

可能95%的人还在犯的PyTorch错误

引言
或许是by design,但是这个bug目前还存在于很多很多人的代码中。就连特斯拉AI总监Karpathy也被坑过,并发了一篇推文。
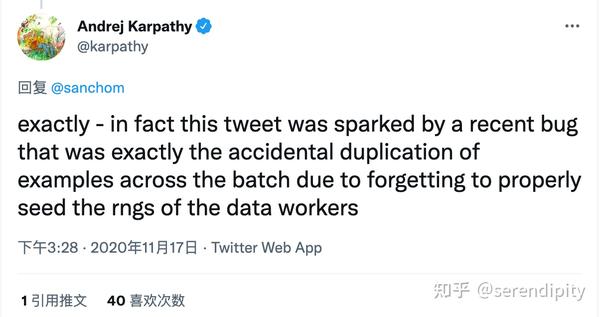
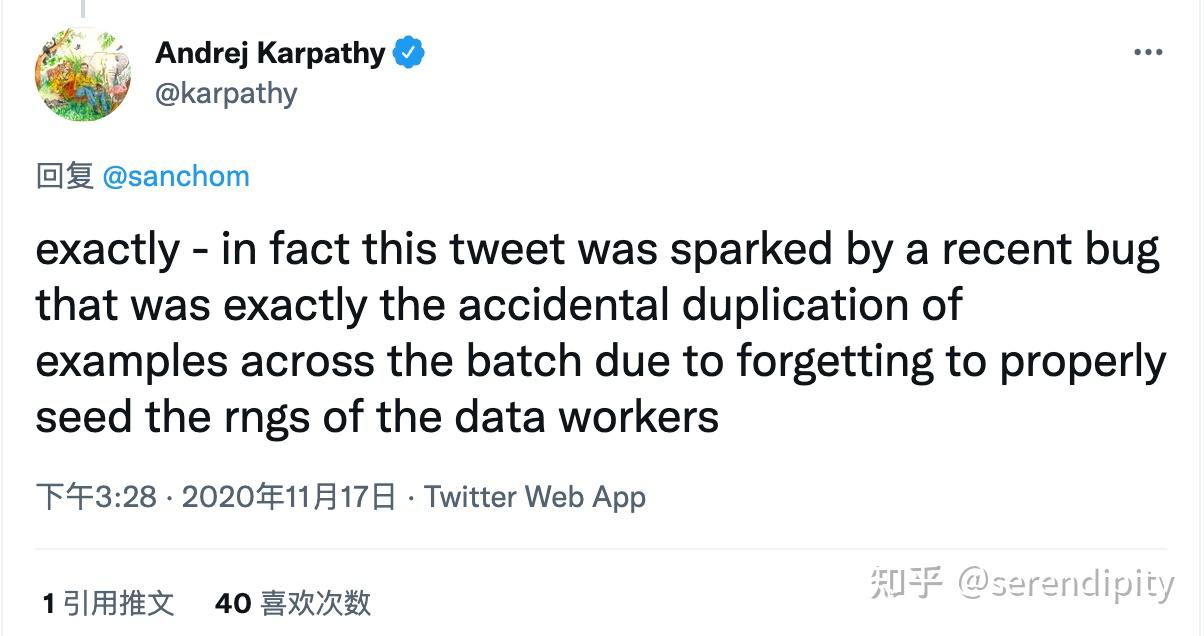
事实上,这条推特是由最近的一个bug引发的,该bug正是由于忘记正确地为DataLoader workers设置随机数种子,而在整个训练过程中意外重复了batch数据。
2018年2月就有人在PyTorch的repo下提了 issue ,但是直到2021年4月才修复。 此问题只在PyTorch 1.9版本以前出现, 涉及范围之广,甚至包括了PyTorch官方 教程 、OpenAI的 代码 、NVIDIA的 代码 。
PyTorch DataLoader的隐藏bug
在PyTorch中加载、预处理和数据增强的标准方法是:继承
torch.utils.data.Dataset
并重载它的
__getitem__
方法。为了应用数据增强,例如随机裁剪和图像翻转,该
__getitem__
方法通常使用NumPy来生成随机数。然后将该数据集传递给
DataLoader
创建batch。数据预处理可能是网络训练的瓶颈,因此有时需要并行加载数据,这可以通过设置
Dataloader
的
num_workers
参数来实现。
我们用一段简单的代码来复现这个bug,PyTorch版本应<1.9,我在实验中使用的是1.6。
import numpy as np
from torch.utils.data import Dataset, DataLoader
class RandomDataset(Dataset):
def __getitem__(self, index):
return np.random.randint(0, 1000, 3)
def __len__(self):
return 8
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=2)
for batch in dataloader:
print(batch)输出为
tensor([[116, 760, 679], # 第1个batch, 由进程0返回
[754, 897, 764]])
tensor([[116, 760, 679], # 第2个batch, 由进程1返回
[754, 897, 764]])
tensor([[866, 919, 441], # 第3个batch, 由进程0返回
[ 20, 727, 680]])
tensor([[866, 919, 441], # 第4个batch, 由进程1返回
[ 20, 727, 680]])我们惊奇地发现每个进程返回的随机数是相同的!!
问题原因
PyTorch用 fork 方法创建多个子进程并行加载数据。这意味着每个子进程都会继承父进程的所有资源,包括Numpy随机数生成器的状态。
注:spawn方法则是从头构建一个子进程,不会继承父进程的随机数状态。torch.multiprocessing在Unix系统中默认使用fork,在MacOS和Windows上默认是spawn。所以这个问题只在Unix上出现。当然,也可以强制在MacOS和Windows中使用fork方式创建子进程。
解决方法
DataLoader
的构造函数有一个可选参数
worker_init_fn
。在加载数据之前,每个子进程都会先调用此函数。我们可以在
worker_init_fn
中设置NumPy的种子,例如:
def worker_init_fn(worker_id):
# np.random.get_state(): 得到当前的Numpy随机数状态,即主进程的随机状态
# worker_id是子进程的id,如果num_workers=2,两个子进程的id分别是0和1
# 和worker_id相加可以保证每个子进程的随机数种子都不相同
np.random.seed(np.random.get_state()[1][0] + worker_id)
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=2, worker_init_fn=worker_init_fn)
for batch in dataloader:
print(batch)正如我们期望的那样,每个batch的值都是不同的。
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[180, 413, 50],
[894, 318, 729]])
tensor([[530, 594, 116],
[636, 468, 264]])等一下,假如我们再多迭代几个epoch呢?
for epoch in range(3):
print(f"epoch: {epoch}")
for batch in dataloader:
print(batch)
print("-"*25)我们发现,虽然在一个epoch内恢复正常了,但是不同epoch之间又出现了重复。
epoch: 0
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 1
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 2
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------因为在默认情况下,每个子进程在epoch结束时被杀死,所有的进程资源都将丢失。在开始新的epoch时,主进程中的随机状态没有改变,用于再次初始化各个子进程,所以子进程的随机数种子和上个epoch完全相同。
因此
我们需要设置一个会随着epoch数目改变而改变的随机数
,例如:
np.random.get_state()[1][0] + epoch + worker_id
。
上述随机数在实际应用中很难实现,因为在
worker_init_fn
中无法得知当前是第几个epoch。但是
torch.initial_seed()
可以满足我们的需求。
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
np.random.seed(worker_seed)实际上,这就是PyTorch官方推荐的 做法 。
没有准备深入研究的读者到这里已经可以了,以后创建DataLoader时,把
worker_init_fn
设置为上面的
seed_worker
函数即可。想了解背后原理的,请看下一节,会涉及到DataLoader的源码理解。
为什么torch.initial_seed()可以?
我们首先要了解多进程DataLoader的处理流程。
-
在主进程中实例化
DataLoader(dataset, num_workers=2)。 -
创建两个
multiprocessing.Queue
用来告诉两个子进程各自应该负责取哪几个数据。假设
Queue1 = [0, 2], Queue2 = [1, 3]就代表第一个子进程应该负责取第0,2个数据,第二个进程负责第1,3个数据。当用户要取第index个数据时,主进程先查询哪个子进程是空闲的,如果第二个子进程空闲,则把index放入到Queue2中。 再创建一个result_queue 用来保存子进程读取的数据,格式为(index, dataset[index])。 -
每个epoch开始时,主要干两件事情。a):
随机生成一个种子
base_seedb): 用fork方法 创建2个子进程 。在每个子进程中, 将torch和random的随机数种子设置为base_seed + worker_id。 然后不断地查询各自的队列中有没有数据,如果有,就取出里面的index,从dataset中获取第index个数据dataset[index],将结果保存到result_queue中。
在子进程中运行
torch.initial_seed()
,返回的就是
torch
当前的随机数种子,即
base_seed + worker_id
。因为每个epoch开始时,主进程都会重新生成一个
base_seed
,
所以
base_seed
是随epoch变化而变化的随机数
。 此外,
torch.initial_seed()
返回的是
long int
类型,而Numpy只接受
uint
类型(
[0, 2**32 - 1]
),所以需要对
2**32
取模。
如果我们用
torch
或者
random
生成随机数,而不是
numpy
,就不用担心会遇到这个问题,因为PyTorch已经把
torch
和
random
的随机数设置为了
base_seed + worker_id
。
综上所述,这个bug的出现需要满足以下两个条件:
- PyTorch版本 < 1.9
-
在Dataset的
__getitem__方法中使用了Numpy的随机数
附录
一些候选方案。
def seed_worker(worker_id):
worker_info = torch.utils.data.get_worker_info()
# worker_info.seed == torch.initial_seed()
np.random.seed(worker_info.seed % 2**32)- @ 晚星
def seed_worker(worker_id):
seed = np.random.default_rng().integers(low=0, high=2**32, size=1)
np.random.seed(seed)- @ ggggnui
class WorkerInit:
def __init__(self, global_step):
self.global_step = global_step
def worker_init_fn(self, worker_id):
np.random.seed(self.global_step + worker_id)
def update_global_step(self, global_step):
self.global_step = global_step
worker_init = WorkerInit(0)
dataloader = DataLoader(dataset, batch_size=2, num_workers=2,
worker_init_fn=worker_init.worker_init_fn)