


Kaggle求生:亚马逊热带雨林篇

大家好,我是思聪 · 格里尔斯,我将向您展示如何从世界上某些竞争最激烈的比赛中拿到金牌。我将面临一个月的比赛挑战,在这些比赛中缺乏正确的求生技巧,你甚至拿不到铜牌。这次,我来到了亚马逊热带雨林。
当我和我的队友们进入这片雨林的时候,这场长达三个月的比赛已经进行了两个月,想要弯道超车,后来居上,那可不是件容易的事。 我们最后在比赛结束的时候,获得了Public Leaderboard第一, Private Leaderboard第六的成绩,斩获一块金牌。 这个过程中,我们设计并使用了一套简洁有效的流程,还探索出了一些略显奇怪的技巧。
这套流程包括 数据问题分析、查找资料、制定和调整解决方案、结果的记录分析 等,使用它,我们从Public Leaderboard一百多名起步,一路杀进金牌区,一直到比赛结束前,占据Public Leaderboard榜首数天,都没有遇到明显的阻力。在这篇文章里,我不仅会介绍这个流程本身,还会把我们产生这套流程的思路也分享出来,让大家看完之后,下次面对一个新问题,也知道该如何下手。这些思路和经验也不仅仅适用于Kaggle比赛,对其他实际的机器学习项目也有很好的借鉴意义,我们从中收获颇丰,希望各位读者也能如此。
在文章的结尾,我还会讲一讲我们比赛最后一夜的疯狂与刺激,结果公布时的懵逼,冷静之后的分析,以及最后屈服于伟大的随机性的故事。
(PS:由于本文较长,约两万字,建议时间有限的读者可以先只读第3部分 探险开始:解决方案的规划和选择 )
目录:
- 初探雨林:概述(Overview)与数据(Data)
- 痕迹与工具:讨论区(Discussion)和Kernel区
- 探险开始:解决方案的规划和选择
- 学习,奋斗,结果与伟大的随机性
- 队伍成员介绍
1. 初探雨林:概述(Overview)与数据(Data)


探险的第一步是要弄清楚问题的定义和数据的形式,这部分看起来会比较繁琐,但是如果想要走得远,避免落入陷阱,这一步还是比较值得花功夫的,所以请大家耐心地看一下。如果是已经参加过这个比赛的读者,可以直接跳过这个部分。
我们先看一下这个比赛的标题:
- Planet: Understanding the Amazon from Space
- Use satellite data to track the human footprint in the Amazon rainforest
翻译一下就是
- Planet(举办比赛的组织名):从太空中理解亚马逊
- 使用卫星数据来跟踪人类在亚马逊雨林中的足迹
看来这是一个关于亚马逊雨林的卫星图像比赛,为了进一步了解问题,我们需要阅读的是比赛的 Overview 和 Data 两个部分。
1.1 描述(Description)
Overview的Description(描述)部分告诉了我们主办方的意图,原来是为了从卫星图片监控亚马逊雨林的各种变化,以便当地政府和组织可以更好保护亚马逊雨林。看我发现了什么,这个Overview的尾部附带有一个官方提供的ipython notebook代码的链接:
Getting started with the data - now with docs!
这个ipython notebook有不少信息量,包含对数据的读取,探索,相关性分析,可以大致让我们对数据有一个基本的感觉,并且可以下载下来进一步分析,可以省上不少功夫。如果官方没有提供这样一个notebook, Kernel区一般也会有人发出自己的一些分析,实在没有最好也自己做一下这个步骤,因为这个可以为后面的一些决策提供信息。
1.2 数据(Data)
然后我们可以先跳过Overview的其他部分,去看一下Data部分。Data部分一般提供数据的下载和说明,先把数据点着下载,然后仔细阅读说明。其中训练集大概有四万张图像,测试集大概有六万张图像。数据说明包括了数据的构成和标签的来源。我们可以先看一下这张图:
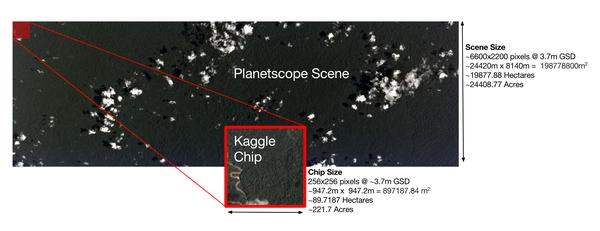

这次比赛中的每个图像样本都是256*256像素,并且每个像素宽约对应地面的宽度大约是 3.7m。然后每个样本都有jpg和tif两种格式,tif好像是比正常的RGB通道多了一个红外线通道,嗯,可能会有用。
数据的标签有17个类,其中4个天气类,7个常见普通类,以及6个少见普通类。
天气类包括:Clear,Partly Cloudy,Cloudy,Haze。其中只要有 Cloudy的就不会有其他类别(因为被云覆盖住了什么都看不到)。
常见普通类包括:Primary Rain Forest,Water (Rivers & Lakes),Habitation,Agriculture,Road,Cultivation,Bare Ground。
少见普通类包括:Slash and Burn,Selective Logging,Blooming,Conventional Mining,"Artisinal" Mining,Blow Down。
普通类描述的是丛林中出现的各种景观,包括河流、道路、耕种用地、采矿基地等等。
下面是一些样本的示例图,图中用红色字体打上了类别信息:


官方还附带了这些类别的说明和相关新闻报道,其中类别的说明最好读一下,有助于对任务的理解。我们在最开始对每个类的含义和特性进行了分析,然而最后探索出来的方案并没有对不同类别进行针对性的处理。虽说如此,下次遇到一个新问题我们仍然会尝试进行分析。
理论上每幅图都拥有一个天气类外加若干个普通类,所以 这是一个Multi-Label (多标签)的问题 。其中少见普通类比较少,大概四万个样本中有的类甚至不到一百个。在最后的Submission中,我们要提交一个包含大概六万个样本的标签的csv文件,其中大约四万个用于Public Leaderboard的分数计算,两万个用于Private Leaderboard的分数计算。
官方还提到数据是众包平台上标注的,所以会包含一些错误的标签,因为其中 一些图像他们组织里的专家都分不清楚 ,更不要说众包标注的工人了,所以我们要意识到这是一个富含噪声的数据集。最后的比赛结果也证实了这一点,因为前63名的分数都在93.0%到93.3%之间,甚至都突破不了94%。这里的分数是指什么呢?请看下一小节。
1.3 评价指标(Evaluation)
弄清了问题的形式,接下来我们可以返回阅读Overview的剩下部分。Evaluation告诉我们这次的评价指标是各个样本F2-score的均值,F2-score的定义如下
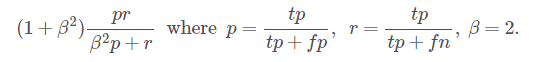

p是精度(precision),表示我们预测出来的类出现在标签中的比例;r是召回率(recall),表示标签中出现的类被我们预测出来的比例。F2-score相对偏好召回率, 所以在比较不确定的时候,预测多一点可能会比预测准一点来得好 。
1.4 奖金(Prize)与比赛时间线(Timeline)
这次比赛的奖金第一名有3万美刀,第二名2万美刀,第三名1万美刀。虽然没有类似Zillow那个一百多万美刀那么惊人,但也是一笔不少的外快了。
比赛开始于4月20日,7月13号则是参加截止日期以及合队截止日期。一般来说,即便你是和几个小伙伴一起参赛,也不要急着太早合队,因为每个队伍每天只有固定的提交次数可用,不合队的话所有人加起来可以获得数倍的提交机会,这对于初期的方案探索是非常有益的。
另外,7月13日也同时是预训练模型声明截止的时间,因为图像类比赛经常会使用ImageNet上预训练过的模型,为了公平起见,所有人都只能使用讨论区一个置顶帖中声明过的预训练模型,如果选手所使用的预训练模型没在里面,那就要在截止时间前自觉去帖子里添加声明,否则视为作弊。
比赛最后于UTC时间7月20号晚上11点59分结束,对于身在国内的我们来说,这意味着最后一天要通宵陪欧洲人民冲刺到早上八点。
2. 痕迹与工具:讨论区(Discussion)和Kernel区
一个老练的探险队员要善于利用前人留下的信息。我们队里常说,一个能善于使用讨论区、工程能力不差并且有时间精力的人,应该有很大可能性拿到一个银牌。讨论区里包含着官方的一些申明通知,还有其他队伍的一些经验分享,Kernel区包含了一些公开发布的代码。这些都是所有参赛队伍共享的信息,对于一个新手和后进场的队伍,从这里面获取足够信息可以取得比较好的开端。
此外,常被忽略的一个点是,其他一些已经结束的类似比赛中,也包含了大量对这个比赛有用的信息。比如这个比赛是卫星图像的多标签分类比赛,那么其他卫星图像比赛or图像or多标签分类比赛的信息都会对这个比赛有用,这些比赛的讨论区经常包含了大量优秀的解决方案,这对我们后面设计方案会有帮助。
最后要小心的是,讨论区里面的发言也不一定对,Kernel区的代码可能也有些bug,比如这次比赛有一些队伍因为使用了一个有bug的submission生成代码,最后都掉了八九百名,场面十分血腥。
我们从参赛的时候从讨论区获取的一些有用信息如下:
- tif图像数据在RGB通道之外包含红外通道,按理来说多使用上这个信息应该会提高效果,然而恰恰相反,讨论区的人说用了之后反而变差了,这可能是因为有些图片的红外通道跟RGB通道是错开的。所以到比赛结束我们也只是稍微尝试了一下去利用tif的红外通道,并没有在上面浪费太多时间。
- 其他队伍有可能使用了哪些预训练模型,每个模型的大体性能如何,这给我们提供了很有用的参考,比如我们在尝试了一些比较小规模的模型(如ResNet18、ResNet34)之后,以为这些模型已经够了,再大再复杂的模型可能会过拟合,但是从讨论区我们看到,大模型还是有明显优势的,这就促使我们敢于花大量时间去跑那些笨重的ResNet152、DenseNet161等预训练模型。
- 从其他类似比赛的讨论区我们看到,高分队伍一般不会使用特别复杂的Ensemble方法,甚至会仅仅使用简单的bagging和stacking(下面会讲),所以我们就把更多的精力花在单模型的调优。事实证明,即便到了比赛后期,还不断有一些更好的单模型新鲜出炉,使我们Ensemble后的效果猛地一窜,窜到了Public Learderboard前三乃至第一。
3. 探险开始:解决方案的规划和选择
以上准备可能会花上你一到两天的时间,但磨刀不误砍柴工,我们也差不多可以开始我们的征程了。
3.1 BCE Loss训练 和 F2-Score阈值调优
上面提到,这次比赛问题是Multi-Label(多标签)分类问题,评价指标是F2 Score,但F2 Score并不是可以直接优化的值,所以我们采取的方法是:
- 每个输出接Sigmoid层,分别预测每个类的概率,使用Binary Cross Entropy Loss优化。这其实是多标签分类问题的常见套路,本质是独立地对每个类做二分类学习。虽说不同类之间可能存在相互依赖,但我们假设这些依赖可以通过共享底层参数来间接实现。
- 在训练上述二分类任务时,由于正负样本数目不均衡,我们并不能直接拿p = 0.5作为二分类的阈值进行预测,而需要为每个类搜索一个合适的阈值,使得整体的F2-Score最大。具体来说,我们采取了讨论区放出的一个 方案 ,贪婪地对每个类的阈值进行暴力搜索,逻辑如下:
# 假装是Python的伪代码
给定17个类的阈值构成的阈值向量,每个元素初始化为0.2