


斯坦福 & 微软 | 决策预训练 Transformer,可解决一系列上下文强化学习(RL)问题


首发: AINLPer 微信公众号( 获取分享干货!! )
编辑: ShuYini
校稿: ShuYini
时间: 2023-06-30
引言
在不同的数据集上训练的大型Transformer模型往往具备很强的上下文学习能力。今天分享的这篇文章,作者主要研究了Transformer在问题决策中的上下文学习能力,为此介绍了 「一种决策预训练Transformer(DPT)方法」 ,该方法是一种有监督得预训练方法,即:在不同的任务中,Transformer在给定请求状态和上下文交互数据集的情况下预测出最佳动作。
实验结果发现,尽管没有经过明确的训练, 「预训练的Transformer可用于解决一系列上下文中的RL问题」 ,并表现出在线探索和离线保守的特性;同时该模型还可以 「将预训练的分布推广到新的任务中,并自动适应未知结构的决策策略」 ;最后作者证明了DPT可以被视为贝叶斯后验抽样的有效实现。
背景介绍
近年来,在有监督学习领域,基于大量数据训练的Transformer模型展现出了令人印象深刻的能力,此类模型通常可以结合上下文生成结果,也被称为少样本prompt或者in-context学习。在此能力的加持下,预训练模型可根据少量有监督的输入-输出示例,并被要求在其上下文中预测最有可能的输出,而无需参数更新。在过去的几年中,上下文学习已被应用于解决各种任务,并且越来越多的工作开始理解和分析有监督学习中的上下文学习。
在本文,作者主要研究和理解上下文学习在连续决策任务上的应用,特别是在强化学习背景下。决策(例如强化学习)比监督学习更加动态和复杂。理解和应用上下文学习可以在很大程度上提高Agent适应能力和决策能力,这对于机器人控制和推荐系统来说也是非常有用的。
对于上下文决策,上下文不再是输入-输出元组,而是状态-动作-奖励元组,以此来表示与未知环境交互的数据。 「Agent利用这些上下文输入来理解外界的动态变化以及哪些状态能够产生有益的结果」 。在线强化学习中一个好决策的标志是:能够选择探索性的动作来收集信息,同时利用这些信息来选择不断优化的动作,相比之下,对于离线强化学习,基于离线数据集的Agent应该产生相对保守的动作。一个理想的上下文决策应该表现出类似的行为。
为了研究上下文决策,本文提出了一个简单的有监督预训练目标,即通过有监督学习来训练一个Transformer模型,根据请求状态和上下文交互数据使其预测最佳决策动作输出。并将该预训练模型称为决策预训练Transformer(DPT)。DPT可以作为在线或离线RL算法部署到新任务中,将上下文交互数据集传递给DPT,并让其预测不同状态下的最佳动作。例如:在线情况下,对于一个新的任务,由于一开始并没有交互数据,DPT的预测也不准确,但随着交互数据的不断补充,模型的输出会变得越来越可信。最后作者在经验和理论上证明了,DPT决策效果惊人,并且DPT有效地执行了后验抽样。
决策预训练模型
如下图所示,预训练得到的Transformer模型,利用给定的交互数据来预测出最优的操作,得到的决策预训练Transformer(DPT)在上下文数据集上学习最佳动作的分布。对于一项新的任务,该模型既可以利用在线数据收集进行在线部署应用,也可以利用静态数据集进行离线部署应用。
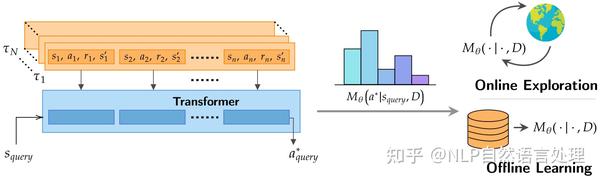

多臂老虎机问题
对于multi-armed bandit问题,作者检验了DPT在线学习和离线学习预测结果的性能。其中,在线学习的目标是从头开始最大化累积奖励,而在离线情况下,由于某些动作可能无法很好预测出来,因此需要考虑噪声带来的不确定性。
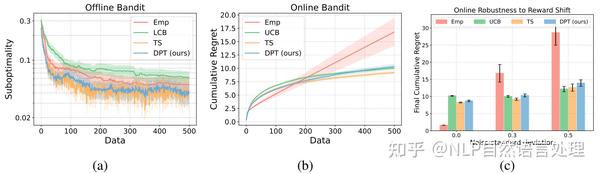

「DPT可以通过不确定性来学习推理」 。验证结果如上图所示。其中,如上图a所示,在离线设置中,当上下文数据集是从与预训练期间相同的分布中采样时,DPT显着超过了Emp和LCB的性能,同时与TS的性能相匹配,这表明了DPT可以在有噪声影响的情况下进行推理;如上图b所示,DPT可以媲美专为探索而设计的经典优化算法UCB和TS的性能;如上图c所示,作者通过改变标准差证明了该属性对于预训练期间未见的奖励中的噪声具有鲁棒性。
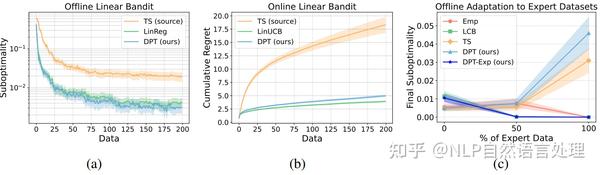

「DPT可以学习利用问题类的固有结构」 。验证结果如上图所示,具体地,作者使用TS收集的上下文数据集预训练DPT模型。如上图a、b所示,DPT可以利用未知的线性结构。它几乎与LinUCB相当,并且显着优于不使用该结构的数据集源TS。这些结果证明 DPT可以自动利用结构,并且基于监督学习的RL方法可以学习超越预训练数据质量的新颖探索。
「DPT可以适应专家数据集」 。其验证结果如上图c所示,具体地,离线强化学习中的一个常见假设是数据集往往是最优数据(例如专家数据)和次优数据之间的混合。在图 c中,作者绘制了在具有不同百分比的专家数据的新离线数据集上进行评估时两个预训练模型的测试时性能。结果表明,当预训练分布偏向专家次优数据时,DPT-Exp的行为类似于LCB,而DPT仍然类似于TS。
马尔可夫决策过程
接下来,作者通过测试DPT探索和信用分配能力,来研究DPT处理马尔可夫决策过程。实验结果表明,DPT具备新任务泛化能力、基于图像观察的可扩展性以及结合上下文行为的能力。
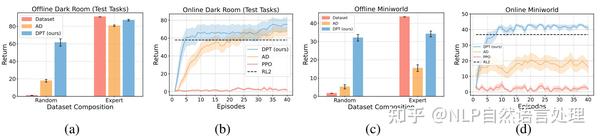

「对离线数据和任务的泛化能力」 。当给定专家数据集时,DPT可以实现接近最佳的性能。 即使给定一个平均总奖励为1.1的随机数据集,DPT也能获得更高的平均回报61.5,如上图a所示;接下来,作者在线评估DPT、AD、RL2和PPO,其中不包含之前20此的测试数据,如上图b所示,DPT的返回值最高;
「基于图像观测的学习能力」 。在Miniworld中,Agent接收25×25像素的RGB图像观测值,如上图d所示,DPT可以从随机数据集和专家数据集中离线解决这个高维任务,与AD、RL2相比,DPT在线学习的效率更高。
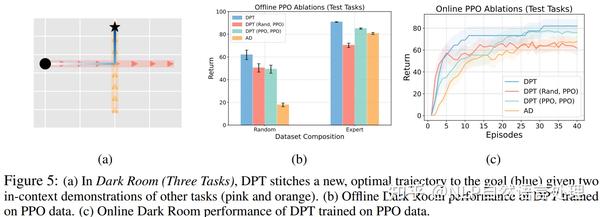
「从上下文子序列拼接能力」 。一些离线强化学习算法的理想特性是能够将离线数据集中的次优子序列拼接成具有更高回报的结果。为了测试DPT是否表现出拼接,作者设计了一个暗室环境,其中存在三个可能的任务。其中预训练数据仅包含其中两个的专家演示。 在测试时,DPT在第三个看不见的任务上进行评估,但其离线数据集只是原始两个任务的专家演示。尽管如此,它还是利用数据来推断解决第三个任务的路径。
前面只是考虑了由最优策略提供的操作标签。然而, 「在某些任务中,即使在预训练中也不容易获得最优策略」 。在本实验中,在80个训练任务中对每个PPO Agent进行训练,最后以生成80个,从中我们对上下文数据集进行采样。
作者使用通过PPO学习的策略和从PPO重放缓冲区采样的上下文数据集进行动作标注。我们对80个训练任务中的每一个训练PPO代理进行1K集的训练,以生成80K个总部署,从中我们对上下文数据集进行采样。这种变体DPT (PPO, PPO)的性能与DPT相当,甚至优于AD,如下图所示:

推荐阅读
[1] 微软 & 麻省理工 | 实验结果表明:代码自修复能力仅存在GPT-4!GPT-3.5不具备该能力
[2] FinGPT:一个「专用于金融领域」的开源大语言模型(LLM)框架,源码公开!
[3] ACL2023 & 复旦 | 模块化Prompt多任务预训练,可快速适应下游任务(含源码)
[4]近乎完美!最强算术语言模型: Goat-7B,干翻GPT-4,怒越PaLM-540B!24G可训练
[5] 超 GPT-4!LONGMEM:提升大语言模型(LLMs)长文本处理能力,最高可达64k
[6]斯坦福发布AlpacaFarm,RLHF人工成本降低45倍!
[7] 透彻!驯服大型语言模型(LLMs)的五种方法,及具体方法选择思路
[8] DTG:一种简单有效的Prompt方法,激发LLMs能力!