


量化金融数据:Numba加速Pandas聚合

苏什么来着

XJTU MFE在读|苦逼量化实习生
当处理高频金融数据达到TB级,Pandas的运算效率低下逐渐凸显。
Numba是一个成熟的性能优化方案,经过Numba编译的Python矩阵运算,运行速度接近C/C++语言。
Numba简介
Numba,一个高性能Python编译器。
Numba 使 Python 代码变得更快。
Numba 是一个开源 Just-in-time compilation(JIT ,即时编译)编译器,可将 Python 和 Numpy 代码的子集翻译为机器码。
安装Numba
conda install numba使用Numba
导入数据
加载dataframe,内存占用超过1GB
import numba
import numpy as np
import pandas as pd
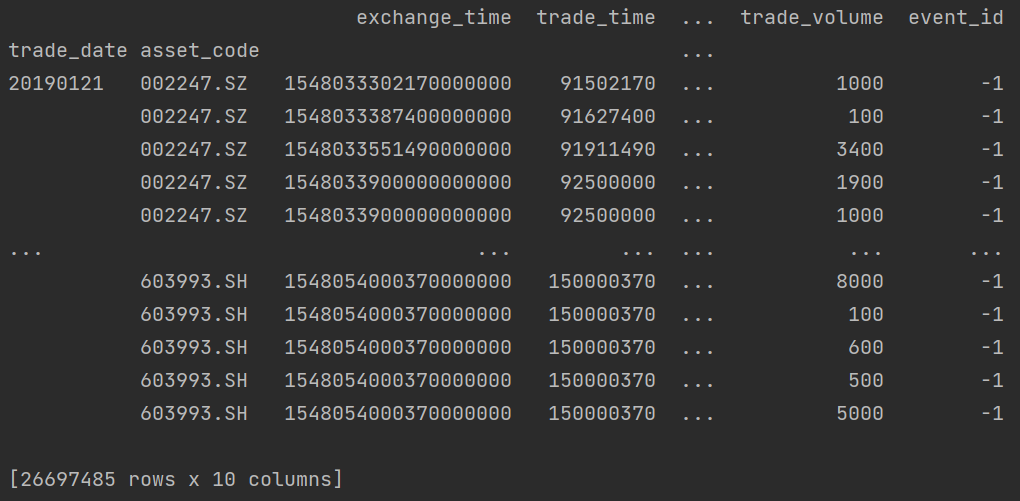
data = pd.read_feather("test.feather").set_index(['trade_date', "asset_code"])
data["trade_amount"] = data["trade_volume"] * data["trade_price"]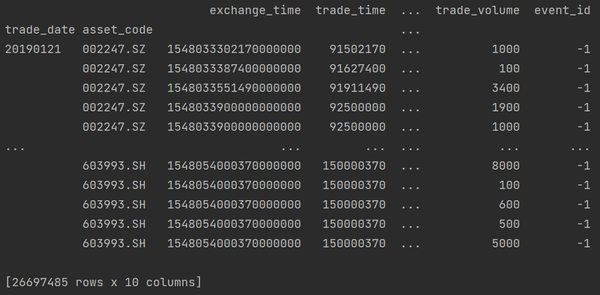
普通分组聚合运算
def p(group):
threshold = group["trade_amount"].mean() + group["trade_amount"].std()
fac = group[group["trade_amount"] > threshold]["trade_amount"].sum() / group["trade_amount"].sum()
return fac
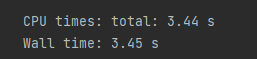
factor = data.groupby(["trade_date", "asset_code"]).apply(p)针对MultiIndex进行分组,对分组的dataframe进行一些自定义的矩阵运算,耗费3.44秒。
Numba加速
@numba.jit(signature_or_function=numba.float32(numba.float32[:]),nopython=True,cache=True,nogil=True,boundscheck=True)
def p(trade_amount):