程序的中间件,用于处理大量动态数据请求。
这仅仅是Elasticsearch常见用途的一个概括,它还可以用于其他多种场景,例如数据仓库、推荐系统等。
干货 | 拆解一个 Elasticsearch Nested 类型复杂查询问题
铭毅天下:
干货 | 拆解一个 Elasticsearch Nested 类型复杂查询问题
zisepaopao1135:
Elasticsearch学习,请先看这一篇!
不败顽童博主:


