2.上传文件
hdfs dfs -put 1.txt /ops
3.文件被复制到本地系统中
hdfs dfs -get /ops/1.txt /data/work
4.删除文件或目录
hdfs dfs -rm /ops/1.txt hdfs dfs -rmr /ops
5.查看文件内容
hdfs dfs -cat /ops/1.txt
6.建立目录
hdfs dfs -mkdir -p /ops/20161201
7.fsck
1)查看目录的健康状态
hdfs fsck /
2)check 目录下的文件
hdfs fsck /ops -files
3)查看某个目录 block 以及监控情况
hdfs fsck /ops -files -blocks -locations
4)查看目录损坏的块
hdfs fsck / -list-corruptfileblocks
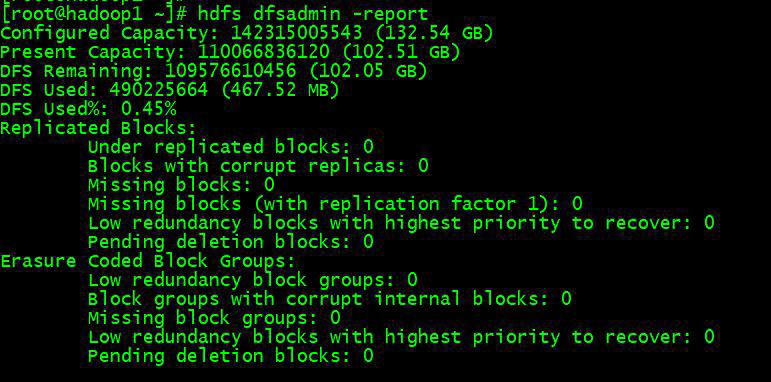
hdfs dfsadmin -report
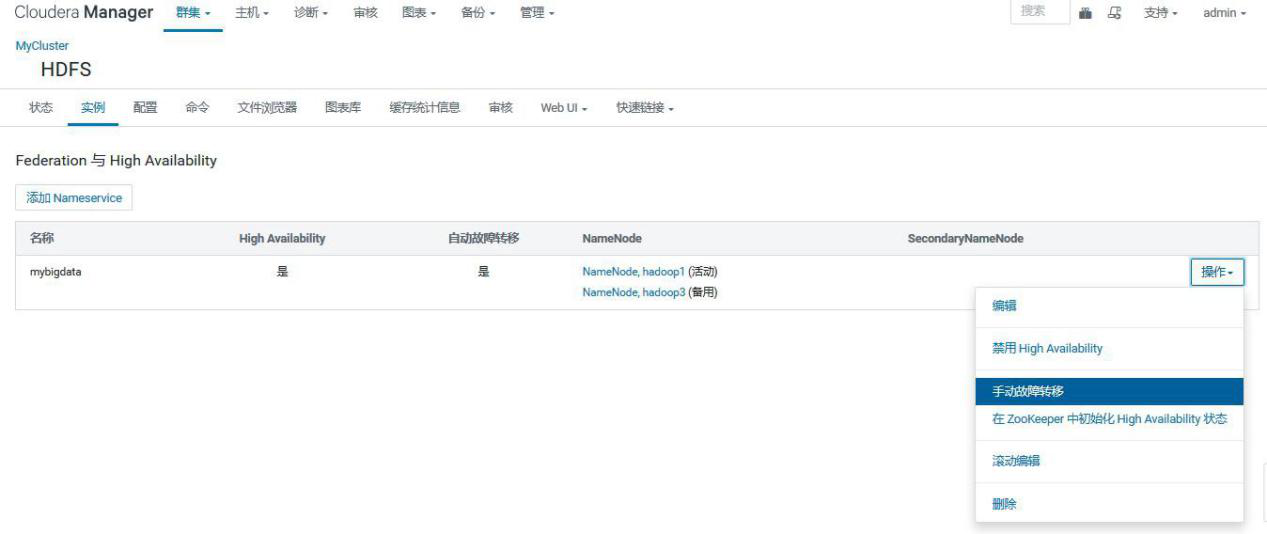
## 3.3、主从切换
1.命令行操作
1)查看 namenode 主从状态
hdfs haadmin -getServiceState nn1
此处的 nn1 为在 hdfs-site.xml 中配置的 namenode 服务的名称
2) active 从 nn1 切 换 到 nn2
hdfs haadmin -failover nn1 nn2
2.CM 操作
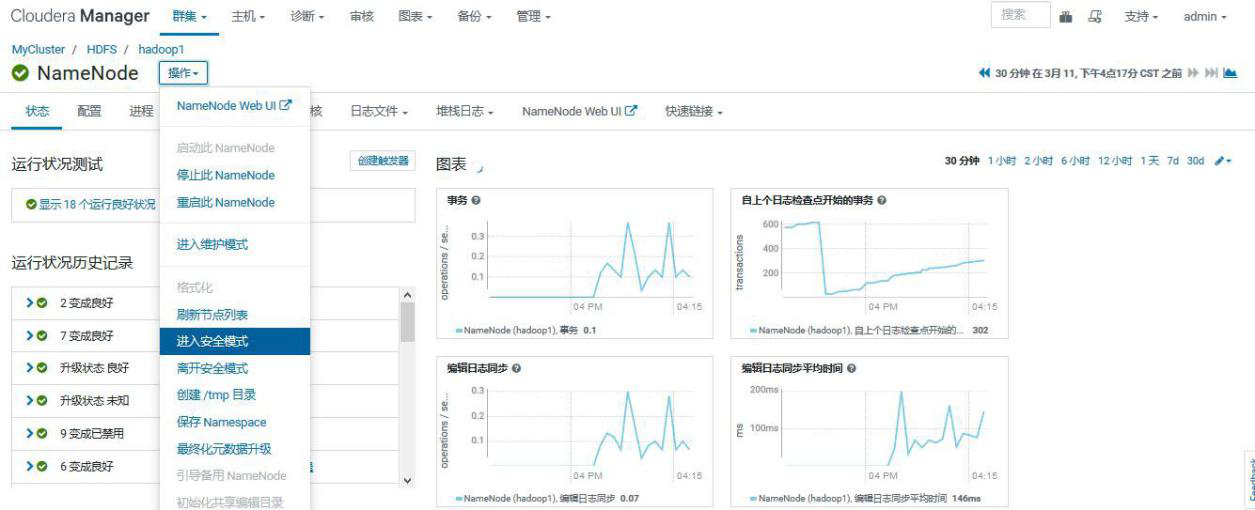
## 3.4、安全模式
1.命令行操作
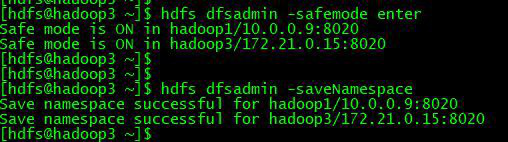
1)进入安全模式
在必要情况下,可以通过以下命令把 HDFS 置于安全模式
两个 NameNode 进入安全模式
hdfs dfsadmin -safemode enter
单个 NameNode 进入安全模式
hdfs dfsadmin -fs hdfs://hadoop3:8020 -safemode enter
2)退出安全模式
两个 NameNode 退出安全模式
hdfs dfsadmin -safemode leave
单个 NameNode 退出安全模式
hdfs dfsadmin -fs hdfs://hadoop3:8020 -safemode leave
3)查看状态
hdfs dfsadmin -safemode get
2.CM 操作
## 3.5、保存命名空间
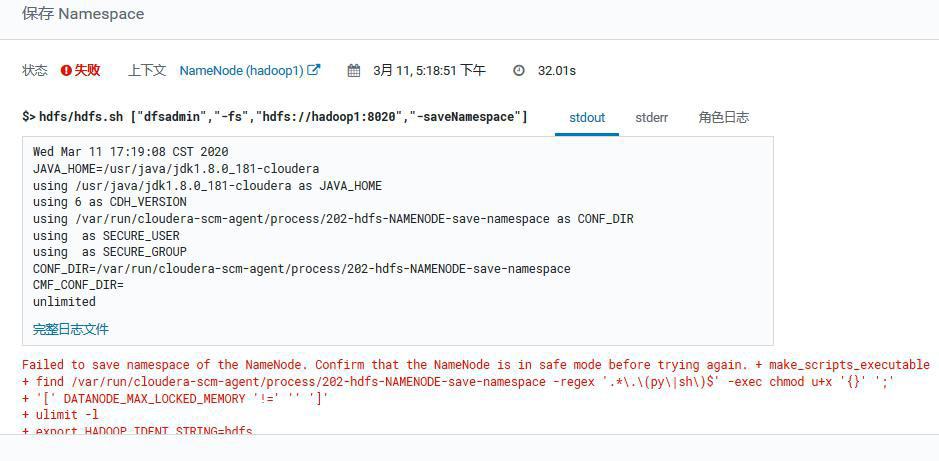
### 3.5.1、首先进去安全模式不然报错

CM 上操作也报错:
### 3.5.2、保存命名空间
hdfs dfsadmin -saveNamespace
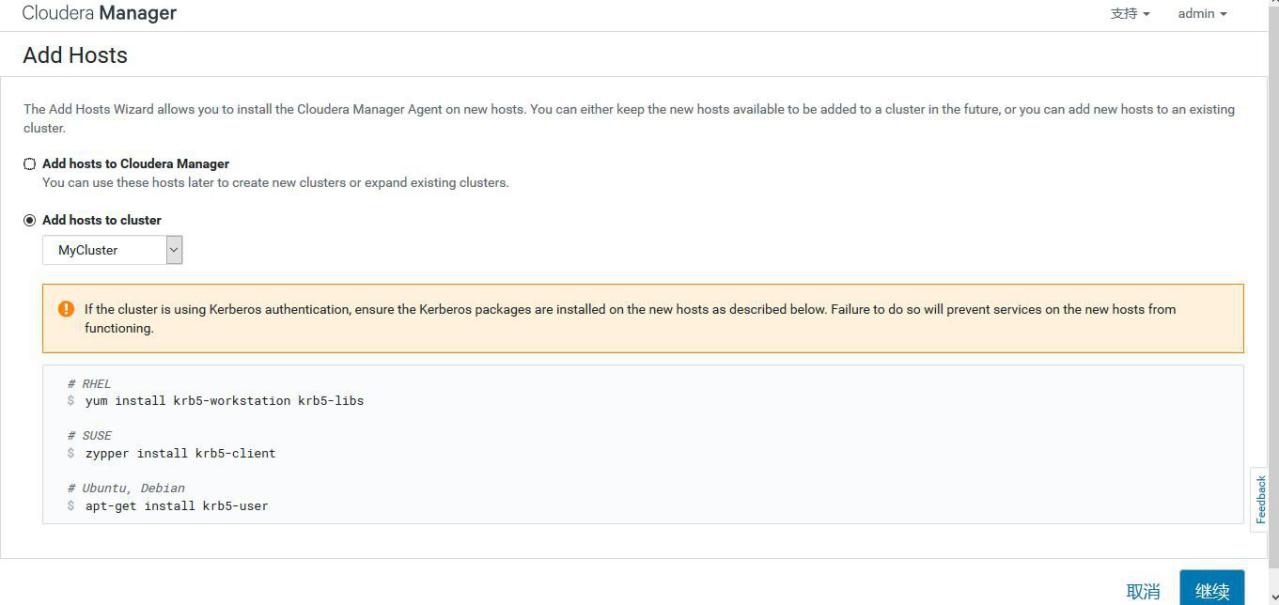
## 3.6、扩缩容
### 3.6.1、扩容
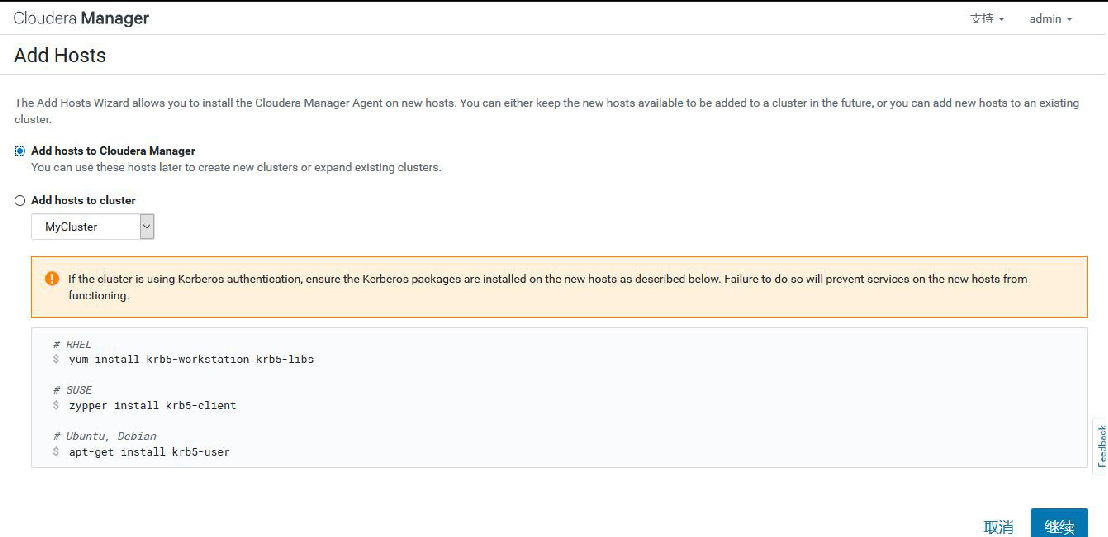
①选择 add hosts,添加主机到 CM
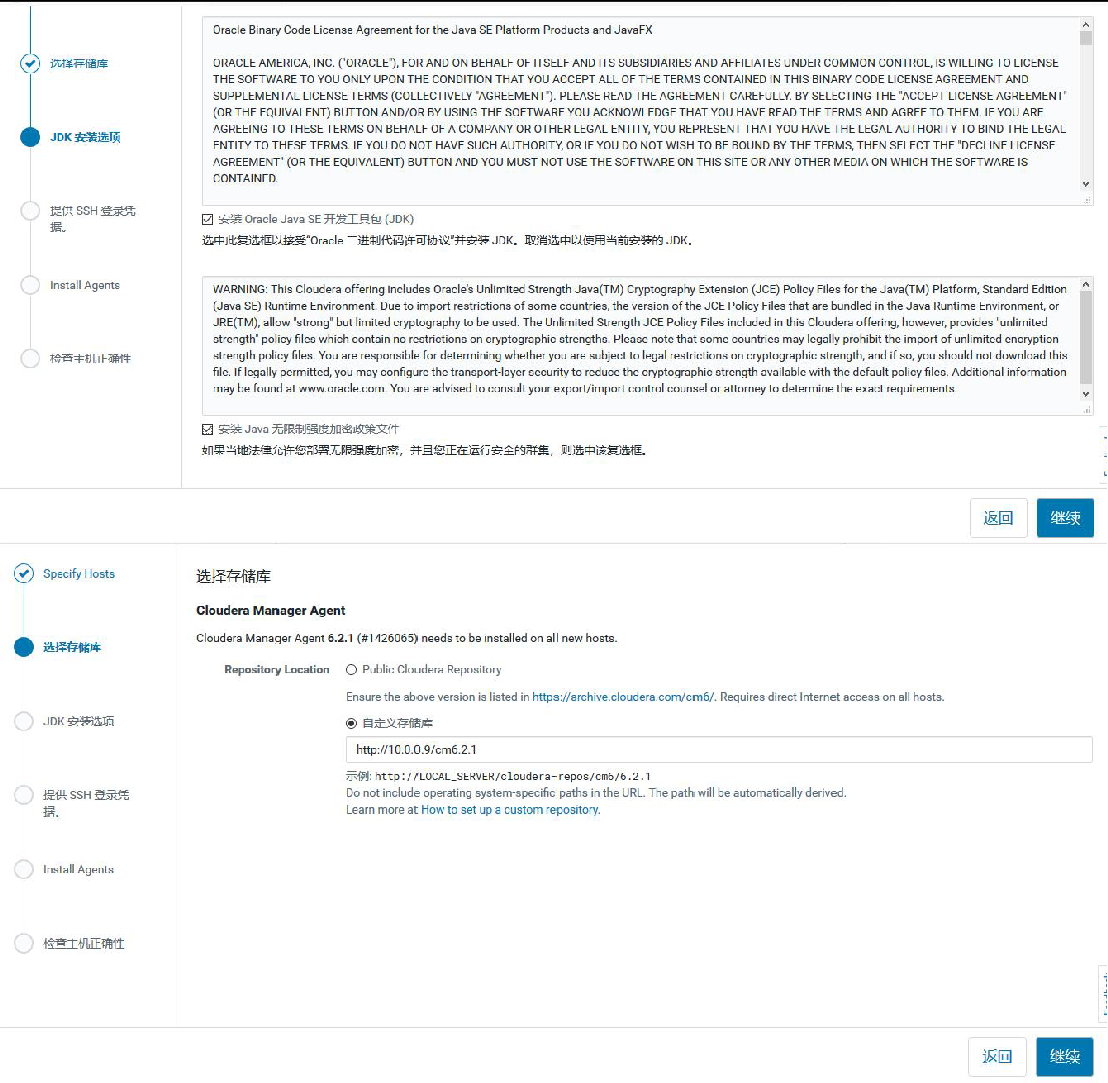
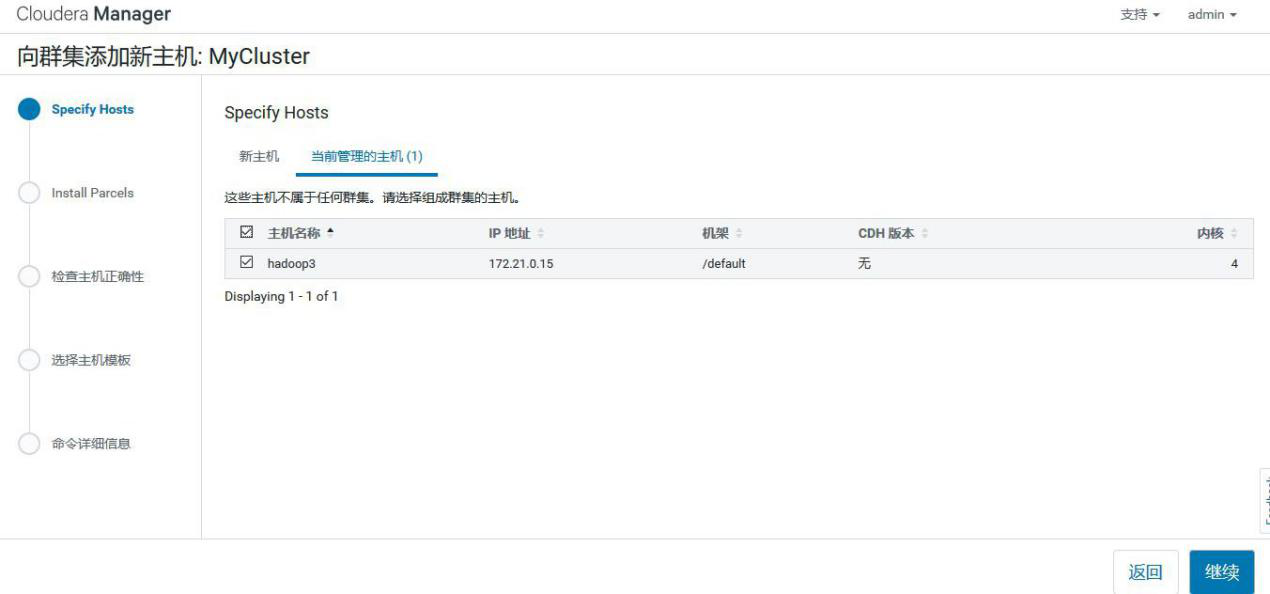
②添加 hadoop3
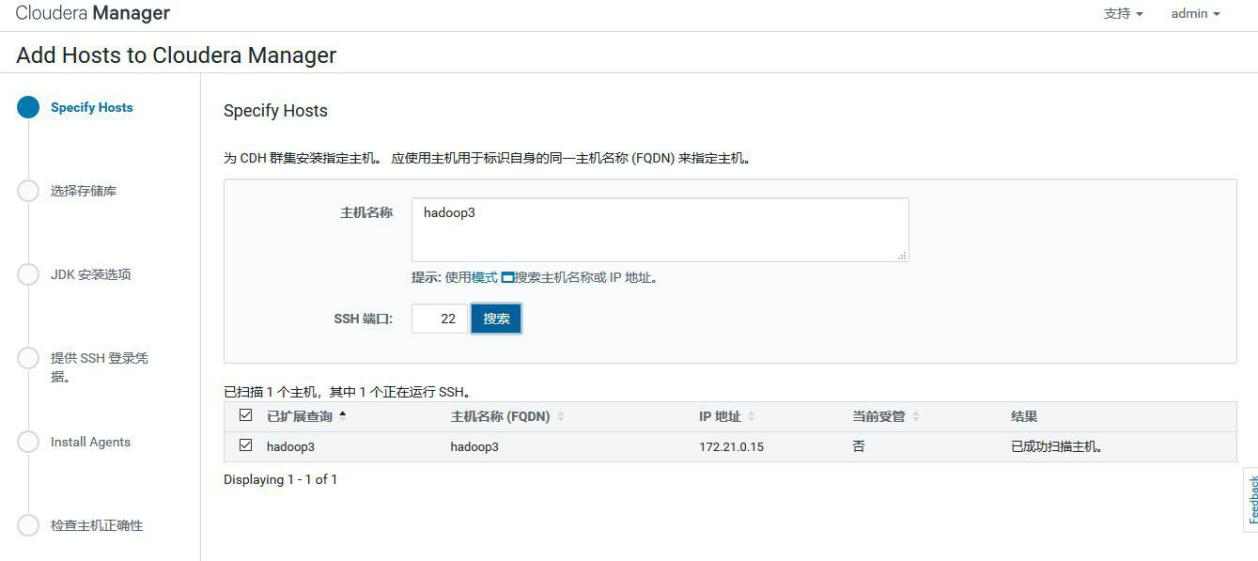
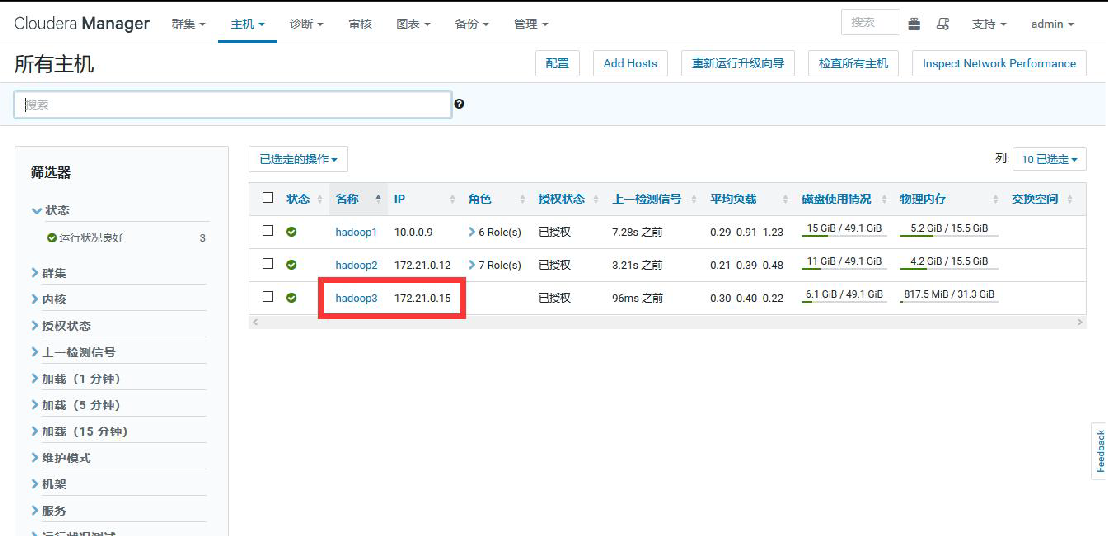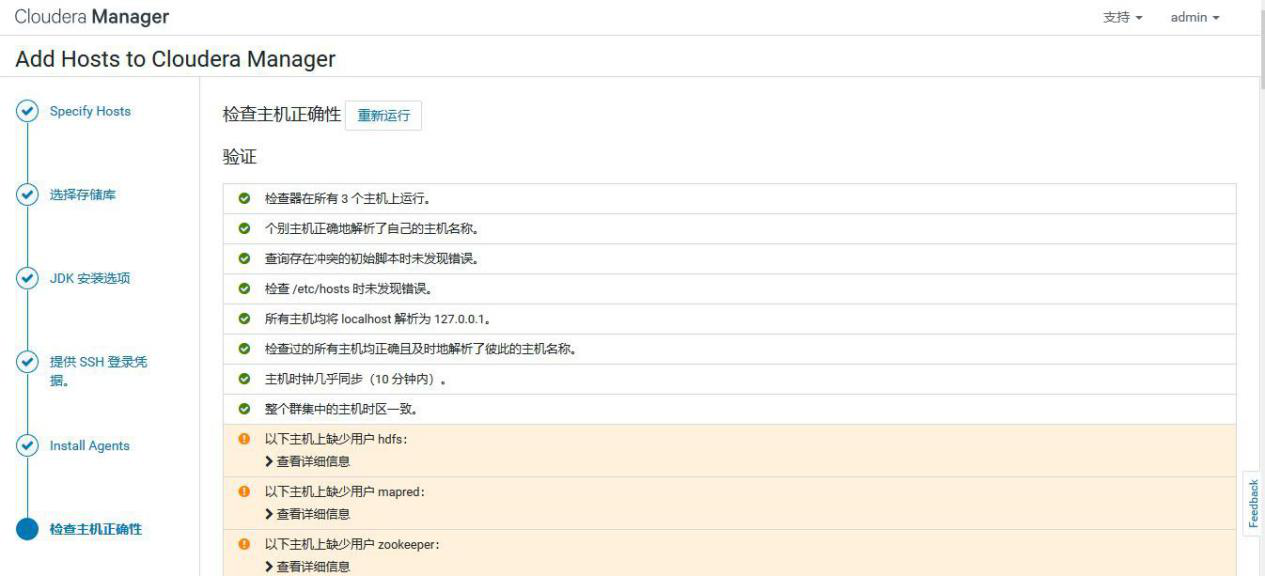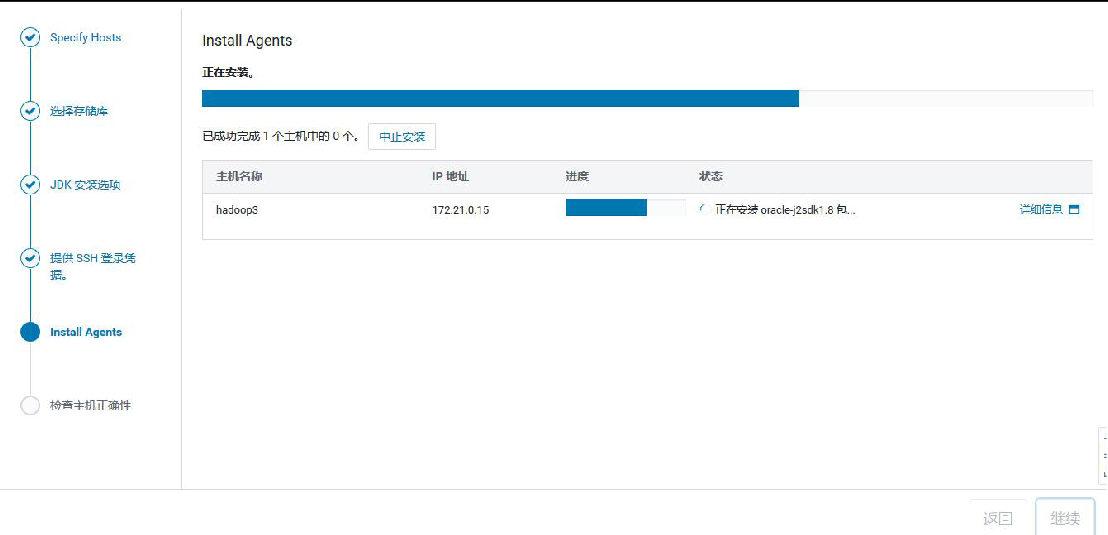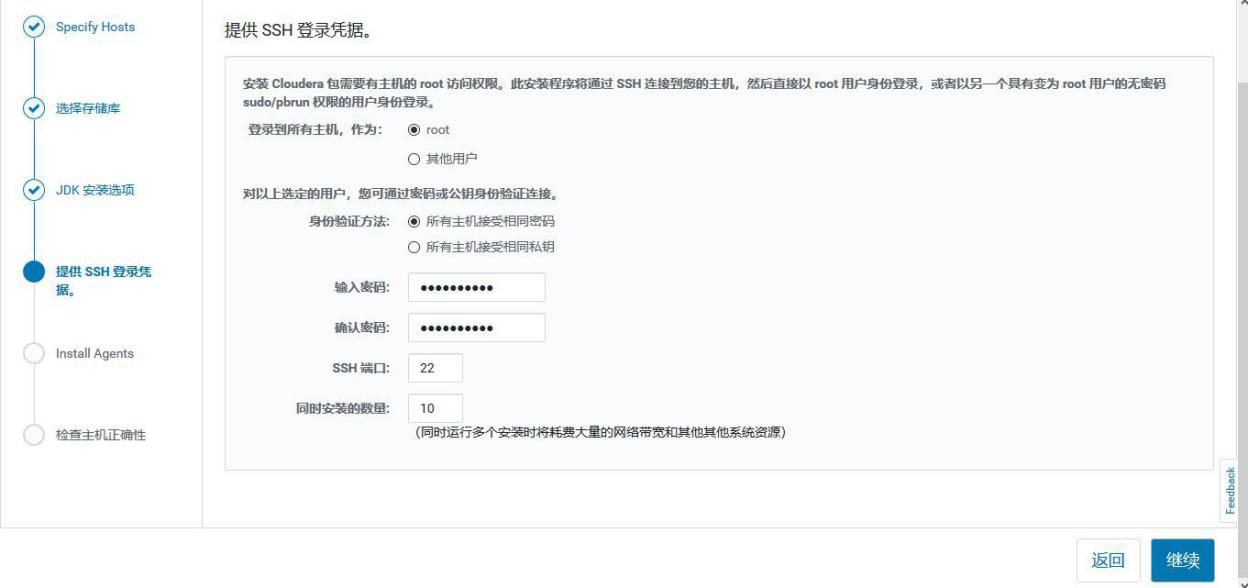
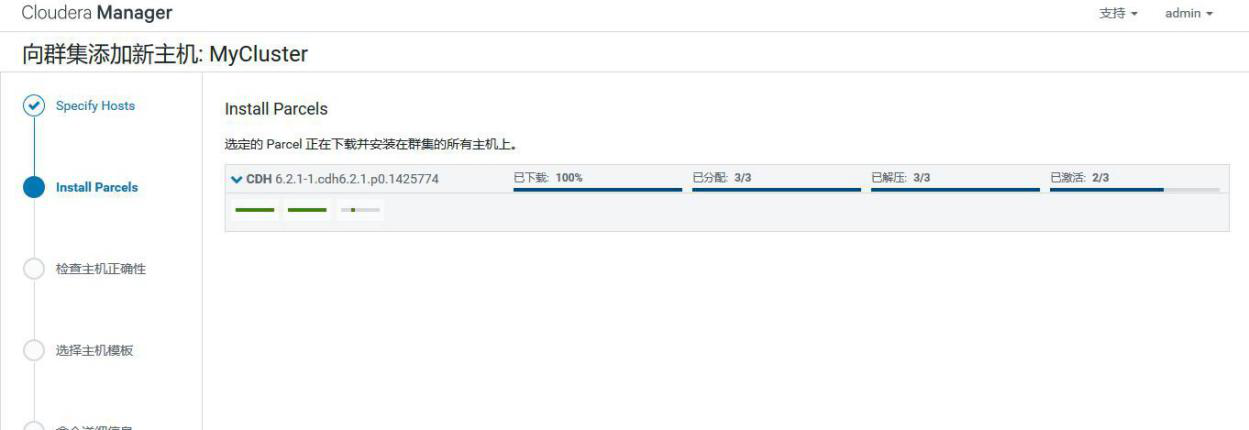
③添加 hadoop3 到 MyCluster 集群
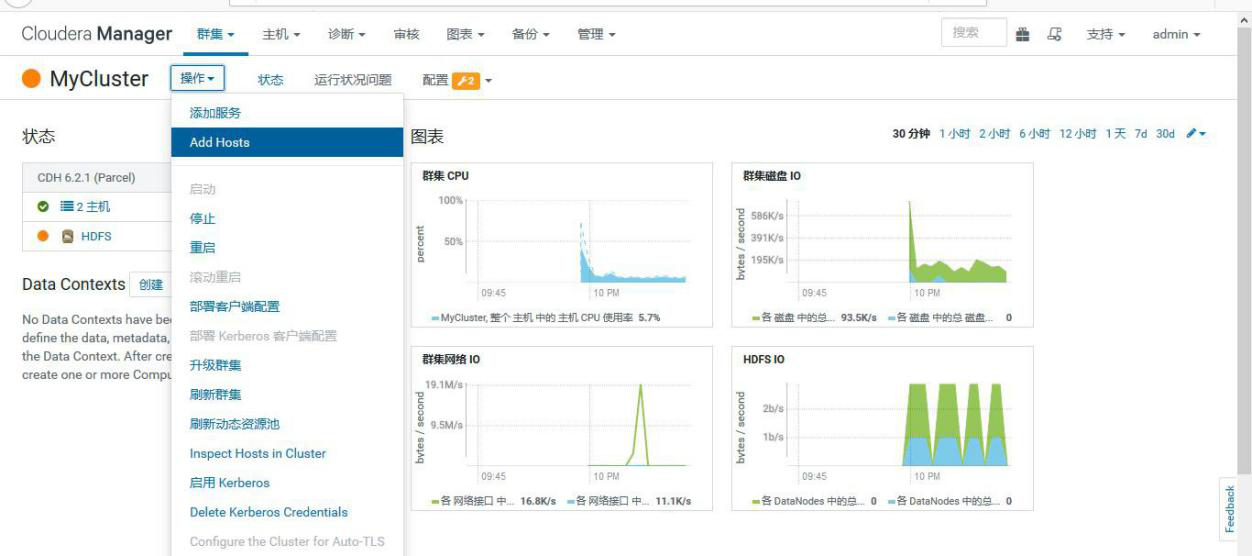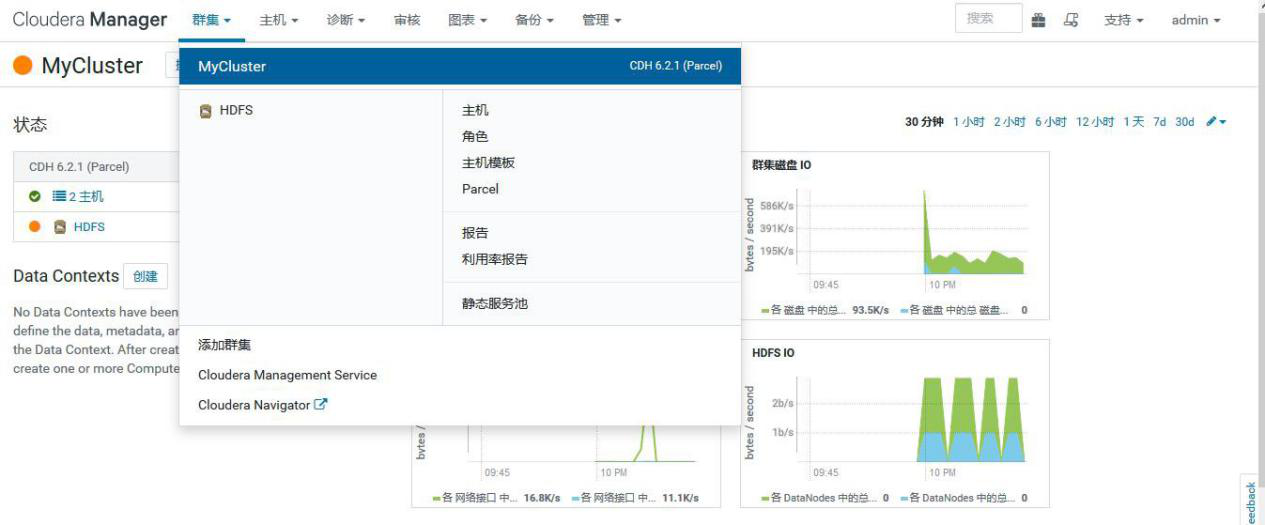
④添加角色实例
⑤启动新增的 datanode
3.6.2、缩容
4.1、meta 文件损坏导致datanode 进程无法启动
xx集群的hadoop033节点主机重启后,datanode进程无法启动。
【查看日志】
在 datanode 的"角色日志详细信息"中发现数条关于无法读取.meta文件的报错:
【登录主机核实】
以第一条报错为例,我们进入到/data/hdfsdsk09/data/current/BP-1981380748-192.168.116.201-1398150807170/current/finalized/subdir48/subdir46/目录下,发现该条报错中提到的 meta 文件的属主、属组和权限等信息显示异常。
hdfsdsk09 磁盘下的某几个 meta 文件损坏,导致 datanode 进程无法启动。
【解决方法】
修复 hdfsdsk09 磁盘
①以 sudo 权限取消 hdfsdsk09 的挂载命令:sudo umount /data/hdfsdsk09
②fsck 修复磁盘
命令:sudo fsck /data/hdfsdsk09
③启动 datanode
在 CM 页面启动 datanode。
如果磁盘无法通过 fsck 命令修复,就找主机侧,让他们用 root 用户格式化磁盘,然后我们按照坏盘故障来处理。
4.2、多个datanode 节点存储不足
xx集群的多个 datanode 可用空间不足,并引发 CM 页面告警。
HDFS 页面显示所有 datanode 存储的标准差已达 11%(正常情况下是 5%)
【解决方案】
运行 Hadoop 自带的 balancer 程序,平衡 HDFS 中的各节点间的差距。在任意节点都可以启动 balancer,但是建议选择空闲(内存占用低)的节点。
【执行 balancer】
①在内存占用较低的 zchadoop002-1 上启动 balancer 脚本,将 HDFS 中所有节点的存储值中的最低值和平均值的差值设置为 5。
命令:start-balancer.sh -threshold 5
启动 balancer 后,在屏幕输出了 balancer 的日志路径。
②设置 balancer 所能占用的带宽
带宽的大小与负载均衡的速度成正比,但是速度过大可能会导致
map/reduce 运行缓慢,所以务必选择业务空闲时间段启动 balancer。默认的带宽为 1048576(1M/S)。由于 balancer 可以在中断后重新执行(类似于迅雷的断点续传),所以可以先设置一个较低的带宽,慢了的话,再一次次加速。此处设置为 2M/S。需要强调的是,balancer 每次设置的带宽是临时性的,第二次启动 balancer 时,要重新设置带宽。
命令:hdfs dfsadmin -setBalancerBandwidth 2000000
③查看进程
balancer 是一个 java 程序,可 jps 查看。
④查看 Balancer 的进展
除了通过 HDFS 页面中的存储变化来间接反映 balancer 的进展外,还可以通过日志来量化其进展。
命令:more /opt/boh-2.0.0/logs/hadoop/hadoop-hadoop-balancer-zchadoop002- 1.out
可以看到每次迁移中的待迁移数据 Bytes Left To Move 都在减少,说明balancer 在起作用。但为什么已完成的迁移量 Bytes Already Moved 一直是0 字节,还没搞清楚。
4.定时执行 balancer
因为 balancer 的速度由多方因素影响,我们不能保证当天的 balancer 在当天就能完成。又考虑到 balancer 有类似迅雷的“断点续传”特点,而且带宽在 balancer 中断后会失效,所以在每天的定时计划中的顺序是“停止昨天的 balancer→设置带宽(非必须)→启动今天的 balancer”。balancer 的运行时间段应当避开主机繁忙期。下图以xx集群的定时计划为例。
4.3、datanode 数据盘坏盘故障
以xx机房 hadoop056 出现坏盘为例
1.发现故障
目前发现数据坏盘的方式有两种,通过监控系统自动报警和在 CM 页面里肉眼观察。
自动报警:待定。
肉眼观察:在 HDFS 页面的 datanodes 目录 (132.35.xx.xx:5007 0/dfshealth.html#tab-datanode)里,观察 Failed Volumes 列的数值,若有非 0 值,则该值对应的 datanode 有坏盘。
2.停止 hadoop056 上的进程
以 Admin 身份登录 CM,进入 hadoop1-56 的进程页面,在右上方的“操作”里选择“停止主机上的角色”
3.通知硬件侧更换硬盘
4.换盘后的操作
①以 root 身份登录到 hadoop056 节点
②停止 cloudera-scm-agent
命令:/opt/cm-5.1.3/etc/init.d/cloudera-scm-agent stop
③返回 hadoop 用户,查看 datanode 进程是否已经停止
④切回 root,查看/data 目录,找到新换的盘。
属主和属组是 root 的磁盘就是被更换的新盘。
⑤在新换的磁盘目录 hdfsdsk01 下新建目录
在正常情况下,以 hdfsdsk02 为例,磁盘目录里应该有如下 5 个目录。
但是新加的磁盘是没有红框里的 4 个目录,需要我们手工创建。只创建第一级即可,它们下面的目录和文件会在 datanode 进程启动之后自动生成。
⑥修改新磁盘目录的属主和属组为 hadoop
命 令 :chown -R hadoop:hadoop /data/hdfsdsk01
改变属组和属主之后的效果
⑦启动 cloudera-scm-agent
命令:/opt/cm-5.1.3/etc/init.d/cloudera-scm-agent start
⑧返回 hadoop 用户,检查 datanode 进程是否已经启动
⑨二次确认
检查新换的盘是否还有坏卷
命令:fsck -y /data/hdfsdsk01
若还存在坏盘,则通知二线 xx 处理
4.4、datanode 数据盘存储超过阈值
收到告警短信,hadoop057 的第8块盘的存储率超过了 90%。
在/data 目录下执行 df -h,报警属实
【检查HDFS存储】
由于 datanode 单块磁盘的存储过高,导致整个集群的 HDFS 存储超过了75%。
反馈对应负责人进行数据清理
4.5、坏块处理
查看 HDFS 页面出现如下图报错即为有坏块
【处理方法】
首先登陆 DN 节点,执行 hadoop fsck /命令,查看集群坏块的状况,以及坏块的路径
执行 hadoop fsck / -delete 命令删除坏块
删完后再次执行 hadoop fsck /命令,查看集群坏块的状况
执行hadoop fs -setrep -R 2 /user/hive/warehouse/zbg_dwa.db 修 改 表 的副本数,这里副本数为 2(注:升副本的时候只升删除坏块的那个小表即可,目录越小越好)
执行Hadoop fsck /user/hive/warehouse/zbg_dwa.db 查看副本数是否正确
4.6、datanode 宕机
hadoop056 节点与cloudera manager失去联系时间过长。
通知硬件侧该节点宕机,经硬件侧同事确认是由于此节点电源故障导致宕机,随后他将节点重启
【重启后配置】
①以 root 身份登录到 hadoop056 节点
②停止 ntp 服务
③与 hadoop211 上的 NTP Server 同步
命令:ntpdate hadoop211
④将时间写到主板
命令:hwclock -w
⑤启动 ntp 服务
⑥启动 cloudera-scm-agent
命令:/opt/cm-5.1.3/etc/init.d/cloudera-scm-agent start
⑦检查 datanode 进程是否已经启动
返回到 hadoop 用户,执行 jps 命令。
⑧登录CM,启动 hadoop056 节点上的角色。
如未解决,联系二线处理
4.7、hdfs 目录被删除排查
XXX 告知 XXX 集群目录被删除,并提供了被删除目录,请求定位被谁删除
【 问题排查 】
HDFS 审计日志查看
2019-06-29 00:32:44,275 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/013 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/013perm=hdfs:ss_deploy:rwxrwxrwx proto=rpc
2019-06-29 00:40:55,525 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/011 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/011perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 00:41:20,228 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/017 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/017perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 00:54:54,697 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/031 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/031perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:03:05,264 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/018 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/018perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:08:24,077 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/034 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/034perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:10:29,977 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/038 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/038perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:13:28,904 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/036 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/036perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:31:42,517 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/051 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/051perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:34:22,650 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/075 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/075perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:36:09,417 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/071 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/071perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:40:21,424 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/076 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/076perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:51:24,962 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/079 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/079perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 01:51:58,956 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/083 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/083perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 02:00:20,934 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/081 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/081perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 02:09:09,425 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/086 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/086perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
2019-06-29 02:10:34,062 INFO FSNamesystem.audit: allowed=true ugi=hdfs (auth:SIMPLE)ip=/10.191.xxx.xxx cmd=rename options=2 src=/serv/smartsteps/raw/events/locationevent/2019/06/28/087 dst=/user/hdfs/.Trash/Current/serv/smartsteps/raw/events/locationev ent/2019/06/28/087perm=hdfs:ss_deploy:rwxr-xr-xproto=rpc
4.8、MaxDirectoryItemsExceededException
hdfs 目录存储最大文件数异常 MaxDirectoryItemsExceededException
1.org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.prot ocol.FSLimitException$MaxDirectoryItemsExceededException): The directory item limit of /XXX/XXX/FF is exceeded: limit=1048576 items=1048576
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.verifyMaxDirIte ms(FSDirectory.java:2060)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.addChild(FSDire ctory.java:2112)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.addLastINode(F SDirectory.java:2081)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.addINode(FSDir ectory.java:1900)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.addFile(FSDirect ory.java:327)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInter nal(FSNamesystem.java:2794)
【问题处理】
更改 hdfs-site.xml 添加如下
<property>
<name>dfs.namenode.fs-limits.max-directory-items</name>
<value>1048576</value>
<description>Defines the maximum number of items that a directory may than contain. Cannot set the property to a value less than 1 or more 6400000.</description>
</property>
把这个配置添加到 hdfs-site.xml 中,把值设置为大一些,问题搞定。不过在此也存在一个问题,这个 HDFS 的限制有个范围,最多不能超过6400000,因此后续还要考虑到历史数据的删除。

