


简述目前AutoML类型与模式

有关AutoML的介绍以及相关原理可以参阅这篇 简述AutoML由来与其应用现状
我将AutoML分为 传统AutoML ,自动调节传统的机器学习算法的参数,比如随机森林,我们来调节它的max_depth, num_trees, criterion等参数。还有一类AutoML,则专注深度学习。这类AutoML,不妨称之为 深度AutoML。 与传统AutoML的差别是,现阶段深度AutoML,会将神经网络的超参数分为两类,一类是与训练有关的超参数,比如learning rate, regularization, momentum等;还有一类超参数,则可以总结为网络结构。对网络结构的超参数自动调节,也叫 Neural architecture search (nas) 。而针对训练的超参数,也就是传统AutoML的自动调节,叫 Hyperparameter optimization (ho) 。
转自 JxKing Blog
“傻瓜式“AutoML
傻瓜式AutoML的概念是面向更广泛用户的自动机器学习,不需要用户对算法,模型,调参有深入理解,只需要输入数据集,之后所有的任务都集成在平台作为一种服务,但往往用户只有调用的权限,且无法得知内部的算法,模型架构以及超参数等。由原始数据输入,到结果输出,从输入端到输出端,中间的神经网络自成一体(也可以当做黑盒子看待),是端到端的。
- Cloud AutoML
谷歌的automl服务有三种
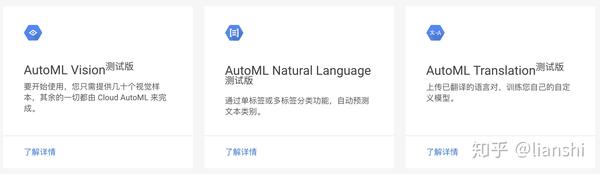

拿AutoML Vision为例,像网页上显示的一样,要开始使用,您只需要提供几十个视觉样本,其余的一切都由Cloud AutoML来完成,我们来看一下是什么流程:
- 将一组图片复制到 Google Cloud Storage 中。
- 创建一个列有图片及其标签的 CSV 文件。
- 使用 AutoML Vision 界面创建数据集,并训练和部署模型。
开始之前
- 登录 您的 Google 帐号。
- 在GCP控制台中,转到“管理资源”页面,然后选择或创建项目。
- 确保您的项目已启用结算功能。
- 启用Cloud AutoML和云存储API.
创建 Cloud Storage 存储分区 :
使用 Cloud Shell(一个连接到 GCP Console 项目的基于浏览器的 Linux 命令行)创建 Cloud Storage 存储分区:
- 打开 Cloud Shell 。
- 输入以下内容:
PROJECT=$(gcloud config get-value project) && BUCKET="${PROJECT}-vcm"3. 创建存储分区:
gsutil mb -p ${PROJECT} -c regional -l us-central1 gs://${BUCKET}4. 为 AutoML Vision 服务帐号添加权限:
允许 AutoML Vision 服务帐号访问您的 Google Cloud 项目资源,在 Cloud Shell 会话中,输入以下内容:
PROJECT=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT \
--member="serviceAccount:custom-vision@appspot.gserviceaccount.com" \
--role="roles/ml.admin"
gcloud projects add-iam-policy-binding $PROJECT \
--member="serviceAccount:custom-vision@appspot.gserviceaccount.com" \
--role="roles/storage.admin"5. 将示例图片复制到存储分区中:
接下来,复制 此 Tensorflow 博文 中使用的花卉数据集。这些图片存储在公开的 Cloud Storage 存储分区中,因此您可以直接将它们从那里复制到您自己的存储分区中,在 Cloud Shell 会话中,输入以下内容:
gsutil -m cp -R gs://cloud-ml-data/img/flower_photos/ gs://${BUCKET}/img/6. 样本数据集包含一个 CSV 文件,其中包含所有图片位置以及每个图片的标签。您将基于这一文件创建您自己的 CSV 文件:
- 更新 CSV 文件,使其指向您自己的存储分区中的文件:
gsutil cat gs://${BUCKET}/img/flower_photos/all_data.csv | sed "s:cloud-ml-data:${BUCKET}:" > all_data.csv- 将 CSV 文件复制到您的存储分区中:
gsutil cp all_data.csv gs://${BUCKET}/csv/创建数据集
访问 AutoML Vision 网站,开始创建数据集和训练模型的过程: http://beta-dot-custom-vision.appspot.com/ 。
出现提示时,请确保选择已用于您的 Cloud Storage 存储分区的项目。
- 在 AutoML Vision 页面中,点击 新建数据集 :

2. 为此数据集指定名称。点击加号 (+) 继续。


3. 指定 CSV 文件的 Cloud Storage URI。在本快速入门中,CSV 文件位于
gs://your-project-123-vcm/csv/all_data.csv
。请确保将
your-project-123
替换为您的具体项目 ID。
4. 点击 创建数据集 。导入过程需要几分钟才能完成。完成后,您将进入下一页,其中包含为数据集识别出的所有图片(包括已标记图片和未标记图片)的详细信息。在 过滤标签 下选择一个标签即可按标签过滤图片。

训练模型
创建数据集并完成相应处理后,点击 训练 标签可启动模型训练。
点击 开始训练 以继续。
系统将针对您的模型启动训练。对于此数据集,训练模型的操作需要大约 10 分钟完成。该服务将在训练完成后或发生任何错误时通过电子邮件通知您。
训练完成后,您的模型将自动进行部署。
点击 评估 标签可详细了解 F1、精确率和召回率分数。点击 过滤标签 下的每个标签可详细了解真正例、假负例和假正例。
进行预测
点击 预测 标签,查看有关如何将图片发送到模型以进行预测的说明。您也可以参阅 查询 AutoML Vision 模型 ,以及 进行预测 中显示的示例。
预测需要调用api接口: 具体的代码等过程戳这里
以下是找到的国内以及国外用户具体项目应用Cloud AutoML的博文:
可惜的是谷歌目前在AutoML Vision中只支持训练图片分类器
- Baidu EasyDL
百度的EasyDL,同样有三种大类的服务:


对比谷歌,百度缺少了文本自动翻译的功能,这可能就是我们平常不用百度翻译,而用谷歌翻译的原因吧,但是百度增加了声音分类,而且在图像识别类型中增加了物体检测的功能,以下是本人对于百度easyDL物体检测功能的使用过程:
1.创建模型

模型就相当于一个空架子,因为百度会帮你用什么模型来train你还不清楚,这个空架子很好建立,重要的是数据集,不过模型名称要与你所实现的功能契合,否则到后面就会忘了。
建立好模型之后会出现这个界面,你可与随时删除你创建的模型


2.创建数据集
点击数据中心的上传即可建立数据集

给你自己的数据集起一个名字,也是要注意命名考究一些,毕竟你不一定要训练一种数据集。
当你创建好数据集之后,出现这个界面


点击标注/上传界面,上传你需要训练的照片
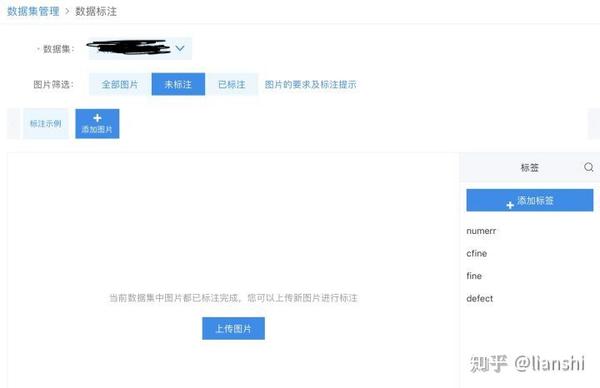

或者你也可以先建立你物体检测的标签,然后点击上传图片上传照片。
3.在图片标注标签
这里请注意,目前百度仅支持利用自己的页面内进行图片标注,自己标注过的图片不行。
利用标签工具框选你要识别的部位,并且在右面选择你的标签
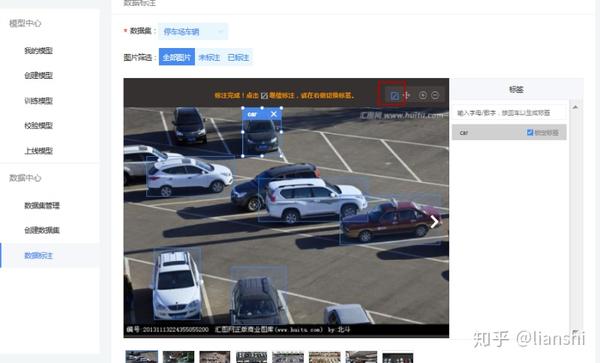

当你把所有数据集的图片标注完成之后便完成了数据集的准备,下一步可以开始训练了。
4.训练模型
接下来可以训练模型了
选择你建立的模型,并点击下面的添加数据集,
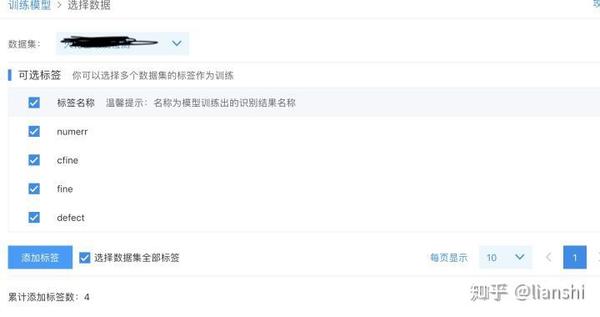

导入你想训练的标签,就可以开始训练了。


点击训练中旁的!可以查看进度,当模型训练完成之后会自动给你的手机发短信。
5.查看并发布模型
模型训练完之后,可以查看模型训练的效果,点击完整评估结果可以查看更细致的评测,比如单独一个标签的识别好坏。


点击发布模型,输入自定义的端口名称,同样取名也考究一些方便自己调用。
发布模型之后,工作人员会人工审核,亲测如果上午发布,一两个小时就会通过审核,如果下午发布,可能就要晚上或者第二天了。
6.调用训练好的模型
如果你的模型发布成功,恭喜你拥有一个可以调用的api接口,调用这个接口会直接链接这个模型。
打开你的IDE
导入必要的库:
import requests
import json
import base64access_token的获取,我们在调用API时需要带上该参数才能顺利地请求服务,下面的代码用来获取Access Token,获取Access Token可以用多种语言来实现,详情参考 百度云文档中心 :
url_token = "https://aip.baidubce.com/oauth/2.0/token"
data_token = {"grant_type":"client_credentials","client_id":"SyxRac9LCYvgALevM8jzIrCH","client_secret":"IZNEomXbYA3LZN2g92iOwNc83xvTGYLE"}
#由于post请求的习惯是在body中放入要传给服务器的数据,因此,这里的post方法采用了data参数,而不是params参数。然而,采用params参数也是可以的
resp = requests.post(url_token,data = data_token)
#resp是一个http响应对象,resp.text则是一个json格式的字符串.json.loads()方法可以将json字符串转为字典。
resp_dict = json.loads(resp.text)
#转为字典之后的好处就是,可以直接从键索引出值,access_token的获取相比用字符串处理要方便得多
access_token = resp_dict["access_token"]
#print(resp_dict["access_token"])请求服务
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=b0Xuhn9sZ6hf2u1YcKBP41ii' \
'&client_secret=jtQqGUrWauLAnwA9wdvMvCmvCTVukPE3'
response = requests.get(host)
content = response.json()
access_token = content["access_token"]
image = open(r'C:\\Users\\pain\\Desktop\\plastic.jpg', 'rb').read()
data = {'image': base64.b64encode(image).decode()}
request_url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/garbageclassification" + "?access_token=" + access_token
response = requests.post(request_url, data=json.dumps(data))
content = response.json()
print(content)
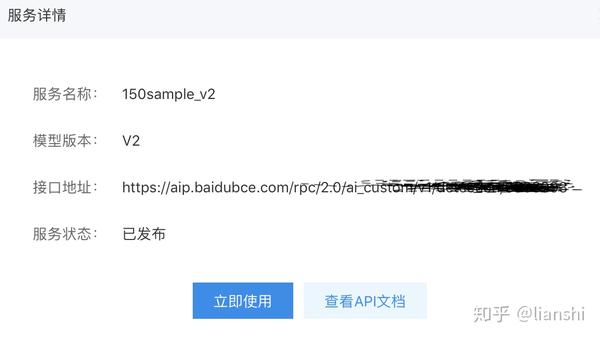

request url 为上图的接口地址
client_id 和client_secret分别为发布模型后应用管理中的API Key与Secret Key
替换代码中的 access token,clientid和client _secret,选择图片,即可输出识别结果:


自动调节参数类
自动调节参数类automl指的是通过平台上的引擎,或者内置搜索算法,帮助用户实现摩模型超参数的自动寻优,但是门槛高于傻瓜式automl,还需要用户进行模型代码的实现,转换输入数据的格式等。并且对超参数有一定了解。一般属于传统机器学习的AutoML
- 阿里云pai
阿里云pai机器学习平台已经发展很久了,在搭建机器学习算法可以调用其中的封装好的模块,且模块的种类很多如下:

宣称搭建机器学习就如同搭积木一般,
不过这种开发平台还是比较常见的,为什么还提到pai呢,原因是其添加了一个自动参数调节引擎:
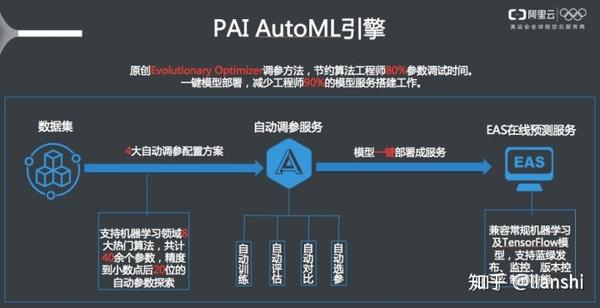

从图中可以看出,阿里云新增的引擎在数据集与模型部署之间,并且支持机器学习领域的8大热门算法,共计40余个算法的自动参数搜索。
也就是说,平台所做的automl是用户在明确自己使用模型,并且建立好模型的基础上,pai平台训练的时候,可以进行自动参数选择。
下面是官方给出的自动调参的简介:
调参配置
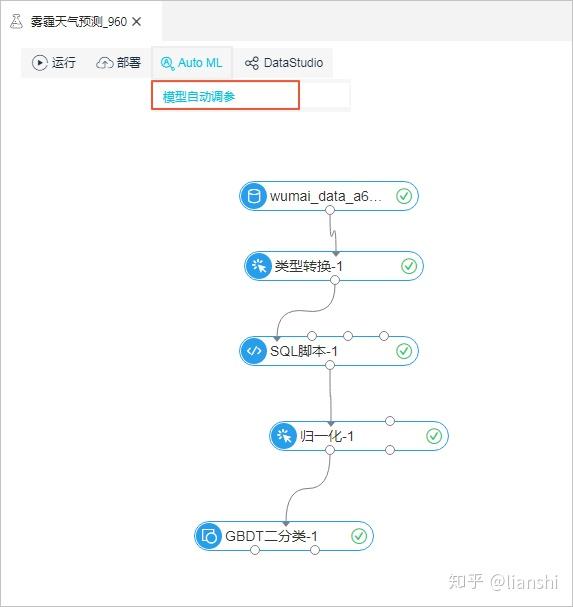
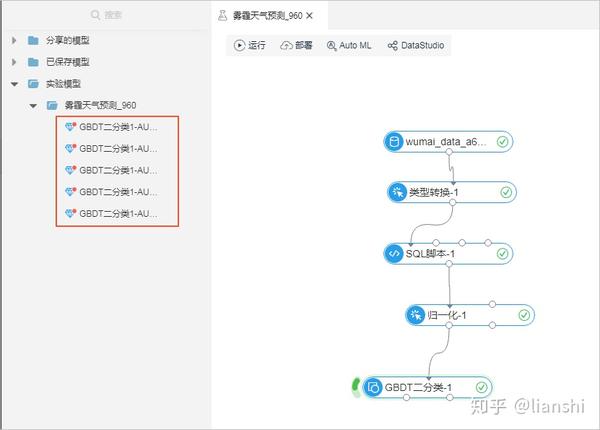
- 登录机器学习控制台,单击左侧导航栏的 实验 。
- 单击某个实验,进入该实验的画布区,本文档以雾霾天气预测实验为例。
- 选择画布左上角的 Auto ML > 模型自动调参 。

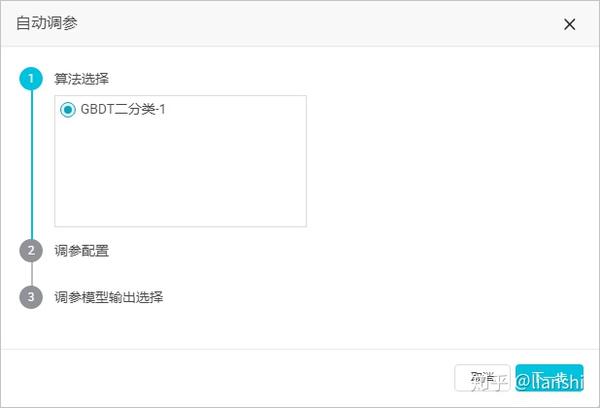
4. 在
自动调参
配置页面,选择需要调参的算法,单击
下一步
。
说明:一个实验中有多个算法时请单选一个算法。

5. 在 调参配置 模块,选择调参方式,完成后单击 下一步 。
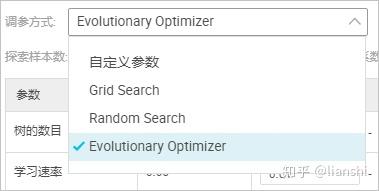
阿里云机器学习提供四种调参方式供您选择:
1. Evolutionary Optimizer
- 随机选定a个参数候选集( 探索样本数 a)。
- 取其中评估指标较高的n个参数候选集,作为下一轮迭代的参数候选集。
- 继续在这些参数周边的r倍( 收敛系数 r)标准差范围探索,以探索出新的参数集,来替代上一轮中评估指标靠后的那些a-n个参数集。
- 根据以上逻辑,迭代m轮( 探索次数 m),直到找到最优的参数集合。
根据以上原理,最终产生的模型数目为 a+(a-n)*m 。
注意
:n的第一个值为 a/2-1,在迭代过程中默认为 n/2-1(小数向上取整)。
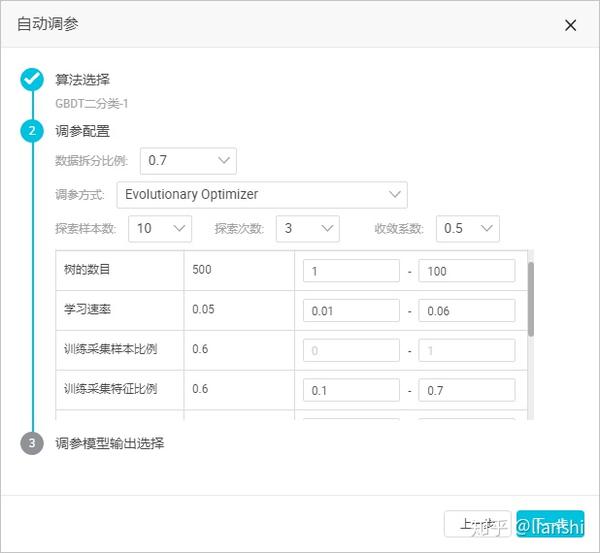

- 数据拆分比例:将输入数据源分为训练集以及评估集,0.7 表示 70% 的数据用于训练模型,30% 用于评估。
- 探索样本数:每轮迭代的参数集个数,个数越多越准,计算量越大,取值为 5~30(正整数)。
- 探索次数:迭代轮数,轮数越多探索越准,计算量越大,取值 1~10(正整数)。
- 收敛系数:用来调节探索范围(上文提到的 r 倍标准差范围搜索),越小收敛越快,但是可能会错过好的参数,取值0.1~1(小数点后一位浮点数)。
- 需要输入每个参数的调节范围, 如果未改变当前参数范围,则此参数按照默认值代入,并不参与自动调参 。
2. Random search
- 每个参数在所在范围内随机选取一个值。
- 将这些值组成一组参数进行模型训练。
- 如此进行m轮(迭代次数),训练产生m个模型并进行排序。
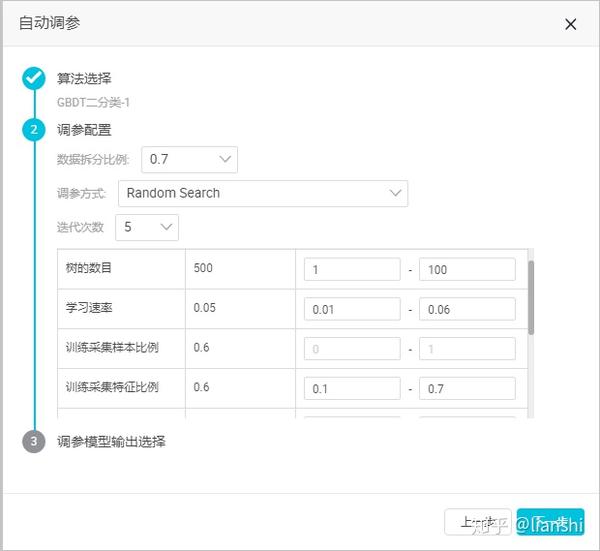

- 迭代次数:表示在所配置的区间的搜索次数,取值 2~50。
- 拆分比例参数将输入数据源分为训练集以及评估集,0.7 表示 70% 的数据用于训练模型,30% 用于评估。
- 需要输入每个参数的调节范围, 如果未改变当前参数范围,则此参数按照默认值代入,并不参与自动调参 。
3. Grid search
- 将每个参数的取值区间拆成 n 段(网格拆分数)。
- 在 n 段里面各随机取出一个随机值。假设有 m 个参数,就可以组合出 n^m 组参数。
- 根据 n^m 组参数训练生成 n^m 个模型并进行排序。
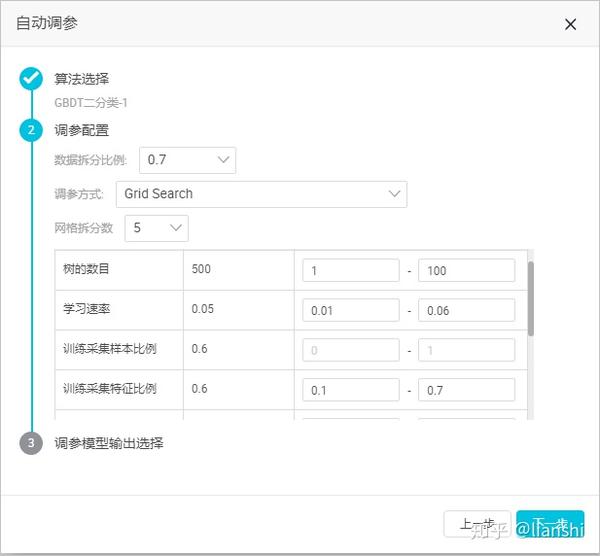

- 网格拆分数:表示拆分出的grid个数,取值2~10。
- 拆分比例参数将输入数据源分为训练集以及评估集,0.7 表示 70% 的数据用于训练模型,30% 用于评估。
- 需要输入每个参数的调节范围, 如果未改变当前参数范围,则此参数按照默认值代入,并不参与自动调参 。
4. 自定义参数
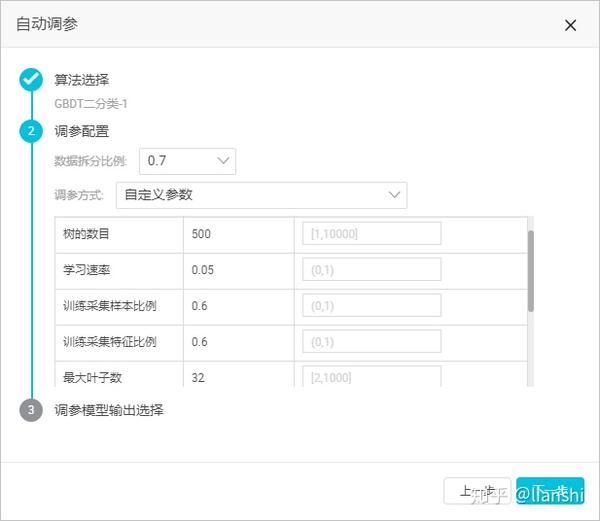

- 用户枚举参数候选集,然后系统帮用户对候选集进行全部组合尝试并打分。
- 枚举范围可以用户自定义输入,参数间通过逗号间隔,如果未输入按照默认参数执行。
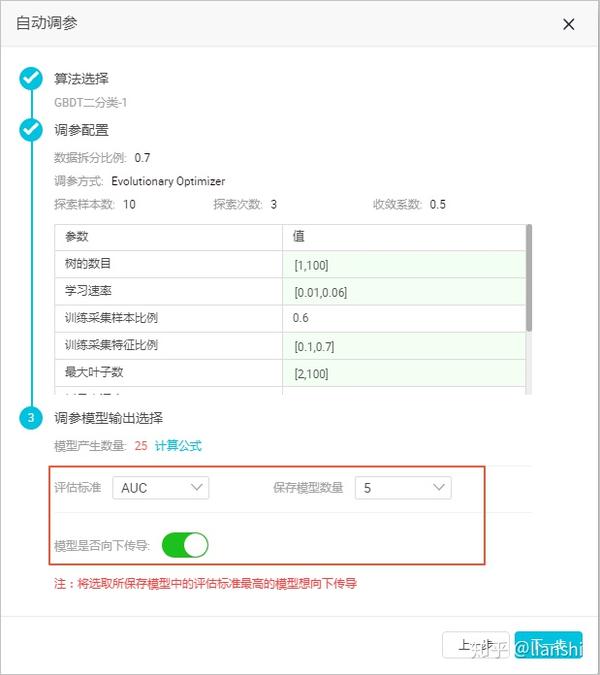
6. 在 调参模型输出选择 模块,配置模型输出参数,完成后单击 下一步 。
- 模型评估:可选择 AUC 、 F1-score 、 PRECISION 、 RECALL 四个维度中的一个作为评估标准。
- 模型保存:保存模型可以选择 1~5 个。根据您所选择的评估标准,对模型进行排名,最终保存排名靠前的几个模型,数量对应您所选择的 保存模型数量 。
- 模型是否向下传导:开关默认打开。如果开关关闭,将将当前组件的默认参数生成的模型,向下传导至后续组件节点。如果开关打开,则将自动调参生成的最优模型,向下传导至后续组件节点。

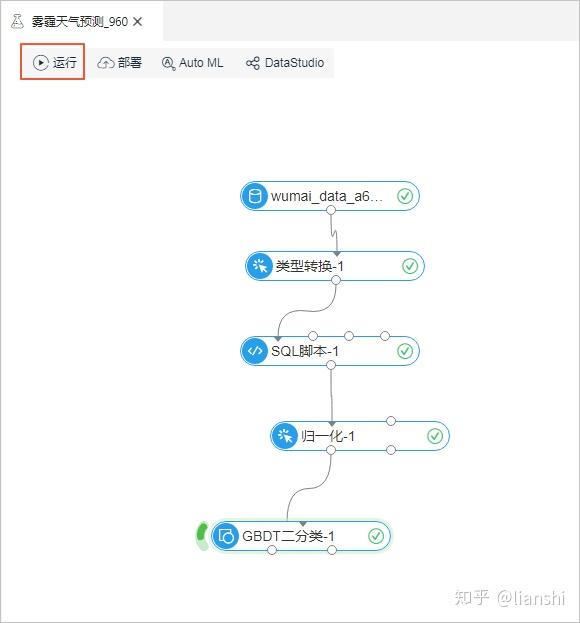
7. 配置完成后,单击画布左上角的
运行
,运行自动调参算法。
说明
:配置完成后,画布上的对应算法已经打开
Auto ML
开关,后续也可以选择打开或关闭此开关。

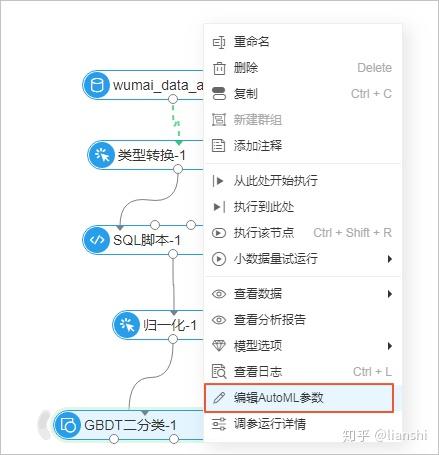
8.(可选)鼠标右键单击模型组件,选择 编辑AutoML参数 ,更改 AutoML 配置参数。

输出模型展示
1. 在调参过程中,鼠标右键单击目标模型组件,选择 调参运行详情 。
2. 在 AutoML-自动调参详情 对话框中,单击 指标数据 ,查看当前调参的进度、各模型的运行状态等信息。
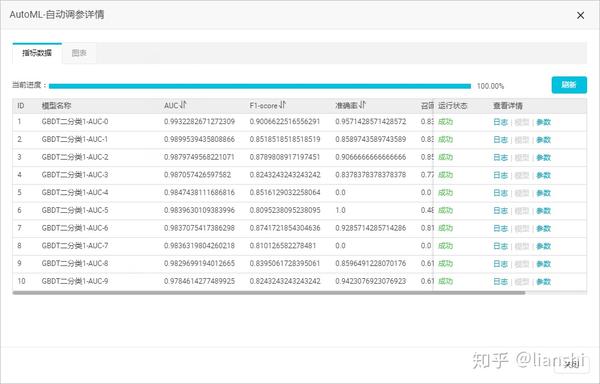

3. 根据候选模型的指标列表( AUC 、 F1-SCORE 、 准确率 、 召回率 )进行排序。
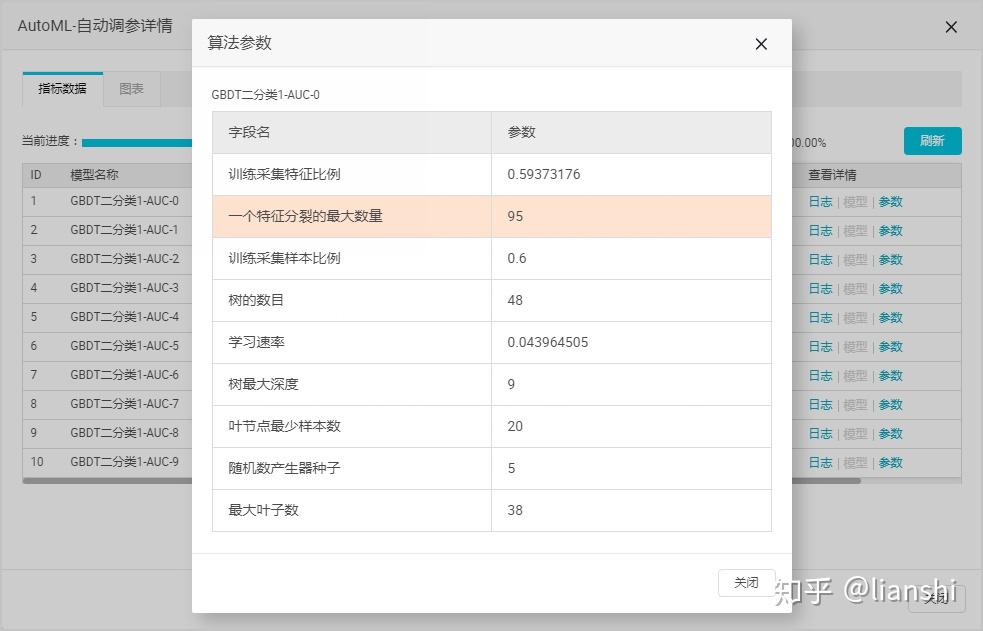
4. 在 查看详情 列单击 日志 或 参数 ,查看每一个候选模型的日志及参数。

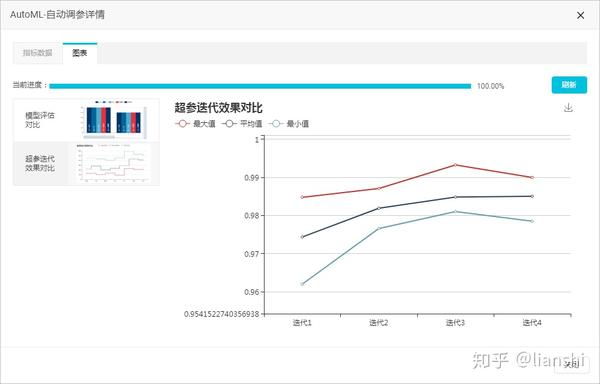
调参效果展示
单击上图中的 图表 ,查看 模型评估对比 和 超参迭代效果对比 图表。
您可以通过 超参迭代效果对比 ,查看每一轮参数更新后评估指标增长的趋势。

模型存储
- 选择左侧导航栏的 模型 。
- 单击 实验模型 ,打开 实验模型 文件夹。
- 单击打开对应的实验文件夹,查看 Auto ML 保存的模型。

更多参考资料详见 阿里云文档
- 腾讯智能钛机器学习
腾讯智能钛机器学习平台与阿里云pai类似,在下图,可以明显的看出线上三种产品的定位以及功能:


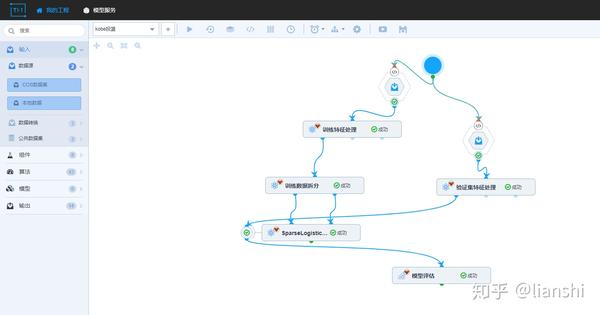
阿里云pai平台相当于TI-ONE的产品,很多GUI模块可以拖拽以调用,TI-ONE 是一站式的机器学习平台,通过可视化的拖拽布局,组合各种数据源、组件、算法、模型和评估模块,形成工作流。让算法工程师方便地进行模型训练、评估及预测。
任务工作流示例图:

可以说与阿里云pai很类似了。敬请期待的TI-S应该就是属于傻瓜式Auto ML,类似与百度的easydl。
在此不再赘述,有兴趣可以去官网注册并尝试:
开源AutoML库
开源的AutoML库有很多,下面仅列举几个知名的,使用AutoML开源库的门槛要比平台的auto调参要高一些,尽管库里有可以支持automl的机制,但是还是需要手动定义搜索空间等一些参数,需要对算法的理解深入。
NNI (Neural Network Intelligence) 是一个工具包,可有效的帮助用户设计并调优机器学习模型的神经网络架构,复杂系统的参数(如超参)等。 NNI 的特性包括:易于使用,可扩展,灵活,高效。
- 易于使用 :NNI 可通过 pip 安装。 只需要在代码中添加几行,就可以利用 NNI 来调优参数。 可使用命令行工具或 Web 界面来查看实验过程。
- 可扩展 :调优超参或网络结构通常需要大量的计算资源。NNI 在设计时就支持了多种不同的计算资源,如远程服务器组,训练平台(如:OpenPAI,Kubernetes),等等。 通过训练平台,可拥有同时运行数百个 Trial 的能力。
- 灵活 :除了内置的算法,NNI 中还可以轻松集成自定义的超参调优算法,神经网络架构搜索算法,提前终止算法等等。 还可以将 NNI 连接到更多的训练平台上,如云中的虚拟机集群,Kubernetes 服务等等。 此外,NNI 还可以连接到外部环境中的特殊应用和模型上。
- 高效 :NNI 在系统及算法级别上不停的优化。 例如:通过 Trial 早期的反馈来加速调优过程。
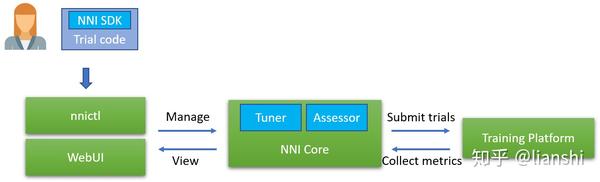
下图显示了 NNI 的体系结构。

主要概念
- Experiment(实验) :实验是一次找到模型的最佳超参组合,或最好的神经网络架构的任务。 它由 Trial 和自动机器学习算法所组成。
- 搜索空间 :是模型调优的范围。 例如,超参的取值范围。
- Configuration(配置) :配置是来自搜索空间的一个参数实例,每个超参都会有一个特定的值。
- Trial : Trial 是一次尝试,它会使用某组配置(例如,一组超参值,或者特定的神经网络架构)。 Trial 会基于提供的配置来运行。
- Tuner : Tuner 是一个自动机器学习算法,会为下一个 Trial 生成新的配置。 新的 Trial 会使用这组配置来运行。
- Assessor :Assessor 分析 Trial 的中间结果(例如,测试数据集上定期的精度),来确定 Trial 是否应该被提前终止。
- 训练平台 :是 Trial 的执行环境。 根据 Experiment 的配置,可以是本机,远程服务器组,或其它大规模训练平台(如,OpenPAI,Kubernetes)。
Experiment 的运行过程为:Tuner 接收搜索空间并生成配置。 这些配置将被提交到训练平台,如本机,远程服务器组或训练集群。 执行的性能结果会被返回给 Tuner。 然后,再生成并提交新的配置。
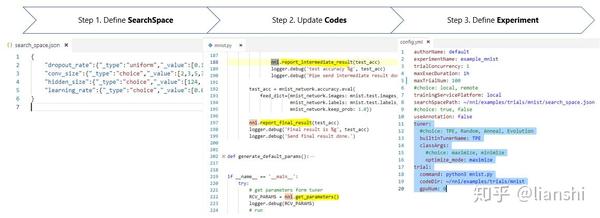
每次 Experiment 执行时,用户只需要定义搜索空间,改动几行代码,就能利用 NNI 内置的 Tuner/Assessor 和训练服务来搜索最好的超参组合以及神经网络结构。 基本上分为三步:
第一步: 定义搜索空间
第二步: 改动模型代码
第三步: 定义 Experiment 配置

现在nni已经有中文的文档,其中有一个 quickstart 文档值得一读:
- Google开源AutoML Adanet
转自 谷歌开源AdaNet:基于TensorFlow的AutoML框架
- 相关论文: AdaNet: Adaptive Structural Learning of Artificial Neural Networks
- 论文地址: http:// proceedings.mlr.press/v 70/cortes17a/cortes17a.pdf
- Github 项目地址: https:// github.com/tensorflow/a danet
- 教程 notebook: https:// github.com/tensorflow/a danet/tree/v0.1.0/adanet/examples/tutorials
谷歌发布博客,开源了基于 TensorFlow 的轻量级框架 AdaNet,该框架可以使用少量专家干预来自动学习高质量模型。AdaNet 在谷歌近期的强化学习和基于进化的 AutoML 的基础上构建,快速灵活同时能够提供学习保证(learning guarantee)。重要的是,AdaNet 提供通用框架,不仅能用于学习神经网络架构,还能学习集成架构以获取更好的模型。
AdaNet 易于使用,能够创建高质量模型,节省 ML 从业者在选择最优神经网络架构上所花费的时间,实现学习神经架构作为集成子网络的自适应算法。AdaNet 能够添加不同深度、宽度的子网络,从而创建不同的集成,并在性能改进和参数数量之间进行权衡。
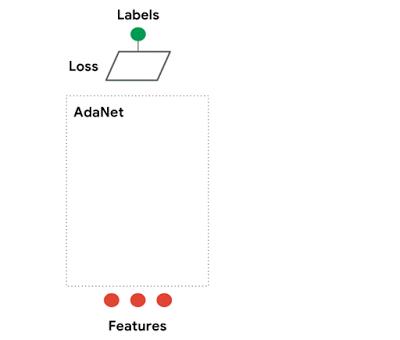
AdaNet 适应性地增长集成中神经网络的数量。在每次迭代中,AdaNet 衡量每个候选神经网络的集成损失,然后选择最好的神经架构进入下一次迭代。
快速易用
AdaNet 实现了 TensorFlow Estimator 接口,通过压缩训练、评估、预测和导出极大地简化了机器学习编程。它整合如 TensorFlow Hub modules、TensorFlow Model Analysis、Google Cloud』s Hyperparameter Tuner 这样的开源工具。它支持分布式训练,极大减少了训练时间,使用可用 CPU 和加速器(例如 GPU)实现线性扩展。
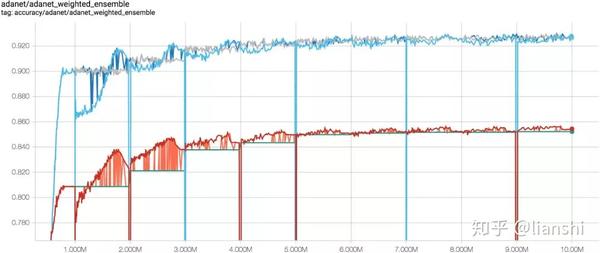

AdaNet 在 CIFAR-100 上每个训练步(x 轴)对应的准确率(y 轴)。蓝线是训练集上的准确率,红线是测试集上的性能。每一百万个训练步开始一个新的子网络,最终提高整个集成网络的性能。灰色和绿色线是添加新的子网络之前的集成准确率。
TensorBoard 是 TensorFlow 最好的功能之一,能够可视化训练过程中的模型指标。AdaNet 将 TensorBoard 无缝集成,以监控子网络的训练、集成组合和性能。AdaNet 完成训练后将导出一个 SavedModel,可使用 TensorFlow Serving 进行部署。
学习保证
构建神经网络集成存在多个挑战:最佳子网络架构是什么?重复使用同样的架构好还是鼓励差异化好?虽然具备更多参数的复杂子网络在训练集上表现更好,但也因其极大的复杂性它们难以泛化到未见过的数据上。这些挑战源自对模型性能的评估。我们可以在训练集分留出的数据集上评估模型表现,但是这么做会降低训练神经网络的样本数量。
不同的是,AdaNet 的方法是优化一个目标函数,在神经网络集成在训练集上的表现与泛化能力之间进行权衡。直观上,即仅在候选子网络改进网络集成训练损失的程度超过其对泛化能力的影响时,选择该候选子网络。这保证了:
- 集成网络的泛化误差受训练误差和复杂度的约束。
- 通过优化这一目标函数,能够直接最小化这一约束。
优化这一目标函数的实际收益是它能减少选择哪个候选子网络加入集成时对留出数据集的需求。另一个益处是允许使用更多训练数据来训练子网络。
AdaNet 目标函数教程: https:// github.com/tensorflow/a danet/blob/v0.1.0/adanet/examples/tutorials/adanet_objective.ipynb
通过固定或自定义 tf.contrib.estimator.Heads,用户可以使用自己定义的损失函数作为 AdaNet 目标函数的一部分来训练回归、分类和多任务学习问题。
用户也可以通过拓展 adanet.subnetwork.Generator 类别,完全定义要探索的候选子网络搜索空间。这使得用户能够基于硬件扩大或缩小搜索空间范围。子网络的搜索空间可以简单到复制具备不同随机种子的同一子网络配置,从而训练数十种具备不同超参数组合的子网络,并让 AdaNet 选择其中一个进入最终的集成模型。
如果说去年“机器换人”的舆论来自车间的机器人手,那今年在全球范围内挥舞起“自动化”大棒的,就成了机器学习。上月,李飞飞发布面向商业公司的机器学习库AutoML,技术门槛之低,让不少工程师担忧不已。一波未平,8月月初,美国德州农工大学开源Auto Keras,同样的功能,但是完全免费。而今天,软件巨头Salesforce也入场了,他们带来的TransmogrifAI,才可能是真正的AutoML“杀手”
工作流程:
通常情况下,如果要构建性能良好的机器学习模型,它需要的研究量和开发量是相当可观的。数据准备、特征工程、模型训练……这些繁琐过程需要不断迭代,为了得到成熟的模型,数据科学家们可能要耗费数周乃至数月的时间。
TransmogrifAI是一个基于Scala和SparkML构建的库,它能承担这个过程中的部分工作。只需几行代码,数据科学家就可以自动完成数据清理、特征工程和模型选择,然后训练出一个高性能模型,进行进一步探索和迭代。
它封装了机器学习过程的五个主要步骤:
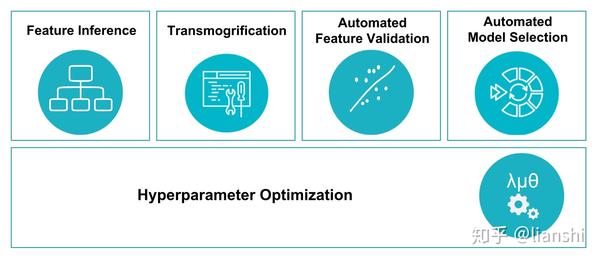

特征推断(Feature Inference)
数据是所有机器学习管道的第一步。数据科学家先收集所有相关数据,再进行整平操作,添加、聚合不同数据源,从中提取可能有助于预测的原始信号。这之后,提取得到的信号会被放进灵活的数据结构中,也就是DataFrame,方便后续操作。虽然这些数据结构简单且易于操作,但其中还是存在一些错误,可能会对下游造成影响,比如存在类型错误和空值错误。
TransmogrifAI可以帮助解决这类问题。它允许用户为其数据指定类型,自动把原始预测变量和响应信号提取为“特征”。除了原始类型,TransmogrifAI的支持面更丰富、更细化,地理位置、电话号码、邮政编码……凡是数据科学家可能频繁遇到的,它都能进行区分。
事实上,即便用户没有指定,TransmogrifAI也可以自行推断。例如,当它检测到数据中的文本特征其实是分类特征时,它会记录这个错误并进行适当处理。不用等到运行时再报错,数据科学家在编译时就能找出大多数错误。

自动化特征工程(Transmogrification)
虽然找到正确的类型有助于数据推理和减少对下游的不良影响,但最终所有特征都是要被转换成数字表示的。只有这样,机器学习算法才能寻找并利用其中的规律。这个过程被称为特征工程。
举个例子,我们该怎么把美国的各个州(如CA, NY, TX等)转成数字?一种方法是把每个州映射为1到50之间的数字,因为美国一共有50个州。但这种编码方法的缺点在于没有保留州与州之间地理位置上的关系。那么如果我们计算州中心点到美国中心点的距离,并以此为编码依据呢?这确实可以解决之前提到的问题,但它同样无法反映东西南北位置。
所以特征工程的方法有无数种,但是找出正确的一种十分不容易。
TransmogrifAI可以帮数据科学家自动化这个恼人的过程。它为自己支持的所有特征类型提供了无数种编码技术,能做到不仅把数据转成算法可用的格式,还能优化转换,使机器学习算法更容易从数据中学习。例如,同样是年龄数字特征,它能根据特定问题(时尚行业、金融理财)把它们转成最合适的年龄段。
尽管TransmogrifAI已经具备了上述强大能力,但考虑到特征工程是一场无穷无尽的“博弈”,它也支持用户自定义和扩展默认值。
自动化特征验证(Feature Validation)
特征工程可能导致数据维度出现爆炸性增长,而高维数据往往会让模型出现差错!其中最典型的是模型过拟合,另一个容易被忽视但影响巨大的问题是数据泄露。
假设我们手头有一个包含交易信息的数据集,任务是预测最终的交易金额,而数据集上一个条目叫“已结算交易金额”,这是完成交易后才能统计到的信息。如果我们不慎把这个信息也放进训练集里,模型就会发现它的“可参考性”极强,最后成为一个测试时精度极高,实践时一无所用的废品。
事实上,在Salesforce业务中,这种后见之明的偏见尤其成问题,因为大部分客户的数据很复杂,平时也是自动填充的,这使得数据科学家很容易混淆因果关系。
TransgmogrifAI包含执行自动特征验证的算法,可以删除几乎没有预测能力的特征——随着时间的推移而使用的特征,表现出零方差的特征,或者在训练样本中的分布与预测时的分布存在显着不同的特征。在处理含有偏差的高维数据时,这些算法会用一系列基于特征类型的统计测试,结合特征谱系来检测和排除偏差。
自动化模型选择(Model Selection)
完成所有关于数据预处理的工作后,数据科学家就该把机器学习算法应用于准备好的数据以构建预测模型。如果是手动完成,他们往往需要尝试许多不同的算法,并找到合适的参数设置。这是个耗时的工程。
TransmogrifAI的模型选择器可以在数据上运行多种算法,并比较它们的平均验证错误,从中挑出最佳算法。除此之外,它还能通过适当地对数据进行采样并重新校准预测以匹配真实的先验,自动处理不平衡数据的问题,进一步提高模型性能。
超参数优化(Hyperparameter Optimization)
上述自动化步骤的基础都涉及超参数优化,它几乎无处不在。而就是这么一个耗时久、任务量重、让数据科学家望而生畏的操作,它背后的技术原理却不难,可以直接看成一个高性能模型和一个随机数生成器模型。这个任务,TransmogrifAI可以代劳。
总的来看,现在TransmogrifAI在Salesforce内部已经成功把训练模型所需的总时间从几周、几个月缩短到了几个小时。而封装所有这些复杂操作的代码却非常简单,只需短短几行就能搞定:
// 读取交易数据
val dealData = DataReaders.Simple.csvCase[Deal](path = pathToData).readDataset().toDF()
// 抽取特征
val (isClosed, predictors) = FeatureBuilder.fromDataFrame[RealNN](dealData, response = "isClosed")
// 自动化特征工程
val featureVector = predictors.transmogrify()
// 自动化特征验证
val cleanFeatures = survived.sanityCheck(featureVector, removeBadFeatures = true)