现在我们对Elasticsearch有些了解,现在我们来了解下它的API,Elasticsearch提供了一个REST API,是通过HTTP访问JSON
注意:学到这里相信大家对ES的交互有了足够的了解,所以下面为了文章的简洁性,我将不再列出
Curl
命令。
为了方便演示我们再重新创建一些索引
POST /_bulk
{"create":{"_index":"othermovies","_type":"doc","_id":"1"}}
{"title": "复仇者联盟4","director": "安东尼·罗素","year": 2019,"genres": ["科幻","动作"],"actors": ["小罗伯特·唐尼","克里斯·埃文斯","娜塔丽·波曼"]}
{"create":{"_index":"othermovies","_type":"doc","_id":"2"}}
{"title": "爱在记忆消失前","director": "保罗·维尔奇","year": 2017,"genres": ["剧情"],"actors": ""}
{"create":{"_index":"othermovies","_type":"doc","_id":"3"}}
{"title": "肥猫流浪记","director": "曹建南","year": 1988,"genres": ["剧情"], "actors": "郑则仕"}
大多数引用index参数的API都支持使用index1,index2,index3简单的表示方法来对索引进行操作
例如,我们查询了索引movies和othermovies中的包含爱在的文档信息:
POST /movies,othermovies/_search
"query": {
"match": {
"title": "爱在"
通过响应消息知道我们成功匹配出了爱在日落黄昏时 和爱在记忆消失前。
它还支持通配符,例如:test*或*test或te*t或*test*
我们这里只同匹配moives即可,如:
POST /*movies/_search
"query": {
"match": {
"title": "流浪"
匹配出了流浪地球 和肥猫流浪记
它还支持“排除”(-)的能力,例如:test*,-test3。
注意: - 必须和 * 一块使用
POST /*movies,-othermovies/_search
"query": {
"match": {
"title": "仇"
只匹配到了V字仇杀队
如果URL中一个或多个索引不存在的时候,是否忽略这些索引,值为true和false,默认为true。
例如,classicmovies索引存在,但comedymovies不存在。
首先我们来执行下没有ignore_unavailable参数的
POST /movies,comedymovies/_search
"query": {
"match": {
"query": "西游"
响应信息:
"error": {
"root_cause": [
"type": "index_not_found_exception",
"reason": "no such index",
"resource.type": "index_or_alias",
"resource.id": "comedymovies",
"index_uuid": "_na_",
"index": "comedymovies"
"type": "index_not_found_exception",
"reason": "no such index",
"resource.type": "index_or_alias",
"resource.id": "comedymovies",
"index_uuid": "_na_",
"index": "comedymovies"
"status": 404
我们从响应信息可以看出查询报错了。
接下来我们添加上ignore_unavailable 参数,并且指定为true值防止错误。
POST /movies,comedymovies/_search?ignore_unavailable=true
"query": {
"query_string": {
"query": "西游"
命令执行成功
当使用通配符查询时,当有索引不存在的时候是否返回查询失败。值为true和false,默认为true.
allow_no_indices 跟 ignore_unavailable 都是用来防止没有索引的错误的,它们的区别是:
ignore_unavailable控制的是任何索引包括带通配符和不带通配符的,
allow_no_indices 控制的是带通配符的索引。
例如,不是以act开头的索引
我们使用false 值来执行一遍看看
POST /oth1er*/_search?allow_no_indices=false
"query": {
"query_string": {
"query": "西游"
设为true查看下执行情况
POST /oth1er*/_search?allow_no_indices=true
"query": {
"match": {
"query": "西游"
经过我多次测试发现,使用了\* 通配符,即使不添加allow_no_indices=true 参数也能成功执行,所以我怀疑es默认添加了allow_no_indices=true,但是目前我在文档上没有查找到这个说明。
设置是否扩展通配符到closed的index中,open表示只在匹配并为open的index中查询,closed表示在匹配的所有的index中查询, 默认为closed
值为open,close,none,all。
| 值 | 说明 |
|---|
| open | 表示只支持open类型的索引 |
| close | 表示只支持关闭状态的索引 |
| none | 表示不可用 |
| all | 表示同时支持open和close索引 |
现在我们来关闭othermovies这个索引
POST /othermovies/_close
现在我们来查询这个索引看看
GET /othermovies/moive/1
我们可以查看到,这个索引已经被关闭 "reason":"closed"
下面我们使用expand_wildcards=closed 来查询看看
GET /*movies/_search?expand_wildcards=close
结果错误,提示没有有效的扩展通配符值
下面我们使用expand_wildcards=open 来查询看看
curl -H "Content-Type: application/json" -GET 'http://localhost:9200/*movies/_search?expand_wildcards=open'
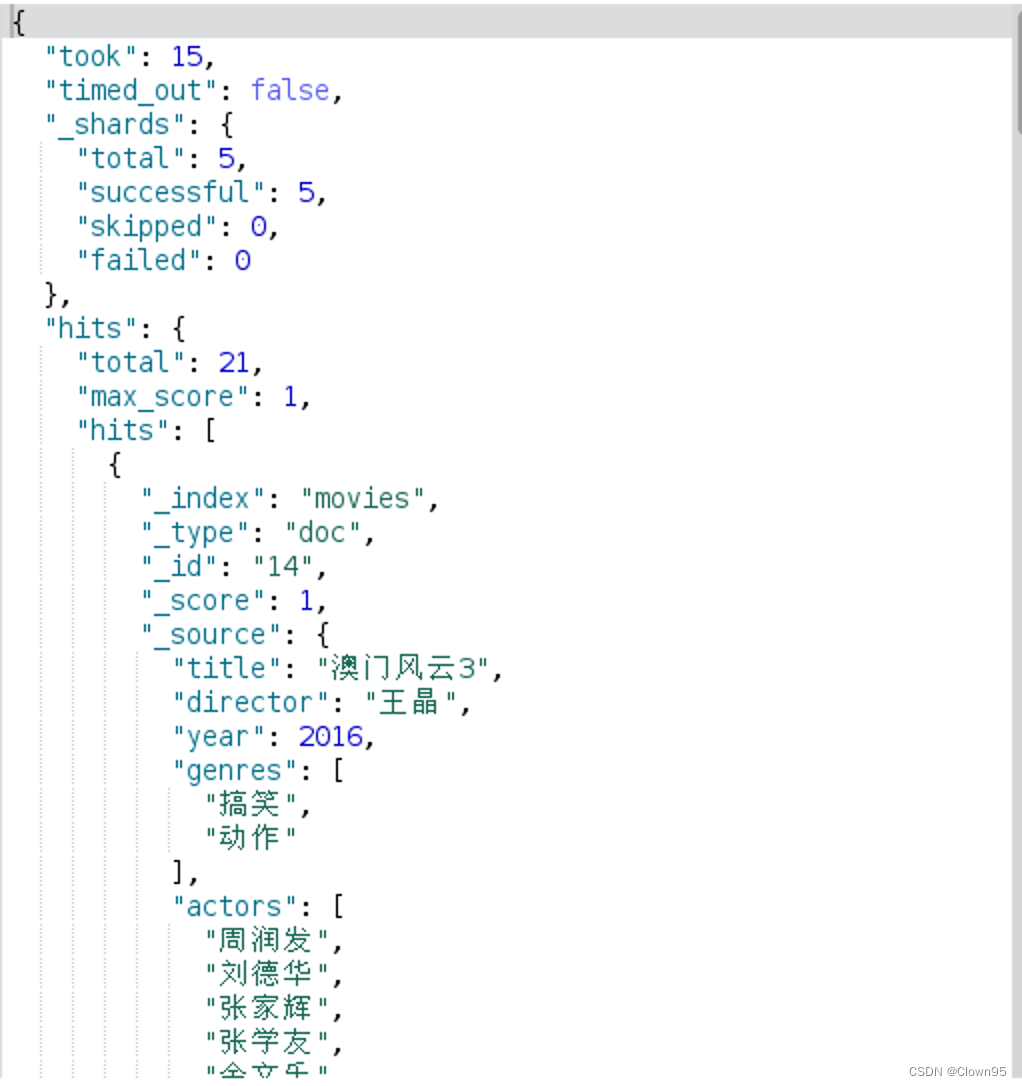
我们可以看到匹配到了其他的索引。
format: 表示返回数据的格式, 可选值为yaml和json两种。
首先我们返回json格式:
GET /movies/doc/1?format=json
响应信息:
"_index": "movies",
"_type": "doc",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"title": "大话西游",
"director": "刘镇伟",
"year": 1994,
"genres": [
"喜剧",
"爱情",
"actors": [
"周星驰",
"朱茵",
"吴孟达",
"罗家英",
"蓝洁瑛",
"莫文蔚"
接着我们看下yaml格式的:
GET /movies/doc/1?format=yaml
响应信息:
_index: "movies"
_type: "doc"
_id: "1"
_version: 1
found: true
_source:
title: "大话西游"
director: "刘镇伟"
year: 1994
genres:
- "喜剧"
- "爱情"
- "魔幻"
actors:
- "周星驰"
- "朱茵"
- "吴孟达"
- "罗家英"
- "蓝洁瑛"
- "莫文蔚"
pretty 漂亮的结果,表示在已json格式返回数据时是否以可视化的格式返回, false或未在设置表示不格式化, 否则格式化。
这个必须使用 Crul命令来查看, 因为kibana会帮我们自动格式化,体现不出来效果。
首先我们看下不加pretty=false的:
curl -XGET 'http://localhost:9200/movies/doc/1?pretty=false'
响应信息:
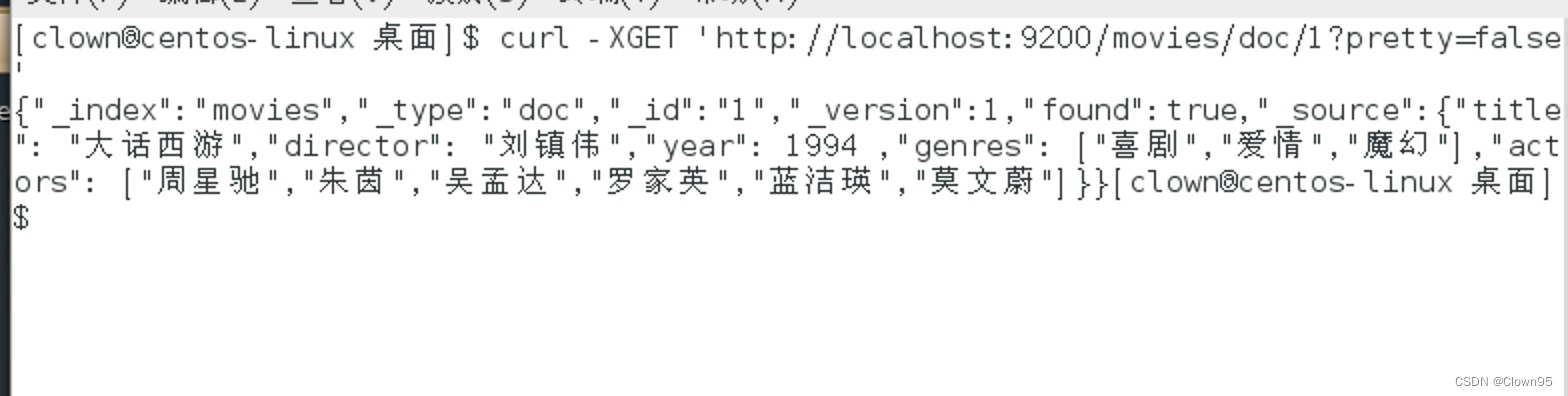
可以看到如果pretty=false 是以压缩形式显示的,对阅读照成一定的难度。
再来看下pretty=true的:
curl -XGET 'http://localhost:9200/movies/doc/1?pretty=true'
响应信息:
可以看到我们得到了一个格式化的json信息。
查询结果过滤,主要使用filter_path参数进行设置
比如说我们只需要 took, hits.total, hits.hits._id, hits._source
curl -XGET 'http://localhost:9200/movies/doc/_search?filter_path=took,hits.total,hits.hits._id,hits.hits._source'
比如说我们需要查询节点信息,但是节点信息很多。
我们可以使用通配符,例如:
curl -XGET 'http://localhost:9200/_nodes/stats?filter_path=nodes.*.*ost*,nodes.*.os.*u&pretty=true'
响应消息:
"nodes": {
"g1nsooFJSAiopLEAfxBnhA": {
"host": "10.211.55.8",
"os": {
"cpu": {
"percent": 4,
"load_average": {
"1m": 0.26,
"5m": 0.15,
"15m": 0.15
filter_path 暂时说到这里,如果你需要了解更多的用法可以查看官方文档。
日期筛选可以限定时间序列索引的搜索范围,而不是搜索全部内容,通过时间限定,可以从集群中减少搜索的内容,提高搜索效率和减少资源占用。例如只搜索最近两天的错误日志。
几乎所有的API都支持日期筛选。
日期筛选的语法为:
<static_ name{date_ math_ expr{date_ format |time_ zone}}>
语法解释:
- static_ name:索引的名称;
- date_ math_ expr: 动态日期计算表达式;
- date_ format:日期格式;
- time_ zone: 时区,默认为UTC。
curl -XGET 'http://localhost:9200/<*moives-{now/d}>/_search'
表达式说明:
| 表达式 | 解析 |
|---|
| <logstash-{now/d}> | logstash-2024.03.22 |
| <logstash-{now/M}> | logstash-2024.03.01 |
| <logstash-{now/M{YYYY.MM}}> | ogstash-2024.03 |
| <logstash-{now/M-1M{YYYY.MM}}> | logstash-2024.02 |
| <logstash-{now/d{YYYY.MM.dd|+12:00}}> | logstash-2024.03.23 |
时间搜索也可以通过逗号,来选择多个时间,例如,选择最近三天的数据。
当多用户通过URL访问Elasticsearch索引的时候,为了防止用户误删除等操作,可以通过基于URL的访问控制来限制用户对某个具体索引的访问。在elasticsearch.yml配置文件中添加参数:
rest.action.multi.allow_explicit_index: false
这个参数默认为true。当该参数为false时,在请求参数中指定具体索引的请求将会被拒绝。
title: ElasticSearch(四) API 约定tags: ElasticSearchauthor: Clown95API 约定现在我们对Elasticsearch有些了解,现在我们来了解下它的API,Elasticsearch提供了一个REST API,是通过HTTP访问JSON注意:学到这里相信大家对ES的交互有了足够的了解,所以下面为了文章的简洁性,我将不再列出C......
expand_wildcards
设置是否扩展通配符到closed的index中,open表示只在匹配并为open的index中查询,closed表示在匹配的所有的index中查询, 默认为closed。
值为open,close,none,all。
open:表示只支持open类型的索引
close:表示只支持关闭状态的索引
none:表示不可用
all:表示同时支持open和close索引
allow_no_indices
当使用通配符查询时,当有索引不存在的时候是否返回查询失败
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/multi-index.html
官网文档其实很详细的,大家可能没有时间或精力去详细的阅读。
目前最新的是7.10,我使用的版本是7.8。
多目标语法
大部分使用, , 的请求都支持多目标语法。
例如,我们可以传递多个索引: test1,test2,test3,也可以使用通配符(*)去匹配符合条件的目标,比如 test* 或者 *test 或者 te*t
提起es的Update By Query很多人一定也不陌生,它对应的就是关系型数据库的update set ... where...语句,这对应一般的存储引擎而言算是最基本的功能,但它的坑确不少,多到让你使用起来很奔溃,比如批量更新时非事务模式执行(允许部分成功部分失败)、大批量操作会超时、频繁更新会报错(版本冲突)、脚本执行太频繁时又会触发断路器等。
1. 非事务模式执行
在前面update...

