


写了不到礼拜的Flink,Team Leader竟然让滚蛋回家了!!!

小叶同学,用了2个月时间,顺利完成实时处理的华丽转型。靠着对各种原理、机制倒背如流,成功拿到了一个大厂的offer。但还没有熬过一个礼拜,面试官把小叶叫到办公室,非常严肃地说,你这写的也配叫代码?用一堆operator组合放在一个类里,然后把功能就做出来了?你做过单元测试吗?你有工程化思维吗?太差劲了,明天就去人事办理离职吧。
小叶一脸茫然….我功能实现出来了啊,为啥会这样?….
单元测试的重要性
单元测试是一种软件测试方法,就是对软件中的“单元”进行测试,很多时候,拿Java来说,其实很多时候,就是对我们编写的方法进行测试。而单元测试一般都是Dev来写的,好的Dev基本上没有单元测试的,通过单元测试,来确保我们的代码能够正常工作。
小猴在13年的时候,开始尝试测试驱动开发(TDD),就是先编写测试用例,然后再编写代码。这种骚操作是与传统的开发模式反着来的,先根据需求把测试用例写出来,然后再开发代码,确保代码能够顺利通过测试。其实大家去刷OJ,也有点这个意思。OJ很多都是把题目需求给出来,然后给定输入、输出,我们再编写代码通过测试。这种开发模式刚开始会非常不适应,因为打破了我们以前固有的思维模式。根据我的经验,大家可以先从小粒度的TDD开始,开始设计一个模块之前,用TDD,先把test case写好,写好输入、写好断言、然后开发代码。这种方式可行,而且效率比较高。它可以保证我们的代码质量,不至于被diss得太狠。
那说一下单元测试的几个优势吧:
1、可以让我们更容易排错
搞测试的都知道有覆盖率一说,如果一些代码都没有被测试过,那么出错的概率将会大大提高。我们有了测试用例,可以让测试覆盖更多的源程序。而且将来,如果对代码做了调整,我们把测试用例拿出来溜溜,就知道这些更改是否影响了程序本身的预期行为。单元程序可以更容易帮助dev发现问题,用更少的资源来查找错误。
2、省时省力省钱
技术哲学里,越早暴露错误越好。能在编译之前就发现错误,多好~所以,我们都会在IDE中写程序,装X党喜欢在notepad里写代码,其实那都是给小白做做show而已。然后就是编译时、再下来就是运行时、…最最难受地就是在product上出现错误。代价相当昂贵。很多先人都为此交了巨额学费。
3、能够快速运行的单元测试有时候比文档更有效
很多dev是不愿意写代码的,但好的测试用例,能够快速地告诉我们一个模块提供了什么样的功能。通过单元测试,我们可以快速摸清楚整个系统的基本情况。
4、增加可重用性
写单元测试时,各个模块都是彼此隔离的,代码如果能够在单元测试环境中使用良好,就表示代码的可重用性是比较高的。
Flink Streaming单元测试
我发现了,不管是写MapReduce、Spark、还是Flink,有很多dev都没有编写单元测试用例的习惯(应该是很大一部分,尤其是在一些乡镇企业做开发的程序员)。
但不管你写的是什么样的程序,这些开发的方法论是必须要懂的。细节决定成败!
编写具备测试能力的Flink程序
我们在开发过程中,不能光以实现为目标,还要考虑测试。新手程序员,大多数都是上来就开始写大段的代码,然后把项目跑起来一看,我去~出错了。然后就开始手忙脚乱地改各种bug。而有经验的程序员,往往会考虑程序的可测试性,而且有一个良好地习惯——编写测试用例。我们写Flink程序的时候,也应该养成编写测试用例的习惯,一个是它可以确保我们的程序具备一定的可靠性、容错性,再来就是将来当我们对代码做调整的时间也能够快速验证程序的行为。
接下来,为了方便演示,我们编写一个示例程序,然后,我们用Flink对测试的支持,来测试我们的代码。
这个Flink程序做的处理很简单,就是实现单词计数。首先我们自定义一个source不断地发出文本,然后我们编写代码进行处理解析,最后用滚动窗口每5秒进行一次计算,并放到有状态的存储中。我们先把程序快速地实现出来。
要实现这个程序很简单,可能就是几个lambda表达式一组合就实现好了。但,企业开发不会是这样的。所以,我用一个简单的例子来构建一个比较容易演示单元测试的环境。代码结构如下:
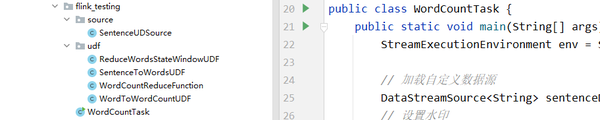

1、先把pom.xml导进来。
<properties>
<flink-version>1.12.0</flink-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala-version}</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala-version}</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
<testSource>1.8</testSource>
<testTarget>1.8</testTarget>
</configuration>
</plugin>
</plugins>
</build>
2、构建一个不断发送句子的source。
public class SentenceUDSource extends
RichSourceFunction<String> {
private volatile Boolean isCanceled;
private Random random;
private static final String[] SENTENCE = {
"The cat stretched"
, "Jacob stood on his tiptoes"
, "The car turned the corner"
, "Kelly twirled in circles"
, "She opened the door"
, "Aaron made a picture"
, "I am sorry"
, "I danced"
@Override
public void open(Configuration parameters) throws Exception {
this.isCanceled = false;
this.random = new Random();
@Override
public void run(SourceContext ctx) throws Exception {
while(!isCanceled) {
int ramdomIndex = random.nextInt(SENTENCE.length);
ctx.collect(SENTENCE[ramdomIndex]);
TimeUnit.MILLISECONDS.sleep(500);
@Override
public void cancel() {
this.isCanceled = true;
3、实现一个将句子切分为单词的UDF。
/**
* 将句子转换为单词
public class SentenceToWordsUDF extends RichFlatMapFunction<String, String> {
private Logger logger = LoggerFactory.getLogger(SentenceToWordsUDF.class);
@Override
public void flatMap(String sentence, Collector<String> out) {
// 将单词用空格切分
if(!StringUtils.isEmpty(sentence)) {
String[] words = sentence.split(" ");
if(words != null && words.length > 0) {
for (String word : words) {
// 继续判断单词是否为空
if(StringUtils.isNotEmpty(word)) {
out.collect(word);
else {
logger.warn("Word is empty!");
else {
logger.error("The sentence is invalid!\nThe sentence is:" + sentence);
else {
logger.warn("Sentence is empty!");
}4、实现一个将单词转换为元组的UDF
/**
* 将单词转换为元组
public class WordToWordCountUDF extends RichMapFunction<String, Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> map(String word) {
Tuple2<String, Integer> wordCount = Tuple2.of(word, 1);
return wordCount;
5、实现一个用ReducingState的ProcessWindowFunction,基于窗口进行计数统计
/**
* window处理UDF
* 对单词进行聚合计算,并将计算结果保存在State中
public class ReduceWordsStateWindowUDF extends ProcessWindowFunction<
Tuple2<String, Integer>
, Tuple2<String, Integer>
, String
, TimeWindow> {
private Logger logger = LoggerFactory.getLogger(ReduceWordsStateWindowUDF.class);
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 用于保存单词计算结果的状态
private ReducingState<Tuple2<String, Integer>> reducingState;
@Override
public void open(Configuration parameters) throws Exception {
// 创建一个state的description
ReducingStateDescriptor<Tuple2<String, Integer>> reducingStateDes = new ReducingStateDescriptor<>("wordcount"
, new WordCountReduceFunction()
, TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
reducingState = getRuntimeContext().getReducingState(reducingStateDes);
@Override
public void process(String s
, Context context
, Iterable<Tuple2<String, Integer>> elements
, Collector<Tuple2<String, Integer>> out) {
// 打印window的计算时间
TimeWindow window = context.window();
logger.info(sdf.format(window.getEnd()) + " window触发计算!");
elements.forEach(t -> {
try {
if(reducingState != null) {
// 将单词直接放入到状态中即可
reducingState.add(t);
// 将结果继续输出到下游
out.collect(reducingState.get());
} catch (Exception e) {
logger.error("add wordcount tuple to reducing state error!", e);
6、给ReducingState提供一个reduce的实现
/**
* 实现ReducingState中单词聚合计算
public class WordCountReduceFunction implements ReduceFunction<Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}7、终于到了最后一步,组装pipeline。
public class
WordCountTask {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 加载自定义数据源
DataStreamSource<String> sentenceDataSource = env.addSource(new SentenceUDSource());
// 设置水印
SingleOutputStreamOperator<String> sentenceWithWatermarkStream =
sentenceDataSource.assignTimestampsAndWatermarks(WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((word, ts) -> System.currentTimeMillis()));
// 将句子分隔为单词
SingleOutputStreamOperator<String> wordsDataStream = sentenceWithWatermarkStream.flatMap(new SentenceToWordsUDF());
// 将单词转换为元组
SingleOutputStreamOperator<Tuple2<String, Integer>> wordCountDataStream = wordsDataStream.map(new WordToWordCountUDF());
// 按照单词进行分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordCountDataStream.keyBy(t -> t.f0);
// 5秒滚动时间窗口
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> tumblingWindowedStream =
keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5)));
// 用状态进行聚合计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream =
tumblingWindowedStream.process(new ReduceWordsStateWindowUDF());
// 打印sink输出
resultDataStream.print();
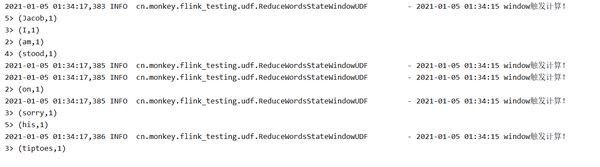
env.execute("WordCount for Unit Testing!");
运行一下,程序能够正常输出:

测试无状态、无时间的UDF
其实,我们写复杂地流处理程序时,不会这么地顺利,所以,在我们每写一个Stream UDF的时候,我们都应该先写写测试。好了!接下来,给大家看看如何写Flink的测试用例,此处,我们用JUnit4来进行单元测试。
1、把Junit Maven依赖导入进来
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>2、测试一下单词转元组的UDF。直接在test目录中编写测试用例即可。非常简单!
public class WordToWordCountUDFTest {
@Test
public void map() {
WordToWordCountUDF wordToWordCountUDF = new WordToWordCountUDF();
assertEquals(Tuple2.of("hadoop", 1), wordToWordCountUDF.map("hadoop"));
}如果发现和预期有差别,就会报错了。
java.lang.AssertionError:
Expected :(hadoop1,1)
Actual :(hadoop,1)
<Click to see difference>测试用到collector的UDF
接下来,我们来测试一个SentenceToWordsUDF这个类。这个类就有点麻烦了。我们发现这个函数有一个Runtime的依赖,就是需要一个Collector。
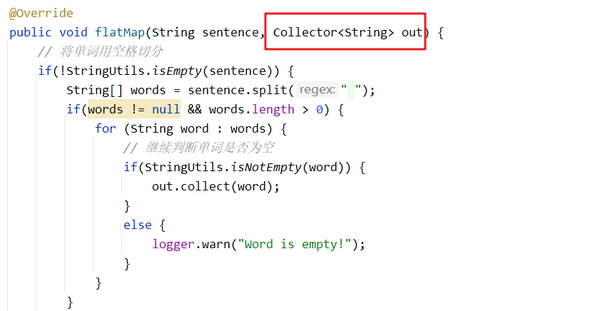

怎么办呢?
我们需要使用mockito来完成测试了。先把mockito的依赖导入进来。
<!-- 引入mock -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>2.7.22</version>
<scope>test</scope>
</dependency>
public class SentenceToWordsUDFTest {
@Test
public void flatMap() {
SentenceToWordsUDF sentenceToWordsUDF = new SentenceToWordsUDF();
// 使用Mockito mock一个Collector对象
Collector collector = Mockito.mock(Collector.class);
sentenceToWordsUDF.flatMap("hadoop spark hello", collector);
// 因为此处flatMap UDF会输出3次,所以我们用Mockito verify三次,验证每次收集到的单词
Mockito.verify(collector, Mockito.times(1)).collect("hadoop");
Mockito.verify(collector, Mockito.times(1)).collect("spark");
Mockito.verify(collector, Mockito.times(1)).collect("hello");
}
大家发现没,我用一个mock调用就完成了Collector的模拟,然后用Mockito的verify实现输出结果的校验。Nice!
注意:我们编写代码的时候,也应该尽量隔离Runtime,尽量避免不必要的麻烦。
测试有状态、有时间的UDF
接下来我们要来测试ProcessWindow UDF,这个就有难度了,我们前面看到了这个UDF中涉及了watermark、window、state。而因为状态、时间都是Flink Runtime相关。这给测试增加了难度。所以,Flink为了支持这种Runtime的测试,专门准备了一个库来进行测试。就是这个flink-test-utils,除此之外,我们还需要将Flink的runtime库导入进来。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-test-utils_2.11</artifactId>
<version>1.12.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime_2.11</artifactId>
<version>1.12.0</version>
<scope>test</scope>
<classifier>tests</classifier>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.12.0</version>
<scope>test</scope>
<classifier>tests</classifier>
</dependency>
我们使用这个库里面的这些类来进行测试。
- 专门用于给DataStream测试的类:OneInputStreamOperatorTestHarness
- 专门用于给KeyedStreams 测试的类:KeyedOneInputStreamOperatorTestHarness
- 专门用于给两个连接的DataStream测试的类:TwoInputStreamOperatorTestHarness
- 专门用于给两个连接的KeyedStream测试的类:KeyedTwoInputStreamOperatorTestHarness
有了这些类,我们就可以开始测试带有Flink Runtime的UDF了。这些类的使用步骤如下:
一、准备测试环境
1、构建被测使用到了状态、时间的UDF
2、构建指定StreamOperatorTestHarness对象
3、设置StreamOperatorTestHarness参数,类似于设置StreamExecutionEnvironment参数一样,例如:我们可以设置周期性水印的时间间隔
4、调用TestHarness对象的open方法(open方法会自动调用我们的open方法实现)
二、编写测试用例
1、在测试用例中调用processElement发射数据
2、调用processWatermark发送一个watermark
3、调用getOutput来获取结果
4、将预期的结果保存下来,与输出结果进行断言
听起来是不是很简单?但大家看看下面的代码。
我们来用上述方法来测试ReduceWordsStateWindowUDF类。
public class ReduceWordsStateWindowUDFTest {
private KeyedOneInputStreamOperatorTestHarness<String, Tuple2<String, Integer>, Tuple2<String, Integer>> testHarness;
private static class TupleKeySelector implements KeySelector<Tuple2<String, Integer>, String> {
private static final long serialVersionUID = 1L;
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
@Before
public void setupTestHarness() throws Exception {
// 1、构建被测使用到了状态、时间的UDF
ReduceWordsStateWindowUDF reduceWordsStateWindowUDF = new ReduceWordsStateWindowUDF();
// 2. 创建一个WindowState Description
ReducingStateDescriptor<Tuple2<String, Integer>> stateDesc = new ReducingStateDescriptor<>(
"window-contents"
, new WordCountReduceFunction()
, TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}).createSerializer(new ExecutionConfig()));
WindowOperator<String
, Tuple2<String, Integer>
, Tuple2<String, Integer>
, Tuple2<String, Integer>
, TimeWindow> operator =
new WindowOperator<>(
TumblingEventTimeWindows.of(Time.seconds(5))
, new TimeWindow.Serializer()
, new TupleKeySelector()
, BasicTypeInfo.STRING_TYPE_INFO.createSerializer(new ExecutionConfig())
, stateDesc
, new InternalSingleValueProcessWindowFunction<
Tuple2<String, Integer>
, Tuple2<String, Integer>
, String
, TimeWindow>(reduceWordsStateWindowUDF)
, EventTimeTrigger.create()
, null);
testHarness = new KeyedOneInputStreamOperatorTestHarness<>(operator
, new TupleKeySelector()
, BasicTypeInfo.STRING_TYPE_INFO);
// 4、调用TestHarness对象的open方法(open方法会自动调用我们的open方法实现)
testHarness.open();
@Test
public void process() throws Exception {
// 存储期望输出
ConcurrentLinkedQueue<Object> expectedOutput = new ConcurrentLinkedQueue<>();
// 用testHarness emit几个数据
testHarness.processElement(Tuple2.of("hadoop", 1), 1000);
testHarness.processElement(Tuple2.of("spark", 1), 1500);
testHarness.processElement(Tuple2.of("hadoop", 1), 2000);
testHarness.processElement(Tuple2.of("hadoop", 1), 4999);
testHarness.processWatermark(new Watermark(4999));
expectedOutput.add(new StreamRecord<>(Tuple2.of("hadoop", 3), 4999));
expectedOutput.add(new StreamRecord<>(Tuple2.of("spark", 1), 4999));
// 因为window还会把watermark继续发送到下游,所以watermark也要添加进来
expectedOutput.add(new Watermark(4999));
// 校验结果
TestHarnessUtil.assertOutputEqualsSorted("window计算错误", expectedOutput, testHarness.getOutput(), new Tuple2ResultSortComparator());
private static class Tuple2ResultSortComparator implements Comparator<Object>, Serializable {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Watermark || o2 instanceof Watermark) {
return 0;
} else {
StreamRecord<Tuple2<String, Integer>> sr0 = (StreamRecord<Tuple2<String, Integer>>) o1;
StreamRecord<Tuple2<String, Integer>> sr1 = (StreamRecord<Tuple2<String, Integer>>) o2;
if (sr0.getTimestamp() != sr1.getTimestamp()) {
return (int) (sr0.getTimestamp() - sr1.getTimestamp());
int comparison = sr0.getValue().f0.compareTo(sr1.getValue().f0);
if (comparison != 0) {
return comparison;
} else {
return sr0.
getValue().f1 - sr1.getValue().f1;
}

因为这里要模拟window的behavior,所以,得模拟一个WindowOpertor来模拟窗口。解释下关键的几个部分代码:
1、因为我们当前是对一个单流KeyedStream进行测试,所以先要构建一个TestHarness。
testHarness = new KeyedOneInputStreamOperatorTestHarness<>(operator
, new TupleKeySelector()
, BasicTypeInfo.STRING_TYPE_INFO);
2、而关键就在于这个operator,我们是基于window来进行操作的。所以要构建一个WindowOperator。
我先把被测的带window操作的UDF对象构建出来。
// 1、构建被测使用到了状态、时间的UDF
ReduceWordsStateWindowUDF reduceWordsStateWindowUDF = new ReduceWordsStateWindowUDF();
此处,我们用的是ReducingState进行单词计数,所以,按照我们的使用方式把Description构建出来。
// 2. 创建一个WindowState Description
ReducingStateDescriptor<Tuple2<String, Integer>> stateDesc = new ReducingStateDescriptor<>(
"window-contents"
, new WordCountReduceFunction()
, TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}).createSerializer(new ExecutionConfig()));
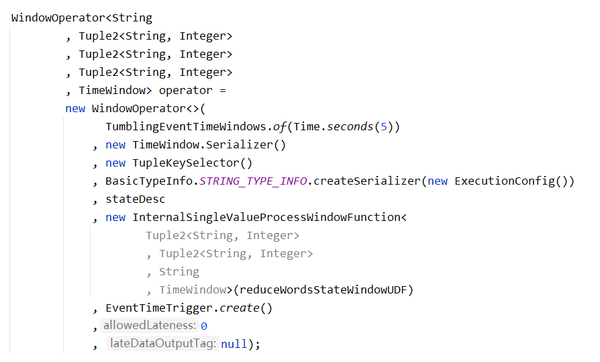
接下来这段代码我从WindowOperator的泛型说起,然后再介绍构建WindowOperator的参数。
WindowOperator<String
, Tuple2<String, Integer>
, Tuple2<String, Integer>
, Tuple2<String, Integer>
, TimeWindow> operator =
new WindowOperator<>(
TumblingEventTimeWindows.of(Time.seconds(5))
, new TimeWindow.Serializer()
, new TupleKeySelector()
, BasicTypeInfo.STRING_TYPE_INFO.createSerializer(new ExecutionConfig())
, stateDesc
, new InternalSingleValueProcessWindowFunction<
Tuple2<String, Integer>
, Tuple2<String, Integer>
, String
, TimeWindow>(reduceWordsStateWindowUDF)
, EventTimeTrigger.create()
, null);关联一下Flink的源码,你会发现WindowOperator的泛型有4个参数。大家看Flink的缩写非常简洁,一看就知道啥意思了。K – key,表示KeyedStream中进行分流的key类型,我们这里是String。IN – 表示输入的类型,我们将单词转换为元组,所以此处是Tuple2<String, Integer>。文档漏了一个ACC - accumulator,这是累加的意思,就是Tuple2 + Tuple2的类型,我们这儿还是Tuple2。再下来是OUT – 表示输出的类型,仍然是Tuple2。最后一个W – Window的缩写,我们这里是滚动时间窗口,所以是TimeWindow。


类型分析完了,接下来分析它的构造器参数。
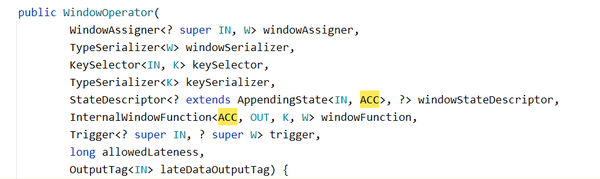

(对window不熟悉的同学,可以看一下我之前写的一篇关于window的文章:
第一个参数是窗口分配器,我们这里使用的是滚动窗口TumblingEventTimeWindows.of(Time.seconds(5)),所以直接把滚动窗口传进去,它实现了这个抽象类。
第二个参数是窗口序列化器,窗口是一个对象,里面保存了开始时间、结束时间。我们直接用时间窗口的序列化器即可new TimeWindow.Serializer()。
第三个参数是KeyedSelector,这个就是从输入中选择key的逻辑。直接复用:new TupleKeySelector()
第四个参数是Key类型的序列化器,我们这里使用的是String类型,所以直接使用使用Flink提供的String类型序列化器即可。BasicTypeInfo.STRING_TYPE_INFO.createSerializer(new ExecutionConfig())
第五个参数是window所使用的StateDescriptor,把我们之前构建的对象传进来。
关键的来了,第六个参数是InternalWindowFunction,这是一个接口,它有以下实现。
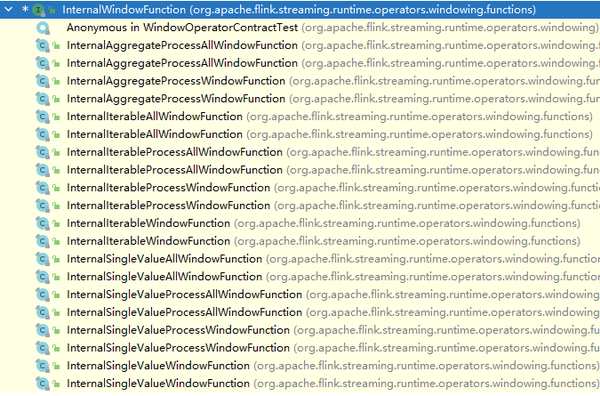

而我们需要的就是SingleValueProcessWindowFunction。我们用它来将我们自己的实现wrap下。就是这样,
new InternalSingleValueProcessWindowFunction<
Tuple2<String, Integer>
, Tuple2<String, Integer>
, String
, TimeWindow>(reduceWordsStateWindowUDF)
第七个参数是指定一个trigger,我们直接使用Eventtime的trigger即可,即EventTimeTrigger.create()。
第八个参数是是否允许延迟事件,我们此处设置为0,不延迟。
终于到了最后一个,第九个参数是side output(旁路输出流)的tag,我们这儿并没有对延迟的数据流进行额外处理,设置为null即可。
3、构建好了operator后,我们就可以构建TestHarness了。
testHarness = new KeyedOneInputStreamOperatorTestHarness<>(operator
, new TupleKeySelector()
, BasicTypeInfo.STRING_TYPE_INFO);
4、调用一下TestHarness的open,这样它会自动调用我们在UDF中实现的open方法。
5、然后我们就开始设计我们的测试用例了。
我们先构建一个Queue,专门用来保存我们期望的输出结果的。
ConcurrentLinkedQueue<Object> expectedOutput = new ConcurrentLinkedQueue<>();
然后我们用TestHarness.processElement emit了4个数据。
// 用testHarness emit几个数据
testHarness.processElement(Tuple2.of("hadoop", 1), 1000);
testHarness.processElement(Tuple2.of("spark", 1), 1500);
testHarness.processElement(Tuple2.of("hadoop", 1), 2000);
testHarness.processElement(Tuple2.of("hadoop", 1), 4999);
接下来,emit一个触发计算的watermark。注意,我这里emit的时间是4999,因为我们的窗口是5秒(5000毫秒)长度,而窗口触发计算会在4999时开始触发,所以但4999的watermark来了之后,窗口就会trigge计算了。
紧接着,我们把我们的断言加到前面我们创建的queue中。
expectedOutput.add(new StreamRecord<>(Tuple2.of("hadoop", 3), 4999));
expectedOutput.add(new StreamRecord<>(Tuple2.of("spark", 1), 4999));
// 因为window还会把watermark继续发送到下游,所以watermark也要添加进来
expectedOutput.add(new Watermark(4999));
最后一步:
TestHarnessUtil.assertOutputEqualsSorted("window计算错误", expectedOutput, testHarness.getOutput(), new Tuple2ResultSortComparator());
我们需要来对比值是否相等,所以,我们需要一个结果比较器。
private static class Tuple2ResultSortComparator implements Comparator<Object>, Serializable {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Watermark || o2 instanceof Watermark) {
return 0;
} else {
StreamRecord<Tuple2<String, Integer>> sr0 = (StreamRecord<Tuple2<String, Integer>>) o1;
StreamRecord<Tuple2<String, Integer>> sr1 = (StreamRecord<Tuple2<String, Integer>>) o2;
if (sr0.getTimestamp() != sr1.getTimestamp()) {
return (int) (sr0.getTimestamp() - sr1.getTimestamp());
int comparison = sr0.getValue().f0.compareTo(sr1.getValue().f0);
if (comparison != 0) {
return comparison;
} else {