

在Linux下做性能分析3:perf

==介绍==
ftrace的跟踪方法是一种总体跟踪法,换句话说,你统计了一个事件到下一个事件所有的时间长度,然后把它们放到时间轴上,你可以知道整个系统运行在时间轴上的分布。
这种方法很准确,但跟踪成本很高。所以,我们也需要一种抽样形态的跟踪方法。perf提供的就是这样的跟踪方法。
perf的原理是这样的:每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。这个原理图示如下:
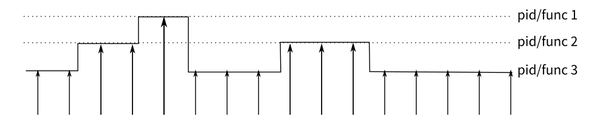
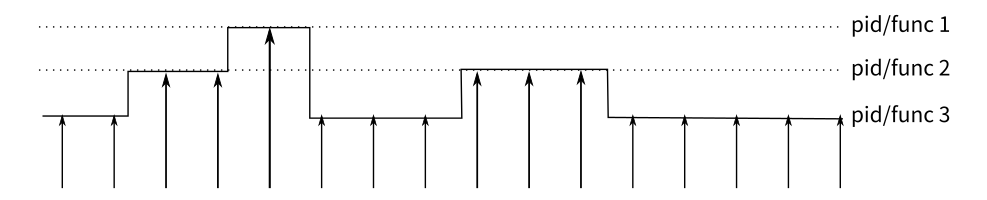
很明显可以看出,这是一种采样的模式,我们预期,运行时间越多的函数,被时钟中断击中的机会越大,从而推测,那个函数(或者pid等)的CPU占用率就越高。
这种方式可以推广到各种事件,比如上一个博文我们介绍的ftrace的事件,你也可以在这个事件发生的时候上来冒个头,看看击中了谁,然后算出分布,我们就知道谁会引发特别多的那个事件了。
当然,如果某个进程运气特别好,它每次都刚好躲过你发起探测的位置,你的统计结果可能就完全是错的了。这是所有采样统计都有可能遇到的问题了。
还是用我们介绍ftrace时用到的那个sched_switch为例,我们可以用tracepoint作为探测点,每次内核调用这个函数的时候,就上来看看,到底谁引发了这个跟踪点(这个只能用来按pid分类,按函数分类没有用,因为tracepoint的位置是固定的),比如这样:
sudo perf top -e sched:sched_switch -s pid
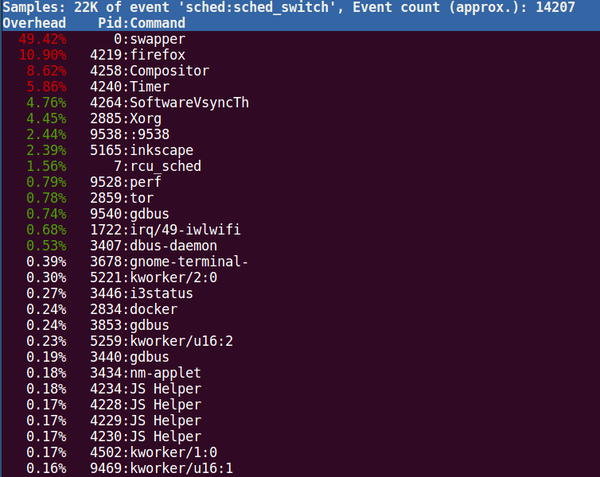

当然,perf使用更多是CPU的PMU计数器,PMU计数器是大部分CPU都有的功能,它们可以用来统计比如L1 Cache失效的次数,分支预测失败的次数等。PMU可以在这些计数器的计数超过一个特定的值的时候产生一个中断,这个中断,我们可以用和时钟一样的方法,来抽样判断系统中哪个函数发生了最多的Cache失效,分支预测失效等。
下面是一个分支预测失效的跟踪命令和动态结果:
sudo perf top -e branch-misses
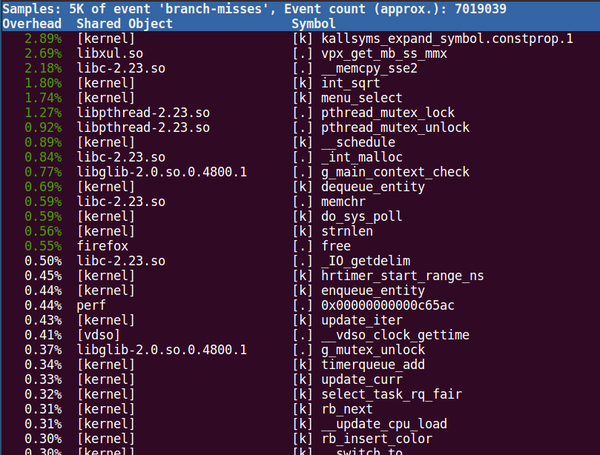

我们从这里就可以看到系统中哪些函数制造了最多的分支预测失败,我们可能就需要在那些函数中考虑一下有没有可能塞进去几个likely()/unlikely()这样的宏了。
而且读者应该也注意到了,perf比起ftrace来说,最大的好处是它可以直接跟踪到整个系统的所有程序(而不仅仅是内核),所以perf通常是我们分析的第一步,我们先看到整个系统的outline,然后才会进去看具体的调度,时延等问题。而且perf本身也告诉你调度是否正常了,比如内核调度子系统的函数占用率特别高,我们可能就知道我们需要分析一下调度过程了。
==使用perf==
perf的源代码就是Linux的源代码目录中,因为它在相当程度上和内核是关联的。它会使用Linux内核的头文件。但你编译内核的时候并不会编译它,你必须主动进入tools/perf目录下面,执行make才行。
perf支持很多功能,make的时候它会自动检查这些功能是否存在。比如前面我们用了tracepoint进行事件收集,你就要保证你的系统中有libtracepoint这个库。perf的自由度设计得相当高,很多功能你都可以没有,并不会影响你的基本功能。
由于perf和内核关联,所以理论上,你用哪个内核,就应该使用对应内核的perf,这能保证接口的一致。所以很多类似Ubuntu这样的发行版,你装哪个内核,就要装对应内核的perf命令,而通过的perf命令入其实只是个脚本,根据你当前的perf命令,调用不同perf版本。
但那只是理论上,实践中,其实perf的用户-内核接口相当稳定,很多时候跨版本使用是没有问题的,由于perf的版本还在高速发展中,而且很多发行版的perf版本没有使能很多功能,我在实践中经常直接找最新的内核自己重新编译版本,好像也没有出过什么问题。读者可以有限度参考这个经验。perf也没有很多的路径依赖,你编译完以后连安装都不用,直接用绝对路径调用你编译的版本即可。
==一般跟踪==
前面我们已经看了几个perf工作的例子了。类似git,docker等多功能工具,perf也是使用perf <子命令>这种模式。所有人首先需要学习的是两个最简单的命令:perf list和perf top。
perf list列出perf可以支持的所有事件。例如这样:
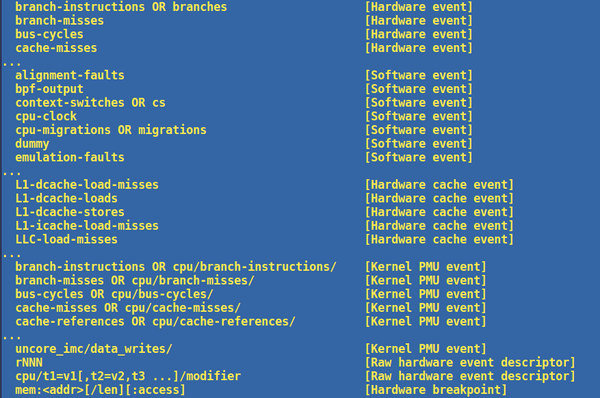
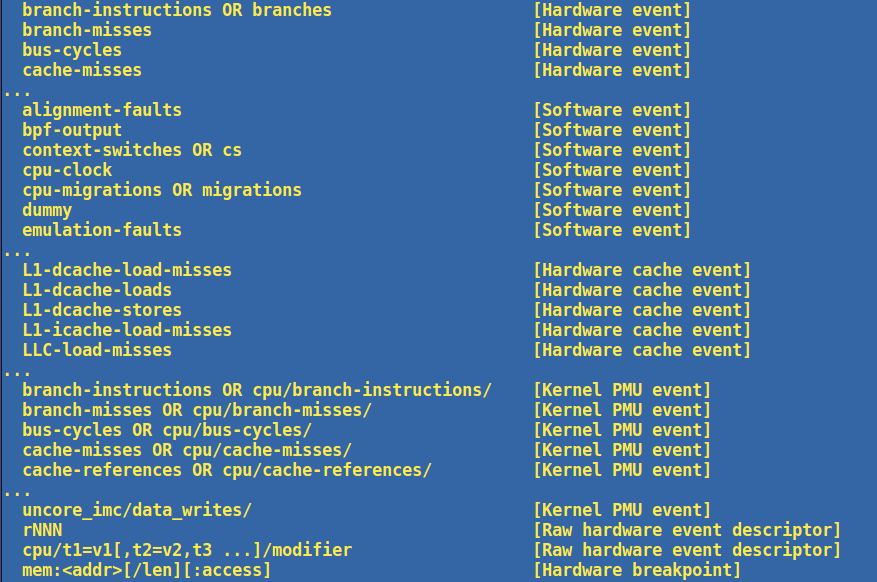
旧版本还会列出所有的tracepoint,但那个列表太长了,新版本已经不列这个东西了,读者可以直接到ftrace那边去看就好了。
perf top可以动态收集和更新统计列表,和很多其他perf命令一样。它支持很多参数,但我们关键要记住两个参数:
1. -e 指定跟踪的事件
-e可以指定前面perf list提供的所有事件(包括没有列出的tracepoint),可以用多个-e指定多个事件同时跟踪(但显示的时候会分开显示)
一个-e也可以直接指定多个事件,中间用逗号隔开即可:
sudo perf top -e branch-misses,cycles
(perf list给出的事件是厂家上传上去给Linux社区的,但有些厂家会有自己的事件统计,没有上传出去,这你需要从厂家的用户手册中获得,这种事件,可以直接用编号表示,比如格式是rXXXX,比如在我们的芯片里面,0x13号表示跨芯片内存访问,你就可以用-e r0013来跟踪软件的跨片访问次数)
事件可以指定后缀,比如我想只跟踪发生在用户态时产生的分支预测失败,我可以这样:
sudo perf top -e branch-misses:u,cycles