


Survey阅读笔记:关系归纳偏差+深度学习+图网络

论文时间为2018年6月,DeepMind联合谷歌大脑、MIT等机构27位作者发表的论文,论文提出“图网络”(Graph network),将end-to-end的学习与归纳推理结合,有望解决Deep Learning中无法进行关系推理的问题。
关键词:
关系归纳偏置(relational inductive biases)
关系深度强化学习(Relational Deep Reinforcement Learning)
关系RNN(Relational Recurrent Neural Networks)
组合泛化(combinatorial generalization)
实体(entities)
关系(relations)
规则(rules)
1.简介(Introduction):
AI最近在在诸如视觉,语言,控制和做决策等多个领域中迎来了重生,之所以能取得如此成绩,与近来计算开销和数据资源越来越廉价孕育了深度学习密切相关。然而,尽管有如此进步,AI在很多方面达不到人类智能水平。尤其是从一个个体经验来泛化出来一些可以广泛适用群体的特征,这仍旧是线代AI的巨大挑战。
论文认为:组合泛化(combinatorial generalization)是AI中最首要的任务,要达到这个目的,结构化表征(structured representations)和计算能力(computations)很关键。如生物学中,将先天基因和后天孕育结合在一起,因此我们必须摒在” 手动设计结构 (hand-engineering)“和” 端到端 (end-to-end)”二选一的错误做法,而是把两者结合起来:深度学习+基于结构的方法:图网络。
我们要探索的是:如何在深度学习结构中学习实体(entities),关系(relations),规则(rules)并组合起来,然后在其结构中实现关系归纳偏差?对此,我们提出了一种可在AI中应用的新模块,即 图网络 ,图网络通过提供一个接口用来操作结构化知识并处理结构上的行为。那么图网络如何实现 关系推理 (relational reasoning)和 组合泛化 (combinatorial generalization)呢?
一种关键的人类的智能能力——以有限表示无穷 (A key signature of human intelligence is the ability to make "in finite use of fi nite means")。即用一些集合的元素(如句子,单词)进行无限的组合(组成句子,文章)。这也反映出了组合泛化原则:从已有的模块进行组合,来达到推理,预测等功能。
人类组合泛化能力依赖于我们对结构化表示和关系推理的认知 (Humans' capacity for combinatorial generalization depends critically on our cognitive mechanisms for representing structure and reasoning about relations.)。人类使用分级制来提取行为和表示的差别和共性,同时面对新颖的问题,会采用相似技能与常规经验相组合(composing familiar skills and routines)来解决。即:我们通过对齐两个域之间的关系结构,并根据其中一个域来对另一个域相对应的知识得出一个推论或类比(We draw analogies by aligning the relational structure between two domains and drawing inferences about one based on corresponding knowledge about the other)。
当我们在学习时,我们把新的知识添加到已经学过的结构表示中,或是调整整体结构来适应新、旧知识的整合 (When learning, we either t new knowledge into our existing structured representations, or adjust the structure itself to better accommodate (and make use of) the new and the old)。自AI诞生以来,组合泛化一直是许多算法(如逻辑,语法,分类规划,图模型,逻辑推理,无参数贝叶斯等)的中心,如今研究聚焦在明确实体和关系的学习中,像关系强化学习,统计关系学习。在计算代价比较大,数据没那么廉价的时期,强有力归纳偏差算法则会表现的非常重要。
对比过去的AI算法,往往都陷入“端到端”的设计哲学中,并强调最小化先验表征和计算假设,并避免明确的结构和手工设计结构。正是由于深度学习刻意避开了组合性和明确的结构方法,而面对像复杂语言、场景理解、结构化数据推理、基础训练上的迁移学习和少量经验学习这些需要组合泛化功能实现的任务,深度学习在这些任务上就难以实现了。
像生物学一样, 在AI中我们要遵循总体大于部分的理念 来达到组合泛化,把结构化和灵活性相结合。而最近在深度学习中兴起结构化方法,即为图网络,与传统深度学习方法区别是:图网络将实体(entities)和关系(relations)的表示,结构和相应的计算,并减轻需要预先指定它们的负担。特定的结构假设则会带来强烈的关系归纳偏差,而特定的假设结构会引导这些方法来学习实体和关系,偏好也是人类智能的基本成分(偏好这里原文为suggest,此处为鄙人自行翻译的)。
2.关系归纳偏差(Relational inductive biases):
Box 1:关系推理(relational reasoning):
我们将结构定义为已知模块组合而成的产品 (We de ne structure as the product of composing a set of known building blocks)。
结构表示:得到组成成分分布
结构计算:组成元素上的操作
关系推理则是使用规则(rules)来操纵实体(entities)、关系(relations)的结构表示 。我们用如下术语来捕获AI和计算机科学中的概念:
~实体:一个有属性的元件,通常为一个有尺寸的物理对象。
~关系:实体之间的属性值,包括大小长短距离等,关系属性可以作为相关权重的阈值来决定关系为true or false。
~规则:一个函数(类似非二级制逻辑预测),用来衡量实体,关系和其它实体,关系,像规模比较(哪个实体更大,X实体比Y实体大多少)。
~关系推理:利用规则,在实体和关系的结构化表示上所做的操作。
图模型通过对随机变量进行显式的随机条件独立性来表示复杂的联合分布(有点绕口),模型能取得成功的原因,因为模型可以捕获到真实世界生成过程的稀疏结构并且支持能够进行推理和学习的算法。论文提到隐马尔科夫模型的例子,隐马尔科夫模型约束潜在的状态,在前一个时间步上有条件地独立于其他的状态,在当前时间步上有条件的独立于观察,这与许多现实世界因果关系结构很匹配。明确表达了稀疏的变量之间的依赖关系提供了各种有效的推理和算法。如消息传递,应用一个图形模型中跨地区公共信息传播,得到一个可组合,部分并行的推理过程,同时可以应用于不同大小和形状的图模型。
Box2:归纳偏差(Inductive biases):
也许这个说法不够准确和规范,但我们把在学习过程中,实体之间关系和相互作用施加约束叫做归纳偏差。( While not a precise, formal de nition, we use this term to refer generally to inductive biases (Box 2) which impose constraints on relationships and interactions among entities in a learning process. )
学习过程涉及到寻找一个解空间中的解, 归纳偏差(inductive biases) 允许一个学习算法优先选择一个解决方案或者解释方案(solution or interpretation)。归纳偏差经常会以提高灵活性来提高样本复杂性,并可由偏差-方差来权衡理解。
归纳偏差表现在:
⑴贝叶斯模型中,先验分布的选择和参数表达;
⑵作为正则化项,来避免过度拟合;
⑶在算法本身的体系结构中编码。
理想状态下,可以在不减小模型的表现力下搜寻解决方案,若约束过强,不匹配的归纳偏差也能得到一个次优解方案。
归纳偏差可以表达关于数据生成或解的空间的假设(assumptions),例如:当一维函数拟合数据时,线性最小二乘遵循约束约束函数是线性模型的约束,那么近似误差就在二次罚函数(不太理解这个函数)之下。
与此相似,L2正则化优先考虑参数具有最小值的解决方案,并针对不适合问题引入独特解决方案和全局结构。这可以解释为一个关于学习过程的假设:当解决方案之间的歧义较少时,寻找好的解决方案更容易。。其中,假设可以不明确,仅仅反映模型或算法如何与世界交互。
创建新的机器学习结构在最近几年非常火,但是从业者们大都陷入了同一种设计方案中去,疯狂的堆叠诸如"多层感知机"、"卷积云层"等模型网络及一种由多类CNN组合而成的MLP处理图像数据的网络模型。这些做法会形成一种特别的关系归纳偏差——分层处理——这样就会导致信息在输入阶段进行长时间的交互。尽管我们主题是讨论关系归纳偏差,像权重衰退,dropout等非关系归纳偏差的算法也在深度学习中表现良好。如果我们接着往下看,模型的 基础模块 (the building block)也带有归纳偏差。


深度学习中,实体和关系通常分布式表示,而规则则作为神经网络函数来逼近。
~规则函数的参数。
~规则函数如何在计算图上重复使用或共享。
~架构如何定义交互与表示之间的隔离。
关系归纳偏差在标准深度学习中建立基块:
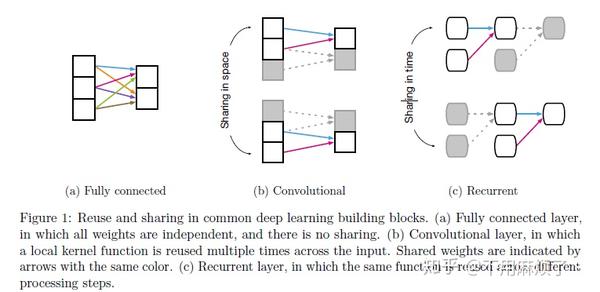

1.全连接阶层:
实体-细胞单元,
关系-all-to-all,
规则-参数权重(W)和偏差(b)
2.卷积层:
实体-细胞单元,
关系-稀疏,
规则-参数权重(W)和偏差(b)
不同于全连接网络,卷积云中,有一些重要的关系归纳偏差:局部性和平移不变性,局部性反映了规则的参数是在输入信号的坐标空间中彼此非常接近的实体,与远端实体隔离开。翻译不变性反映了输入中跨地方重用相同规则。这些偏差在处理图像数据更有效,局部性里有一个高协方差,随距离增加而减小。
3.递归层:
实体-input和每一步过程的隐状态
关系-当前input和马尔科夫依赖当前隐状态的隐状态
规则-结合实体(input,hidden state)来更新隐状态
3.图网络(Graph networks):
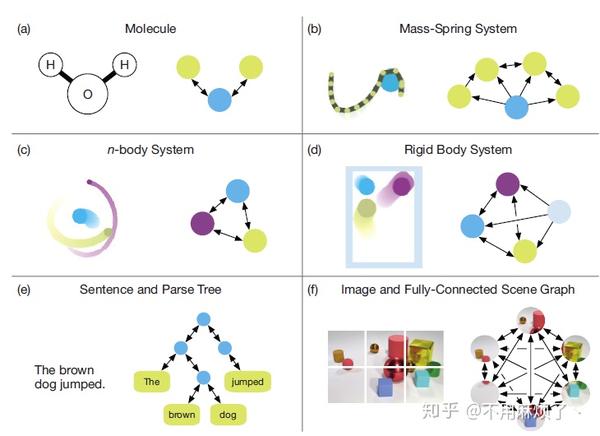

图网络模型遍布监督学习,半监督学习,无监督学习,强化学习等领域。并能在视觉理解,few-shot learing(不知道是啥),动态物理结构(the dynamics of physical systems),多代理系统(multi-agent systems),知识图谱推理,预测化学分子和图像分割,meshes and point clouds(也不知道是啥)等表现得很有效果。最近图网路的工作重心在:图生成模型和图形嵌入无监督学习中。
此外,有两种网络结构,MPNN,统一了不同种图网络和卷积云网络算法,NLNN则统一了多种“self-attention”算法。
Graph network (GN) block:
我们的图网络框架:定义了一类函数在图结构表示上进行关系推理,泛化和 延展了不同类图网络,如MPNN,NLNN算法,并且支持从单一模块上构造复杂结构。这种主要统一了GN框架里单元计算即为GN 模块。
注:图网络不仅仅在神经网络上可以使用。
这种“graph-to-gtraph”模块以图作为输入,在结构上表现计算,然后返回一个图作为输出。如 Box 3, 实体为图的节点,关系为边。
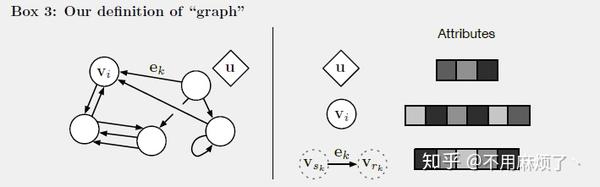

如图Box3,Vi为节点,ek为边,u为全局属性。sk和rk为发送者和接收者。
图网络的设计理念 :
灵活表示 (Flexible representations)
可控内部结构 (Con gurable within-block structure)
可组合多块体系结构 (Composable multi-block architectures)
举例解释(论文后续总会以这个例子解释):在引力场中预测一组橡胶球的运动,橡胶球之间由若干个弹簧相连接起来。
图的定义 :图定义为一个三元组,G=(u,V,E),u为全局变量(类似于例子中的引力场),V={vi}i=1:Nv 为节点的集合,每个vi为节点属性(类似于例子,V代表每一个球的属性,属性如位置,重力等等),E = f(ek; rk; sk)gk=1:Ne为边的集合,每个ek代表边的属性,rk为接收节点索引,sk为发送者的索引(类似于例子,E表示连接不同球的弹簧,并符合弹簧常数)。


GN模块的内部结构 :


∅e映射所有边来更新边,
∅v映射所有节点来更新节点,
∅u应用一次全更新。
ρ函数,将集合作为输入,将其减少为表示聚合信息的单个元素,函数必须对输入的排列不变,使用可变数量的参数。
GN 模块的内部计算步骤(Computational steps within a GN block):
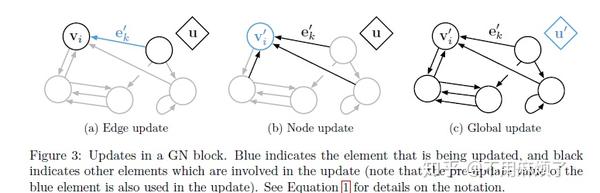

1.∅e应用每一条边,其参数(ek,vrk,vsk,u),返回e'k,在我们的例子中,符合连接两球之间的势能;
2.ρ e->v将投影到顶点i的边更新聚合到e'i中,为下一步节点更新使用,这就像对应于第i个球上所有的势能进行求和;
3.∅v计算更新过的节点属性V'i,例:计算每个球的位置,速度,动能;
4.ρ e->u更新E',聚合所有的边输入给e',然后给下一步全局更新使用,例:计算合理和弹簧势能;
5.ρ v->u应用到V',聚合所有的更新节点,并在接下来全局更新使用,例:计算系统总能量;
6.∅u每一个图应用一次,并更新全局属性u',例:类似物理系统的净力量(the net forces)和系统总能量。
图网络中的关系归纳偏差(Relational inductive biases in graph networks):
1.图网络可表示实体内任意关系,GN's输入决定实体如何交互和隔离,而非那些固定结构;
2.图表示实体和关系作为集合,集合排列不变,意味着GN's对于这些元素顺序不变;
3.GN的边、节点分别可在所有边和节点上重复使用,GNs自动支持一种组合泛化形式。
4.图网络结构的设计原则(Design principles for graph network architectures):
设计理念在之前部分已经有所涉及,在这里进行继续补充,总的来说,框架对特定的属性表示和功能形式是不可预知的,我们聚焦于深度学习框架,其中GNs扮演可学习的图到图的逼近功能函数。
高灵活性体现 :1.属性的表示;
2.图网络的结构。
属性 :1.节点,边,属性可悲任意结构形式表示;
2.文体需求决定属性的表现形式(如图像需求属性为tensor,text需求属性为词寻列);
3.对于广泛的GN块,边,节点的输出通常为一列向量或张量, 每一个边或节点或全局变量输出为单一向量或张量,从而可将GN输出传递给深度学习模块。
GN block 的输出通常为定制的,边(edges),节点(nodes),globals(全局属性)这三种也可混合或拼接。
图结构(Graph structure):
两个非硬性指标:
1.输入明确指出关系结构;
2.必须腿短或假设关系结构。
配置内部模块结构:
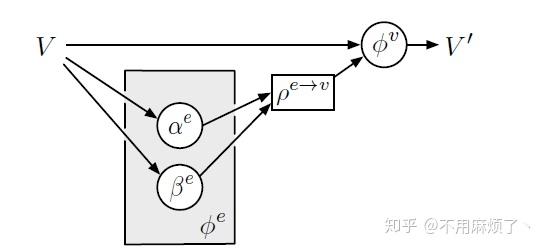
每一个∅方程需要几个f方程才能执行,f的参数决定了它需要什么样的输入信息:
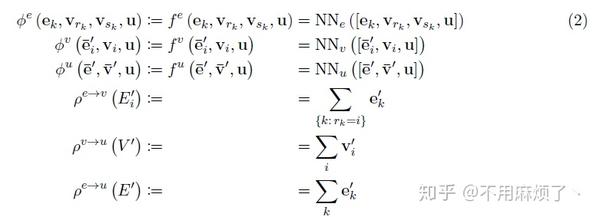

∅函数可以使用MLP,CNN,RNN处理,具体要看实际操作数据。
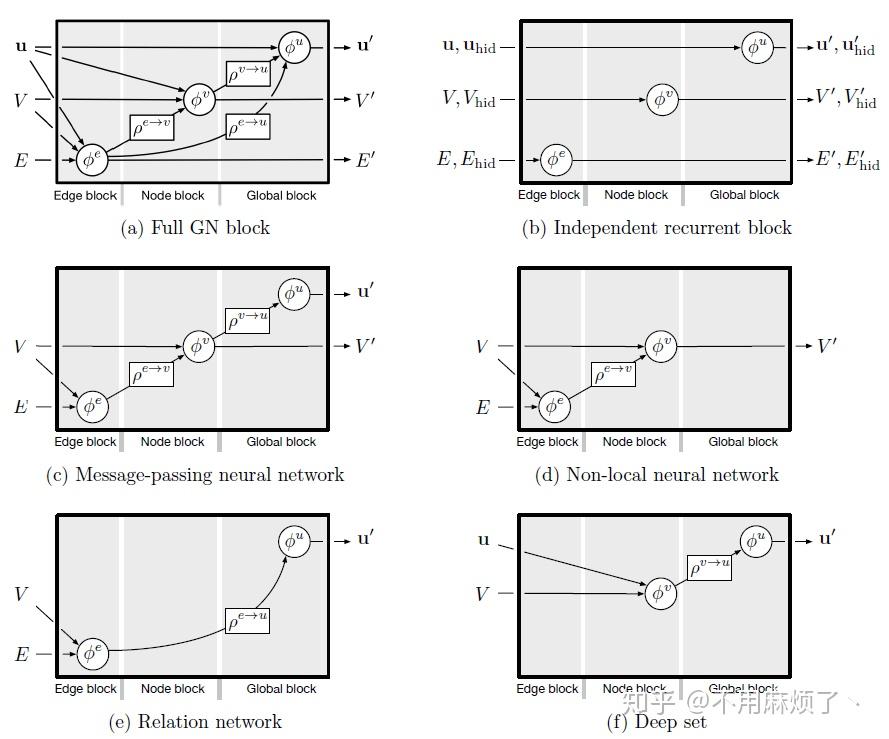
Message-passing neural network (MPNN):
MPNN概括了许多以前的架构,可以自然地翻译成GN形式主义。
大致分为五个步骤:消息函数,元素求和,更新函数,读出函数,d master服务(详情还是看论文内容吧)。
Non-local neural networks (NLNN):

NLNN由 ∅e 和 ρ e->v 在GN框架下实现的,图像/句子不同区域对应于一个全连接的图中节点,attention mechanism在聚合步骤中定义节点的权值。“attention”这里指,每个节点更新基于与它相邻节点属性的权值,这个权值有节点和它相邻节点的配对函数计算而来。
边不确定问题解决:通过置零节点间的权重,并不共享边。
其它图网络变体 :
若全局属性、节点、边在输入时未指定,那么这些向量可以为零长向量。
CommNet,structure2vec,Gated Graph Sequence Neural Networks
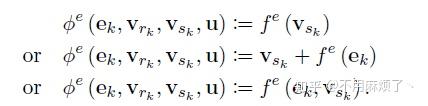

Relation Network
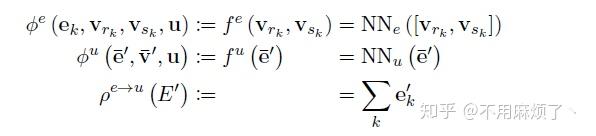

Deep Set
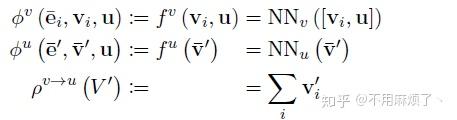

Point Net
使用相似更新规则,最大聚合: 最大聚合:ρv->u 和两步节点更新。
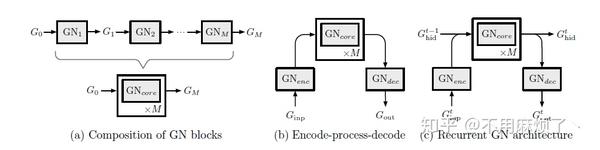

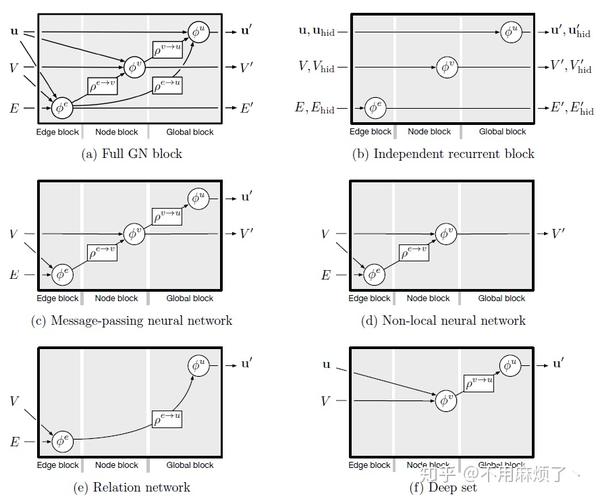
如Figure 6,
a: 中GN可共享权重,也可独立,多个GN顺序组合而成GN“核心”的例子。
b: 节点,边,全局属性用于特定任务的目的。编码-处理-解码体系结构。
c: 在顺序设置中应用编码-处理-解码体系结构,革新岁时间推移而展开,并在每个时间步骤中重复使用。合并为连接,分割行表示复制。
可组合多个块结构:
图到图的输入输出,即便内部配置不同,确保一个GN块输出可作为输入给另一个GN块,类似于深度学习中Tensor到Tensor的接口。如果排除全局u(聚合节点和边的信息),那么有这些节点和边决定可以访问的信息节点也会没有,同时,这也意味着把复杂的计算分解成更小的基本步骤,这些步骤还可用于捕获时间顺序性。
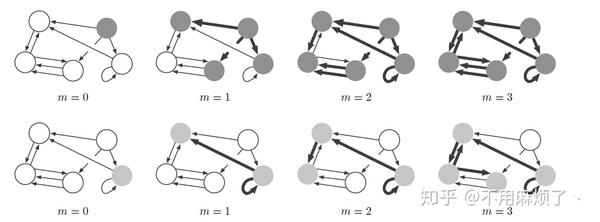

消息传递示例(example of message passing):
第一行:相关节点位于右上角,最下一行,兴趣节点在右下角。
最下一行:兴趣节点在右下角。
阴影节点:表示信息在m个传递步骤中与原始节点的距离。
粗体边:表示哪儿些信息可能传递。
图网络在代码中的执行 :与CNN相似,自然并行处理。也允许将几个独立的图进行计算打包在一起。与CNN相似,用于优化的函数的样本是所有训练图上的边和节点。在实践中∅e和∅v节点和边可以像小批处理机制那样来训练。
讨论:
论文主张使用一个未被完全建立成深度学习块,即图网络来在深度学习中建立强关系归纳偏差,在图形结构数据上进行计算。GNS非在系统水平上进行严格计算,可在整个关系中应用共享计算,也允许对从未见过的系统进行推理。
研究GN's组合归纳能力发现:GN's训练出来的预测单步物理状态可能会在未来的研究过程中出现,而且GN可在很多不同尺寸中泛化的很好。在现代人工智能中,采用显示结构和灵活学习室实现更好的样本效率和归纳的可行方法。
图网络的局限性 :不能区分某些非同构图;递归、控制流、条件迭代不能直接用图形标识。
拓展问题 :尽管图网络可能产生的潜在影响让人兴奋,但这些模型只是向前迈了一小步,实际上仍有很多问题没有得到解决。深度学习的一个特点,是能够对原始数据直接计算,但是将原始数据转化为图形一样的结构更好的方式仍然未知。
此外,许多底层图结构比全连通图要稀疏得多,如何引入这个稀疏性也是一个问题。虽然有人在探索这个问题,单目前未知还没有一种方法能可靠地从感观数据中提取离散实体,这在未来研究中是一个令人兴奋的挑战,一旦解决,将会为更强大、更可靠的推理算法打开大门。
如何在计算过程中自适应修改图形结构? 若一个对象分裂成多个部分,那么表示该对象的节点也应该分裂成多个节点。类似,只表示接处对象之间的边可能有用,需要根据上下文来添加或删除边。如何支持这种适应性的问题也正在被积极研究,特别是,一些用于识别图的地层结构方法可能还很适用。
人类的认知使得人们强烈认为,世界是由物体和关系组成的,GNs做出了类似的假设,它们的行为也比较容易解释。GNs操作实体和关系,对应于人类理解的事物,从而支持更多可解释分析和可视化。
未来工作的一个有趣方向是进一步探索图形网络行为的可解释性。
结论 :尽管进来深度学习的推动下,AI在许多重要领域都取得了突破性进展,但人类和机器间仍然存在巨大的鸿沟,尤其在高效、通用的学习方面。我们在这探索了灵活的学习方法,这些方法实现了强大的关系归纳偏差,利用显示结构表示和计算,并提出一个称为图网络的框架,该框架对应于图的神经网络中各种最近方法进行了归纳和扩展,图网络被设计为使用可定制的图到图的模块来构建复杂体系结构,它们的关系归纳偏差促进了组合泛化比其它标准机器学习构建块有更高的效率。尽管有如此多的好处与潜力,但在图形上操作科学系模型,知识通往AI的一块垫脚石,也许我们乐观过多,也许低估了许多学习方法和程序。
完事儿了~鄙人能力,程度有限,花了四天读完加整理,有错误只管挑,方便我纠正和学习~
