

使用 LLM 多轮对话的交互形式进行一次性脚本编程

目标
通过 LLM 产生对 tool 的调用。比如“打开空调”,就去调用空调打开的 api。而不是生成一个 python 脚本让我去执行。一个典型应用场景是 chat with vscode。通过多轮对话的方式调用 vscode 的插件 api,从而读取要阅读的代码和git历史,达到探索式学习的目的。另外一个应用场景是对代码做批量重构,需要读取,转换,写回源代码。
Context 维护是难点
- 单轮对话很难实现复杂的自动化任务
- 由 autogpt 自动拆解任务进行多轮对话,在目前的 LLM 推理能力下,效果没有保证。Context 在多轮对话之间的传递是 autogpt 自动来做的。
- 由 python/javascript 等编程语言串联的多轮对话需要离开 LLM,使用非自然语言描述任务。Context 在多轮对话之间的传递是由 python/javascript 硬编码的。
- 普通的 chatgpt 模式的多轮对话自动把前文做为 context。这导致 context 膨胀过快,无效信息也会让 LLM 判断错关键任务。
可以看到,进行多轮 LLM 对话的时候,怎么实现“前情提要”现有多种方案。但是对于一次性脚本编程,现有的方案都有不足。引起我思考这个问题的一个起因是用 Claude 100K API 去对源代码进行摘要的时候,我需要编写一个 python 脚本把一个目录的文件先读出来,然后再拼成一个 prompt 去请求 Claude 100K API。这就很不灵活,我如果希望的 context 不是正好在一个目录里的,而某个函数定义和所有的使用方,那么就得改这个 python 脚本。
我希望 Read-Eval-Print Loop (REPL) 使用体验,就和 python notebook 一样。python notebook 是怎么在多个 cell 之间共享 context 的?是通过 python 的全局变量。如果有一种 toolformer notebook,它每个cell是 toolformer 能够理解的 dsl,就像【打开卧室的空调】这样。那这些 cell 之间如何共享 context?既不能像 chatgpt 那样无脑把所有之前的 conversation 聊天记录都做为 context 塞到后面的对话里,那样太不精确了。又不能像 python 那样的定义变量和引用变量,那样又太精确了。
比如 04搭建一个网页自动化流程 · 影刀文档 (winrobot360.com)
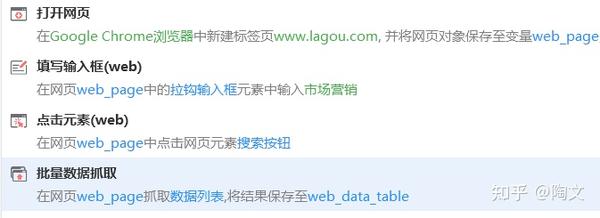
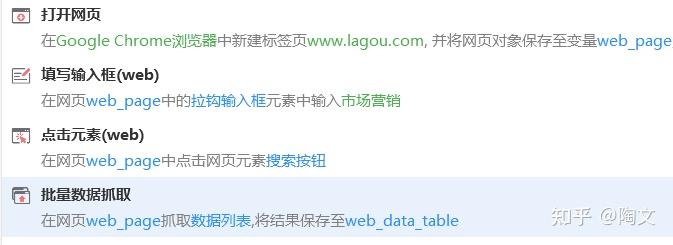
这样通过显式的定义变量的方式来 chat 就很不像 chat。更像是把 python 源代码塞进了 google translate。虽然是中文,但是用起来还是 python。所以问题就是,对于使用 LLM 多轮对话的交互形式进行一次性脚本编程,我们需要在 python 和 chatgpt 这两个极端中间,找一个中间一点的平衡点。这个平衡点很可能就是以 chatgpt 的多轮对话模式为基础,再外挂一个内存数据库。使用 text to sql 类型的 prompt 形式,在多轮聊天的过程中把这个内存数据库的读写,当成 tool 调用来对待。
那这不就是发明了一门新的编程语言吗?是的。chatgpt + 内存数据库,就是一门编程语言。和使用 langchain 挂个 vector db 做客服场景不同,那个是只读的。我们这里需要一个可读可写的db。你的 variables 就是这个数据库,你的每一轮对话就是一个 statement。多轮对话就完成了一个顺序的 statement 流程。然后给这门编程语言添加一个 notebook 的皮
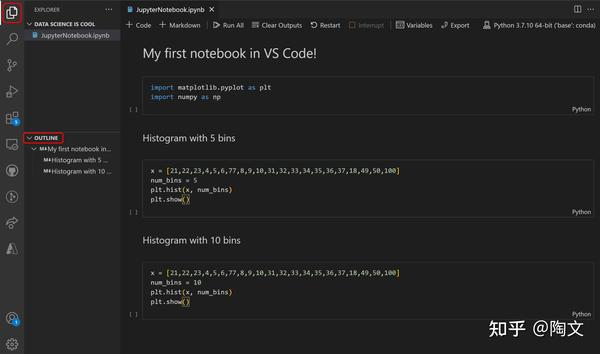
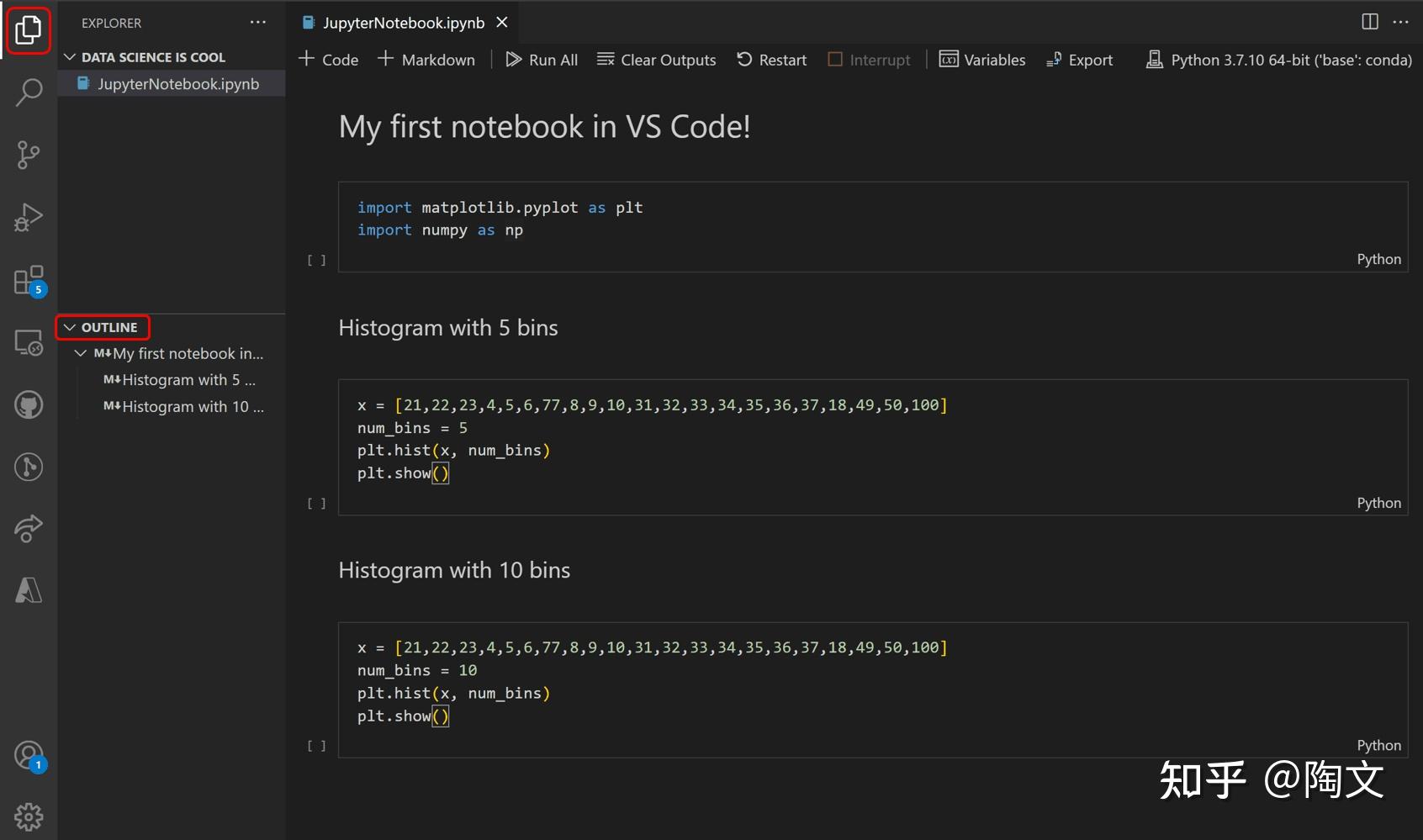
这样,就可以 chat with vscode 了。应用场景是任何需要一次性脚本自动化的地方。比如在 vscode debug console 里就非常需要。用 LLM 对大仓库做摘要,做重构,都可以用得上。
