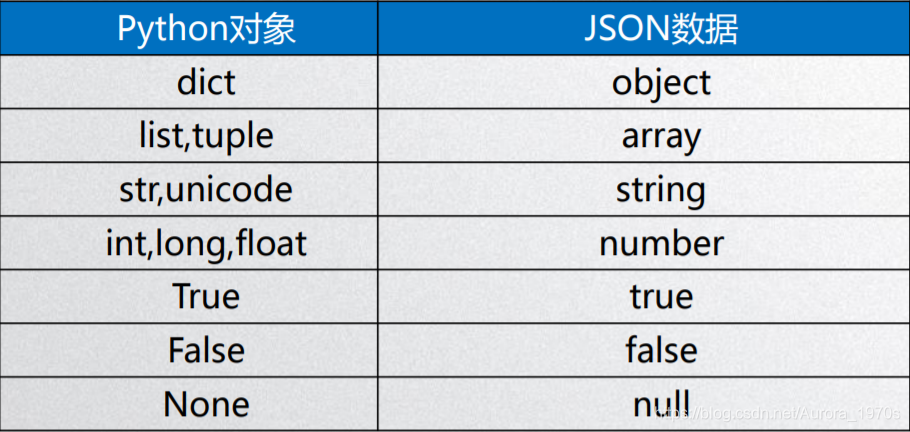
import json
f=open('src_1111.json','r',encoding='utf-8')
ls=json.load(f)
print(ls)
f.close()
t=[list(ls[0].keys())]
print(t)
for line in ls:
t.append(list(line.values()))
print(t)
f2=open('src_7777.csv','w',encoding='utf-8')
for line in t:
f2.write(','.join(line)+'\n')
f2.close()
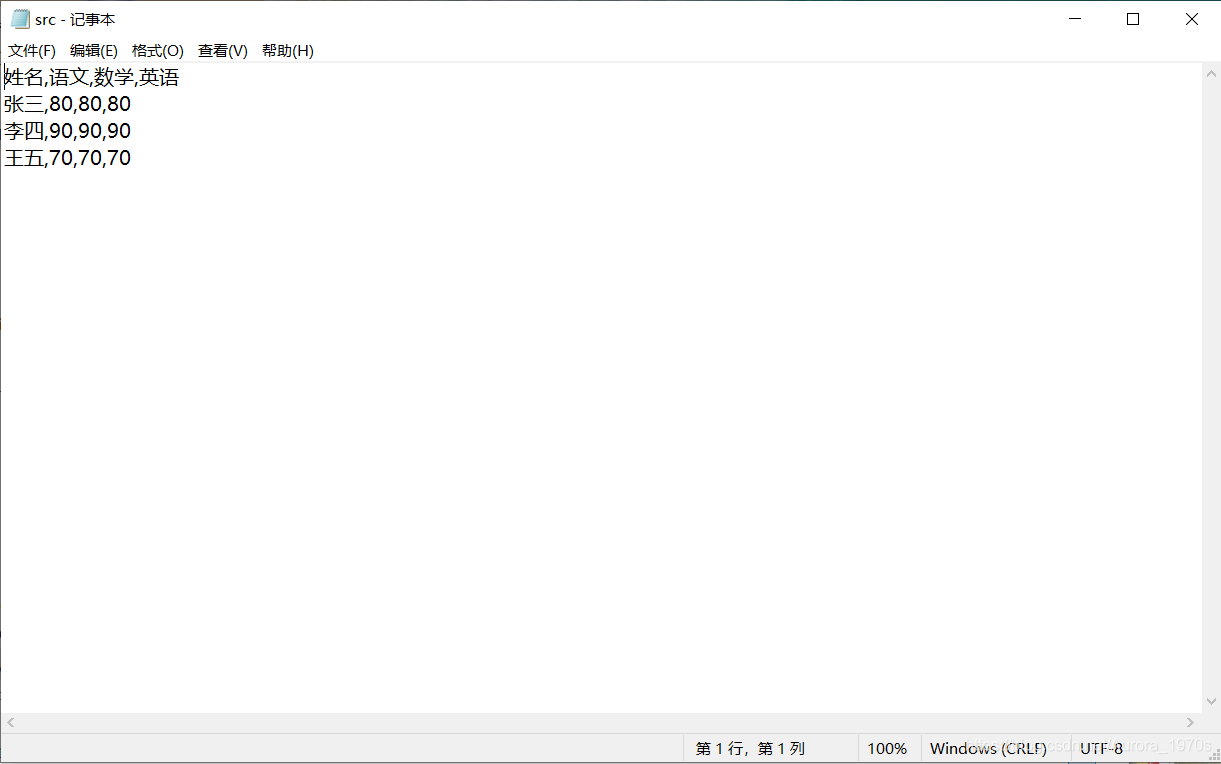
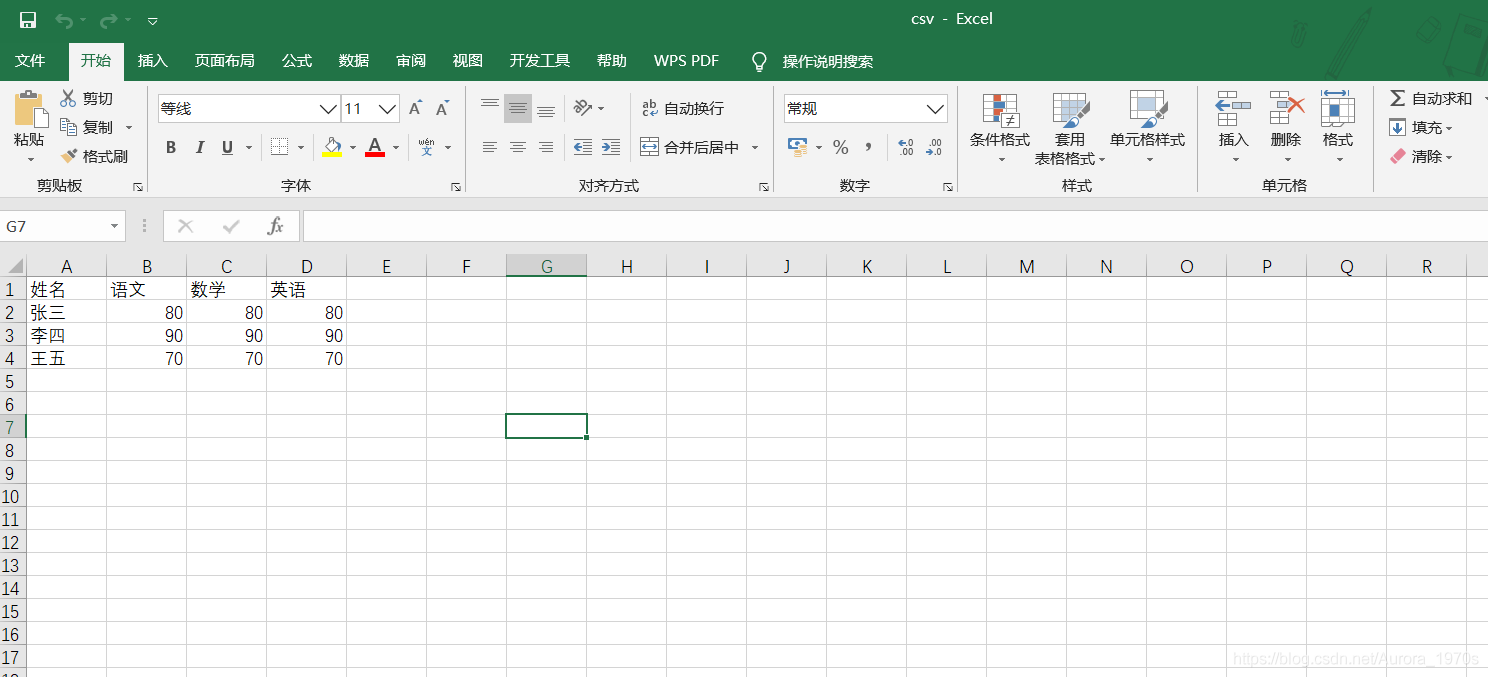
运行之后生成的CSV文件:
姓名,语文,数学,英语,总分
张三,80,80,80,240
李四,90,90,90,270
王五,70,70,70,210
Python保险客户办理数据集csv 将其中的json字符串转换为dataframe格式化处理 case_id,event,timestamp,payload,aggregate_type
125044,claim,2020-09-06 00:01:00.277,"{'person': {'relation': 'self'}, 'incident': {'incident_scene': 'work', 'date_of_incident': '2018-02-05', 'time_of_incident': '10:30:00'}, 'occupation': {'occupation': 'employee'}}",case
case_id,event,timestamp,payload,aggregate_type
125044,connected_to_customer,2021-02-18 19:51:09.219,{'customerId': 'ec40fad4-bc74-4774-8a2c-ba92c57191b4' numpy pandas 数据分析 数据挖掘
最近分析一套数据,是csv格式的数据,必须是python分析数据比较顺手啊,于是研究一下csv模块,由于py的版本问题,3的资料中文的很少,所以记录一下,方便以后的学习。
点击打开链接
上面的链接是python官网给的文档,英语好的建议看原版。
一、读部分
没有什么改动,记录几个常用的reader提供的方法,方便数据规整化:
filepath=sys.argv[1]
CSV(逗号分隔值)和JSON(JavaScript对象表示法)是常用的数据交换格式,在Python中处理它们非常方便。CSV通常用于存储表格数据,而JSON则用于结构化数据的表示和传输。Python提供了强大的库和模块来处理CSV和JSON数据。希望这些资源能够帮助您更好地理解和掌握CSV和JSON数据的处理方法。如果您需要更详细的教程和代码示例,请参考上述资源链接中的具体章节和示例代码。
在神经网络训练过程中,常常需要监视各种指标,用来后期优化模型。控制台打印,如果没有自定义回调并且训练周期过长会导致查找起来比较费劲;绘图的方式虽然直观,但是不能得到准确的数值。所以为了格式化输出,方便查看,将各类指标保存到CSV文件中。
CSV(Comma-Separated Values)即逗号分隔值,可以用Excel打开查看。由于是纯文本,任何编辑器也都可打开。与Excel文件不同,CSV文件中:值没有类型,所有值都是字符串不能指定字体颜色等样式不能指定单元格的宽高,不能合并单元格没有多个工作表不能嵌入图像图表Python内置的csv模块,负责处理csv格式数据,其官方如下:官方文档1.1.reader/writer处理csv...
1、CSV文件要在文本文件中存储数据,最简单的方式是将数据作为一系列以逗号分隔的值(CSV)写入文件,这样的文件称为CSV文件。2、分析CSV文件头1)调用csv.reader()将存储的文件对象作为实参传递给它,从而创建一个与文件相关联的阅读器对象。模块csv包含函数next(),调用它并将阅读器对象传递给它时,它将返回文件中的下一行。import csvfilename="sitka_weath
I am creating a very rudimentary "Address Book" program in Python. I am grabbing contact data from a CSV file, the contents of which looks like the following example:Name,Phone,Company,EmailElon Musk...
<br /> <br />1. 行列转换--普通 <br />假设有张学生成绩表(CJ)如下 <br />[姓名] [学科] [成绩]<br />张三 语文 80 <br />张三 数学 90 <br />张三 物理 85 <br />李四 语文 85 <br />李四 数学 92 <br />李四 物理 82<br />王五 数学 60<br />想变成 <br />[姓名] [语文] [数学] [物理]<br
数据如下图:用python对数据进行处理:#读取csv文件内容并进行数据处理import osimport csvimport datetimeimport refrom itertools import islicecsv_file_path = 'query_hive.csv' #文件路径write2_csv_file_path = 'hive_result2.csv' #处理第二列数据wr...
grade1={'李四':60,'张三':70,'王二':80,'麻子':90,'无无':100}
grade2={'李四':60,'张三':70,'王二':80,'麻子':90}
grade3={'张三':60,'王二':70,'麻子':80,'无无':90}
gradelist = [grade1,grade2,grade3]
names = []#存储姓名
grade = {}#存储所有人的...