


python学习(03) - 数据清洗处理

pandas DataFrame处理
pd.read_csv(path, header, names, index_col) - 读取csv文件
常用参数解析 :
- path: str,pathlib
数据集的来源路径,可以使URL,包括http, ftp, s3和文件。
- header: int or list of ints, default 'infer'
read_csv会为各行自动加上行索引,即使原数据集有行索引。
缺失时read_csv会自动识别表头做为列索引(即列名)。
header=None时,即指明原始文件数据没有列索引,这样read_csv为自动加上列索引,除非给定列索引的名字。数据有表头时不能设置header为空(默认读取第一行,即header=0)。
header=0时,表示文件第0行(即第一行,python,索引从0开始)为列索引,这样加names会替换原来的列索引。
- names: array-like, default None
names传入的参数序列会作为表头(原数据有表头则会用names参数替换掉原有表头)。
- index_col: int or sequence or False, default None
指定数据中哪一列作为Dataframe的行索引,也可以指定多列,形成层次索引,默认为None,即不指定行索引,这样系统会自动加上行索引(0-)。
更多有关参数解析参见: pandas系列 read_csv 与 to_csv 方法各参数详解(全,中文版)
查看数据集的常用方法
(1) df.head(num): 查看前num行数据
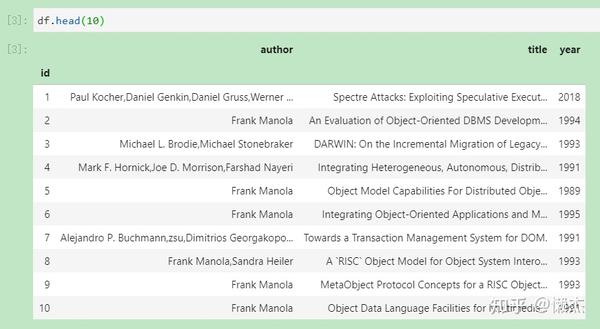

(2) df.tail(num): 查看后num行数据


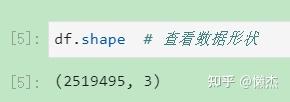
(3) df.shape: 查看数据形状
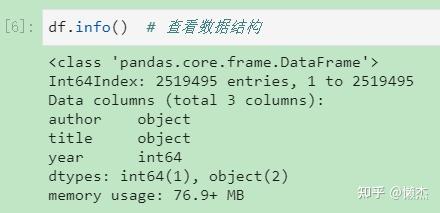
(4) http:// df.info() : 查看数据结构

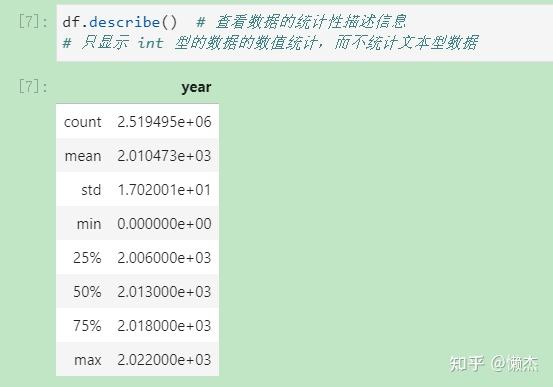
(5) df.describe(): 查看数据中 int 型数据的统计性描述文本

(6) df.isnull(): 查看各列均有缺失值的项,缺失则返回True,否则返回False
(7) df.isnull().any(): any的作用在于:有一个空数据返回结果就是False,如果直接用df.isnull()会返回每一个数据判断后的结果,不便于统计


(8) df.notnull().all(): all的作用在于:所有数据都非空时返回True
(9) df.isnull().sum(): 统计df中数据为空的个数,每一列的总数
(10) df.isnull().sum().sum(): 统计总的个数


(11) df[df.isnull().values==True]: 可以只显示存在缺失值的行列,确定缺失值的位置。
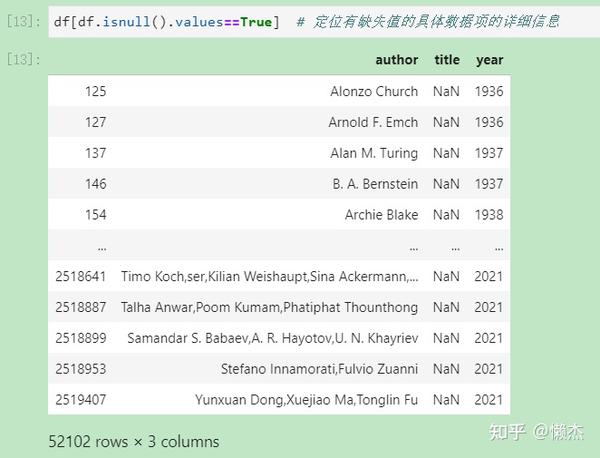

注意:df.isnull().values==True 返回的值类型是 numpy.ndarray(用于存放同类型元素的多维数组),其中的元素对应的是 DataFrame 中各数据项元素是否满足函数要求的bool值。
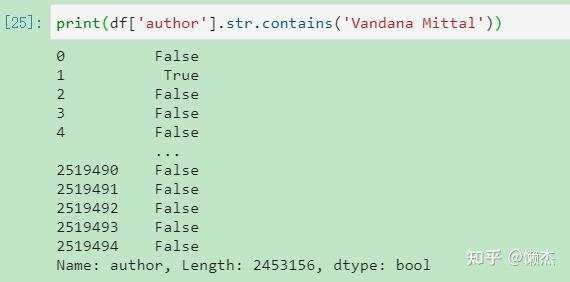
(12) df[df['*'].str.contains('#')]: 查看某列包含特定字符串的行


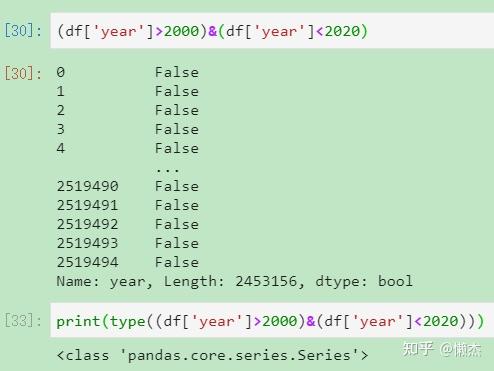
注意:df['author].str.contains('Vandana Mittal') 返回的值类型是pandas.core.series.Series (线性的数据结构, series是一个一维数组),其中的元素对应的是各数据项对应列元素是否满足函数要求的bool值。



如果在筛选条件前加 '~',可以实现反向筛选,再作为赋值对象则可以实现删除筛选目标数据的目的(曲线救国)。


(13) df[df['#']<2021]: 查看某列包含特定数值的行(同样可以实现曲线救国)
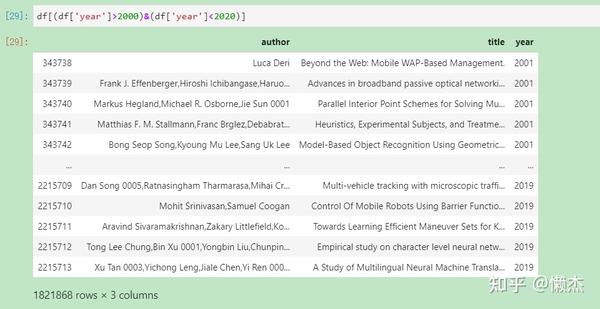

此处补充一个pandas的逻辑和算术运算知识: pandas - 逻辑与算数运算
注意:df['author].str.contains('Vandana Mittal') 返回的值类型是pandas.core.series.Series (线性的数据结构, series是一个一维数组),其中的元素对应的是各数据项对应列元素是否满足函数要求的bool值。

(14) df.duplicated(): 查看重复值,返回值为Series,各元素为bool值,表示该位置对应的是否为重复项。
数据排序
当inplace为False的时候,返回为修改过的数据,原数据不变。 但是当inplace为True,返回值为None,直接在原数据上进行操作。


(1) df.sort_values (by='#', axis=0, ascending=True, inplace=False, na_position='last')
将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
- by: 指定用于排序的列名(axis=0或'index')或行名(axis=1或'columns')
- axis: 若axis=0或'index',则按照指定列中数据大小进行行排序;若axis=1或'columns',则按照指定索引中数据大小进行列排序。默认axis=0。
- ascending: 是否按指定列的数组升序排列,默认为True,即升序排列
- inplace: 是否用排序后的数据集替换原来的数据,默认为False,即不替换
- naposition: {'first','last'},设定排序依据项数值缺失的显示位置
(2) df. sort_index (axis=0, ascending=True, inplace=False, na_position='last') 根据行标签进行排序,默认升序,即axis=0。当axis=1时,根据列标签进行排序。
(3) df.reset_index (level=None, drop=False, inplace=False, col_level=0, col_fill='')
数据清洗时,会将带空值的行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用reset_index()重置索引.
- level:数值类型可以为:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引 。
- drop:当指定drop=False时,则索引列会被还原为普通列;否则,经设置后的原有索引值会被恢复成普通标签。默认为False。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
- col_level:数值类型为int或str,默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。
- col_fill:对象,默认'',如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名。
此外,还有一种实现重置索引的方法,如(4)所述:
(4) df.index = range[df.shape[0]] : shape[0]表示shape的第0维大小,即行的数目。
(5) df.set (keys, drop=True, append=False, inplace=False, verify_integrity=False)
- keys:列标签或列标签/数组列表,需要设置为索引的列
- drop:默认为True,删除用作新索引的列(不删除的话会有两个同样但顺序不同的列)
- append:是否将列附加到现有索引(即追加指定的索引),默认为False。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
- verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为False将提高该方法的性能,默认为False。
数据清洗
(1) df.dropna (axis=0, how='any', thresh=None, subset=None, inplace=False)
返回值:DataFrame。
全缺省时删除至少有一个元素缺失的行,要想删除列可设axis=1.
- axis: 0表示对包含缺失值的行进行删除;1表示对包含缺失值的列进行删除
- how: any表示有任何NA存在就删除所在行或列;all表示该行或列必须都是NA才删除
- thresh: int整数数据类型;optional随意数据类型
- subset: 列标签或者标签序列
- inplace: True在原表上进行修改;False不在原表上进行修改
(2) 删除整行或整列:df.drop (labels=None,axis=0, index=None, columns=None, inplace=False)
- labels 就是要删除的行列的名字,用列表给定
- axis 默认为0,指删除行,因此删除columns时要指定axis=1;
- index 直接指定要删除的行
- columns 直接指定要删除的列
- inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;
- inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
(3) df.duplicated (subset=None, keep='first')
返回值: Series。
- subset: 列标签或者标签序列,默认为None(表示考虑所有列)。
- keep: 可选参数有三个:'first'、'last'、'False', 默认值 'first'。分别对应显示第一条重复项;显示最后一条重复项;显示全部重复项。
(4) df.drop_duplicates (subset='#', keep='first', inplace=True)
返回值: DataFrame。
- subset: 输入要进行去重的列名,默认为None(此时考虑所有列),多个删除依据可以设为序列
- keep: 可选参数有三个:'first'、'last'、'False', 默认值 'first'。其中,first表示: 保留第一次出现的重复行,删除后面的重复行。last表示: 删除重复项,保留最后一次出现。False表示: 删除所有重复项。
- inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。
(5) 删除包含某些数值的行或者列
如:df[df['year']<2000] , 此时筛选出 df 中 'year' 列数值小于 2000 的列,如果想要删除这些列,可以筛选出目的数据后作为赋值对象实现保留以达到删除。如第2节中(13)所述。
(6) 删除某列包含特殊字符的行
如:df[df['author'].str.contains('Vandana Mittal')] 筛选出来的是含有字符'Vandana Mittal'的数据项,而 df[~df['author].str.contains('Vandana Mittal')] 筛选出来的则是不含有字符'Vandana Mittal'的数据项,将其作为赋值对象,可以曲线实现删除。如第2节中(12)所述。
(7) 删除某列包含若干个某字符的行
例如想要知道 df 中 author 列含有多少个' , ',则可以:
df['author'].str.count(',') # 返回值为Series,对应各行在该列中逗号的出现次数。
(8) 删除某列包含非英文字符的行
例如想要将非英文标题的数据项删除,则可以:
df[~ df['title'].map(lambda x: x.isascii())] # 查看 Non-English title 的文章
df = df[ df['title'].map(lambda x: x.isascii())] # 删除 Non-English title 的文章
- map(function, iterable, ...) # function--函数;iterable--一个或多个序列 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
- lambda x: x.isascii() # lambda函数也叫匿名函数,即,函数没有具体的名称。lambda语句中,冒号前是参数,可以有多个,用逗号隔开,冒号右边的是返回值。 lambda语句构建的其实是一个函数对象
- isascii() # 判断是否为ASCII码
(9) 求dataframe的差集
假设有两个dataframe为a和b,a和b可以是相互包含的关系,现在想要将a中和b重复的内容去掉,也就是求差集,步骤如下:
(1)需要对两个dataframe进行去重
(2)利用append方法,a=a.append(b)
(3)再次利用append方法,a=a.append(b)
【为什么要利用两次append方法?】为了真正引入重复,若只是一次append,可能会导致在a中添加了a原本不存在的数据项,但是在去重时该数据项并非重复故无法去除。
(4)去重,利用drop_duplicates方法,a=a.drop_duplicates(),以及设置参数keep=False,意思就是只要有重复,重复的记录都去掉。(keep默认='first',也就是保留第一条记录)
>>>data_a={'state':[1,1,2],'pop':['a','b','c']}
>>>data_b={'state':[1,2,3],'pop':['b','c','d']}
>>>a=pd.DataFrame(data_a)
pop state
0 a 1
1 b 1
2 c 2
>>>b=pd.DataFrame(data_b)
pop state
0 b 1
1 c 2
2 d 3
>>>a = a.append(b)
>>>a = a.append(b)
>>>result = a.drop_duplicates(subset=['pop','state'],keep=False)
>>>result
pop state
0 a 1引自: Python Dataframe 指定多列去重、求差集的方法
数据拼接
(1) df.concat (objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None)
- objs:进行拼接的对象,常为序列的形式,如[o1,o2]
- axis:拼接轴方向,默认为0,沿行拼接;若为1,沿列拼接
- join:默认外联'outer',拼接另一轴所有的label,缺失值用NaN填充;内联'inner',只拼接另一轴相同的label;
- join_axes: 指定需要拼接的轴的labels,可在join既不内联又不外联的时候使用
- ignore_index:对index进行重新排序
- keys:多重索引
(2) df.append (other, ignore_index=False)
- other:追加到df末尾的数据,可以是序列
- ignore_index:若为True,则对index进行重排
(3) df.join (other, on=None, how='left',, lsuffix='', rsuffix='', sort=False)
索引上的合并
- other:追加到df末尾的数据,可以是序列
- on:参照的左边df列名key(可能需要先进行set_index操作),若未指明,按照index进行join
- how:{'left', 'right', 'outer', 'inner'}, 默认'left',即按照左边df的index进行连接(若声明了on,则按照对应的列);若为'right'则按照右边df的index进行连接。若'inner'为内联方式;若为 'outer'为全连联方式(同于merge)。
- sort:是否按照join的key对应的值大小进行排序,默认False
- lsuffix 和 rsuffix:当left和right两个df的列名出现冲突时候,通过分别设定左df和右df后缀的方式避免错误
(4) pd.merge (left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)
- left和 right:两个要合并的DataFrame;
- how:连接方式,有 inner、left、right、outer, 默认为inner;
- on:指的是用于连接的 列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
- left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
- right_on:右侧DataFrame中用于连接键的列名;
- left_index:使用左侧DataFrame中的 行索引作为连接键;
- right_index:使用右侧DataFrame中的行索引作为连接键;
- sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
- suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x', '_y');
- copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
- indicator:显示合并数据中数据的来源情况
(5) 其他
可以通过Series直接添加到DataFrame来实现拼接
如df只有ABCD四列,则可以用 df['E'] = df2来实现。df2为Series,要注意index。
数据定位
(该节 原文链接 )
主要通过以下几个函数来定位DataFrame中的特定数据
- iloc
- loc
- iat
- at
总的来说,分为两种:
一种是通过lables(即row index和column names,这里row index可以字符,日期等非数字index)(使用loc, at);
另一种通过index(这里特指数字位置index)(使用iloc, iat)
oc和at的区别在于, loc可以选择特定的行或列,但是at只能定位某个特定的值,标量值。一般情况下,我们iloc和loc更加通用,而at, iat有一定的性能提升。
In [630]: df
Out[630]:
age color food height score state
Jane 30 blue Steak 165 4.6 NY
Nick 2 green Lamb 70 8.3 TX
Aaron 12 red Mango 120 9.0 FL
Penelope 4 white Apple 80 3.3 AL
Dean 32 gray Cheese 180 1.8 AK
Christina 33 black Melon 172 9.5 TX
Cornelia 69 red Beans 150 2.2 TX
# 选择某一行数据
In [631]: df.loc['Dean']
Out[631]:
age 32
color gray
food Cheese
height 180
score 1.8
state AK
Name: Dean, dtype: object
# 选择某一列数据,逗号前面是行的label,逗号后边是列的label,使用":"来表示选取所有的,本例是选取所有的行,当':'在逗号后边时表示选取所有的列,但通常我们可以省略。
In [241]: df.loc[:, 'color']
Out[241]:
Jane blue
Nick green
Aaron red
Penelope white
Dean gray
Christina black
Cornelia red
Name: color, dtype: object
# 也可以如下选取一列,但是与前者是有区别的,具体参考Reference中的《Returning a view versus a copy》
In [632]: df.loc[:]['color']
Out[632]:
Jane blue
Nick green
Aaron red
Penelope white
Dean gray
Christina black
Cornelia red
Name: color, dtype: object
# 选择某几行数据,注意无论选择多行还是多列,都需要将其label放在一个数组当中,而选择单个行或列,则不需要放在数组当中
In [634]: df.loc[['Nick', 'Dean']]
Out[634]:
age color food height score state
Nick 2 green Lamb 70 8.3 TX
Dean 32 gray Cheese 180 1.8 AK
# 注意以下这种用法不行,这是由于Pandas会认为逗号后边是列的label
df.loc['Nick', 'Dean']
# 选择范围
In [636]: df.loc['Nick':'Christina']
Out[636]:
age color food height score state
Nick 2 green Lamb 70 8.3 TX
Aaron 12 red Mango 120 9.0 FL
Penelope 4 white Apple 80 3.3 AL
Dean 32 gray Cheese 180 1.8 AK
Christina 33 black Melon 172 9.5 TX
# iloc的特定用法, 可以用-1这样index来获取最后一行的数据
In [637]: df.iloc[[1, -1]]
Out[637]:
age color food height score state
Nick 2 green Lamb 70 8.3 TX
Cornelia 69 red Beans 150 2.2 TX
数据定位是后续条件过滤、赋值以及各种转换的基础,一定要熟练掌握。
另外,在定位某一个具体的元素的时候,loc和at并不完全相同。
# loc支持以下两种定位方式
In [726]: df.loc['Jane', 'score']
Out[726]: 4.6
In [727]: df.loc['Jane']['score']
Out[727]: 4.6
# 但是at只支持第一种定位方式
In [729]: df.at['Nick', 'height']
Out[729]: 181
In [730]: df.at['Nick']['height']
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-730-948408df1727> in <module>()
----> 1 df.at['Nick']['height']
~/.pyenv/versions/3.6.4/envs/data_analysis/lib/python3.6/site-packages/pandas/core/indexing.py in __getitem__(self, key)
1868 key = self._convert_key(key)
-> 1869 return self.obj._get_value(*key, takeable=self._takeable)
1871 def __setitem__(self, key, value):
TypeError: _get_value() missing 1 required positional argument: 'col'
有两点需要说明:
- 在针对特定元素赋值的时候最好使用at来进行操作,性能提升还是很明显的。
-
loc的两种方式并不等同,
df.loc['Jane', 'score']是在同一块内存中对数据进行操作,而df.loc['Jane']['score']是在另一个copy上进行操作,具体参考 Returning a view versus a copy
其他一些数据处理方式
(1) 如何分割某一列内的元素使其每个元素单独占一行
因为在我自己处理的数据集中存在含有多个元素的一个字段,如author字段有三个元素:
| id | author | title | year |
|---|---|---|---|
| 99 | A,B,C | Whatever | 2021 |
现在需要分割重排列为:
| id | author | title | year |
|---|---|---|---|
| 99 | A | Whatever | 2021 |
| 100 | B | Whatever | 2021 |
| 101 | C | Whatever | 2021 |
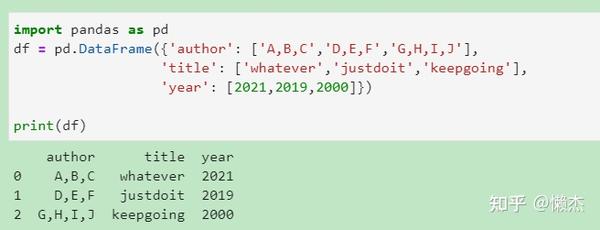

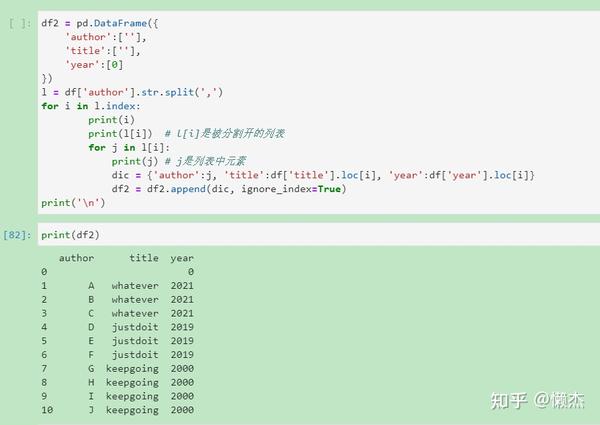

(2) 删除字符串开头和结尾中指定的字符
- string.strip()
返回 string 的副本,并删除指定的前导和后缀字符。( 想去掉字符串里面的指定字符,那么就把这些字符当参数传入。此函数只会删除头和尾的字符,中间的不会删除。 )如果strip()的参数为空,那么会默认删除字符串头和尾的空白字符(包括' ', '\n', '\r', '\t'这些)。
当传入的字符有多个(即参数是字符串形式,如‘ab’)时,函数会把传入的参数拆解成一个个的字符('a', 'b),然后把头尾的这些字符去掉,直到遇到非指定字符时停止并返回一个副本。如:
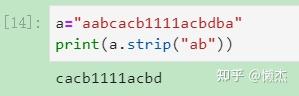
可见,无论参数传入多少个字符,函数在处理时都会将其分解为单个字符进行处理。
因为strip()一次只能处理一个数据,所以假设要对所有列名进行处理,可以采用列表推导式进行处理,即:


- string.lstrip() 和 string.rstrip()
和上面的strip()基本相同,参数结构也相同。
lstrip() 是去掉 left (头部)的指定字符,rstrip() 是去掉 right (尾部)的指定字符。
那么如果想要直接删除一串子字符该怎么办呢?
(3) 按指定值将字符串拆分成列表:split(s)
将字符串拆分为列表,s为拆分依据,默认为空格。
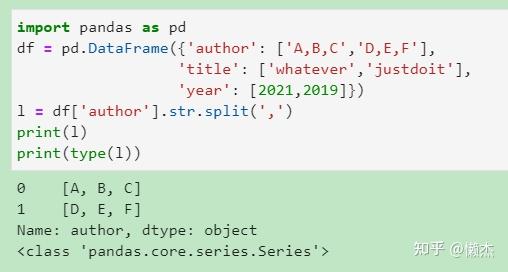

(4) 统计某列各元素对应出现的次数:df['#'].value_counts()
返回值为一个Series
(5) 将输入的1970年1月1日以来的秒数,转换为可读性较好的当地时间和GMT时间
1970年1月1日被称为epoch纪元,而这个值,想要将其转化为一个可读性的值,类似于这样的:2009-05-03 10:30:15
import time
print time.asctime(time.localtime(1309433893)) #-> ‘Thu Jun 30 19:38:13 2011’
print time.asctime(time.gmtime(1309433893)) #-> ‘Thu Jun 30 11:38:13 2011’
#上述解决方式得到的结果并不符合我们的要求,于是有如下:
epoch = 1309433893;
local_time = time.localtime(epoch);
gmt_time = time.gmtime(epoch);
#print time.asctime(local_time), time.asctime(gmt_time);
print time.strftime("%Y-%m-%d %H:%M:%S", local_time);
print time.strftime("%Y-%m-%d %H:%M:%S", gmt_time);
#输出的格式可以自行更改,类型为time.struct_time
格式化参数的含义:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始