

用Python开发电影客户端

简介
本项目是用Python开发的影视客户端,具有增删改查、下载资源和数据可视化等功能。
本项目的主要技术步骤包括:
- 基于Python爬虫的数据获取:通过Python的Requests库和re库实现网络爬虫,获取数据。
- 基于Excel和Navicat的数据处理:使用Excel和Navicat对获取到的数据进行数据清洗、数据加工等数据处理。
- 基于PyQt的图形用户界面开发:使用PyQt库和Qt Designer进行图形用户界面开发,再用QSS对图形用户界面进行改善。
- 基于PyQt的数据操作与可视化:建立图形用户界面与后台数据库的连接,通过PyQt库操作数据库,实现客户端相关功能。
下面,首先展示客户端各功能的测试效果,再讲解各个技术步骤。目录如下:
- 各功能的测试效果
- 基于爬虫的数据获取
- 基于Excel和Navicat的数据处理
- 基于PyQt的图形用户界面开发
- 基于PyQt的数据操作与可视化
(阅读提示:若在浏览器上阅读,可使用Ctrl+F,输入相关章节标题,如“基于爬虫的数据获取”,快速定位到相应章节。)
1. 各功能的测试效果
客户端主要功能包括:浏览影库、条件查询、下载、增加影片、删除影片、可视化共6个功能。
1.1 测试环境
软件环境:Python 3.7.3,JetBrains PyCharm Edu 2019.1,Windows 10教育版
硬件环境:Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz 8GB RAM
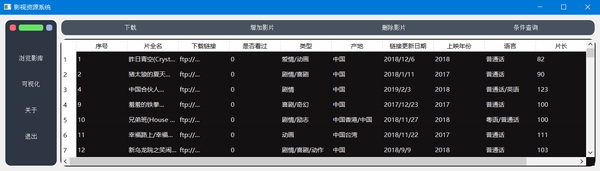
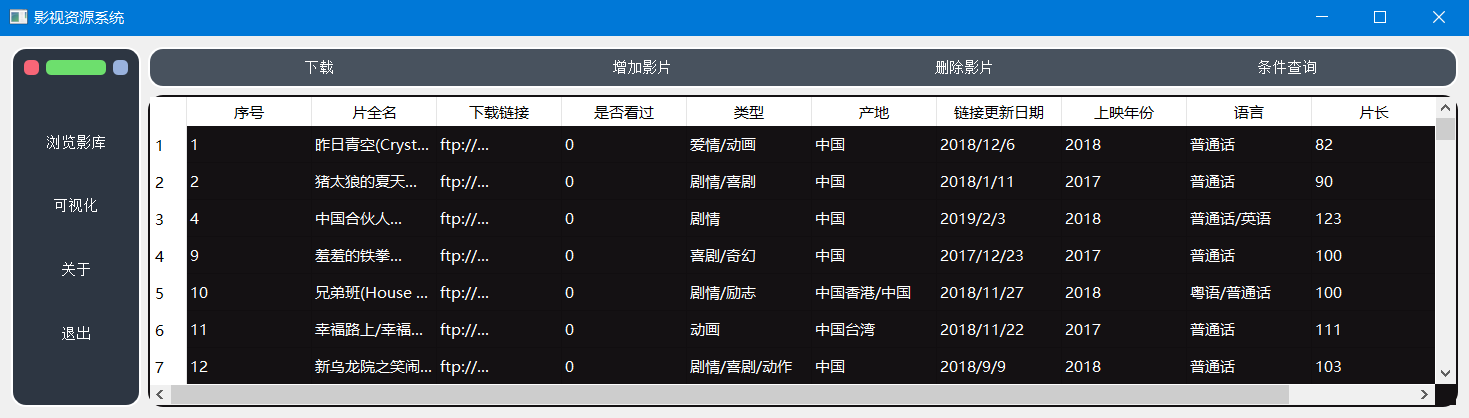
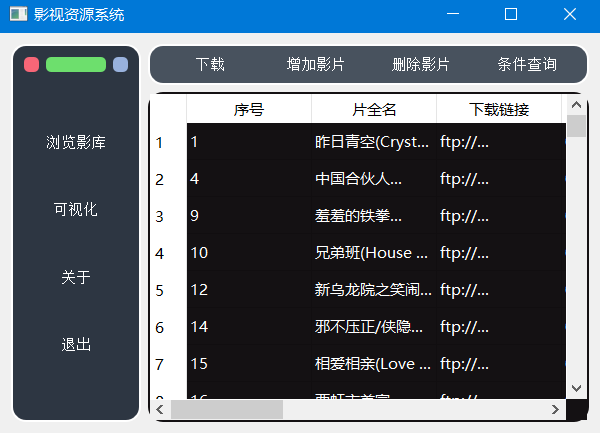
1.2 浏览影库
点击左侧菜单区的“浏览影库”按钮,可以在右下侧结果区看到数据库中所有影视数据的信息。浏览影库的效果如图所示:
1.3 条件查询
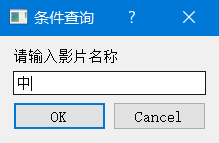
点击“条件查询”,将弹出输入对话框,用来获取用户输入。输入影片名称的相关信息,如“中”字,点击“OK”开始查询。输入对话框如图所示:
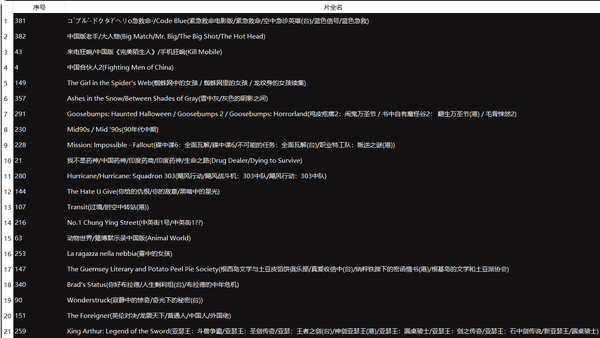
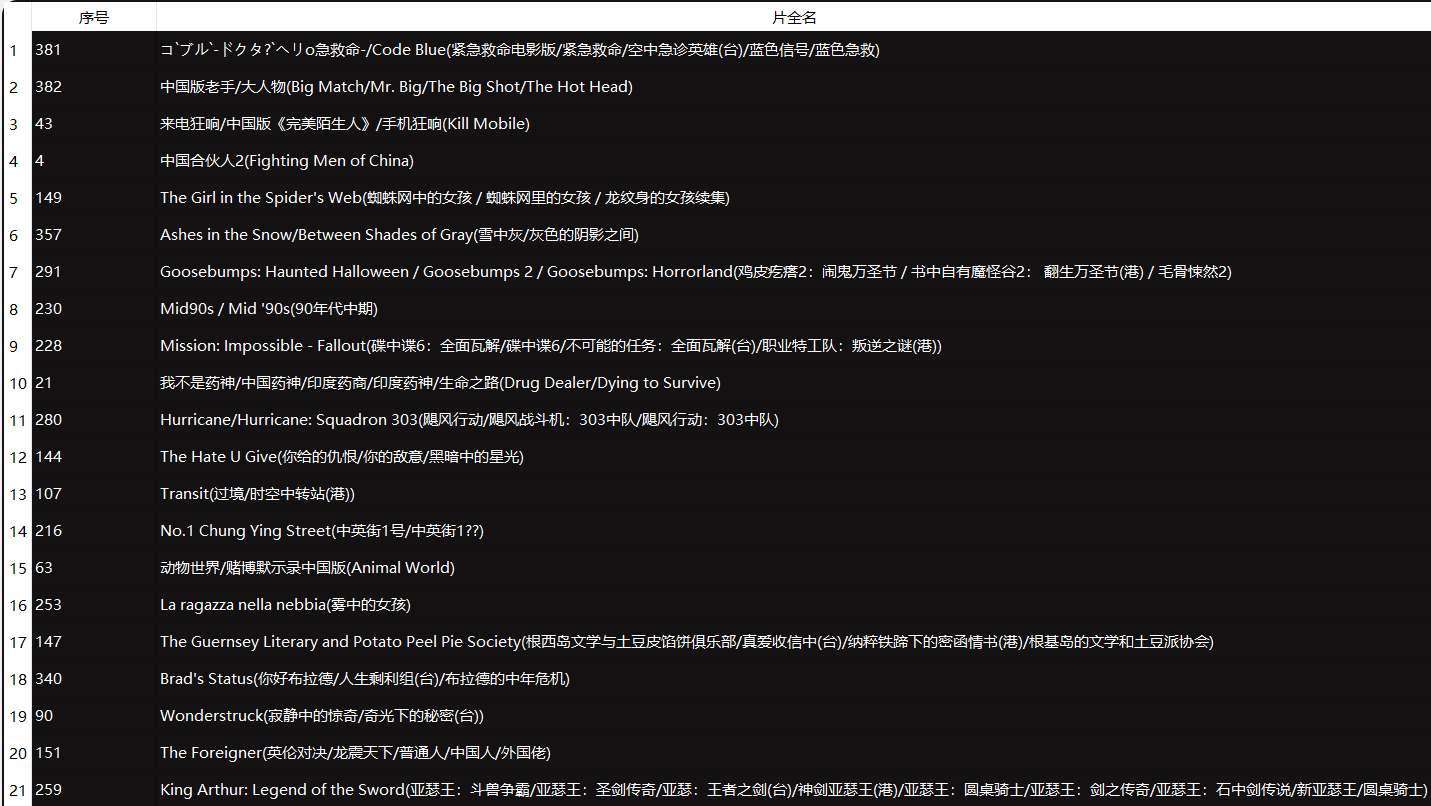
可以在结果区中看到“片全名”中包含“中”字的所有数据,如图所示:
1.4 下载
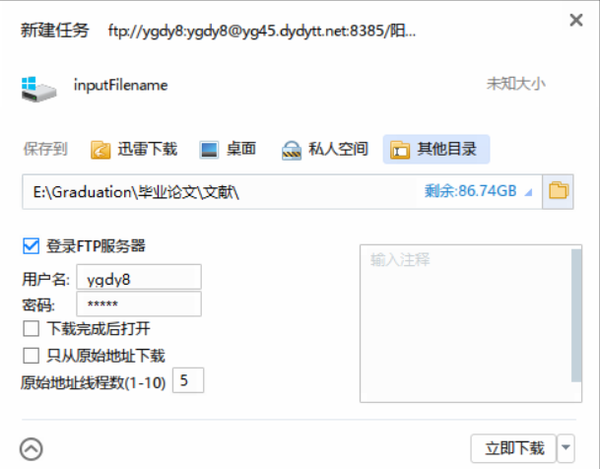
当用户复制下载链接后,点击下载按钮,可以调用迅雷进行影片下载。在迅雷程序下载界面中,可以设置影片文件名、存储路径等信息。下载界面如图所示:
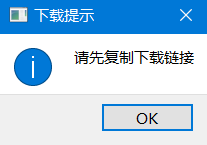
而当用户复制的内容不是下载链接时,客户端会弹框提示用户正确复制下载链接后,再使用下载功能。下载提示如图所示:
1.5 增加影片
当用户进行查询后,结果区会显示相应数据,此时用户可以将光标定位到结果区表格中的特定行,点击“增加影片”按钮,则会在该行前插入一行,用户可以输入符合数据表字段约束的影片数据。增加影片的效果如图所示:


1.6 删除影片
当用户进行查询后,结果区会显示相应数据,此时用户可以将光标定位到结果区表格中的特定行,点击“删除影片”按钮,则会删除该行,且操作不可撤消。被删除的行最前的列号会显示为感叹号,表示已删除影片。删除影片的效果如图 所示:


1.7 可视化
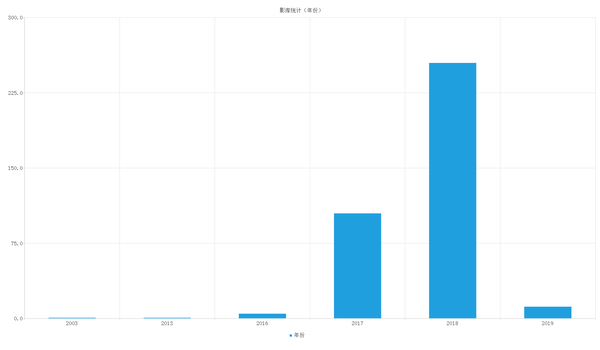
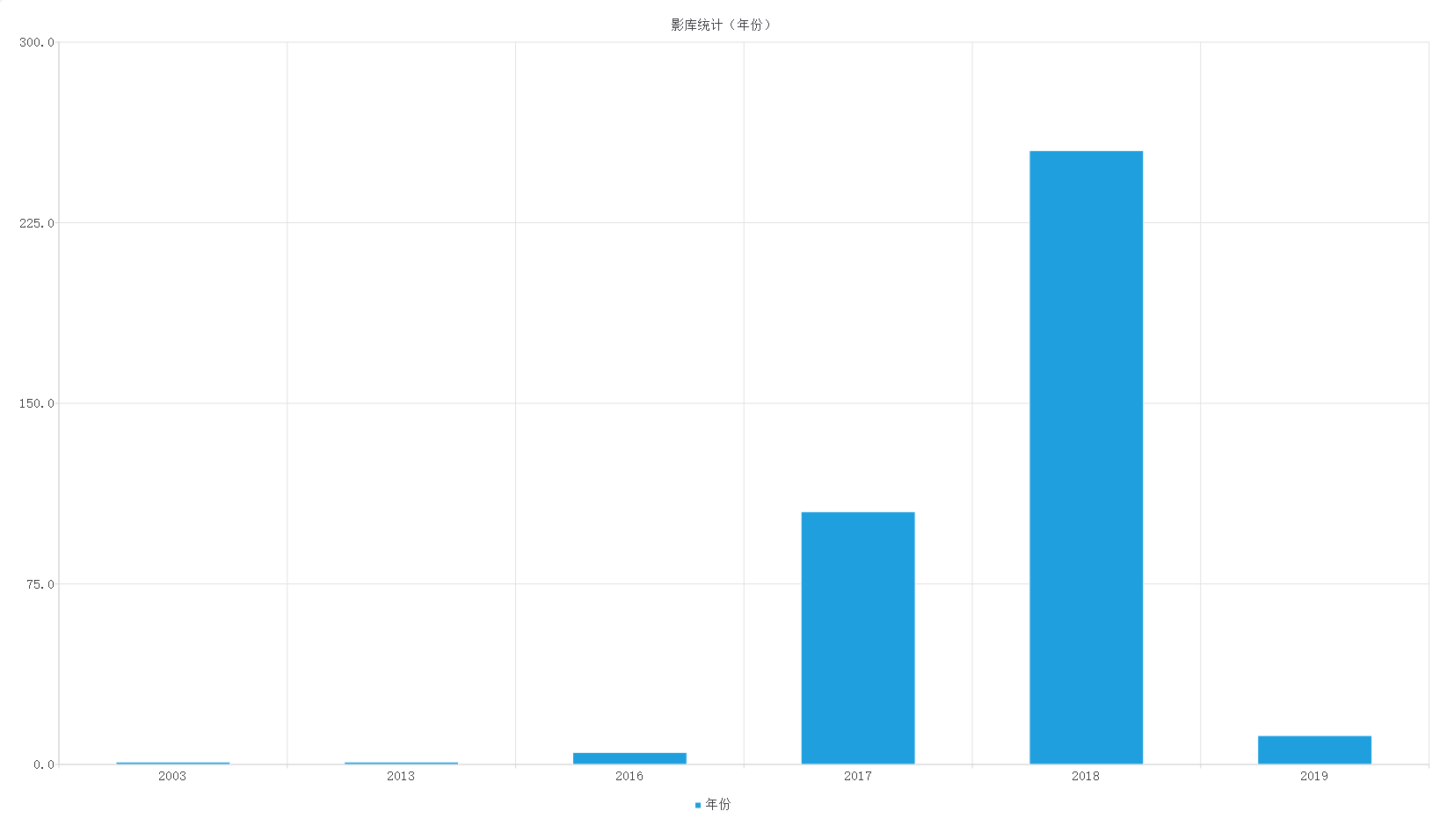
当用户点击“可视化”按钮,结果区会显示相应的图表,将数据库中的数据在某维度上的信息,通过可视化的图表形式呈现给用户。可视化的效果如图所示:
2. 基于爬虫的数据获取
本项目的数据来源是通过爬虫爬取电影网站“ 电影天堂 ”的“最新影片”模块收集的。
爬取单部影视作品的发布时间、译名、片名、年代、产地、类别、语言、片长和下载地址等数据。
爬虫的实现主要有3步:确定爬虫网址、定位数据和保存数据。
2.1 确定爬虫网址
通过研究网址的组成,可发现网址规律。
每页网址组成为: www.ygdy8.net/html/gndy/dyzz/list_23_ + 页码 + .html


单部电影网址后部分类似于:/html/gndy/dyzz/20190427/58502.html,可以通过增加“电影天堂”网址前部分“ www.ygdy8.net ”组装成完整的单部电影网址


2.2 定位数据每条电影网址
通过查看网页源代码和正则表达式re库匹配相应的数据。
以定位获取网页上“片名”的信息为例。首先进入到特定“电影详情页面”网址中,查看网页源代码,找到“片名”信息在网页源代码中的位置。以下图为例,例子如图所示:


图中可以看到“片名”信息为“◎片 名 How To Train Your Dragon: The Hidden World/How to Train Your Dragon 3 <br />”。于是可以通过正则表达式来定位获取“片名信息”,代码为:
re.findall('片 名 (.*?) <br />', html2.text)2.3 保存数据
爬取的数据会按序存放在movie_data列表中,再由writer对象的writerow方法,一行行地将movie_data列表中的元素写入csv(逗号分隔符)文件中,待后续进行数据处理,存入数据库中。具体代码如下:
writer.writerow(movie_data)2.4 爬虫的完整代码
import requests
import re
import csv
import datetime
# 计算程序运行所需时间
starttime = datetime.datetime.now()
# 'w' 表示只能写入(已存在的同名文件会被删除),utf-8解析电影数据的编码,newline=''避免写入时多余的空行
f = open('./data/movie_dytt5.csv', 'w', encoding='utf-8', newline='')
writer = csv.writer(f)
# 写入字段名:片名、译名、链接、类别、产地、发布时间、年代、语言、片长
movie_colum = ['origin_name', 'tran_name', 'link', 'category', 'place', 'link_time', 'year', 'language', 'length']
writer.writerow(movie_colum)
# 电影页数为193,时间截止为2019/4/15 15:17
for i in range(1, 194):
# 每页电影网址组成:http://www.ygdy8.net/html/gndy/dyzz/list_23_ + 1/2/3/... + .html
url = f"http://www.ygdy8.net/html/gndy/dyzz/list_23_{i}.html"
# requests.get() 返回 Response 对象
html = requests.get(url)
# gb2312网页编码,正确地获取网页数据
html.encoding = 'gb2312'
# findall方法用于匹配获取每页电影的后部分网址
# 每页电影的后部分网址格式形如:/html/gndy/dyzz/20190328/58369.html
data = re.findall('<a href="(.*?)" class="ulink">', html.text)
# 提示网络爬虫进度
print(f"正在获取第{i}页电影数据...")
for j in data:
# 构造每页电影的网址,访问相应的电影详情页面
url2 = f"http://www.ygdy8.net{j}"
html2 = requests.get(url2)
html2.encoding = 'gb2312'
# 获取相关电影字段数据,存入列表中
movie_data = re.findall('片 名 (.*?) <br />', html2.text)
movie_data.extend(re.findall('译 名 (.*?) <br />', html2.text))
movie_data.extend(re.findall('<a href="(.*?)">.*?</a></td>', html2.text))
movie_data.extend(re.findall('类 别 (.*?) <br />', html2.text))
movie_data.extend(re.findall('产 地 (.*?) <br />', html2.text))
movie_data.extend(re.findall('发布时间:(.*?) ', html2.text))
movie_data.extend(re.findall('年 代 (.*?) <br />', html2.text))
movie_data.extend(re.findall('语 言 (.*?) <br />', html2.text))
movie_data.extend(re.findall('片 长 (.*?) <br />', html2.text))
# 将电影数据写入csv文件中
writer.writerow(movie_data)
# 关闭文件,确保安全
f.close()
print(f"完成数据获取!")
# 程序运行结束计时
endtime = datetime.datetime.now()
print(f"程序运行时间为:{(endtime - starttime)}")3. 基于Excel和Navicat的数据处理
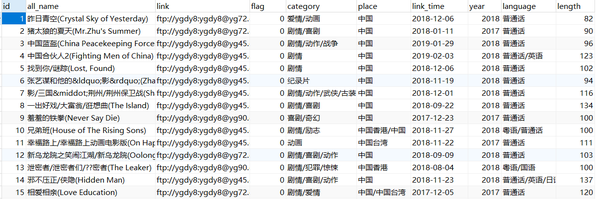
由于爬虫目标网页的不规范和爬虫策略的不足,导致获取的数据质量不高,存在诸如乱码、值错位、值缺失等问题。
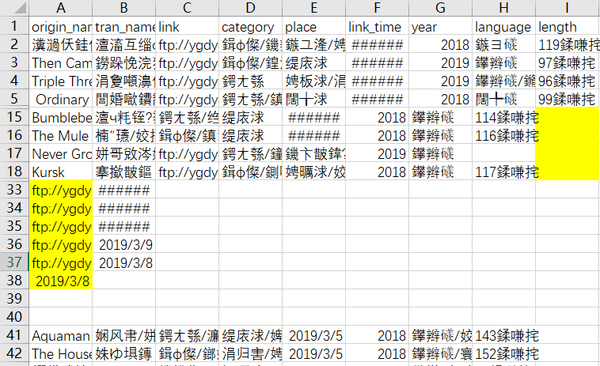
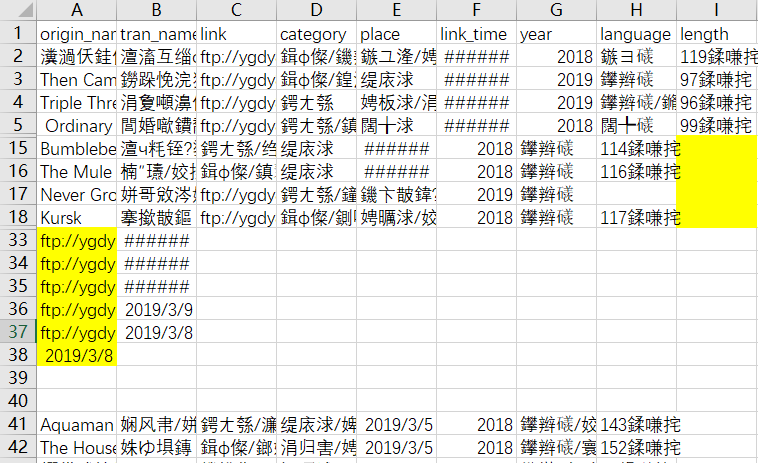
可用Excel进行数据清洗,删除空值行、错误值、重复值等,再用Navicat进行数据加工,导入数据库、合并字段、新增字段等。完成数据处理后的数据效果如下。

4. 基于PyQt的图形用户界面开发
Qt是一套跨平台的C ++库,提供大量访问桌面系统和移动系统的高级API。涉及到多个方面,如UI开发等。而PyQt是Qt的一套全面的Python绑定,能够用于图形用户界面的开发。
通过QtWidgets.QSplashScreen设置程序启动界面


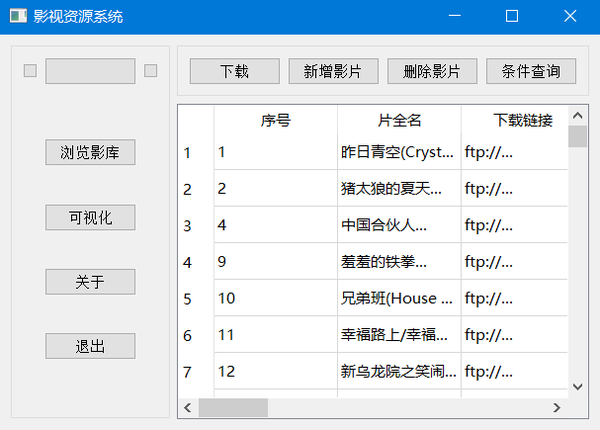
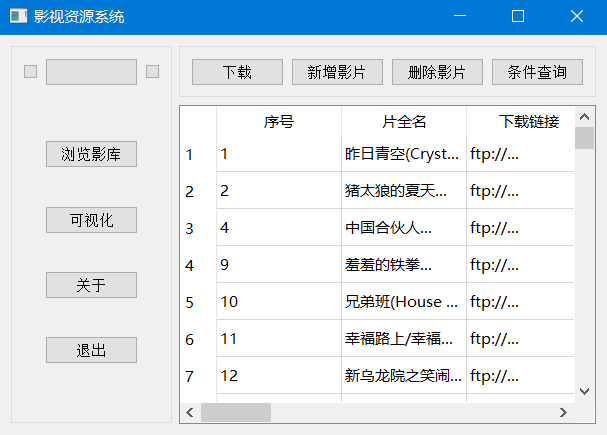
通过布局和组件设置,得到基本的程序主页界面
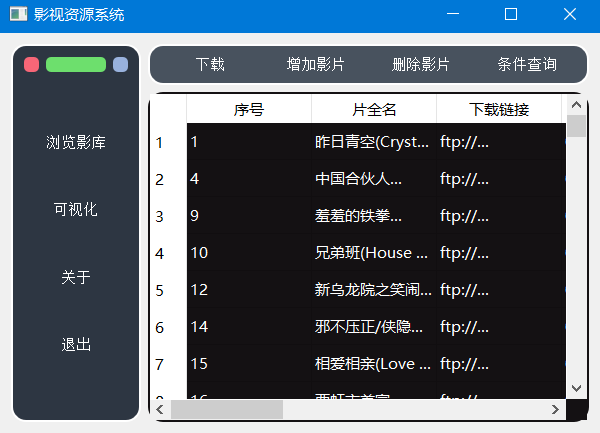
再通过类似CSS语言的QSS语言改善界面
5. 基于PyQt的数据操作与可视化
通过PyQt的QtSql模块,配置和连接本地数据库,再根据其MVC(Model–View–Controller)模式,实现增删改查功能。接着调用迅雷实现下载功能。最后用PyQt的QtChart模块来生成图表,展示数据。
5.1 配置和连接数据库
本项目使用PyQt5的QtSql来操作数据库,而这需要相应的数据库驱动,才能连接相应的数据库上,从而进行相关的数据库操作。由于本项目使用的数据库为MySQL,所以先将通过文件拷贝,将MySQL安装路径下相关文件配置到PyQt5相关安装路径。配置好后,便可以开始连接MySQL。确定数据库驱动名称,设置主机名称、数据库名称、用户名和密码:
def database(self):
db = QtSql.QSqlDatabase.addDatabase('QMYSQL')
db.setHostName('localhost')
db.setDatabaseName('moviedb')
db.setUserName('root')
db.setPassword('password')
5.2 增删改查功能
根据PyQt的MVC模式,可通过模型来操作数据,实现数据的增删改查功能。
创建Model,连接表
model = QtSql.QSqlTableModel()
table_widget.setModel(self.model)
model.setTable('movie_copy2')
model.insertRow(self.table_widget.currentIndex().row())
model.removeRow(self.table_widget.currentIndex().row())
model.setEditStrategy(QtSql.QSqlTableModel.OnFieldChange)
model.select()
model.setFilter(f"all_name Like '%{cond}%'")
5.3 下载功能
下载功能是通过监测剪切板的文本,当其满足一定条件后,可以调用迅雷程序进行下载。
监测剪切板文本
import win32clipboard as w
import win32con
def getText():
w.OpenClipboard()
d = w.GetClipboardData(win32con.CF_TEXT)
w.CloseClipboard()
return (d).decode('GBK')
调用迅雷下载
from win32com.client import Dispatch
def download(self):
url = getText()
# 若文本内容为下载链接则进行下载
if url and ('ftp:' in url) or ('magnet:' in url):
print('复制内容正确,可以开始下载')
# 调用迅雷,新建任务,提交执行任务
filename = 'inputFilename'
thunder = Dispatch('ThunderAgent.Agent64.1')
thunder.AddTask(url, filename)
thunder.CommitTasks()
5.4 数据可视化
数据可视化是指通过可视化的方式,如图表等,展示数据库中数据的某些维度的信息。通过PyQt5的QtSql模块来读取数据,再用QtChart模块来生成图表,展示数据。
首先通过QtSql.QSqlQuery 装载SQL语句,进行查询。再通过遍历查询结果,将数据存在列表,作为图表的数据源。
然后通过QtChart.QBarSet和QtChart.QBarSeries设置图表的数据源,再用QtChart.QChart制作图表,再通过QChartView显示在图形用户界面上。
数据库中各影片的“年份”分布情况如图:
def visualization(self):
# 查询部分
query = QtSql.QSqlQuery()
col_name = 'year'
# 调用exec()函数后QSqlQuery的内部指针位于第一个记录的前一个位置
# 查询得到year字段值:有多少种、每种多少个
query.exec(f'Select {col_name}, Count(id) As count From movie_copy2 Group By {col_name} Order By {col_name}')
kind_list = []
num_list = []
# 在访问第一条记录之前必须要调用QSqlQuery::next()
while query.next():
v1 = query.value(0) # int print(type(v1))
v2 = query.value(1) # int
# print(f'{v1} {v2}') # sql语句结果
# kind_list 用作坐标轴的分组标签名,故为str类型
kind_list.append(str(v1))
# numList 用作QBarSet数据集,要求为float类型(float高于int)
num_list.append(v2)
# 打印列表情况,后续用于组装数据集
print(kind_list)
print(num_list)
# 图表部分
# 查询列名(面向用户)
setName = '年份'
# 数据系列:数据集赋值
# QBarSet对象类型为float
set0 = QBarSet(setName)
set0.append(num_list)
# 用系列来控制数据集,可将数据集分配到不同的组(另一个类别)
# The series groups the data from sets to categories.
series = QBarSeries()
series.append(set0)
# 图表区域
self.chart = QChart()
self.chart.addSeries(series)
self.chart.setTitle(f'影库统计({setName})')
# 启动时动画
self.chart.setAnimationOptions(QChart.SeriesAnimations)
# 数据系列:类别赋值
categories = kind_list
# 横坐标轴:categories数据
axisX = QBarCategoryAxis()
axisX.append(categories)
# 添加横坐标轴到图表区域,设置居底对齐
self.chart.addAxis(axisX, Qt.AlignBottom)
# 添加坐标轴到系列中
series.attachAxis(axisX)
# 纵坐标轴
axisY = QValueAxis()
# 纵坐标轴取值范围
axisY.setRange(0, 300)
self.chart.addAxis(axisY, Qt.AlignLeft)
series.attachAxis(axisY)
# 显示图例
self.chart.legend().setVisible(True)
self.chart.legend().setAlignment(Qt.AlignBottom)
# 将图表添加到视图
self.chartView = QChartView(self.chart)
# 视图的抗锯齿效果
self.chartView.setRenderHint(QPainter.Antialiasing)