

从0到1复现斯坦福羊驼(Stanford Alpaca 7B)

近日,Meta开源了他们的LLaMA系列模型,包含了参数量为7B/13B/33B/65B的不同模型,然而,原模型的效果较差(如生成的结果文不对题、以及无法自然地结束生成等)。因此,斯坦福的 Alpaca 模型基于 LLaMA-7B 和指令微调,仅使用约 5 万条训练数据,就能达到类似 GPT-3.5 的效果。
该项目提供了廉价的对LLaMA模型进行微调的方法,大体思路如下:
首先,利用OpenAI提供的GPT模型API生成质量较高的指令数据(仅52k),例如:
{
"instruction": "Rewrite the following sentence in the third person",
"input": "I am anxious",
"output": "She is anxious."
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
然后,基于这些指令数据使用HuggingFace Transformers框架精调LLaMA-7B模型。
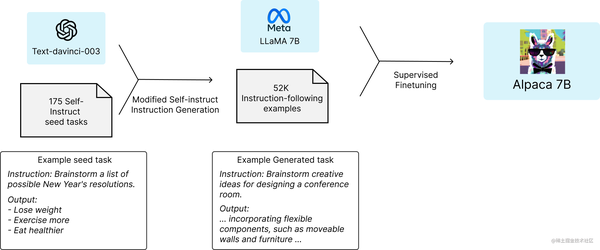
下面基于 LLaMA-7B 尝试复现 Alpaca,相关代码放置在GitHub上面: llm-action 。
环境搭建
基础环境配置如下:
- 操作系统: CentOS 7
- CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
- GPUs: 8 卡 A800 80GB GPUs
- Python: 3.10 (需要先升级OpenSSL到1.1.1t版本( 点击下载OpenSSL ),然后再编译安装Python), 点击下载Python
- NVIDIA驱动程序版本: 470.161.03,根据不同型号选择不同的驱动程序, 点击下载 。
- CUDA工具包: 11.3, 点击下载
- NCCL: 2.9.9-1, 点击下载
- cuDNN: v8.2.0, 点击下载
上面的NVIDIA驱动、CUDA、Python等工具的安装就不一一赘述了。
新建并激活虚拟环境llama-venv-py310。
cd /home/guodong.li/virtual-venv
virtualenv -p /usr/bin/python3.10 llama-venv-py310
source /home/guodong.li/virtual-venv/llama-venv-py310/bin/activate
离线安装PyTorch, 点击下载 对应cuda版本的torch和torchvision即可。
pip install torch-1.12.1+cu113-cp310-cp310-linux_x86_64.whl
pip install torchvision-0.13.1+cu113-cp310-cp310-linux_x86_64.whl
安装transformers,目前,LLaMA相关的 实现 并没有发布对应的版本,但是已经合并到主分支了,因此,我们需要切换到对应的commit,从源代码进行相应的安装。
cd transformers
git checkout 0041be5
pip install .
安装apex。
git clone https://github.com/NVIDIA/apex.git
cd apex
git checkout 22.04-dev
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
其他其他相关的库。
pip install -r requirements.txt
requirements.txt
文件具体的内容如下。
numpy
rouge_score
openai
sentencepiece
tokenizers==0.12.1
wandb
deepspeed==0.8.0
accelerate
tensorboardX
通过Dokcer镜像构建模型训练推理环境
如果想避免在物理机上面构建训练环境的繁琐过程,也可直接基于Dokerfile构建环境。
第一步,编写alpaca.Dockerfile文件:
FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel
MAINTAINER guodong.li liguodongiot@163.com
ENV APP_DIR=/workspace
RUN mkdir -p -m 777 $APP_DIR
RUN pip install --no-cache-dir \
transformers==4.28.1 numpy rouge_score fire openai sentencepiece tokenizers==0.13.3 wandb deepspeed==0.8.0 accelerate tensorboardX \
-i https://pypi.tuna.tsinghua.edu.cn/simple \
--trusted-host pypi.tuna.tsinghua.edu.cn
COPY apex ${APP_DIR}/apex
RUN apt-get update && apt-get -y install nvidia-cuda-dev
RUN cd ${APP_DIR}/apex && pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" . && cd .. && rm -rf ${APP_DIR}/apex
WORKDIR $APP_DIR
第二步,构建Docker镜像。
docker build -f alpaca.Dockerfile -t stanford_alpaca:v3 .
第三步:基于Docker镜像创建模型训练和推理容器。
docker run -dt --name stanford_alpaca_v3 --restart=always --gpus all --network=host \
-v /home/gdong/code:/code \
-v /home/gdong/model:/model \
-v /home/gdong/output:/output \
-w /code \
stanford_alpaca:v3 \
/bin/bash
第四步,进入Docker容器。
docker exec -it stanford_alpaca_v3 bash
模型格式转换
将LLaMA原始权重文件转换为Transformers库对应的模型文件格式。
cd transformers
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /data/nfs/guodong.li/pretrain/llama-model \
--model_size 7B \
--output_dir /data/nfs/guodong.li/pretrain/hf-llama-model
转换之后会生成tokenizer和llama-7b(模型权重文件)两个目录。可以通过以下方式加载模型和分词器:
tokenizer = transformers.LlamaTokenizer.from_pretrained("/data/nfs/guodong.li/pretrain/hf-llama-model/tokenizer/")
model = transformers.LlamaForCausalLM.from_pretrained("/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b/")
LLaMA 分词器(tokenizer)基于
sentencepiece
分词工具。 sentencepiece在解码序列时,如果第一个token是单词(例如:
Banana
)开头,则tokenizer不会在字符串前添加前缀空格。 要让tokenizer输出前缀空格,请在
LlamaTokenizer
对象或tokenizer配置中设置
decode_with_prefix_space=True
。
这里将tokenizer目录的文件拷贝到llama-7b目录下。
cp tokenizer/* llama-7b/
注: 如果不想转换也可以直接从Hugging Face下载转换好的 模型 。
数据集准备
Stanford Alpaca
中的
alpaca_data.json
文件即是他们用于训练的指令数据集,我们可以直接使用该数据集进行模型精调。但是在
Alpaca-LoRA
中提到该数据集存在一些噪声,因此,他们对该数据集做了清洗后得到了
alpaca_data_cleaned.json
文件。采用该数据集进行训练大概率会得到更好结果。
模型精调
Stanford Alpaca 使用 Hugging Face 训练代码微调的LLaMA模型。 微调 LLaMA-7B 和 LLaMA-13B 的超参数如下表所示:
| 超参数 | LLaMA-7B | LLaMA-13B |
|---|---|---|
| Batch size | 128 | 128 |
| 学习率 | 2e-5 | 1e-5 |
| Epochs | 3 | 5 |
| Max length | 512 | 512 |
| Weight decay | 0 | 0 |
本文未使用PyTorch FSDP是因为当前环境的Cuda版本为11.3,且PyTorch版本为1.12.1,运行会报错。 Cuda版本升级到11.6及以上,且PyTorch版本升级为1.13.1及以上,应该不会有问题(后来在cuda-11.7和torch-1.13.1上面进行过验证,确实没问题) ,具体命令如下:
torchrun --nproc_per_node=8 --master_port=25001 train.py \
--model_name_or_path /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b \
--data_path /data/nfs/guodong.li/data/alpaca_data_cleaned.json \
--bf16 True \
--output_dir /data/nfs/guodong.li/output/alpaca/sft_7b \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "tensorboard" \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True
在这里,我们使用DeepSpeed框架来减少显存占用和提高训练效率。
git clone https://github.com/tatsu-lab/stanford_alpaca.git
cd stanford_alpaca
修改
train.py
文件:
# 注释掉原有代码
model = transformers.AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
# 通过Llama加载tokenizer和model
model = transformers.LlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
tokenizer = transformers.LlamaTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
trainer.save_state()
# safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir)
trainer.save_model()
启动命令:
torchrun --nproc_per_node=8 --master_port=11223 train.py \
--model_name_or_path /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b \
--data_path /data/nfs/guodong.li/data/alpaca_data_cleaned.json \
--output_dir /data/nfs/guodong.li/output/alpaca/sft_7b \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "tensorboard" \
--gradient_checkpointing True \
--fp16 True \
--deepspeed ds_config.json
其中,
ds_config.json
文件内容如下所示:
{
"zero_optimization": {
"stage": 3,
"contiguous_gradients": true,
"stage3_max_live_parameters": 0,
"stage3_max_reuse_distance": 0,
"stage3_prefetch_bucket_size": 0,
"stage3_param_persistence_threshold": 1e2,
"reduce_bucket_size": 1e2,
"sub_group_size": 1e8,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
"offload_param": {
"device": "cpu",
"pin_memory": true
"stage3_gather_16bit_weights_on_model_save": true
"fp16": {
"enabled": true,
"auto_cast": false,
"loss_scale": 0,
"initial_scale_power": 32,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
运行过程:
torchrun --nproc_per_node=8 --master_port=11223 train.py \
> --model_name_or_path /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b \
> --data_path /data/nfs/guodong.li/data/alpaca_data_cleaned.json \
> --output_dir /data/nfs/guodong.li/output/alpaca/sft_7b \
--per_device_eval_batch_size 1 \
> --num_train_epochs 1 \
> --per_device_train_batch_size 4 \
> --per_device_eval_batch_size 1 \
> --gradient_accumulation_steps 4 \
> --evaluation_strategy "no" \
> --save_strategy "steps" \
> --save_steps 1000 \
> --save_total_limit 1 \
> --learning_rate 2e-5 \
> --weight_decay 0. \
> --warmup_ratio 0.03 \
> --lr_scheduler_type "cosine" \
> --logging_steps 1 \
> --report_to "tensorboard" \
> --gradient_checkpointing True \
> --fp16 True \
> --deepspeed ds_config.json
WARNING:torch.distributed.run:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
[2023-03-28 11:13:02,320] [INFO] [comm.py:657:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
[2023-03-28 11:13:20,236] [INFO] [partition_parameters.py:413:__exit__] finished initializing model with 6.74B parameters
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:41<00:00, 1.26s/it]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:41<00:00, 1.26s/it]
Using pad_token, but it is not set yet.
Using pad_token, but it is not set yet.
WARNING:root:Loading data...
WARNING:root:Loading data...
WARNING:root:Formatting inputs...
WARNING:root:Formatting inputs...
WARNING:root:Tokenizing inputs... This may take some time...
WARNING:root:Tokenizing inputs... This may take some time...
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
Emitting ninja build file /home/guodong.li/.cache/torch_extensions/py310_cu113/utils/build.ninja...
Building extension module utils...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
ninja: no work to do.
Loading extension module utils...
Loading extension module utils...
Time to load utils op: 0.10286140441894531 seconds
Time to load utils op: 0.20401406288146973 seconds
Parameter Offload: Total persistent parameters: 0 in 0 params
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...Loading extension module utils...
Time to load utils op: 0.0004200935363769531 seconds
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
Time to load utils op: 0.0003352165222167969 seconds
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0003571510314941406 seconds
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0006623268127441406 seconds
Time to load utils op: 0.0005290508270263672 seconds
Time to load utils op: 0.0006077289581298828 seconds
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.001024484634399414 seconds
Using /home/guodong.li/.cache/torch_extensions/py310_cu113 as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0003275871276855469 seconds
{'loss': 1.5163, 'learning_rate': 0.0, 'epoch': 0.01}
{'loss': 1.5216, 'learning_rate': 0.0, 'epoch': 0.02}
{'loss': 1.0547, 'learning_rate': 2.025571894372794e-06, 'epoch': 0.98}
{'loss': 1.0329, 'learning_rate': 1.8343633694278895e-06, 'epoch': 0.99}
{'loss': 1.0613, 'learning_rate': 1.6517194697072903e-06, 'epoch': 1.0}
{'train_runtime': 4605.8781, 'train_samples_per_second': 11.277, 'train_steps_per_second': 0.022, 'train_loss': 1.175760779050317, 'epoch': 1.0}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 101/101 [1:16:45<00:00, 45.60s/it]
GPU显存占用情况:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.161.03 Driver Version: 470.161.03 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800 80G... Off | 00000000:34:00.0 Off | 0 |
| N/A 47C P0 75W / 300W | 66615MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A800 80G... Off | 00000000:35:00.0 Off | 0 |
| N/A 46C P0 70W / 300W | 31675MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A800 80G... Off | 00000000:36:00.0 Off | 0 |
| N/A 49C P0 72W / 300W | 35529MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A800 80G... Off | 00000000:37:00.0 Off | 0 |
| N/A 50C P0 76W / 300W | 54277MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 NVIDIA A800 80G... Off | 00000000:9B:00.0 Off | 0 |
| N/A 51C P0 80W / 300W | 44229MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 NVIDIA A800 80G... Off | 00000000:9C:00.0 Off | 0 |
| N/A 49C P0 72W / 300W | 59841MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 6 NVIDIA A800 80G... Off | 00000000:9D:00.0 Off | 0 |
| N/A 47C P0 77W / 300W | 65217MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 7 NVIDIA A800 80G... Off | 00000000:9E:00.0 Off | 0 |
| N/A 43C P0 68W / 300W | 30141MiB / 80994MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 30534 C ...lama-venv-py310/bin/python 66593MiB |
| 1 N/A N/A 30535 C ...lama-venv-py310/bin/python 31653MiB |
| 2 N/A N/A 30536 C ...lama-venv-py310/bin/python 35507MiB |
| 3 N/A N/A 30537 C ...lama-venv-py310/bin/python 54255MiB |
| 4 N/A N/A 30540 C ...lama-venv-py310/bin/python 44207MiB |
| 5 N/A N/A 30541 C ...lama-venv-py310/bin/python 59819MiB |
| 6 N/A N/A 30542 C ...lama-venv-py310/bin/python 65195MiB |
| 7 N/A N/A 30543 C ...lama-venv-py310/bin/python 30119MiB |
+-----------------------------------------------------------------------------+
模型推理
编写模型推理脚本
inference.py
:
import sys
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
model_path = str(sys.argv[1]) # You can modify the path for storing the local model
print("loading model, path:", model_path)
model = LlamaForCausalLM.from_pretrained(model_path, device_map='auto', low_cpu_mem_usage=True)
tokenizer = LlamaTokenizer.from_pretrained(model_path)
print("Human:")
line = input()
while line:
inputs = 'Human: ' + line.strip() + '\n\nAssistant:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids
input_ids = input_ids.cuda()
outputs = model.generate(input_ids, max_new_tokens=100, do_sample = True, top_k = 30, top_p = 0.85, temperature = 0.5, repetition_penalty=1., eos_token_id=2, bos_token_id=1, pad_token_id=0)
rets = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print("Assistant:\n" + rets[0].strip().replace(inputs, ""))
print("\n------------------------------------------------\nHuman:")
line = input()
编写完成完成之后,运行脚本(需自行指定模型训练时生成的权重目录):
CUDA_VISIBLE_DEVICES=1 python inference.py /output/alpaca_sft_7b
测试过程:
> CUDA_VISIBLE_DEVICES=1 python inference.py /output/alpaca_sft_7b
loading model, path: /output/alpaca_sft_7b
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████| 3/3 [00:39<00:00, 13.07s/it]
Human:
写一首中文歌曲,赞美大自然
Assistant:
你的歌词是怎么样?
------------------------------------------------
Human:
推荐几本金庸的武侠小说
Assistant: