


垃圾回收的算法与实现--读书笔记(更新ing)

《垃圾回收的算法与实现》--中村成洋
算法篇
1. 学习GC之前
说明GC中的基本概念
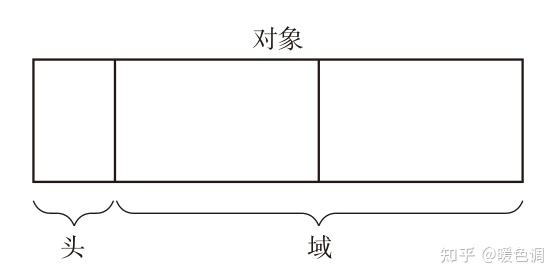
1.1 对象 / 头 / 域
在 GC 的世界中,对象表示的是“ 通过应用程序利用的数据的集合 ”,对象是 GC 的基本单位,对象由头(header)和域(field)构成
1.1.1 头
对象中保存对象本身信息的部分称为“头”
- 对象的大小
- 对象的种类
此外,头中事先存有运行 GC 所需的信息
1.1.2 域
对象使用者在对象中可访问的部分称为“域”,对象使用者会 引用 或 替换 对象的域值,对象使用者基本上无法直接更改头的信息,域中的数据类型
- 指针
- 非指针
指针是指向内存空间中某块区域的值,非指针指的是在编程中直接使用值本身,在对象内部,头之后存在 1 个及 1 个以上的域

1.2 指针
GC 是根据对象的指针指向去搜寻其他对象的。另一方面,GC 对非指针不进行任何操作( 在大多数语言处理程序中,指针都默认指向对象的首地址 )
1.3 mutator
mutator 是 Edsger Dijkstra琢磨出来的词,有“改变某物”的意思。它的实体就是”应用程序“。mutator实际进行的操作包括
- 生成对象
- 更新指针
伴随这些变化会产生垃圾,负责回收垃圾的机制就是GC
1.4 堆
堆指的是动态(程序运行时)存放对象的内存空间,当mutator申请存放对象时,所需的内存空间就从堆中分配给mutator
1.5 活动对象、非活动对象
分配到内存空间的对象中能被mutator引用的对象称为”活动对象“,反过来分配到堆中的不能被程序引用的对象称为”非活动对象“
1.6 分配
在内存空间中分配对象,mutator需要新空间时,向分配器(allocator)申请一个大小合适的空间
1.7 分块
为利用对象实现准备出来的空间,内存中的各个区块都重复着分块-活动对象-垃圾(非活动对象)-分块...的过程
1.8 根
是指向对象的指针的”起点”部分,这些都是能被mutator直接引用的空间。GC把可以直接或间接从全局变量中引用的对象视为活动对象。mutator可以直接引用调用栈(call stack)和寄存器,所以 调用栈、寄存器以及全局变量空间 都是根
1.9 评价标准
1.9.1 吞吐量(throughput)
指的是“单位时间内的处理能力“。在mutator的执行时间中,假设GC执行时间为A+B+C,由于堆大小为HEAPSIZE,所以这个GC算法的吞吐量为 HEAPSIZE/(A+B+C)
1.9.2 最大暂停时间
指的是因执行GC而暂停执行mutator的最长时间
1.9.3 堆使用效率
左右堆使用效率的因素有两个
- 头的大小:堆中堆放的信息越多,GC效率也越高,吞吐量也随之改善。同时头越小越好,因此为了执行GC需要将头中对方的信息控制在最小限度
- 堆的用法:复制算法(每次只利用堆的一半)和标记-清除算法(利用整个堆)
堆的使用效率和吞吐量以及最大暂停时间不可兼得。可用的堆越大,GC运行越快
1.9.4 访问的局部性
具有引用关系的对象通常很可能存在连续访问的情况,把具有引用关系的对象放在堆中较近的位置,就能提高缓存中读取到想利用的数据的概率
2. GC标记-清除算法
2.1 什么是GC标记-清除算法
标记阶段:标记所有的活动对象
清除阶段:清除所有的非活动对象(没有被标记的对象)
// 首先标记根直接引用的对象
mark_phase() {
for (r: $roots) {
mark(*r);
// 递归标记能通过指针数组访问到的对象
mark(obj) {
if (obj.mark == FALSE) {
obj.mark = TRUE;
for (child: children(obj)) {
mark(child);
}如果标记未完成,程序在对象的头部中进行置位操作,这个位要分配到对象的头中,并且能用 obj.mark 访问。标记阶段结束后,所有的活动对象被标记,消耗时间和活动对象的数量成正比( 遍历对象并标记 )
遍历可以使用DFS或BFS。通过比较内存使用可知DFS更节省内存,因此在标记阶段通常使用DFS
sweep_phase(){
sweeping = $heap_start
while(sweeping < $heap_end)
if(sweeping.mark == TRUE)
sweeping.mark = FALSE
sweeping.next = $free_list
$free_list = sweeping
sweeping += sweeping.size
}size域存储对象大小(字节数)。回收对象是把对象作为分块,连接到被称为”空闲链表“的单向链表,在之后需要分配时只需要遍历这个空闲链表就可以找到分块了
在清除阶段,GC需要遍历整个堆,堆越大消耗的时间越多
分配:将回收的垃圾进行再利用。在目前的例子中,从空闲链表中找到大小合适的分块的操作就是分配
new_obj(size){
// 如果得到大小超过所需大小的分块,则将此分块分为所需大小和剩余大小分块,返回所需分块,将其余分块加入空闲链表
chunk = pickup_chunk(size, $free_list)
if(chunk != NULL)
return chunk
allocation_fail()
}分配策略
First-fit:找到大于等于的分块就返回
Best-fit:返回大于等于的最小分块
Worst-fit:总是返回当前最大的剩余分块,会产生很多碎片,不推荐使用
合并:分配会产生大量的小分块,连续连接分块的操作叫做合并,合并是在清除阶段完成
sweep_phase(){
sweeping = $heap_start
while(sweeping < $heap_end)
if(sweeping.mark == TRUE)
sweeping.mark = FALSE
if(sweeping == $free_list + $free_list.size)
// 如果当前块与上一个分块连续,那么将这两个分块合并为一个分块
$free_list.size += sweeping.size
sweeping.next = $free_list
$free_list = sweeping
sweeping += sweeping.size
}2.2 优点
- 实现简单
- 与保守式GC算法兼容,对象不允许移动(见第六章保守式GC算法)
2.3 缺点
- 碎片化:分配会产生大量的小分块,这种状况被称为碎片化(fragmentation)。这种情况下即使有足够大小的分块也可能无法分配,此外,把有引用关系的对象放到堆中较远位置会增加访问时间
- 分配速度:算法中分块不是连续的,因此每次分配都需要遍历空闲链表,找到足够大的分块。最坏情况是每次都遍历到链表尾部
- 与写时复制(copy-on-write)技术不兼容:即使不改变对象,每次遍历堆也会重置对象标志位,频繁发生不应发生的复制
写时复制(copy-on-write):众多UNIX操作系统的虚拟存储中用到的高速化方法。例如Linux中复制进程,即调用fork(),大部分内存空间不会被复制,写时复制技术只是 装作 已经复制了内存空间,实际上是将内存空间共享了。在写入共享内存空间时,要复制自己私有空间的数据,对这个私有空间进行重写,复制后只访问这个私有空间,不访问共享内存(在写入时进行复制)
2.4 多个空闲链表
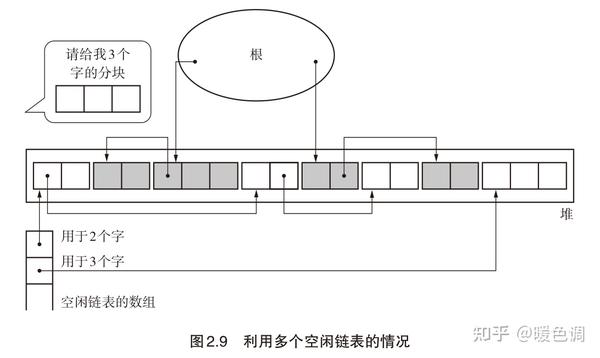

利用一个数组来存储不同字长分块的空闲链表头指针,在mutator申请分块时首先拿到对应分块的头指针,然后直接分配,可以提高分配效率
考虑到mutator频繁申请特大分块的情况比较稀少,所有可以给字长设置上限,即1~100字长各一个空闲链表,100字长以上单独一个空闲链表
new_obj(size) {
index = size * BYTELENGTH / WORDLENGTH
if (index < 100) {
if ($freelist[index] != NULL) {
chunk = $freelist[index]
$freelist[index] = $freelist[index].next
return chunk
} else {
chunk = pickup_chunk(size, $freelist[101])
if (chunk != NULL) {
return chunk
allocation_fail()
sweep_phase() {
for (i : 2..101) {
$freelist[i] = NULL
sweeping = $heap_start
while (sweeping < $heap_end) {
if (sweeping.mark == TRUE) {
sweeping.mark = FALSE
} else {
index = size * BYTELENGTH / WORDLENGTH
if (index <= 100) {
sweeping.next = $freelist[index]
$freelist[index] = sweeping
} else {
sweeping.next = $freelist[101]