

Glide 图片加载框架真的强大……


鉴于Bitmap对象是如此复杂,直接使用底层API来执行图片的获取、解码、显示等工作还是有一定难度的,因而Android官方更建议我们直接使用像 Glide 之类的图片加载框架,因为此类图片加载框架已经将大部分的复杂工作都抽象出来了,使用起来相对简单,而不需要我们关心其底层是如何实现的。
但!是!作为一个有追求的高级开发工程师,怎么能停留在只会“用”的程度上呢?我们也想了解,作为Android官方力荐的图片加载框架,Glide究竟优秀在哪些方面呢?其又是如何设计与实现的呢?
秉承着这个想法,本篇内容我们将围绕着以下几个维度展开,即:
- Bitmap的使用过程中都有哪些常见问题?
- Android对此提供了哪些解决方案?
- Glide又是如何在此基础上进一步优化的?
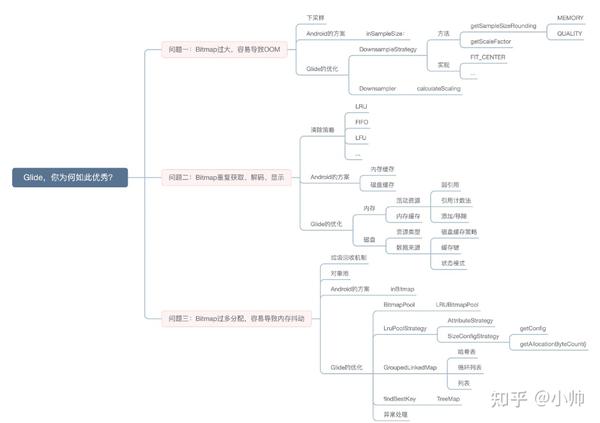
本文为下篇,同样在开始之前,先奉上的思维导图一张,方便后续复习:

问题一:Bitmap过大,容易导致OOM
众所周知,移动设备上的各项系统资源都是很稀缺的,在内存方面的一个体现就是——Android为每个应用分配的堆内存大小都是存在硬性上限的,具体的上限数值表现不一,主要取决于设备的总体可用RAM大小。
如果应用在达到了堆内存容量大小的上限后,还尝试分配更多的内存,就会触发OOM 。
而Bitmap恰恰是个贪婪的内存大户,稍不注意很容易就会耗尽应用原本就不多的内存预算。
例如有这样一台手机,其相机应用所拍摄的照片最大可达4048x3036像素(也即1200万像素),透过上篇文章我们已经知道,在Android 2.3(API 级别 9)及更高版本上
Bitmap.Config
使用的默认配置是
ARGB_8888
,也即在此配置下每个像素会占用4 bytes。
那么,把这样一张照片直接加载到内存中,大约需要 4048 * 3036 * 4 bytes ≈ 48MB。这是一个很惊人的数字,但凡多来几张,可能立即就会吞噬掉应用的所有可用内存了。

不过在实际的开发中,这种直接将整张图片加载到内存中的场景并不多见,更多情况是在一个有限的展示区域内显示图片,比如一个尺寸相对固定的ImageView。
这个时候,更合理点的做法是 根据目标ImageView的尺寸,让解码器对原始图像进行下采样,以提供一个较低分辨率版本的缩略图 。更高分辨率的图片除了占用更多的内存,以及因为额外的动态缩放而产生额外的性能开销之外,并不会带来其他什么明显的好处。
下采样(subsampled),亦称为降采样(downsampled),也即缩小图像,主要目的有两个:
- 使得图像符合显示区域的大小;
- 生成对应图像的缩略图。
对于一幅尺寸为M N的图像,对其进行s倍下采样,即可得到(M/s) (N/s)尺寸的图像。
如果考虑的是矩阵形式的图像,则是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是参考窗口内所有像素,根据相对位置取对应的权重得到的均值。
Android的方案
在Android中,让解码器对原始图像进行下采样的关键实现,就在于
BitmapFactory.Options
解码选项类的
inSampleSize
属性。
inSampleSize
从字面意义上理解是
样本大小
的意思,按官方文档上的解释如下:
- 如果设置的值>1,会请求解码器对原始图像进行下采样,(从而)返回较小的图像以节省内存。
- 样本大小指的是(在宽与高)任一维中,与所解码位图中的单个像素相对应的像素数。
- 例如, inSampleSize == 4 时所返回的图像宽度/高度均为原始图像的 1/4,像素数为(为原始图像的)1/16。任何值<= 1都与1相同。
- 注意:解码器使用基于2的次幂的最终值,任何其他值都将四舍五入到最近的2的次幂。
第3项不太理解的话可以看一下我画的示意图:
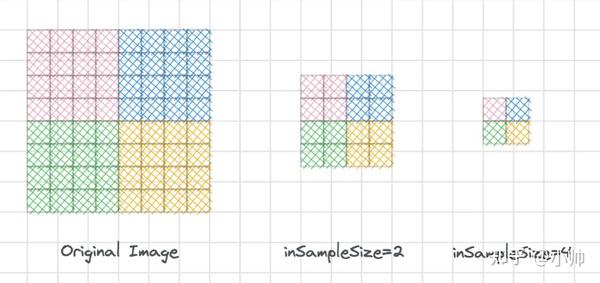

还是以上面的相机应用所拍摄的分辨率为 4048x3036 的照片为例,以
inSampleSize
为4进行解码后,会生成大约 1012x759 的位图,现在再将此照片加载到内存中,只需要 3MB 的大小。
可以看到,由于像素数量的急剧减少,Bitmap所占用的内存也有了比较大的降幅。当然,
inSampleSize
的值也不是越大越好,始终还是应该在
图像细节
和
内存占用
之间达到相对的平衡。
以下就是Android为我们提供的示例,演示如何计算
inSampleSize
值,共分为3步进行:
步骤1,在为构造的Bitmap实际分配内存之前,先读取所解码图片的尺寸:
val options = BitmapFactory.Options().apply {
inJustDecodeBounds = true
BitmapFactory.decodeResource(resources, R.id.myimage, options)
val imageHeight: Int = options.outHeight
val imageWidth: Int = options.outWidth
inJustDecodeBounds
属性表示
只解码边界
,此处设置为true后,会返回一个
空的Bitmap对象
,但会设置
outWidth
、
outHeight
等值,这样就可以
查询Bitmap的宽高等信息,而无需为其像素实际分配内存
了,避免一开始就因加载超大尺寸图片而使内存暴涨。
步骤2,比较原始图片的尺寸与请求的尺寸,在保持最后采样的宽和高都大于请求的宽和高的前提下(避免图像失真),以2的幂计算最大inSampleSize值:
fun calculateInSampleSize(options: BitmapFactory.Options, reqWidth: Int, reqHeight: Int): Int {
val (height: Int, width: Int) = options.run { outHeight to outWidth }
var inSampleSize = 1
if (height > reqHeight || width > reqWidth) {
val halfHeight: Int = height / 2
val halfWidth: Int = width / 2
while (halfHeight / inSampleSize >= reqHeight && halfWidth / inSampleSize >= reqWidth) {
inSampleSize *= 2
return inSampleSize
}
步骤3,使用计算好的
inSampleSize
值,并将
inJustDecodeBounds
重新设为false后,再次进行解码:
fun decodeSampledBitmapFromResource(
res: Resources,
resId: Int,
reqWidth: Int,
reqHeight: Int
): Bitmap {
return BitmapFactory.Options().run {
inJustDecodeBounds = true
BitmapFactory.decodeResource(res, resId, this)
inSampleSize = calculateInSampleSize(this, reqWidth, reqHeight)
inJustDecodeBounds = false
BitmapFactory.decodeResource(res, resId, this)
}Glide的优化
Glide同样会根据目标控件的尺寸,对图片进行适当的下采样、裁剪和变换,以减少内存占用,并确保加载过程尽快完成。
其下采样的关键实现之一在于
DownsampleStrategy
类,该类用于
指示下采样图像时要使用的算法
,从名字上就可以看出,其采用的是23种设计模式中的
策略模式
,
根据不同的缩放模式有不同的策略实现
。
我们先来看看它的策略接口定义:
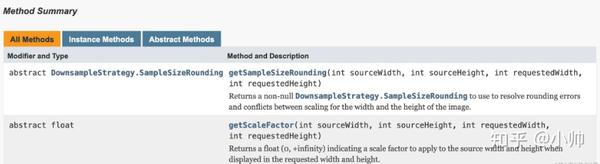

getSampleSizeRounding
方法表示的是
获取样本大小舍入规则
,其返回的
SampleSizeRounding
类型是一个枚举,用于
定义在对
inSampleSize
值四舍五入到最近的2次幂时,是偏向于往更大值取还是往更小值取
,有以下两种类型:
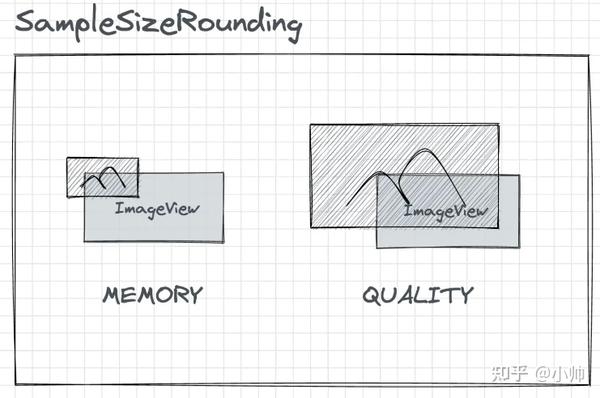
- MEMORY : 省内存 ,即会更倾向于将图像向下采样至 小于 目标大小,以使用更少的内存。
- QUALITY : 保质量 ,即会更倾向于将图像向下采样至 大于 目标大小,以保持图像的质量,会牺牲额外的内存使用。

getScaleFactor
方法则会
返回一个浮点型的缩放因子
,用于
指示原始尺寸和目标尺寸之间的缩放比
。
我们再来看看它有哪些具体的策略实现:
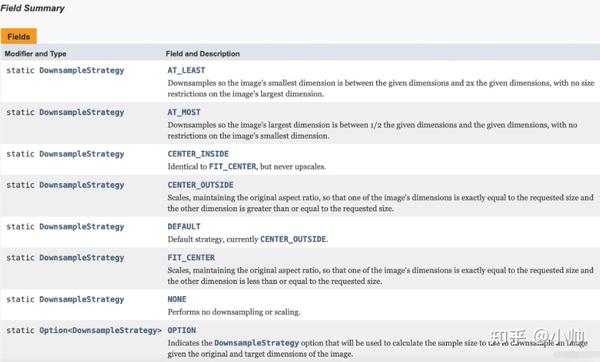

正如你所见,其对应的其实就是
ImageView
的缩放模式。
由于默认情况下,
ImageView
采用的缩放模式是
FIT_CENTER
,于是我们优先来看看
FIT_CENTER
策略的内部实现(省略了部分源码):
@Synthetic
static final boolean IS_BITMAP_FACTORY_SCALING_SUPPORTED =
Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT;
private static class FitCenter extends DownsampleStrategy {
@Synthetic
FitCenter() {}
@Override
public float getScaleFactor(
int sourceWidth, int sourceHeight, int requestedWidth, int requestedHeight) {
if (IS_BITMAP_FACTORY_SCALING_SUPPORTED) {
float widthPercentage = requestedWidth / (float) sourceWidth;
float heightPercentage = requestedHeight / (float) sourceHeight;
return Math.min(widthPercentage, heightPercentage);
} else {
@Override
public SampleSizeRounding getSampleSizeRounding(
int sourceWidth, int sourceHeight, int requestedWidth, int requestedHeight) {
if (IS_BITMAP_FACTORY_SCALING_SUPPORTED) {
return SampleSizeRounding.QUALITY;
} else {
}可以看到,在Android 4.4(API 级别 19)及更高版本上其缩放因子选用的是 宽度缩放比与高度缩放比中数值更小的 那个,采样大小舍入规则选用的是 保质量 。
下采样另一关键的实现在于
Downsampler
类,该类内部实际使用了
BitmapFactory
来实现对图像进行的采样、解码和旋转等操作,其中,关于采样部分和缩放部分的数值计算集中在
calculateScaling
方法,这个方法的主要工作可以分为以下几步:
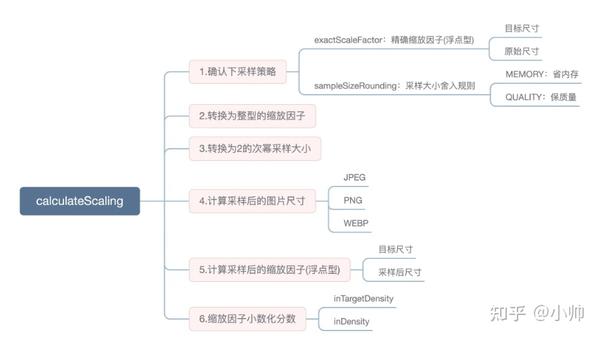

步骤1, 确认下采样策略 。
下采样策略的选择会影响到后面一系列数值的计算。由于我们没有明确指定
ImageView
的缩放模式,因此默认采用的就是
FIT_CENTER
缩放模式,该部分源码及解释前面已经贴出,不再赘述。
private static void calculateScaling(...)
throws IOException {
// 1 确认下采样策略
int orientedSourceWidth = sourceWidth; // 原始图片宽度
int orientedSourceHeight = sourceHeight; // 原始图片高度
// 1.1 获取精确缩放因子(浮点型)
final float exactScaleFactor =
downsampleStrategy.getScaleFactor(
orientedSourceWidth, orientedSourceHeight, targetWidth, targetHeight);
// 1.2 采样大小舍入规则
SampleSizeRounding rounding =
downsampleStrategy.getSampleSizeRounding(
orientedSourceWidth, orientedSourceHeight, targetWidth,
...步骤2,将浮点型的缩放因子 转换为整型的缩放因子 。
从这里开始
SampleSizeRounding
就开始扮演起其角色了:
如果是 省内存模式 ,则取宽度缩放因子与高度缩放因子中数值更大的那一个 ,如此将导致计算出来的采样大小更大,下采样后的图片尺寸更小,因而更省内存,相对的会损失更多的图片质量,保质量模式 *则相反。
...
// 2 转换为整型的缩放因子
int outWidth = round(exactScaleFactor * orientedSourceWidth); // 按精确缩放因子缩放后的宽度
int outHeight = round(exactScaleFactor * orientedSourceHeight); // 按精确缩放因子缩放后的高度
int widthScaleFactor = orientedSourceWidth / outWidth; // 整型宽度缩放因子
int heightScaleFactor = orientedSourceHeight / outHeight; // 整型高度缩放因子
// 2.1 根据SampleSizeRounding选取合适的缩放因子
int scaleFactor =
rounding == SampleSizeRounding.MEMORY
? Math.max(widthScaleFactor, heightScaleFactor)
: Math.min(widthScaleFactor, heightScaleFactor);
...步骤3,将整型的缩放因子 转换为2的次幂采样大小 :
// 3 转换为2的次幂采样大小
int powerOfTwoSampleSize;
// 部分格式不支持
if (Build.VERSION.SDK_INT <= 23
&& NO_DOWNSAMPLE_PRE_N_MIME_TYPES.contains(options.outMimeType)) {
powerOfTwoSampleSize = 1;
} else {
powerOfTwoSampleSize = Math.max(1, Integer.highestOneBit(scaleFactor));
if (rounding == SampleSizeRounding.MEMORY
&& powerOfTwoSampleSize < (1.f / exactScaleFactor)) {
powerOfTwoSampleSize = powerOfTwoSampleSize << 1;
}步骤4,基于上一步得出的采样大小,根据不同的图片类型, 计算采样后的图片尺寸 :
options.inSampleSize = powerOfTwoSampleSize;
int powerOfTwoWidth;
int powerOfTwoHeight;
if (imageType == ImageType.JPEG) {
} else if (imageType == ImageType.PNG || imageType == ImageType.PNG_A) {
powerOfTwoWidth = (int) Math.floor(orientedSourceWidth / (float) powerOfTwoSampleSize);
powerOfTwoHeight = (int) Math.floor(orientedSourceHeight / (float) powerOfTwoSampleSize);
} else if (imageType.isWebp()) {
} else if (orientedSourceWidth % powerOfTwoSampleSize != 0
} else {
}
我们着重理清
calculateScaling
方法的流程,所以这里仅展示较简单的PNG格式相关代码。
步骤5,将采样后的尺寸和目标尺寸传入到策略实现类,计算采样后的缩放因子(浮点型):
double adjustedScaleFactor =
downsampleStrategy.getScaleFactor(
powerOfTwoWidth, powerOfTwoHeight, targetWidth, targetHeight);
最后一步比较难理解,其实这样做实际就相当于
把缩放因子小数化分数
,比如0.5=1/2,随后把1和2分别设置到
inTargetDensity
和
inDensity
。
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) {
options.inTargetDensity = adjustTargetDensityForError(adjustedScaleFactor);
options.inDensity = getDensityMultiplier(adjustedScaleFactor);
if (isScaling(options)) {
options.inScaled = true;
} else {
options.inDensity = options.inTargetDensity = 0;
}private static int adjustTargetDensityForError(double adjustedScaleFactor) {
int densityMultiplier = getDensityMultiplier(adjustedScaleFactor);
int targetDensity = round(densityMultiplier * adjustedScaleFactor);
float scaleFactorWithError = targetDensity / (float) densityMultiplier;
double difference = adjustedScaleFactor / scaleFactorWithError;
return round(difference * targetDensity);
private static int getDensityMultiplier(double adjustedScaleFactor) {
return (int) Math.round(
Integer.MAX_VALUE
* (adjustedScaleFactor <= 1D ? adjustedScaleFactor : 1 / adjustedScaleFactor));
}
至于为什么是这两个参数,看过上篇文章的朋友们应该还记得,我们在分析到Native层的
doDecode
方法内部时,可以看到其正是利用
inTargetDensity
和
inDensity
实现对Bitmap的
精确缩放
的。
static jobject doDecode(JNIEnv* env, SkStreamRewindable* stream, jobject padding, jobject options) {
float scale = 1.0f;
if (env->GetBooleanField(options, gOptions_scaledFieldID)) {
const int density = env->GetIntField(options, gOptions_densityFieldID);
const int targetDensity = env->GetIntField(options, gOptions_targetDensityFieldID);
const int screenDensity = env->GetIntField(options, gOptions_screenDensityFieldID);
if (density != 0 && targetDensity != 0 && density != screenDensity) {
scale = (float) targetDensity / density;
const bool willScale = scale != 1.0f;
int scaledWidth = decodingBitmap.width();
int scaledHeight = decodingBitmap.height();
if (willScale && decodeMode != SkImageDecoder::kDecodeBounds_Mode) {
scaledWidth = int(scaledWidth * scale + 0.5f);
scaledHeight = int(scaledHeight * scale + 0.5f);
if (options != NULL) {
env->SetIntField(options, gOptions_widthFieldID, scaledWidth);
env->SetIntField(options, gOptions_heightFieldID, scaledHeight);
env->SetObjectField(options, gOptions_mimeFieldID,
getMimeTypeString(env, decoder->getFormat()));
}
小结一下,Glide在Android提供的
inSampleSize
方案的基础上,又提供了以下进一步优化:
- 根据不同的缩放模式提供了不同的下采样策略实现,能应对更加丰富多变的场景
- 提前将采样大小转换为了2的次幂,避免Native层的再次运算,并考虑了部分图片格式不支持采样的情况
- 根据不同的图片类型,提供相应的公式来计算采样后的图片尺寸
-
将采样后缩放因子拆分到
inTargetDensity和inDensity,以实现采样后再精确缩放至目标尺寸
问题二:Bitmap重复获取、解码、显示
单张图片的加载并没有什么难度,但大多数情况下我们面临的是一个界面上要同时加载多张图片,并且随着不同的交互效果,会有更多的图片待加载进来的场景。
瀑布流式布局 就是这种短时间内密集加载大量图片的场景的集中体现。

一般而言,像
RecyclerView
、
ViewPager
这类组件,
当其所包含的子视图被移出屏幕后,系统默认会循环利用该子视图,以控制这类组件所占用的内存总量
。
这也意味着,该子视图上 原先已加载的Bitmap会被释放 ,而当该子视图重新回到屏幕后,就免不了需要 重新处理Bitmap的获取、解码、显示等工作 ,这将 极大地降低界面加载图片的响应性和流畅性 。
为了改善这种情况,保证图片能够快速、流畅地被重新加载,引入缓存机制很有必要。
Android的方案
使用内存缓存
内存缓存的最大优势就在于可以 加快资源的访问速度 ,代价就是需要 牺牲掉应用部分可用内存 。
这里插句题外话,请问一个缓存的设计最核心的内容是什么?
是 清除策略 。
因为数据不可能无限期存储,肯定会有一个上限,达到上限后就需要有清除策略来清除,而不同的清除策略又会决定我们采用什么数据结构来存储比较合适。
常见的清除策略有诸如:
-
LRU
:Least Recently Used 的缩写,即
最近最少使用
。会移除最长时间不被使用的对象;常见的使用
LinkedHashMap来实现,也是 很多本地缓存默认使用的策略 ; -
FIFO
:先进先出,按对象进入缓存的顺序来移除它们;常见使用队列
Queue来实现; -
LFU
:Least Frequently Used 的缩写,大概也是最近最少使用的意思,和LRU有点像;区别点在于
LRU的淘汰规则是基于访问时间
,而
LFU是基于访问次数的
;可以通过
HashMap记录访问次数来实现; - ...
LruCache
类是Android SDK提供的内存缓存的实现类,非常适合用于缓存Bitmap,当然也并非完全是开箱即用的,最直接面临的一个问题就是,该为
LruCache
分配多少内存大小?
分配的内存过小,会导致数据的频繁持有与移除,既产生了额外的开销,又对实际问题的解决没什么帮助。
分配的内存过大,挤占了应用其余部分的可用内存不说,严重的更可能引发OOM异常。
缓存大小的合理设置需要综合考虑多种因素,Android官方为我们提供了以下几个维度参考:
- 应用剩余内存
- 屏幕内图片可显示数量、待加载数量
- 设备的屏幕尺寸和密度
- 位图的尺寸和配置
- 图片的访问频率
- 质量和数量的平衡
- ...
当然,这些都只是参考,实际并没有什么万能公式可以得出一个具体的数值,还是我们需要结合应用自身的时机情况来确定。
Android官方提供的示例中,就是通过计算应用的最大可用内存,然后将其1/8分配给了内存缓存来制定的:
private lateinit var memoryCache: LruCache<String, Bitmap>
override fun onCreate(savedInstanceState: Bundle?) {
val maxMemory = (Runtime.getRuntime().maxMemory() / 1024).toInt()
val cacheSize = maxMemory / 8
memoryCache = object : LruCache<String, Bitmap>(cacheSize) {
}
有了内存缓存之后,每次获取
Bitmap
时都会先尝试从内存缓存中查找,找不到再开启一个后台线程从磁盘或网络获取:
fun loadBitmap(resId: Int, imageView: ImageView) {
val bitmap: Bitmap? = getBitmapFromMemCache(imageKey)?.also {
mImageView.setImageBitmap(it)
} ?: run {
mImageView.setImageResource(R.drawable.image_placeholder)
val task = BitmapWorkerTask()
task.execute(resId)
}
而当从后台线程获取到
Bitmap
后,也需要相应的添加或更新到内存缓存:
private inner class BitmapWorkerTask : AsyncTask<Int, Unit, Bitmap>() {
override fun doInBackground(vararg params: Int?): Bitmap? {
return params[0]?.let { imageId ->
decodeSampledBitmapFromResource(resources, imageId, 100, 100)?.also { bitmap ->
addBitmapToMemoryCache(imageId.toString(), bitmap)
}使用磁盘缓存
内存缓存的最大问题在于,其并非是持久化缓存, 当应用由于各种原因被终止,内存缓存也将随之销毁 。特别是应用被切到后台的情况,用户极有可能会回到应用,此时前面描述过的相同的问题就会再次出现。
针对这种情况,我们可以使用 磁盘缓存 来解决。
DiskLruCache
类是Android SDK提供的磁盘缓存的实现类,从名字上就可以看出,其与
LruCache
类一样都是基于LRU清除策略,只是所存储的位置不一样而已。
在实际的应用中,二者也并非是互斥的,通常是我们将图片进行变换处理后,会将最后生成的
Bitmap
同时添加到内存缓存与磁盘缓存,使用时会优先从内存缓存中查找,当从内存缓存找不到相应资源时,再尝试到磁盘缓存中查找。
磁盘缓存的初始化和读取都涉及磁盘IO操作,相对于内存缓存较慢,具体耗时无法预测,因此通常需要放到后台线程进行,需做好线程的同步与互斥。
与应用内存相比,磁盘空间的大小相对于来说没那么紧张,因此Android官方提供的示例中,为磁盘缓存分配的大小是一个固定的数值:
private const val DISK_CACHE_SIZE = 1024 * 1024 * 10 // 10MB
private const val DISK_CACHE_SUBDIR = "thumbnails"
private var diskLruCache: DiskLruCache? = null
private val diskCacheLock = ReentrantLock()
private val diskCacheLockCondition: Condition = diskCacheLock.newCondition()
private var diskCacheStarting = true
override fun onCreate(savedInstanceState: Bundle?) {
// 在后台线程初始化磁盘缓存
val cacheDir = getDiskCacheDir(this, DISK_CACHE_SUBDIR)
InitDiskCacheTask().execute(cacheDir)
internal inner class InitDiskCacheTask : AsyncTask<File, Void, Void>() {
override fun doInBackground(vararg params: File): Void? {
diskCacheLock.withLock {
val cacheDir = params[0]
diskLruCache = DiskLruCache.open(cacheDir, DISK_CACHE_SIZE)
diskCacheStarting = false // 完成初始化
diskCacheLockCondition.signalAll() // 唤醒所有等待中的线程
return null
internal inner class BitmapWorkerTask : AsyncTask<Int, Unit, Bitmap>() {
// 在后台线程解码图像
override fun doInBackground(vararg params: Int?): Bitmap? {
val imageKey = params[0].toString()
// 在后台线程检查磁盘缓存
return getBitmapFromDiskCache(imageKey) ?:
// 磁盘缓存找不到
decodeSampledBitmapFromResource(resources, params[0], 100, 100)
?.also {
// 添加Bitmap到缓存
addBitmapToCache(imageKey, it)
fun addBitmapToCache(key: String, bitmap: Bitmap) {
// 添加到内存缓存
if (getBitmapFromMemCache(key) == null) {
memoryCache.put(key, bitmap)
// 也添加到磁盘缓存
synchronized(diskCacheLock) {
diskLruCache?.apply {
if (!containsKey(key)) {
put(key, bitmap)
fun getBitmapFromDiskCache(key: String): Bitmap? =
diskCacheLock.withLock {
// 等待后台线程磁盘缓存初始化完毕
while (diskCacheStarting) {
try {
diskCacheLockCondition.await()
} catch (e: InterruptedException) {
return diskLruCache?.get(key)
fun getDiskCacheDir(context: Context, uniqueName: String): File {
val cachePath =
if (Environment.MEDIA_MOUNTED == Environment.getExternalStorageState()
|| !isExternalStorageRemovable()) {
context.externalCacheDir.path
} else {
context.cacheDir.path
return File(cachePath + File.separator + uniqueName)
}Glide的优化
Glide的多级缓存方案同样基于内存和磁盘,并在此基础上进一步细化了多种场景、划分了不同类型,如下表所示:


内存部分的优化
先来讲讲内存部分。
可以看到,Glide的内存缓存(Memory Cache)同样采用了LRU清除策略,与Android提供的方案差别不大,只不过其并没有直接复用Android SDK所提供的
LruCache
类,而是在其内部自己实现了一套。
package com.bumptech.glide.load.engine.cache;
public class LruResourceCache extends LruCache<Key, Resource<?>> implements MemoryCache {
}package com.bumptech.glide.util;
public class LruCache<T, Y> {
}清除策略的由来我们前面已经讲过,是为了避免缓存数据的持续累积加重内存与磁盘空间的存储负担, 当存储的数据达到所指定的数量上限或容量上限后,就会触发相应的回收算法来清除一部分数据以释放空间 。
这种做法本身并没有什么问题,但假设遇到了比较边界的情况,比如 准备回收的图片资源刚好正在使用中 ,此时如果仍然不顾实际情况强行回收的话,必然会引发各种预期之外的问题。
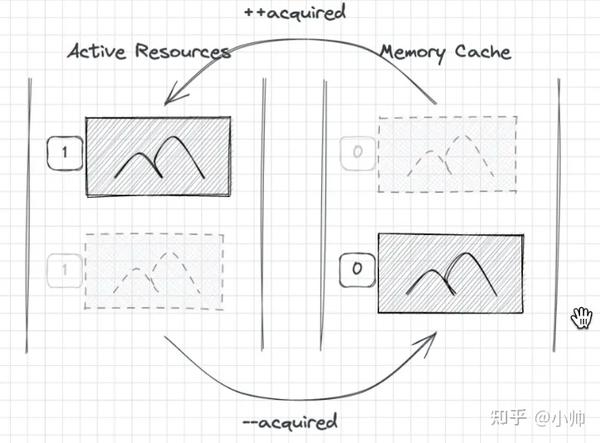
活动资源(Active Resources)的设计目的,正是为了
避免使用中的图片资源被意外回收
,其内部实现是将
Bitmap
以
弱引用
的形式保存到
HashMap
。
final class ActiveResources {
final Map<Key, ResourceWeakReference> activeEngineResources = new HashMap<>();
}static final class ResourceWeakReference extends WeakReference<EngineResource<?>> {
}弱引用我们并不陌生,当一个对象只被弱引用所引用时, 只要垃圾回收器扫描到它,不管内存空间充足与否,都会回收其内存 ,避免了非必要对象过多造成的内存不足或不正确强引用造成的内存泄漏。
那么,Glide是如何判断图片资源 正在使用中 呢?
答案是 引用计数法 。
EngineResource
是一个包装类,对资源对象的抽象
Resource
接口进行了包装,增加了引用计数的功能:
public class Engine implements EngineJobListener,
MemoryCache.ResourceRemovedListener,
EngineResource.ResourceListener {
private EngineResource<?> loadFromActiveResources(Key key, boolean isMemoryCacheable) {
// 1.从活动缓存加载资源
EngineResource<?> active = activeResources.get(key);
if (active != null) {
// 2.若资源存在,增加引用计数
active.acquire();
return active;
...class EngineResource<Z> implements Resource<Z> {
private ResourceListener listener;
// 资源被引用的次数
private int acquired;
synchronized void acquire() {
// 引用次数自增
++acquired;
void release() {
synchronized (listener) {
synchronized (this) {
if (acquired <= 0) {
throw new IllegalStateException("Cannot release a recycled or not yet acquired resource");
// 引用次数自减
if (--acquired == 0) {
// 资源释放回调
listener.onResourceReleased(key, this);
}正如源码所示, 当该资源对象每被使用时,则引用计数加一,如果不再使用,则引用计数减一,当引用计数为0时,则执行资源释放的回调 。
活动资源作为Glide多级缓存读取的起点,优先级最高,我们可以从源码中得到验证:
public class Engine implements EngineJobListener,
MemoryCache.ResourceRemovedListener,
EngineResource.ResourceListener {
public synchronized <R> LoadStatus load(...) {
// 1.从活动缓存加载
EngineResource<?> active = loadFromActiveResources(key, isMemoryCacheable);
if (active != null) {
cb.onResourceReady(active, DataSource.MEMORY_CACHE);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from active resources", startTime, key);
return null;
// 2.从内存缓存加载
EngineResource<?> cached = loadFromCache(key, isMemoryCacheable);
if (cached != null) {
cb.onResourceReady(cached, DataSource.MEMORY_CACHE);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from cache", startTime, key);
return null;
// 3.从磁盘缓存或网络加载
EngineJob<R> engineJob = engineJobFactory.build(...);
DecodeJob<R> decodeJob = decodeJobFactory.build(...);
jobs.put(key, engineJob);
engineJob.addCallback(cb, callbackExecutor);
engineJob.start(decodeJob);
return new LoadStatus(cb, engineJob);
}如果在活动资源中找不到匹配的资源,就会尝试从内存缓存中接着查找,如果找到了,就会 将资源从内存缓存中移除,然后添加到活动资源 :
public class Engine implements EngineJobListener,
MemoryCache.ResourceRemovedListener,
EngineResource.ResourceListener {
private EngineResource<?> loadFromCache(Key key, boolean isMemoryCacheable) {
// 1.从内存缓存中查找资源
EngineResource<?> cached = getEngineResourceFromCache(key);
// 2.若资源存在,则移至活动缓存
if (cached != null) {
cached.acquire();
activeResources.activate(key, cached);
return cached;
private EngineResource<?> getEngineResourceFromCache(Key key) {
Resource<?> cached = cache.remove(key);
return result;
}而当 所有地方都释放了对该资源的使用时,该资源又会从活动资源中移除,并添加至内存缓存 :
public class Engine implements EngineJobListener,
MemoryCache.ResourceRemovedListener,
EngineResource.ResourceListener {
public synchronized void onResourceReleased(Key cacheKey, EngineResource<?> resource) {
// 1.从活动资源中移除
activeResources.deactivate(cacheKey);
if (resource.isCacheable()) {
// 2.添加至内存缓存
cache.put(cacheKey, resource);
} else {
}整个流程的示意图如下:

磁盘部分的优化
内存部分讲完了,我们再来讲讲磁盘部分。
全文到此处为止所提到的缓存,包括内存与磁盘缓存,所存储的都是 修改后的图片 ,也即 经过了缩放、旋转等变换处理后的Bitmap对象 。
仅存储修改后的图片这种做法的弊端就是, 一旦图片需要显示在另外一个不同规格的控件上,就需要重新获取原始图片并再次历经一系列变换处理 。
如果更不幸的原始图片来源于网络,需要消耗额外的电量与流量下载图片不说,图片的重新显示也会有明显的延迟。
这也是为什么Glide的磁盘缓存要进一步拆分为资源类型(Resource)和数据来源(Data),主要还是为了应对不同的图片加载场景,比如:
- 对于 远程图片 ,Glide更倾向于 缓存未经修改过的原始图片数据 ,因为网络IO比磁盘IO更加昂贵。
- 对于 本地图片 ,Glide则更倾向于 仅缓存变换过的缩略图 ,因为要取回原始图片数据重新操作也很容易。
当然,以上只是Glide默认的磁盘缓存策略
AUTOMATIC
的处理,我们可以根据实际需要灵活变换为其他策略:


读到这里不知道你们有没有产生一个疑问,就是Glide既然会缓存变换后的缩略图,那也就意味着图片的每一次缩放、旋转都可能产生新的缩略图,Glide是如何标记区分这些缩略图以便后续查找的呢?
这就涉及到Glide 缓存键 的生成规则了。
一般而言,Glide的缓存键的组成至少包含以下2个元素:
- 请求加载的 模型 (File, Uri, Url等)
- 可选的 签名
对于除数据来源(Data)之外的其他级别的缓存,可能还会包含其他一些数据,比如:
- 图片的宽度和高度
- 执行的变换操作
- 配置的加载选项
- 请求的数据类型 (Bitmap, GIF, 或其他)
Glide会综合以上的元素进行 哈希化 ,以生成 磁盘缓存的缓存键名称 ,并在随后作为磁盘缓存文件的文件名使用:
public class Engine implements EngineJobListener,
MemoryCache.ResourceRemovedListener,
EngineResource.ResourceListener {
public synchronized <R> LoadStatus load(...) {
EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations,
resourceClass, transcodeClass, options);
}有了缓存键后,我们就可以很方便地查找到唯一的磁盘缓存文件了。
前面在讨论活动缓存时有简单提到,当从活动资源、内存缓存中都没能找到匹配的资源时,就会尝试从磁盘缓存中加载:
public class Engine implements EngineJobListener,
MemoryCache.ResourceRemovedListener,
EngineResource.ResourceListener {
public synchronized <R> LoadStatus load(...) {
// 3.从磁盘缓存或网络加载
EngineJob<R> engineJob = engineJobFactory.build(...);
DecodeJob<R> decodeJob = decodeJobFactory.build(...);
jobs.put(key, engineJob);
engineJob.addCallback(cb, callbackExecutor);
engineJob.start(decodeJob);
return new LoadStatus(cb, engineJob);
}class EngineJob<R> implements DecodeJob.Callback<R>,
Poolable {
public synchronized void start(DecodeJob<R> decodeJob) {
this.decodeJob = decodeJob;
GlideExecutor executor = decodeJob.willDecodeFromCache()
? diskCacheExecutor
: getActiveSourceExecutor();
executor.execute(decodeJob);
}
其内部实际开启了一个线程任务并放入了
GlideExecutor
线程池,既然是线程任务,那么其核心业务的执行必然是在
run
方法:
class DecodeJob<R> implements DataFetcherGenerator.FetcherReadyCallback,
Runnable,
Comparable<DecodeJob<?>>,
Poolable {
private Stage stage;
public void run() {
runWrapped();
private void runWrapped() {
switch (runReason) {
case INITIALIZE:
stage = getNextStage(Stage.INITIALIZE);
currentGenerator = getNextGenerator();
runGenerators();
break;
case SWITCH_TO_SOURCE_SERVICE:
runGenerators();
break;
case DECODE_DATA:
decodeFromRetrievedData();
break;
default:
throw new IllegalStateException("Unrecognized run reason: " + runReason);
}不了解设计模式的同学初看这段代码可能有点云里雾里,但其实它是用到了23种设计模式中的 状态模式 。
状态模式这里简单讲一下, 当一个对象存在多种状态,并且控制对象状态变化的表达式太过复杂时 ,就可以使用状态模式来处理,把相关逻辑转移到表示不同状态的一系列类中去,简化原先的判断逻辑。
另外,在状态模式中, 对象的行为通常取决于它的状态,并且需要在运行时根据状态动态改变 。
这里的
Stage
类即表示其当前的状态,表示我们当前阶段将从何处解码图片数据,共有以下几种可能的取值:
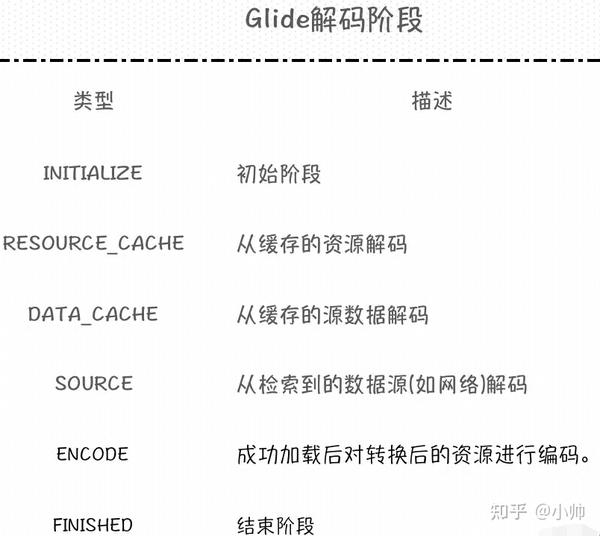

状态切换
的逻辑集中在
getNextStage
方法,配合我们选定的磁盘缓存策略,决定了每个状态对应的下一个状态是什么:
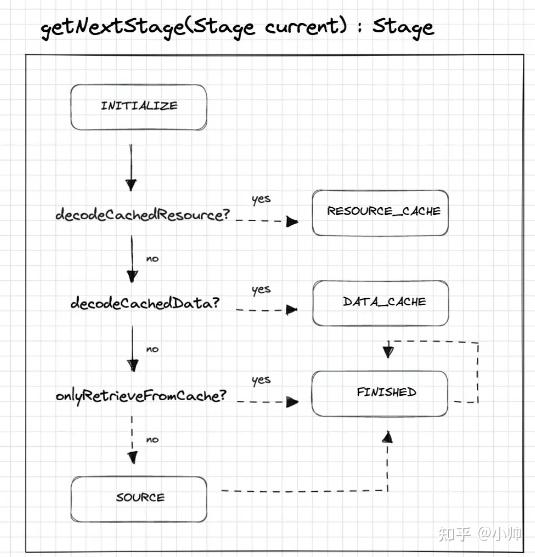
private Stage getNextStage(Stage current) {
switch (current) {
case INITIALIZE:
return diskCacheStrategy.decodeCachedResource()
? Stage.RESOURCE_CACHE : getNextStage(Stage.RESOURCE_CACHE);
case RESOURCE_CACHE:
return diskCacheStrategy.decodeCachedData()
? Stage.DATA_CACHE : getNextStage(Stage.DATA_CACHE);
case DATA_CACHE:
// Skip loading from source if the user opted to only retrieve the resource from cache.
return onlyRetrieveFromCache ? Stage.FINISHED : Stage.SOURCE;
case SOURCE:
case FINISHED:
return Stage.FINISHED;
default:
throw new IllegalArgumentException("Unrecognized stage: " + current);
}整个流程可以用以下示意图表示:

而每个状态所拥有的共同的行为被抽象到了
DataFetcherGenerator
接口,行为映射的逻辑集中在了
getNextGenerator
方法处理:
private DataFetcherGenerator getNextGenerator() {
switch (stage) {
case RESOURCE_CACHE:
return new ResourceCacheGenerator(decodeHelper, this);
case DATA_CACHE:
return new DataCacheGenerator(decodeHelper, this);
case SOURCE:
return new SourceGenerator(decodeHelper, this);
case FINISHED:
return null;
default:
throw new IllegalStateException("Unrecognized stage: " + stage);
}
确定了状态所对应的行为后,就要调用
runGenerators()
方法执行其行为:
private void runGenerators() {
boolean isStarted = false;
while (!isCancelled && currentGenerator != null
&& !(isStarted = currentGenerator.startNext())) {
stage = getNextStage(stage);
currentGenerator = getNextGenerator();
if (stage == Stage.SOURCE) {
reschedule();
return;
}
其核心在于行为类的
startNext()
方法,该方法返回一个布尔值,表示是否检索到资源并开始加载,如果为false,则切换到下一阶段继续执行。
小结一下,Glide在Android提供的内存与磁盘缓存的方案的基础上,又提供了以下进一步优化:
- 内存部分增加了活动资源类型,避免了使用中的图片资源被意外回收。
- 磁盘部分增加了数据来源类型,用于缓存原始图片,避免重复从网络下载。
- 丰富了缓存键的生成规则,以支持缓存多个同一来源但不同规格的图片。
- 巧妙使用策略模式和状态模式,灵活实现不同缓存策略和行为的搭配与切换。
问题三:Bitmap过多分配,容易导致内存抖动
在讲这个问题之前,我们先来简单回顾一下 垃圾回收机制 。
众所周知,我们每一个新对象的创建都需要为其分配内存, ART(Android 运行时)或Dalvik虚拟机会跟踪每次内存分配,一旦确定某块内存不再使用,就会将该内存重新释放到堆中 ,这个过程通常不需要我们干预。
另外,Android的内存堆是分代的, 不同代的对象会被分配到不同的存储分区,分代的标准取决于对象的预期寿命和大小 。
例如,最近分配的对象就属于新生代。而当该对象保持足够长的活跃时间后,就会晋升为老年代,进而成为永久代。
每一代的对象可占用的内存量都有专属上限,一旦填满,系统就会执行垃圾回收以释放内存。
垃圾回收的持续时间,通常取决于其回收的是哪一代的对象,以及对象有多少个。
这个过程通常很快,一般不会影响到应用的性能。但如果操作不当,比如在for循环里面创建了大量的临时对象,或者在onDraw方法里有创建Bitmap对象的动作,都将快速消耗掉新生代存储区域的所有可用内存,迫使 垃圾回收事件被频繁触发 ,或 持续时间超过正常范围 ,进而导致 应用中的代码执行超过屏幕刷新的16ms阈值,引起应用明显的卡顿、掉帧 。
要解决这个问题,除了利用一些内存分析工具如 Profiler 来定位出代码中内存抖动较高的位置,进而改进不合理的代码实现外,另一个有效措施就是: 对象重用 。
对象重用需要用到 对象池 。对象池的好处就是,当我们不再需要某个对象的实例时,我们可以把它放到池子中,而不是像以前一样直接丢弃;而当我们下次再需要使用相同类型的对象实例时,就可以从对象池中获取,而不是重新创建并分配内存。
Android的建议
BitmapFactory.Options
解码选项类的
inBitmap
属性就为Bitmap的重用提供了可能,正确地设置该属性,可以
避免Bitmap内存的重新分配与释放
,从而提高性能。
该属性接收一个
可重用的Bitmap对象
作为参数,然后在解码时会尝试重用该Bitmap对象,如果该Bitmap对象不可用,则将抛出
IllegalArgumentException
异常。
这种做法要求该可重用Bitmap对象是
可变的
(
mutable
,通过
BitmapFactory.Options.inMutable
指定),并且由此解码产生的新Bitmap对象也将保持是可变的。
不过,
inBitmap
的使用存在版本差异。在
Android 4.4(API 级别 19)
之前,仅支持传递大小相同的Bitmap,并且
inSampleSize
值必须为1。在那之后,只需要
新Bitmap的字节数小于可重用Bitmap的字节数
即可。
以下是Android官方提供的实例,演示了如何利用
inBitmap
属性实现Bitmap的重用:
首先,当Bitmap由于各种各样的原因从
LruCache
被移除后,将以软引用形式将放到HashSet中以供后续重用:
var reusableBitmaps: MutableSet<SoftReference<Bitmap>>? = null
private lateinit var memoryCache: LruCache<String, BitmapDrawable>
if (Utils.hasHoneycomb()) {
reusableBitmaps = Collections.synchronizedSet(HashSet<SoftReference<Bitmap>>())
memoryCache = object : LruCache<String, BitmapDrawable>(cacheParams.memCacheSize) {
override fun entryRemoved(
evicted: Boolean,
key: String,
oldValue: BitmapDrawable,
newValue: BitmapDrawable
if (oldValue is RecyclingBitmapDrawable) {
oldValue.setIsCached(false)
} else {
if (Utils.hasHoneycomb()) {
reusableBitmaps?.add(SoftReference(oldValue.bitmap))
}
接着,当我们需要解码一个新的Bitmap时,遍历HashSet检查是否有可重用的Bitmap,如果有,将该Bitmap设为
inBitmap
属性的值:
fun decodeSampledBitmapFromFile(
filename: String,
reqWidth: Int,
reqHeight: Int,
cache: ImageCache
): Bitmap {
val options: BitmapFactory.Options = BitmapFactory.Options()
BitmapFactory.decodeFile(filename, options)
if (Utils.hasHoneycomb()) {
addInBitmapOptions(options, cache)
return BitmapFactory.decodeFile(filename, options)
}检查的过程根据不同的系统版本有所差异:
private fun canUseForInBitmap(candidate: Bitmap, targetOptions: BitmapFactory.Options): Boolean {
return if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) {
val width: Int = targetOptions.outWidth / targetOptions.inSampleSize
val height: Int = targetOptions.outHeight / targetOptions.inSampleSize
val byteCount: Int = width * height * getBytesPerPixel(candidate.config)
byteCount <= candidate.allocationByteCount
} else {
candidate.width == targetOptions.outWidth
&& candidate.height == targetOptions.outHeight
&& targetOptions.inSampleSize == 1
private fun getBytesPerPixel(config: Bitmap.Config): Int {
return when (config) {
Bitmap.Config.ARGB_8888 -> 4
Bitmap.Config.RGB_565, Bitmap.Config.ARGB_4444 -> 2
Bitmap.Config.ALPHA_8 -> 1
else -> 1
}Glide的优化
Glide
为实现
Bitmap
的
池化
专门设计了一系列的类与接口,整理如下:
-
BitmapPool是一个接口,定义了一套与Bitmap对象池重用相关的接口方法。 -
LRUBitmapPool是BitmapPool的一个实现类,结合LruPoolStrategy接口共同实现了LRU清除策略,以使Bitmap对象池的对象数量保持在指定的最大限制之下。 -
LruPoolStrategy是为了适配inBitmap属性在不同Android系统版本的使用差异而设计的策略接口。 -
AttributeStrategy是适用于Android 4.4(API 级别 19)之前的Bitmap重用策略,它要求返回的Bitmap的尺寸必须与请求的尺寸完全匹配。 -
SizeConfigStrategy是适用于Android 4.4(API 级别 19)之后的Bitmap重用策略,它会综合考虑Bitmap.Config的设置以及Bitmap的实际分配字节数,以使我们能安全地重用更多的Bitmap对象,增加Bitmap对象池的命中率,从而提高了程序的性能。
一个对象池的核心方法,无非就是用来
存对象
的
put
方法,与用来
取对象
的
get
方法,我们就从这两个方法入手源码的阅读,来一起探究Glide所设计的Bitmap对象池的精妙之处吧~
先从
LruBitmapPool
的
put
方法开始:
@Override
public synchronized void put(Bitmap bitmap) {
final int size = strategy.getSize(bitmap);
strategy.put(bitmap);
}
可以看到,其
put
方法实际交由了
LruPoolStrategy
接口处理,这里我们只关注其针对高版本的策略实现类——
SizeConfigStrategy
类的
put
方法的内部实现:
private final GroupedLinkedMap<Key, Bitmap> groupedMap = new GroupedLinkedMap<>();
@Override
public void put(Bitmap bitmap) {
int size = Util.getBitmapByteSize(bitmap);
Key key = keyPool.get(size, bitmap.getConfig());
groupedMap.put(key, bitmap);
}
SizeConfigStrategy
类的
put
方法的内部实现很简单,仅仅是根据
BitmapFactory.Config
的配置以及Bitmap的字节大小生成了一个
键
,然后以
键值对
的形式存入
GroupedLinkedMap
之中而已。
GroupedLinkedMap
是Glide内部自定义的一个
容器类
,与有序访问的
LinkedHashMap
有点类似,不同的是它是
按每次多个Bitmap为一组访问的
,而不是按每次单个对象访问的。
这样说还是有点抽象,看一下下面的图就明白了:
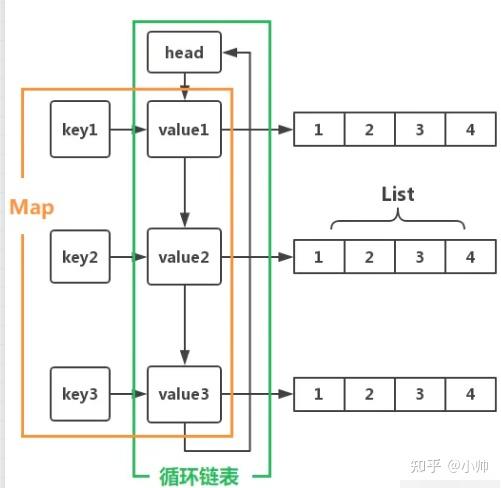

其内部共包含三种数据结构: 哈希表(HashMap) 、 循环链表 以及 列表(ArrayList)
- 哈希表的加入是为了 能快速检索到对应的值 。
- 循环链表的加入是为了 实现LRU清除策略算法 。
- 列表的加入是为了 保存匹配同一个键的多个Bitmap对象 。
第3项应该不难理解,既然是有一定数量规模的对象池,那么符合相同条件的Bitmap对象肯定不止一个。这样设计还有一个好处,就是当我们要减少缓存大小时,可以 批量移除最近最少使用的、符合相同条件的多个Bitmap对象 ,效率更高。
再来看
LruBitmapPool
的
get
方法:
@Override
@NonNull
public Bitmap get(int width, int height, Bitmap.Config config) {
Bitmap result = getDirtyOrNull(width, height, config);
return result;
}@Nullable
private synchronized Bitmap getDirtyOrNull(
int width, int height, @Nullable Bitmap.Config config) {
final Bitmap result = strategy.get(width, height, config != null ? config : DEFAULT_CONFIG);
return result;
}
同样,我们只关注
SizeConfigStrategy
类的
get
方法的内部实现:
public Bitmap get(int width, int height, Bitmap.Config config) {
int size = Util.getBitmapByteSize(width, height, config);
Key bestKey = findBestKey(size, config);
Bitmap result = groupedMap.get(bestKey);
return result;
}
相比起如何根据
键
从
GroupedLinkedMap
容器中检索到对应的
值
,如何借助
findBestKey
方法找到
最佳匹配的键
其实更为核心。
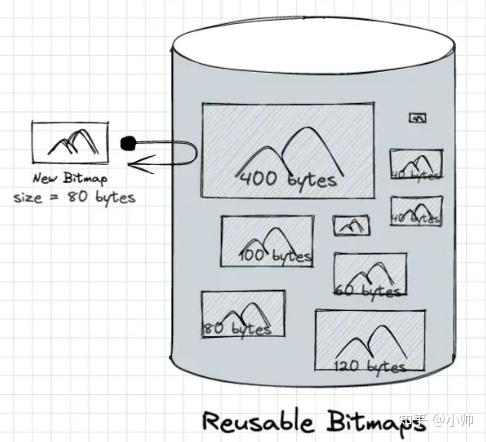
为什么这么说呢?这就得拿出Android提供的示例来进行比较了。
回顾一下前文Android提供的示例,是在Bitmap从内存缓存移除后,以软引用形式将放到HashSet中,然后在需要解码一个新的Bitmap时, 遍历HashSet检查是否有可重用的Bitmap 。
检查的条件,是只要 新Bitmap的字节数小于可重用Bitmap的字节数 即可。
这种方式乍看之下没有什么问题,但一方面,遍历的方式效率较低,另一方面,检查的条件太过简陋, 如果新Bitmap与可重用Bitmap的字节数差异过大,对于内存其实也是一种浪费 。

相比之下,Glide的处理方式则更为合理一点,
findBestKey
方法所谓的找到
最佳匹配的键
,其内部实际是这样子实现的:
private final Map<Bitmap.Config, NavigableMap<Integer, Integer>> sortedSizes = new HashMap<>();
private Key findBestKey(int size, Bitmap.Config config) {
Key result = keyPool.get(size, config);
for (Bitmap.Config possibleConfig : getInConfigs(config)) {
// 1.获取对应Bitmap.Config下的已排序的Bitmap大小集合
NavigableMap<Integer, Integer> sizesForPossibleConfig = getSizesForConfig(possibleConfig);
// 2.返回大于或等于指定Bitmap大小的最小Bitmap大小
Integer possibleSize = sizesForPossibleConfig.ceilingKey(size);
if (...) {
if (...) {
result = keyPool.get(possibleSize, possibleConfig);
break;
return result;
private NavigableMap<Integer, Integer> getSizesForConfig(Bitmap.Config config) {
NavigableMap<Integer, Integer> sizes = sortedSizes.get(config);
if (sizes == null) {
sizes = new TreeMap<>();
sortedSizes.put(config, sizes);
return sizes;
}
注释2听着有点绕口,其实就是
返回一个稍大一点的Bitmap大小
,主要依赖的就是
TreeMap
这个数据结构。
TreeMap
这里不展开讲,否则篇幅承受不住,这里我们只需要知道它有
在内部会对Key进行排序
这个特点就好。也是基于这个特点,我们才能使用其内部方法
ceilingKey(K key)
返回大于或等于给定键的最小键。
TreeMap
的对象添加发生在
SizeConfigStrategy
类的
put
方法,其键是
某个数值的Bitmap大小
,值是
该大小的Bitmap对象在池中的数量
:
@Override
public void put(Bitmap bitmap) {
NavigableMap<Integer, Integer> sizes = getSizesForConfig(bitmap.getConfig());
Integer current = sizes.get(key.size);
sizes.put(key.size, current == null ? 1 : current + 1);
}
综上,
findBestKey
方法
查找最佳的键
的流程可以用以下示意图表示:
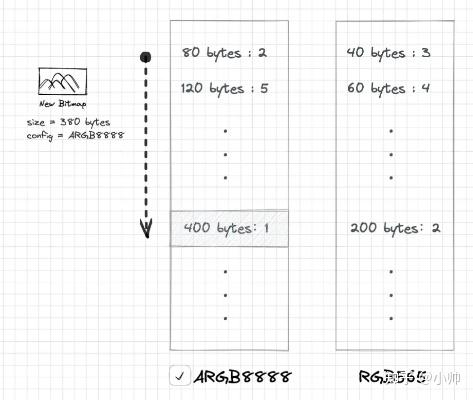

最后一个问题,前面我们讲过,当通过
inBitmap
属性指定的可重用Bitmap对象不可用时,系统将抛出
IllegalArgumentException
异常,对此,Glide又是如何解决的呢?
答案就在
Downsampler
类的
decodeStream
方法中:
private static Bitmap decodeStream(InputStream is, BitmapFactory.Options options,
try {
result = BitmapFactory.decodeStream(is, null, options);
} catch (IllegalArgumentException e) {
if (options.inBitmap != null) {
try {
is.reset();
bitmapPool.put(options.inBitmap);
options.inBitmap = null;
return decodeStream(is, options, callbacks, bitmapPool);
} catch (IOException resetException) {
throw bitmapAssertionException;
throw bitmapAssertionException;
} finally {