


Jupyter入门教程及数据分析初体验

Jupyter Notebook是用于交互开发和展示数据科学项目的功能强大的工具。
Jupyter Notebook将代码及其输出集成到一个文档中,该文档结合了可视化效果,叙述文本,数学方程式和其他富媒体。换句话说:这是一个文档,你可以在其中运行代码,显示输出以及添加说明,公式,图表,并使你的工作更加透明,可理解,可重复和可共享。
教程原文: How to Use Jupyter Notebook in 2020: A Beginner's Tutorial
在 Jupyter Notebook 和 Jupyter Lab 中,如果运行一个函数或一段代码,返回来一些数据,那就说明程序没有改变源数据,只是生成了一些新的数据,如果此时想要改变源数据,就需要进行赋值。
1. 安装
对于初学者来说,最简单的使用Jupyter Notebook的方法是安装 Anaconda 。
Anaconda是用于数据科学的最广泛使用的Python发行版,并且预装有所有最受欢迎的库和工具。
Anaconda中包含的一些最大的Python库,包括: NumPy , pandas 和 Matplotlib , 完整的1000多个列表 此处可见。
因此,Anaconda可以让我们一开始就使用一个库存充足的数据科学库,而不用管理无数的安装包,也不用担心依赖关系和特定于操作系统(即特定于windows)的安装问题。
要获取Anaconda,只需:
(1) 下载 适用于Python 3.8的最新版本的Anaconda。
(2)按照下载页面和/或可执行文件中的说明安装Anaconda。
如果你是已经安装Python的高级用户,并且希望手动管理软件包,则可以 使用pip :
pip3 install jupyter2. 创建第一个notebook
在本节中,我们将学习运行和保存notebook,熟悉其结构并了解界面。我们将紧贴一些核心术语,这些术语将引导你逐步了解如何自己使用Jupyter Notebooks,并为下一小节做好准备,该小节将通过示例数据分析进行学习。
2.1 运行 Jupyter Notebook
在Windows上,可以通过Anaconda添加到你的开始菜单中的快捷方式运行Jupyter,这将在默认的Web浏览器中打开一个新标签页,其外观应类似于下图:
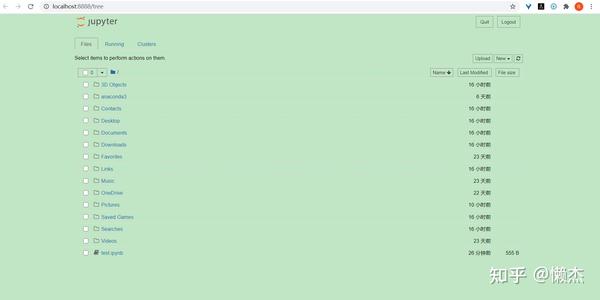
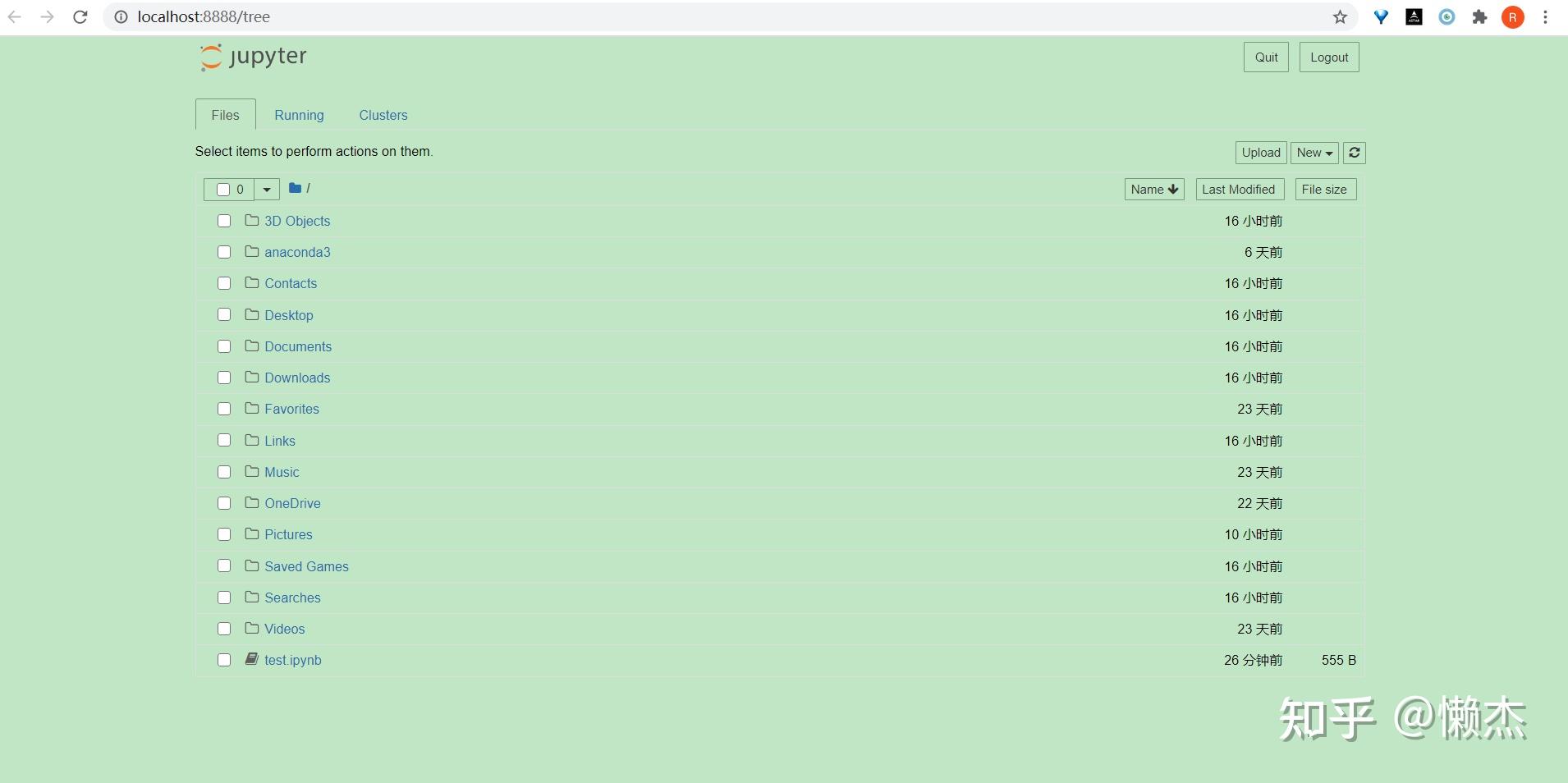
上图为Notebook Dashboard,专门用于管理Jupyter Notebook。 可以将其视为用于探索,编辑和创建notebook的启动板。
Dashboard只允许你访问Jupyter的启动目录中包含的文件和子文件夹(即安装Jupyter或Anaconda的位置)。但是,可以 更改启动目录 :
使用 jupyter notebook 配置文件:
打开cmd(或Anaconda Prompt )并运行jupyter notebook --generate-config。
这会将文件写入C:\Users\username\.jupyter\jupyter_notebook_config.py。
定位到该文件位置并在编辑器中将其打开,
在文件中搜索以下行:#c.NotebookApp.notebook_dir = ''


替换为
c.NotebookApp.notebook_dir = '\\目标路径'
,如:


确保在路径中使用"\\",不必理会报错,保存即可。
删除该行开头的#,以取消注释,允许该行执行。
再次打开jupyter后,即为自定义启动目录。
通过cmd命令行输入命令
jupyter notebook
(注意启动了jupyternotebook后cmd窗口也不能关闭),


或者直接在“开始面板”找到jupyter notebook点击运行。
在浏览器中打开Jupyter Notebook时,Dashboard的URL类似于
https://localhost:8888/tree
。Localhost不是网站,而是表示正在通过本地计算机(提供内容。有时候该URL会被其他程序占用,如果需要更改默认服务器地址,可以在〜/ .jupyter / jupyter_notebook_config.py中指定要让Jupyter运行的端口取消注释/编辑以下行:


Jupyter的Notebooks和Dashboard是Web应用程序,Jupyter启动了本地Python服务器,以将这些应用程序提供给Web浏览器,从而使其基本上独立于平台,并为更轻松地在Web上共享打开了大门。
此时,开始创建一个新的.ipynb文件。单击右上角的“New”下拉按钮,然后选择“ Python 3”:
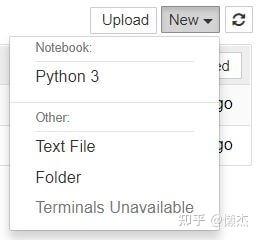
Python 3对应新建一个解释器为python 3的notebook;Text File对应新建一个文本文件;Folder对应新建一个文件夹。
然后,Dashboard可见有
Untitled.ipynb
,且有一些可编辑窗口,表明计算机正在运行。单击上方“Untitled”,可以修改文件名。
每个
.ipynb
文件都是一个文本文件,以
JSON
格式描述notebook的内容 。其中列出了每个单元格及其内容(包括已转换为文本字符串的图像附件)以及一些
元数据
。界面元数据可以在打开 .ipynb 文件后,菜单中选择
Edit->Edit Notebook Metadata
,进行编辑。
2.2 Notebook界面
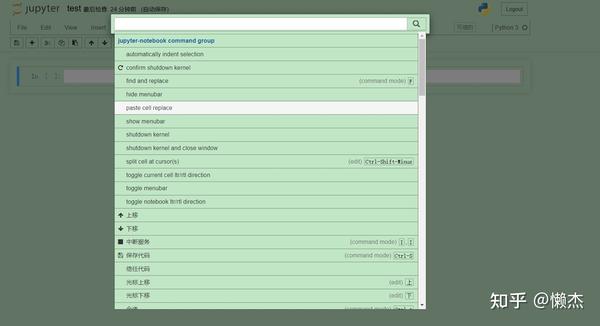
Jupyter本质上只是一个高级文字处理器:


命令列表是带有键盘图标(或
Ctrl + Shift + P
)的小按钮,单击后:

cell 和 kernel 是理解Jupyter以及使它不仅仅是文字处理程序的关键:
- 一个 kernel 是“计算引擎”,用于执行包含notebook文件中的代码块。
- 一个 cell 是一个容器,用于存放要在notebook中显示的文本或由notebook kernel执行的代码。
Cells
一个
Cell
就是下图中绿色框部分,它是 notebook 的主要部分:
通常有两种主要的
cell
:
-
code cell:包括需要执行的代码,以及其运行结果; -
Markdown cell:包含的是 Markdown 格式的文本并且其执行结果。
新notebook中的第一个单元格始终是代码单元格。
用经典的hello world示例进行测试:键入
print('Hello World!')
单元格,然后单击在上方工具栏中“运行”按钮 或按
Ctrl + Enter
。当我们运行该单元格时,其输出将显示在下方,并且其左侧的标签将从
In [ ]
变为
In [1]
。显示
In [*]
时,表示当前代码块正在运行中。
In
是
Input
的缩写。
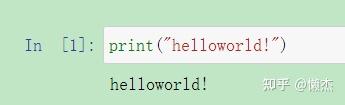
code cell 的输出也构成了文档的一部分,这就是为什么可以在本文中看到它的原因。我们可以分辨出code cell和Markdown cell之间的区别,因为code cell的左侧带有该标签,而Markdown cell则没有。
在菜单栏中,单击“插入(➕)”,然后会在cell下方创建一个新的代码单元。
在运行cell时,它们的边框变为蓝色,而在编辑时为绿色。在Jupyter Notebook中,始终有一个“活动”单元格,其边框突出显示,其颜色表示其当前模式: 绿色表示编辑模式,蓝色表示命令模式 。 Esc 和 Enter 可以切换命令和编辑模式。
键盘快捷键
- 快捷键 H 可以调出来所有的快捷键列表。
- A 可以在上面插入一个code block
- B 可以在下面插入一个code block
- X 就是删除一个block
- M 就是把block转换为markdown
- Shift + Tab 可以查看光标处的函数的参数详情
上述快捷键都是在非编辑下(蓝色模式)用的,就是点block左边序号选中整个block的状态下,或者按 Esc 键。



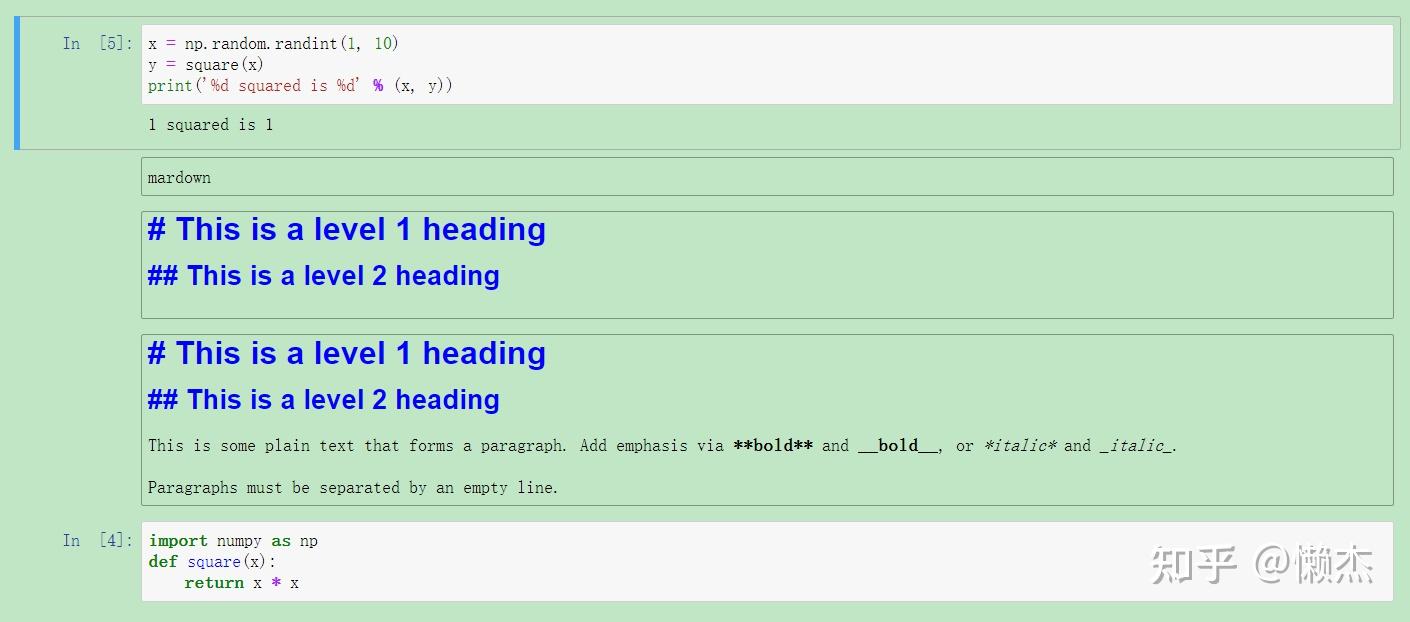
Markdown
Markdown 是一种轻量级,易于学习的标记语言,用于格式化纯文本,它的语法与HTML标签具有一一对应的关系。
输入markdown初始文本:


按下Esc后按M键转换:


如果想 添加图片 ,有三种做法:
- 使用网络上的图片,添加其网络链接 URL,如 https://www.example.com/image.jpg;
- 采用一个本地 URL,那么图片就只能使用在该 notebook 中,比如在同一个 git 仓库中;
-
菜单栏选择 “Edit->Insert Image",这种做法会将图片转换为字符串形式并存储在
.ipynb文件中,这种做法会增加ipynb文件的大小。
更多关于Markdown的操作可以在Markdown网站上参考Markdown的创建者John Gruber的 官方指南 。
每个notebook都有一个kernel。当执行一个cell内的代码的时候,就是采用 kernel 来运行代码,并将结果输出显示在cell内。同时, kernel的状态会随着时间推移以及在单元之间持续存在,并且不止局限在一个单元内,即一个单元内的变量或者导入的第三方库,也可以在另一个单元内使用的,而不是相互独立的。
如果在一个单元格中导入库或声明变量,则它们在另一单元格中也可用:
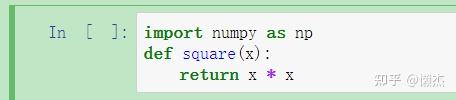
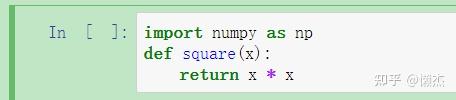
一旦执行上面的单元格,我们可以在
任意
其他cell中使用
np
和
square
(与cell编辑位置无关,与
In [ ]
内编号有关:
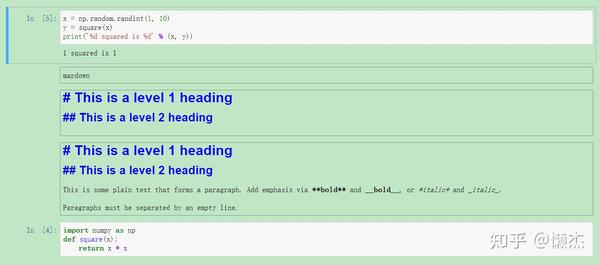
只要某个单元已经运行,声明的任何变量或导入的库都将在其他单元中可用。
改变上述的 y 值,会发生什么?
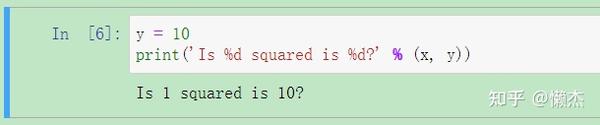
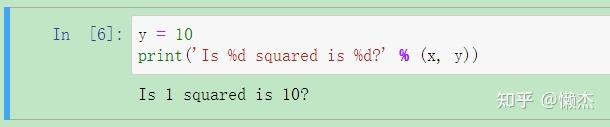
可见,运行了
y = 10
代码单元,
y
就不再等于kernel中x的平方。
大部分情况下都是自顶向下的运行每个单元的代码,但这并不绝对,实际上是可以重新回到任意一个单元,再次执行这段代码,因此每个单元左侧的
In [ ]
就非常有用,其数字就告诉了我们它是运行的第几个单元。
此外,我们还可以重新运行整个 kernel:
-
Restart:重新开始 kernel,这会清空 notebook 中所有的变量定义 -
Restart&Clear Output: 和第一个选项相同,但还会将所有输出都清除 -
Restart&Run All: 重新开始,并且会自动从头开始运行所有的单元内的代码
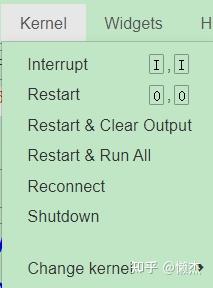
通常如果 kernel 陷入某个单元的代码运行中,希望停止该代码的运行,则可以采用
Interupt
选项。
选择Kernel
在
Kernel
菜单中同样提供了一个更换
kernel
的选项,最开始创建一个
notebook
的时候,就是选择了一个
kernel
,当然这里能否选择其他的
kernel
,取决于环境中是否有安装,比如
Python
的版本。除了
Python
语言,Juypter notebook 支持的
kernel
还包括其他超过一百种语言,比如 Java、C、R、Julia 等等。
2.3 Home Page界面按钮详解


(1)左侧选项卡
- Files 对应下面的文件列表
- Running可以查看命令行窗口和notebook文件运行的管理窗口,类似于任务管理器
- Clusters里面跳转页面可以看有关安装详细信息
- Nbextensions为插件管理页面
(2)右侧选项卡
- Quit 和Logout 退出和注销
- Upload上传文件
- New新建文件
- Python 3对应新建一个解释器为python 3的notebook
- Text File对应新建一个文本文件
- Folder对应新建一个文件夹
- Terminal对应新建一个命令行窗口
(3)文件表列选项卡
小三角可以分类选择文件夹或者文件:
- Folders:勾选所有文件夹
- All Notebooks:勾选所有Notebooks(.ipynb)
- Running:勾选所有在运行的文件
- Files:勾选所有文件
(4)勾选文件时出现的选项卡(运行中的文件和未运行的文件)
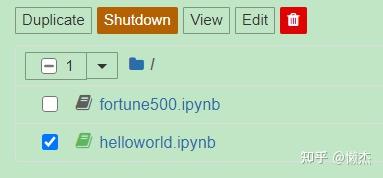
- Duplicate:复制
- Rename:重命名
- Move:移动
- Download:下载
- Shutdown:关闭
- View:视图
- Edit:修改
- 垃圾桶:删除
2.4 Notebook 文件内界面按钮详解
(1)重命名文件
单击窗口上方文件名
(2)菜单栏


File
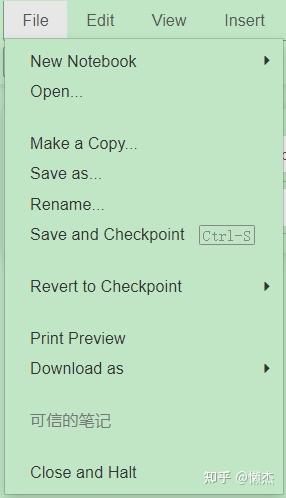
- New Notebook:新建Notebook文件
- Open:打开另外一个文件
- Make a Copy:复制一份
- Save as:另存为
- Rename:重命名
- Save and Checkpoint:保存和检查点,备份
- Revert to Checkpoint:恢复检查点,恢复备份
- Print Preview:打印预览
- Download as:下载为Notebook文件、python文件、html、txt等等多种格式。
- Close and Halt:关闭并停止
Edit
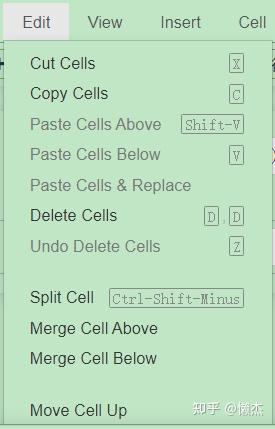
- Cut Cells:剪切单元格
- Copy Cells:复制单元格
- Paste Cells Above:粘贴单元格上方部分
- Paste Cells Below:粘贴单元格下方部分
- Paste Cells Replace:粘贴单元格替换
- Delete Cells:删除单元格
- Undo Delete Cells:撤消删除单元格
- Split Cell:拆分单元格
- Merge Cell Above:合并单元格上方
- Merge Cell Below:合并单元格下方
- Move Cell Up:向上移动单元格
- Move Cell Down:向下移动单元格
- Edit Notebook Metadata:编辑Notebook数据
- Find and Replace:查找和替换
- Cut Cell Attachments:切割单元格附件
- Copy Cell Attachments:复制单元格附件
- Paste Cell Attachments:粘贴单元格附件
- Insert Image:插入图片
View
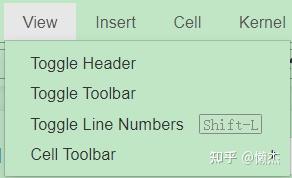
- Toggle Header:显示隐藏标题
- Toggle Toolbar:显示隐藏工具栏
- Toggle Line Numbers:显示隐藏行号
- Cell Toolbar:单元格工具栏
Insert
- Insert Cell Above:在单元格上方插入单元格
- Insert Cell Below:在单元格下方插入单元格
Cell
- Run Cells:运行所有单元格
- Run Cells and Select Below:运行单元格并选择下方
- Run Cells and Insert Below:运行单元格并在下面插入
- Run All:全部运行
- Run All Above:运行单元格上方的全部
- Run All Below:运行单元格下方的全部
- Cell Type:单元格类型
- Current Outputs:当前输出
- All Output:所有输出
Kernel
- Interrupt:中断
- Restart:重启
- Restart & Clear Output:重启并清除输出
- Restart & Run All:重启并全部运行
- Reconnect:重新连接
- Shutdown:关闭
- Change kernel:更换kernel
Widget

- Save Notebook Widget State:保存Notebook小部件状态
- Clear Notebook Widget State:清除Notebook小部件状态
- Download Widget State:下载小部件状态
- Embed Widgets:嵌入小部件
Help
- User Interface Tour:用户界面预览,这个可以带你了解界面。新手去看看。
- Keyboard Shortcuts:键盘快捷键
- Edit Keyboard Shortcuts:编辑键盘快捷键
- Notebook Help:Notebook帮助网址
- Markdown:Markdown网址
- Python Reference:Python参考手册
- IPython Reference:IPython参考手册
- NumPy Reference:NumPy参考手册
- SciPy Reference:SciPy参考手册
- Matplotlib Reference:Matplotlib参考手册
- SymPy Reference:SymPy参考手册
- pandas Reference:pandas参考手册
- About:关于
(3)工具栏


每个图标都有中文注释,光标悬浮在对应图标时会自动显示。
(4)单元格代码区域
每个单元格内的代码既有影响又可以互不影响。多个运行结果可以同时在同一个界面,不像pycharm后面运行结果会关闭前一个再显示。这样可以方便于对比结果和数据。


In[ ]后为输入代码区域;下方为执行结果展示区域。
3. 数据分析实例
假设你是一名数据分析师,而你的任务是找出美国最大公司的利润在历史上是如何变化的。从 《财富》的公共档案库中 ,可以找到自1955年该榜单首次发布以来50年来超过50年的《财富》 500强公司的数据集 。我们已经进行了下一步工作,并创建了可 在此处 使用的数据的CSV文件 。
3.1 命名notebook
在开始编写项目之前,可能需要给它起一个名。单击在屏幕左上方的文件名
Untitled
中输入新的文件名,然后单击其下方的“保存”图标进行保存。
请注意,在浏览器中关闭notebook选项卡 不会 像在传统应用程序中关闭文档 那样 “关闭”notebook。notebook的kernel将继续在后台运行,在管理界面看到 notebook 还是绿色状态就表明其在运行,并且需要在真正关闭之前关闭它-尽管如果不小心关闭了标签页或浏览器,这非常方便!
如果kernel已关闭,则可以关闭选项卡而不必担心它是否仍在运行。
最简单的方法是从notebook菜单中选择“File>Close and Halt”;也可以通过从notebook应用程序中转到“kernel>关闭”或通过在Dashboard中选择notebook并单击“shutdown”来关闭kernel(参见下图),又或者关闭cmd窗口。
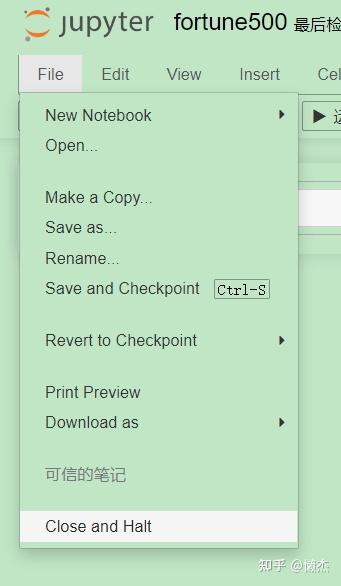
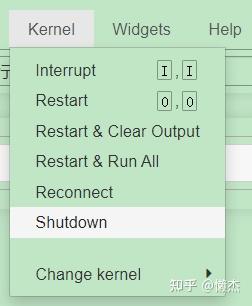
3.2 设置
通常从专门用于导入和设置的代码单元开始。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns sns.set(style="darkgrid")上述代码将导入 pandas 以处理数据,将 Matplotlib 导入以绘制图表,然后将 Seaborn 导入 以使图表更漂亮。导入 NumPy 也很常见, 但在本例情况下,pandas会为我们导入numpy。
此外,
%matplotlib inline
这并不是 python 的命令,它是 Jupyter 中独有的line magic命令,它主要是让 Jupyter 可以捕获 Matplotlib 的图片,并在cell输出中进行渲染。更多关于line magic的细节见:
advanced Jupyter Notebooks tutorial
。
接下来,载入数据(此时csv文件和ipynb文件在同一文件路径):
df = pd.read_csv('fortune500.csv')在单个单元格中也这样做是明智的,以防我们需要在任何时候重新加载它。
此外,加载绝对路径的文件如下:
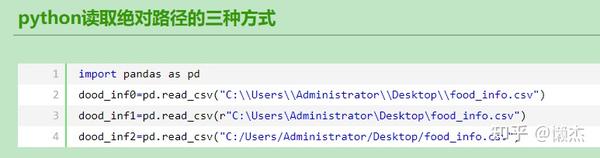
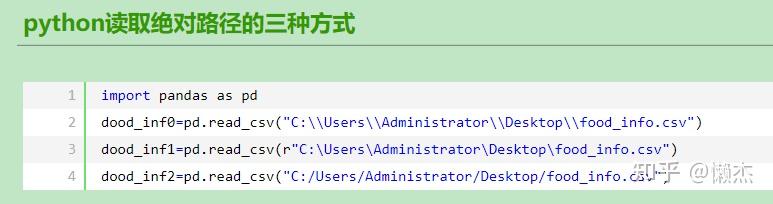
3.3 保存和checkpoint
在开始前,要记得定时保存文件,这可以直接采用快捷键
Ctrl + S
保存文件,它是通过一个命令--“保存和检查点”实现的,那么什么是检查点呢?
每次创建一个新的 notebook,同时也创建了一个
checkpoint
文件,它保存在一个隐藏的子文件夹
.ipynb_checkpoints
中,并且也是一个
.ipynb
文件。


默认 Jupyter 会每隔 120 秒自动保存 notebook 的内容到
checkpoint
文件中,而当你手动保存的时候,也会更新 notebook 和 checkpoint 文件。这个文件可以在因为意外原因关闭 notebook 后恢复你未保存的内容,可以在菜单中
File->Revert to Checkpoint
中恢复。
3.4 解析数据集
经过上述操作,我们已经将数据集 df 加载到最常用的pandas数据结构中,该结构称为DataFrame,基本上看起来像一个表。
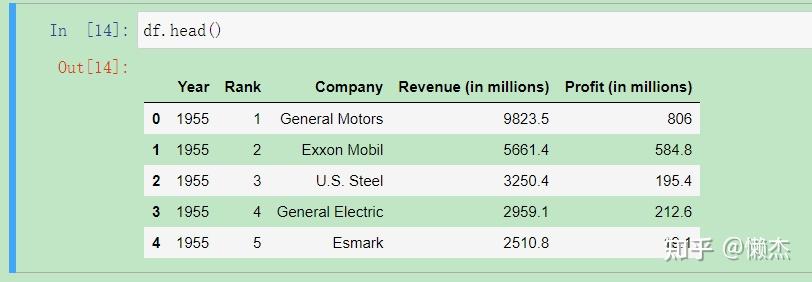
输出数据的前五行:
df.head()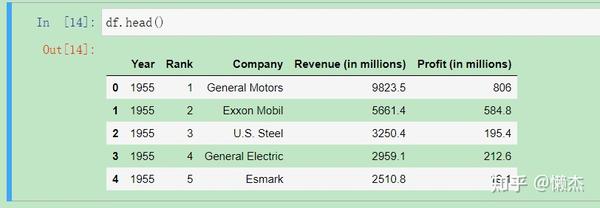
输出数据的后五行:
df.tail()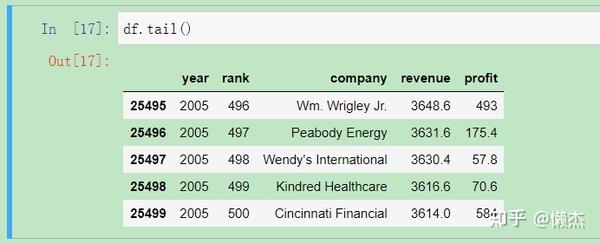
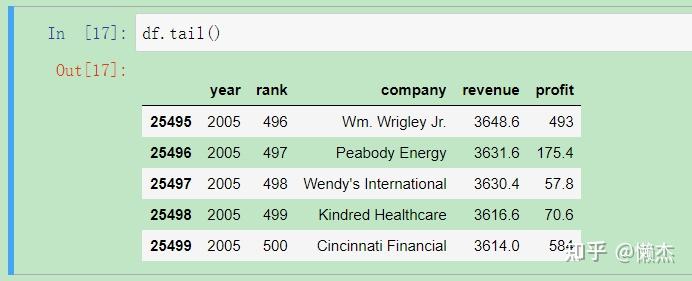
由此得到我们需要的列(分别表示年份、排名、公司名字、收入和利润),每一行对应于一年中的一个公司。
为了方便,可以对列重命名:
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']

还可以查看数据量:
len(df)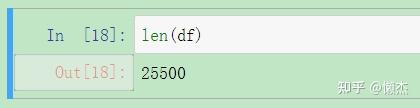
总共有 25500 条数据,恰好是 500 家公司从 1955 到 2005 的数据量。
检查数据集是否如预期的那样被导入。一个简单的检查是查看数据类型(dytypes)是否被正确解释:
df.dtypes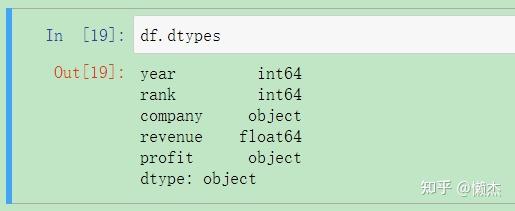
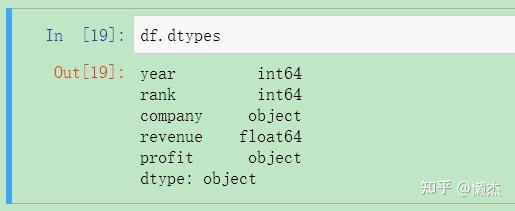
看起来profit有点问题——我们希望它是一个类似revebue的float64。这表明它可能包含一些非整数值,故需要检查:
non_numberic_profits = df.profit.str.contains('[^0-9.-]')
df.loc[non_numberic_profits].head()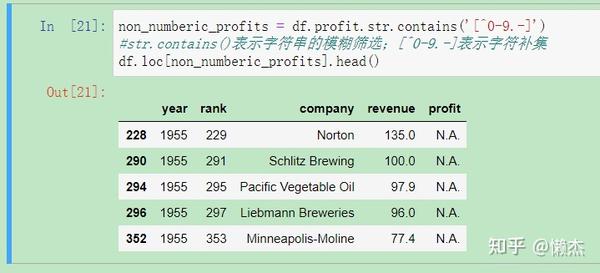
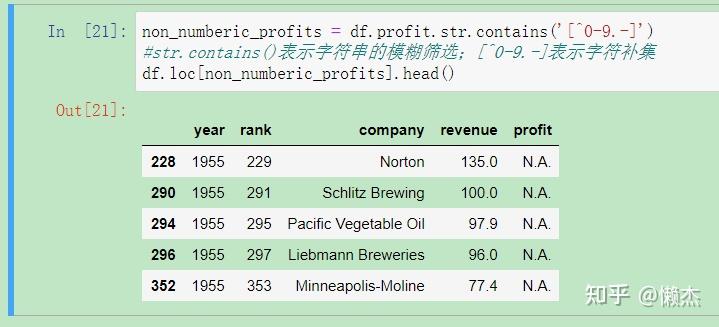
输出结果表明确实存在非整数的数值,而是
N.A
,然后我们需要确定是否包含其他类型的数值:
set(df.profit[non_numberic_profits])

输出结果可见只有
N.A
。
那么该如何处理这种缺失情况呢,这首先取决有多少行数据缺失了
profit
:
len(df.profit[non_numberic_profits])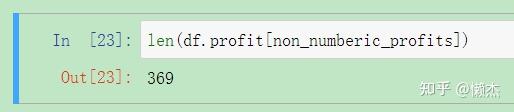
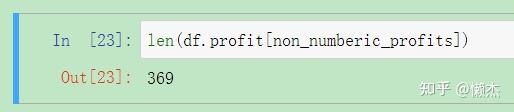
可见,缺少了369项。相比于总共 25500 条数据,仅占据 1.5% 左右。如果缺失的数据随着年份的变化 符合正态分布 ,那么最简单的方法就是直接 删除这部分数据集 ,查看分布情况:
bin_sizes, _, _ = plt.hist(df.year[non_numberic_profits], bins=range(1955, 2006))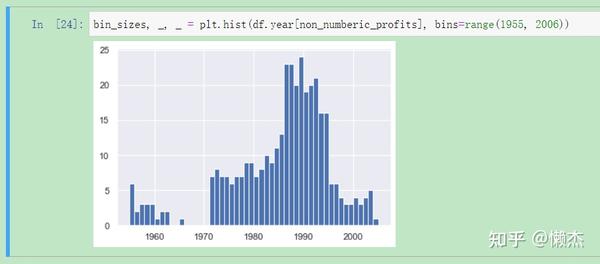
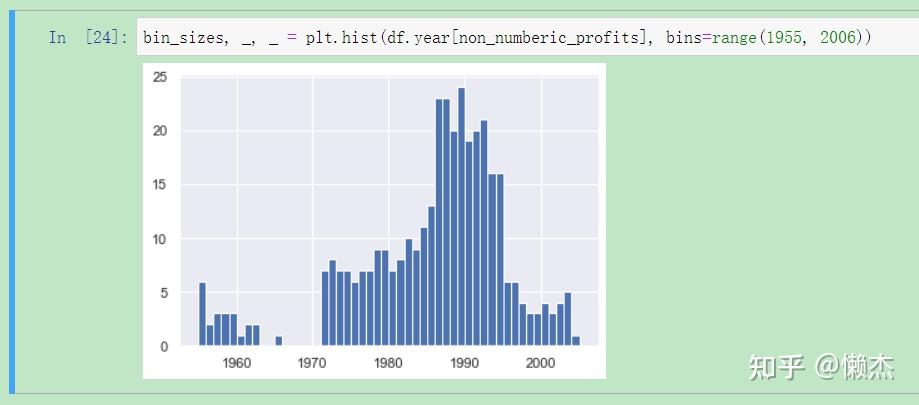
粗略地看,我们可以看到,在单一年份中无效值最多不超过25个,并且由于每年有500个数据点,删除这些值在最糟糕年份的数据中所占的比例不到4%。事实上,除了90年代的激增之外,大多数年份的峰值还不到缺失值的一半。
出于我们的目的,假设这是可以接受的,然后继续删除这些行:
df = df.loc[~non_numberic_profits]
df.profit = df.profit.apply(pd.to_numeric)运行代码后,检查一下是否生效:
len(df)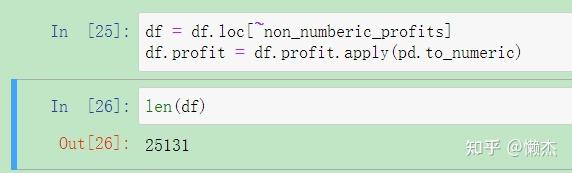
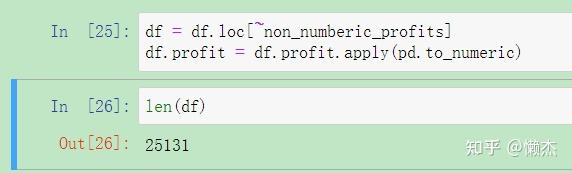
可见,删除了25500-25131=369条profit数据。
检查数据类型是否还存在错误:
df.dtypes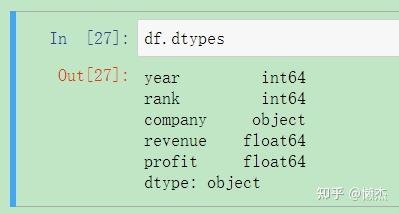
删除数据后,
profit
就是
float64
类型了。
数据的类型等错误项已经排除,接下来可以绘图分析数据。
如果要将你的notebook作为报告呈现,可以去掉创建的数据解析cell(此处包含这些cell是为了演示使用notebook的流程),并合并相关cell(有关详细信息,请参阅下面的高级功能部分)以创建单个数据集解析cell。
这意味着,如果我们在其他地方弄乱了数据集,可以重新运行cell来恢复它。
3.5 使用matplotlib绘图
接下来,我们可以通过绘制每年的平均利润来解决手头的问题。我们也可以绘制收入,因此首先我们可以定义一些变量和方法来减少代码。
group_by_year = df.loc[:, ['year', 'revenue', 'profit']].groupby('year')
avgs = group_by_year.mean()
x = avgs.index
y1 = avgs.profit
def plot(x, y, ax, title, y_label):
ax.set_title(title)
ax.set_ylabel(y_label)
ax.plot(x, y)
ax.margins(x=0, y=0)接着,开始绘图:
fig, ax = plt.subplots()
plot(x, y1, ax, 'Increase in mean Fortune 500 company profits from 1955 to 2005', 'Profit (millions)')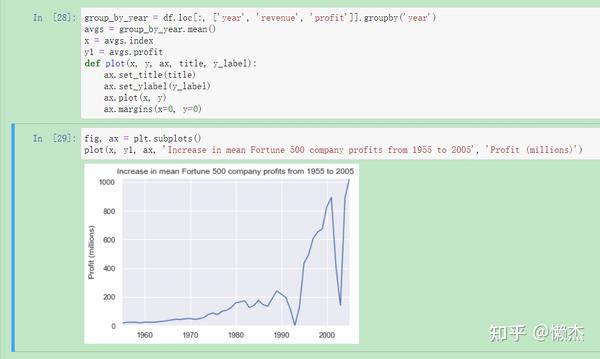
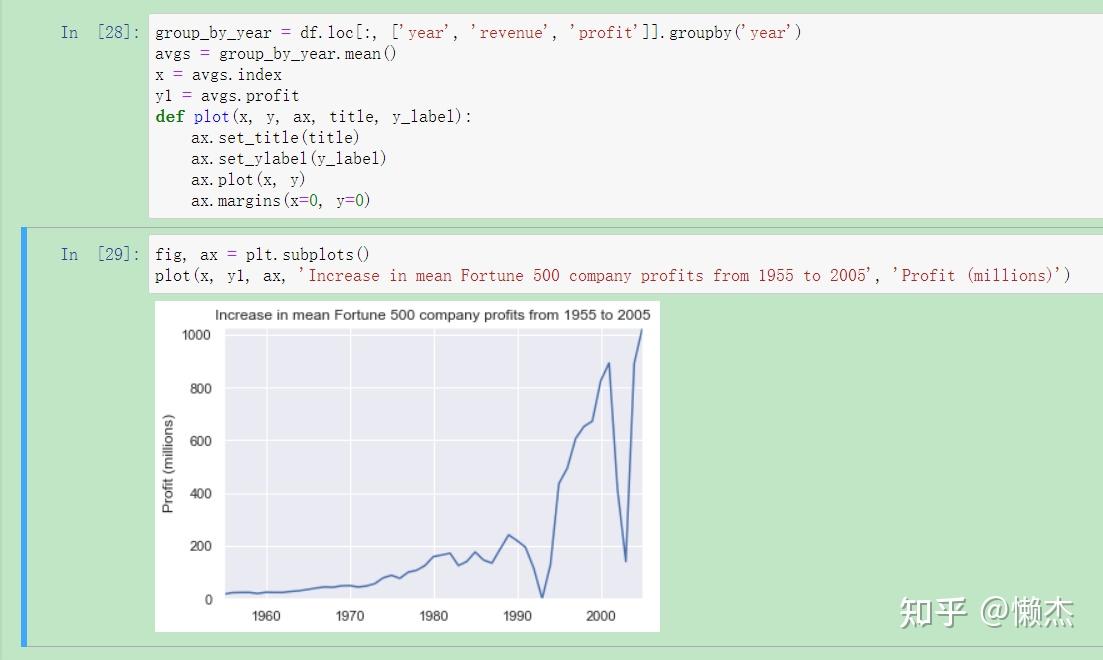
这看起来像指数,但它有一些巨大的下降。它们必须与上世纪90年代初的经济衰退和互联网泡沫相对应。从数据中看到这一点很有意思。但为什么每次经济衰退后profit都会回升到更高的水平呢?
也许revenue能告诉我们更多:
y2 = avgs.revenue
fig, ax = plt.subplots()
plot(x, y2, ax, 'Increase in mean Fortune 500 company revenues from 1955 to 2005', 'Revenue (millions)')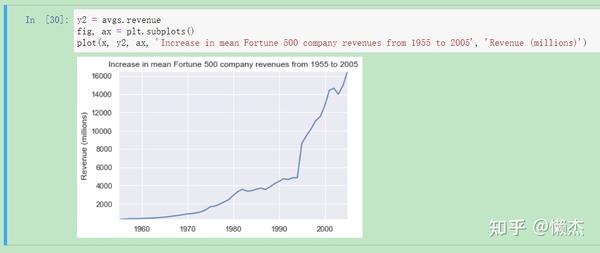
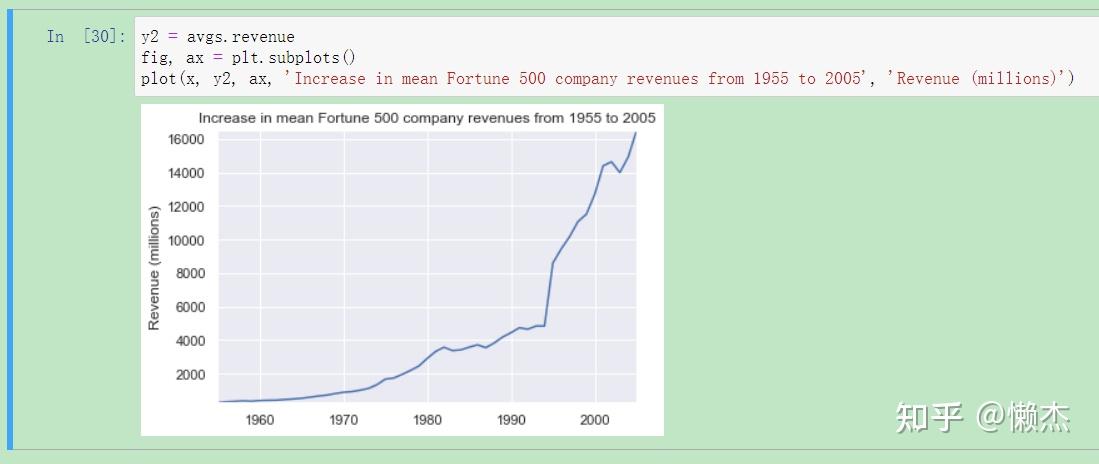
从revenue看,其并没有受到那么严重的打击。
在 Stack Overflow 的帮助下,我们可以通过 +/-它们的标准差把这些图叠加上:
def plot_with_std(x, y, stds, ax, title, y_label):
ax.fill_between(x, y - stds, y + stds, alpha=0.2)
plot(x, y, ax, title, y_label)
fig, (ax1, ax2) = plt.subplots(ncols=2)
title = 'Increase in mean and std Fortune 500 company %s from 1955 to 2005'