def forward(self, emb1, emb2, label):
if self.normalize_feature:
# equal to cosine similarity
emb1 = F.normalize(emb1)
emb2 = F.normalize(emb2)
mat_dist = euclidean_dist(emb1, emb1)
assert mat_dist.size(0) == mat_dist.size(1)
N = mat_dist.size(0)
mat_sim = label.expand(N, N).eq(label.expand(N, N).t()).float()
dist_ap, dist_an, ap_idx, an_idx = _batch_hard(mat_dist, mat_sim, indice=True)
assert dist_an.size(0)==dist_ap.size(0)
triple_dist = torch.stack((dist_ap, dist_an), dim=1)
triple_dist = F.log_softmax(triple_dist, dim=1)
if (self.margin is not None):
loss = (- self.margin * triple_dist[:,0] - (1 - self.margin) * triple_dist[:,1]).mean()
return loss
mat_dist_ref = euclidean_dist(emb2, emb2)
dist_ap_ref = torch.gather(mat_dist_ref, 1, ap_idx.view(N,1).expand(N,N))[:,0]
dist_an_ref = torch.gather(mat_dist_ref, 1, an_idx.view(N,1).expand(N,N))[:,0]
triple_dist_ref = torch.stack((dist_ap_ref, dist_an_ref), dim=1)
triple_dist_ref = F.softmax(triple_dist_ref, dim=1).detach()
loss = (- triple_dist_ref * triple_dist).mean(0).sum()
return loss
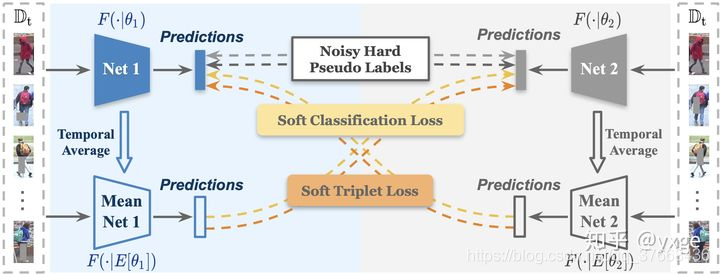
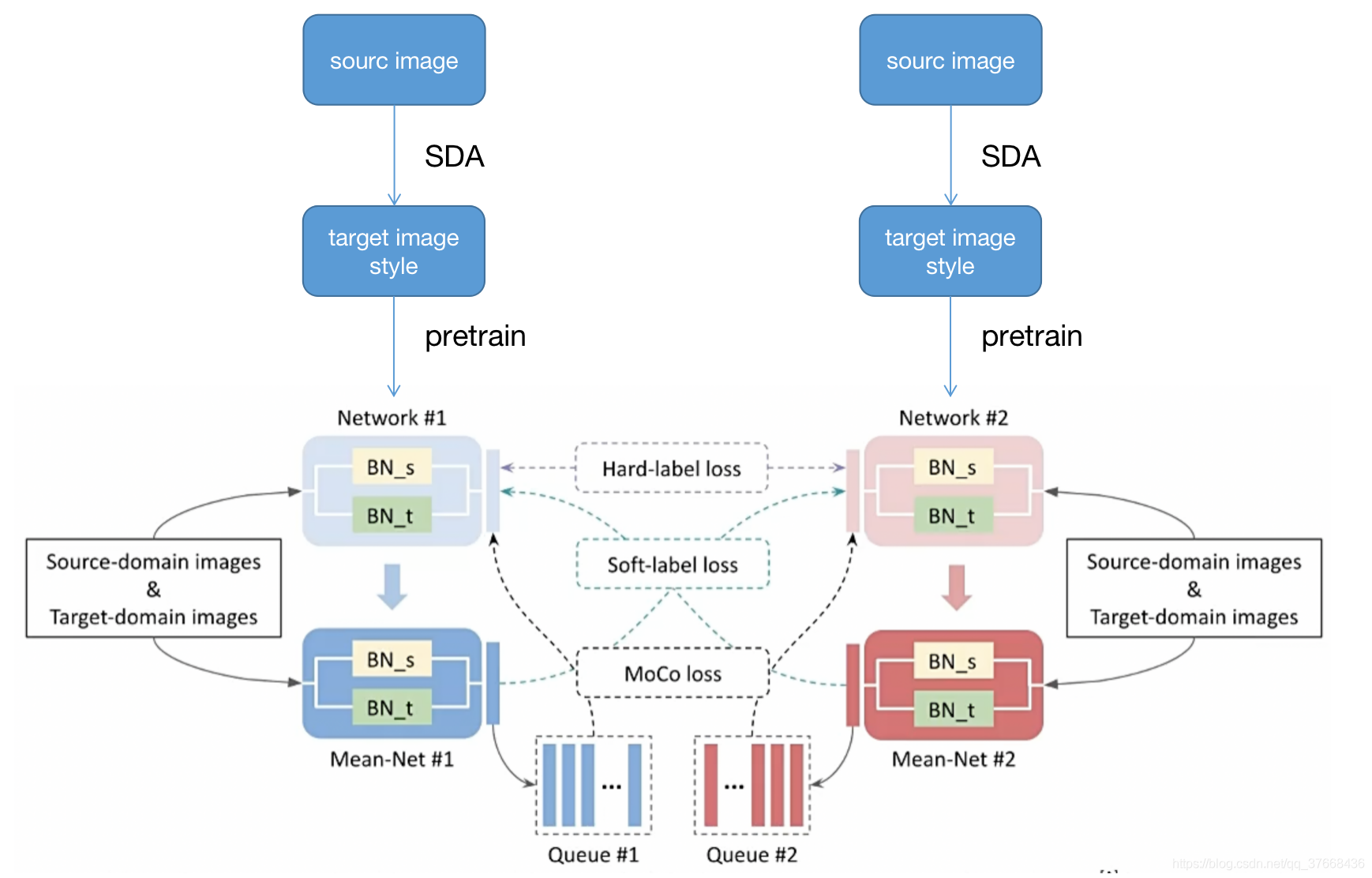
作者首先根据是否有margin来判断输出是Net1或者Net2编码特征的三元损失还是MeanNet编码特征与Net编码特征的三元损失的结合。
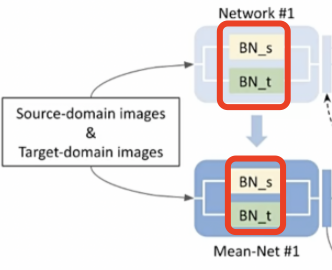
该函数的输入:em1是Net1或者Net2编码的特征,em2是对称的Mean Net的编码的特征,label是聚类的硬标签。
这一行代码:dist_ap, dist_an, ap_idx, an_idx = _batch_hard(mat_dist, mat_sim, indice=True)
是根据硬标签和em1的距离矩阵得到每个特征与正样本距离最大的正样本的索引与负样本距离最小的索引同时计算了这些样本的距离矩阵。就是找到了对应的最难的正负样本。
triple_dist = F.log_softmax(triple_dist, dim=1)计算了Net1或Net2输出特征根据硬标签的三元损失。
同理下面一段:triple_dist_ref = F.softmax(triple_dist_ref, dim=1).detach()计算了MeanNet1或MeanNet2输出特征根据硬标签的三元损失。
最后的loss为两者相乘:loss = (- triple_dist_ref * triple_dist).mean(0).sum()




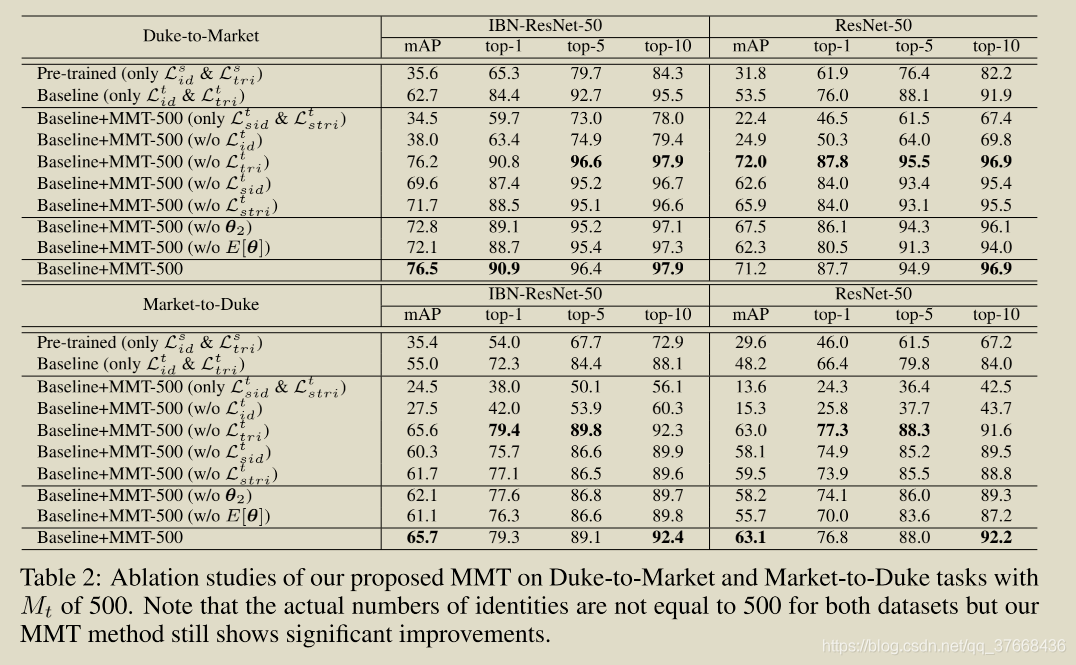
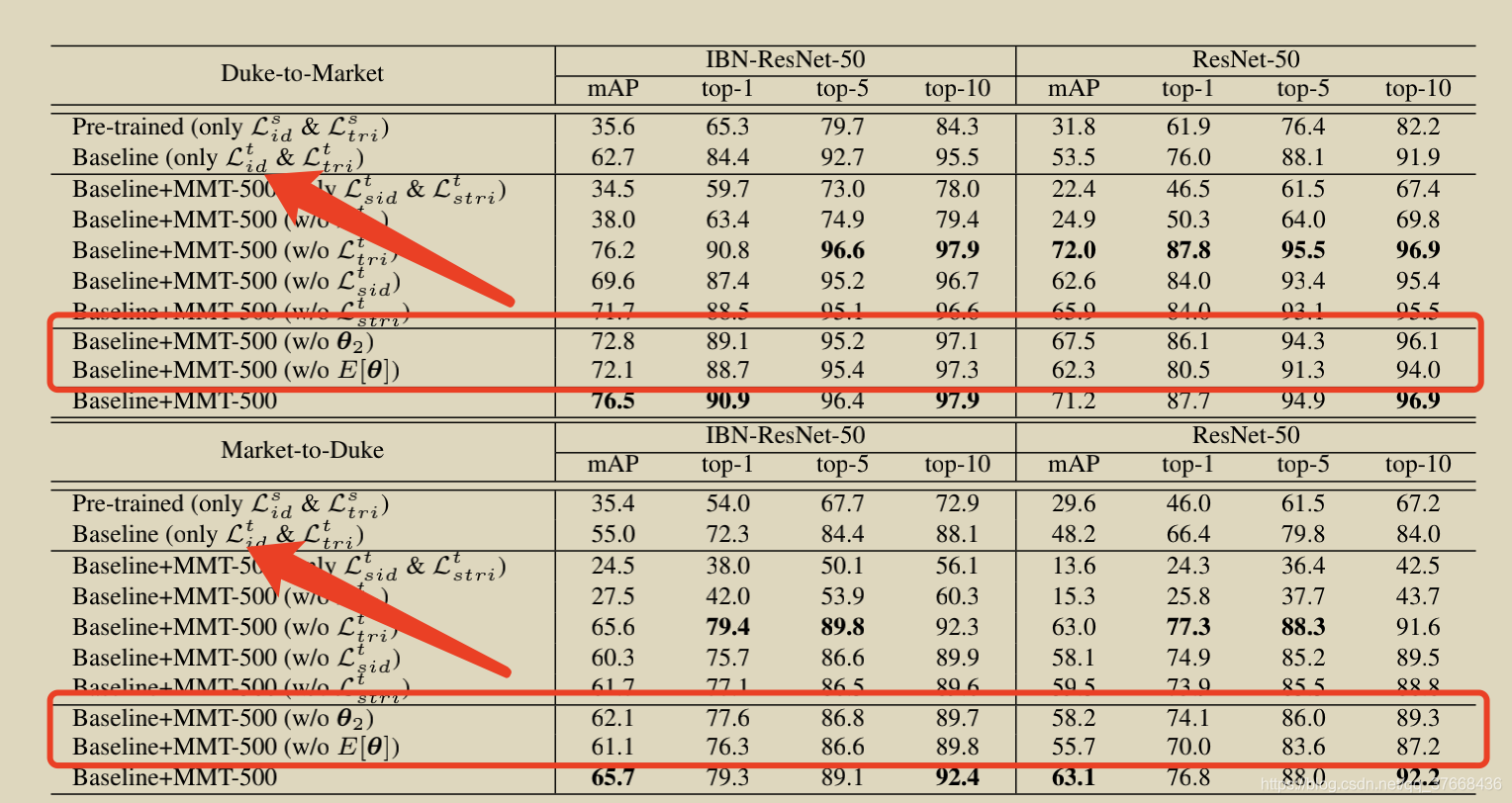


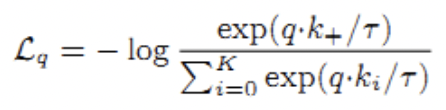
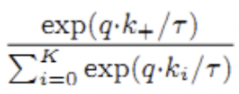 趋于1
趋于1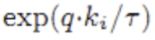 趋于0
趋于0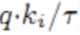 趋于负无穷
趋于负无穷

