时间序列数据库是目前技术发展最快的数据库类型之一。作为业界最为流行的时序数据库InfluxDB,其部署运行十分简洁方便,支持高性能时序数据的读写,在应用程序监控、物联网(IoT)领域有着广泛的应用。
阿里云InfluxDB®是基于开源版InfluxDB优化的版本,内部的数据组织保持与开源版本一致,可以简单概括为索引与数据两部分。用户使用Influxql语句进行数据查询,InfluxDB会解析这条语句并生成AST语法树,通过语法树的遍历,找到需要查询的measurement、tag kv等关键元数据信息,通过InfluxDB的索引找到对应的时序数据所在的文件(TSM),获得数据点,返回给用户。而索引的实现有两种,一种是基于内存的倒排索引(inmem),使用上受限于内存,如果出现宕机的情况,需要扫描解析所有TSM文件并在内存中重新构建,恢复时间很长;另一种则是基于文件的倒排索引(TSI),内存占用较小,可以支持百万甚至千万级别的时间线,宕机恢复影响也很小。
本文将基于文件倒排索引(TSI)的索引类型,深入介绍用户一次数据查询,在InfluxDB内部的流程细节。
Query入口
InfluxDB内部注册了许多服务,其中httpd service是负责处理外部请求的服务,通常情况下,读写请求都会到达services/httpd/handler.go这里。对于select语句来说,调用的是serveQuery。
查询的准备工作,包括计数器的更新、参数解析、解析生成AST树、认证4个方面。
1、计数统计
计数统计方面,查询计数器h.stats.QueryRequests自增1。其次定义一个defer,用于在结束时统计当前查询的耗时。
defer func(start time.Time) {
atomic.AddInt64(&h.stats.QueryRequestDuration, time.Since(start).Nanoseconds())
}(time.Now())
2、参数解析
Influxdb需要对query提交的表单解析若干关键配置参数,才能确定访问的数据库、存储策略、输出格式等详细信息:
node_id
集群版节点id,单机版无效
epoch
查询输出格式,可选值有epoch=[h,m,s,ms,u,ns]
待查询数据库
待查询存储策略
params
chunked
用于控制返回流式批处理中的点而不是单个响应中的点。如果设置为true,InfluxDB将按系列或每chunk_size个点(默认10000)分组响应。
chunk_size
分组相应点数大小
async
是否同步查询返回
3、生成AST树
对于从表单提取的查询语句,InfluxDB有自己的一套Influxql解析框架,可生成类似传统关系型数据库内的AST树。由于Influxql部分代码庞大,与查询逻辑核心关系不大,本文不做展开。
4、认证
出于安全考虑,用户可能开启了InfluxDB的认证配置。只有对应权限的用户以及匹配正确密码之后,才能访问相关的数据库。
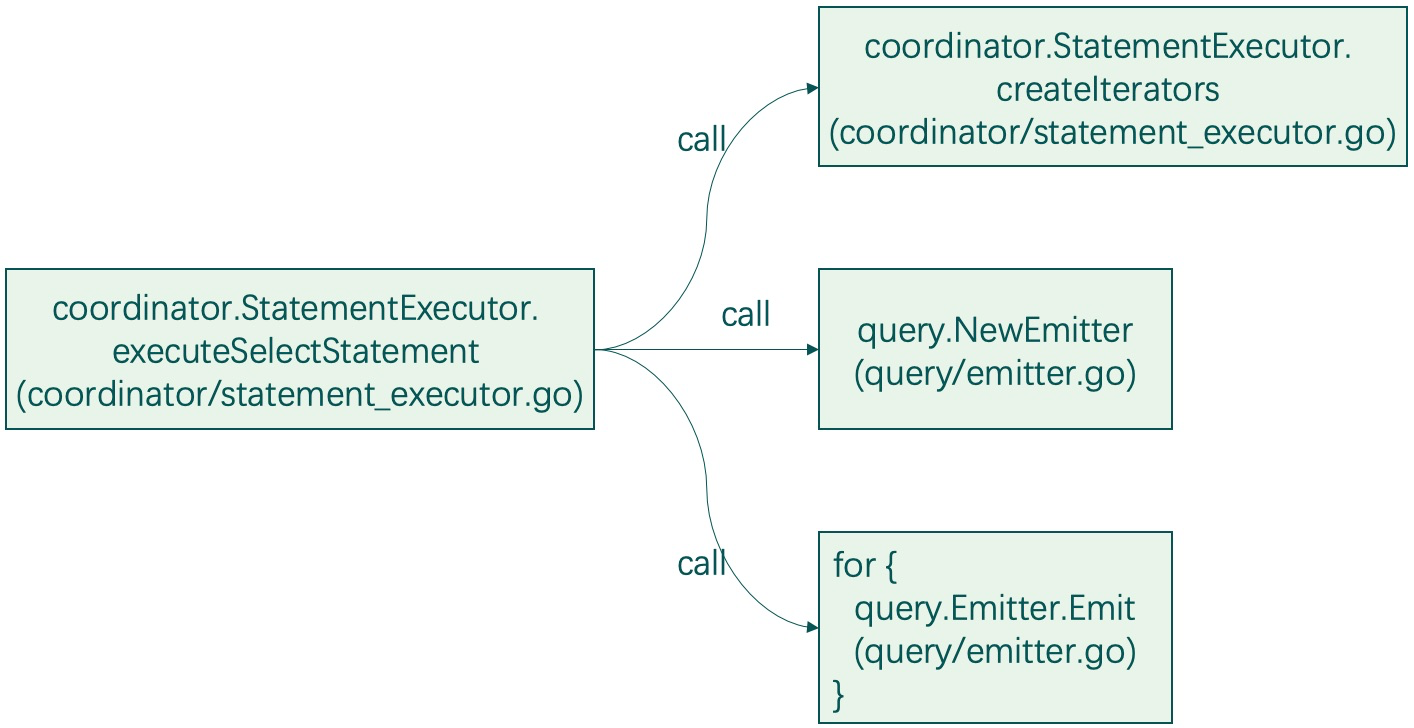
准备工作完成后,最终会执行coordinator/statement_executor.go的executeSelectStatement函数,这个函数是处理查询语句的。从services/httpd/handler.go的serveQuery到coordinator/statement_executor.go的executeSelectStatement,经过了多层的函数调用。为了方便读者阅读代码,下图展示了调用的堆栈(如若遇到go interface部分的函数调用,下图已替换为真正实现interface的结构体的函数)。
在executeSelectStatement函数内部,有几个关键操作:
(1)创建迭代器createIterators,创建过程中内部通过TSI访问TSM并decode部分数据内容(“细节探究:迭代器与TSI、TSM”小节深入分析);
(2)创建基于迭代器的Emitter,通过Emitter函数中循环调用cursor的Scan()函数从cursor中一条一条数据地进行读取。
以下是Emitter读取数据时可能遇到的几种情况:
(a)如果是多个series,则一般是第1个series拿1个数据,然后第2个拿1个数据......拿完后,第1个series再拿第2个数据,以此类推;
(b)当返回数据达到了查询设置的chunkSize(查询参数中没有,则使用默认的10000)时,提前先返回,以此来做到分批返回结果;
(c)如果是查询类似count这种聚合操作,那可能从cur中一共也就返回1条结果数据,聚合工作放在了相关iterator的reducer操作中;
(d)如果已经decode的数据被读取完,还需要继续读取,则会迫使cur再次做底层TSM文件的decode。直到完成需要的数据读取。
当查询结束后,同步情况下从管道依次取出结果。并处理chunked协议等返回协议,最终返回给用户。
细节探究:迭代器与TSI、TSM
CreateIterator
我们提到执行select的主函数executeSelectStatement一个关键操作是创建迭代器(或者说是游标)cursor,这一思想与传统关系型数据库执行计划树的执行过程有相似之处。cursor的创建依赖于查询准备工作中由InfluxQL解析生成的AST树(SelectStatement)。创建过程也类似于传统关系型数据库,分为Prepare、Select两部,其中Prepare过程还可以细分为Compile与Compile之后的Prepare;Select则是基于Prepare后的SelectStatement来构建迭代器。
Prepare过程
Prepare过程先执行了Compile,Compile主要进行以下操作:
1、预处理,主要是解析、校验和记录当前查询状态的全局属性,例如解析查询的时间范围、校验查询条件合法性、校验聚合条件的合法性等等。
2、fields预处理,例如查询带time字段的会自动替换为timstamp。
3、重写distinct查询条件。
4、重写正则表达式查询条件。
Compile之后的Prepare主要进行以下操作:
1、如果查询带聚合,且配置了max-select-buckets限制,且查询时间范围下界未指定时,需要根据限制重写查询时间范围下界。
2、如果配置了额外的查询间隔配置,修正查询时间范围上下界。
3、根据时间上下界获取需要查询的shards map(LocalShardMapping结构体对象)。
4、如果是模糊查询则替换*为所有可能的tag key与field key(获取tag key时,实际上已经访问了TSI索引)。
5、校验查询类型是否合法。
6、确定与查询间隔(group by time())匹配的开始和结束时间并再次校验查询buckets是否超过了max-select-buckets配置项。
Select过程
在InfluxDB内部,由5种Iterator,它们分别是buildFieldIterator、buildAuxIterator、buildExprIterator、buildCallIterator和buildVarRefIterator。它们根据不同的查询产生不同的创建过程,彼此组成互相调用的关系,并组成了最终的cursor。
在Select函数构建cursor的过程中,调用不断向下,我们最终会来到Engine.CreateIterator函数的调用。Engine与一个shard对应,如果查询跨多个shard,在外层会遍历所有涉及本次查询的shards(LocalShardMapping),对每个shard对应的Engine执行CreateIterator,负责查询落在本shard的数据。根据查询究竟是查数据,还是聚合函数,Engine.CreateIterator里会调用createVarRefIterator或者createCallIterator。
它们最终都会调用createTagSetIterators函数,调用之前,会查询出所有的series作为调用参数(这里访问了索引TSI)。接下来,程序会以series和cpu核数的较小值为除数平分所有的series,然后调用createTagSetGroupIterators函数继续处理,其内部会对分配到的series进行遍历,然后对每一个seriesKey调用createVarRefSeriesIterator函数。在createVarRefSeriesIterator函数中,如果ref有值,则直接调用buildCursor函数。如果ref为nil,则opt.Aux参数包含了要查询的fields,所以对其进行遍历,对每个feild,再调用buildCursor函数。
buildCursor函数中,先根据measurement查询到对应的fields,再根据field name从fields中查询到对应的Field结构(包含feild的ID、类型等)。然后,根据field是什么类型进行区别,比如是float类型,则调用buildFloatCursor函数。各类型的buildCursor底层调用的实际是TSM文件访问的函数,新建cursor对象时(newKeyCursor)使用fs.locations函数返回所有匹配的TSM文件及其中的block(KeyCursor.seeks),读取数据时则是根据数据类型调用peekTSM()、nextTSM()等TSM访问函数。
查询倒排索引TSI
我们先看一张基于TSI的InfluxDB索引组织图(如下所示)。其中db(数据库)、rp(存储策略)、shard、Index在文件组织下都是以目录形式表现,TSI使用了分区策略,所以在Index文件夹下是0~7共计8个partition文件夹,partition文件夹则是TSI文件与它的WAL(TSL):
TSI采用了类LSM机制,操作都是以append-only方式以LogEntry格式写入到WAL(TSL文件,其对应的level为0),修改和删除操作也是如此,在后台compaction(Level0 ~ Level 1)的过程中会进行真正的数据删除。当TSL文件执行compaction操作时,实际上是将WAL以TSI格式转化写入一个新的TSI文件中。TSI文件(Level1-Level6)会定期由低层向高层作compact, compact的过程本质是将相同measurement的tagbock作在一起,相同measurement的相同tagkey对应的所有tagvalue放在一起, 相同measurement的相同tagkey又相同tagvalue的不同series id 作合并后放在一起。
我们来看一下TSI文件的内部结构,以便了解当执行查询时,InfluxDB是如何使用它来找到对应measurement、tag key、tag value以及相关数据文件TSM的。
index_file
首先我们看到tsdb/index/tsi1/index_file.go有一个很有意思的常量IndexFileTrailerSize。
IndexFileTrailerSize = IndexFileVersionSize +
8 + 8 + // measurement block offset + size
8 + 8 + // series id set offset + size
8 + 8 + // tombstone series id set offset + size
8 + 8 + // series sketch offset + size
8 + 8 + // tombstone series sketch offset + size
从它的定义我们很容易得出:
1、IndexFileTrailerSize在TSI文件结尾处占固定的82bytes,我们在解析TSI时很容易读取到这个Trailer.
2、通过它的定义我们基本知道了一个TSI包含哪些部分:
这里我们仔细分析1.7以后的代码,发现一个很有趣的问题,series id set这个区域在查询期间没有起到由series id去查series key的作用。实际上在1.7的influxdb,有一个特殊文件夹_series,在这个文件夹中才存放了series id到series key的映射。measurement block
我们再来看measurement block,其定义是在tsdb/index/tsi1/measurement_block.go,我们也很容易发现measurement block也是由存储类似meta信息的Trailer以及其他各部分组成。
MeasurementTrailerSize = 0 +
2 + // version
8 + 8 + // data offset/size
8 + 8 + // hash index offset/size
8 + 8 + // measurement sketch offset/size
8 + 8 // tombstone measurement sketch offset/size
(1)Trailer部分是整个MeasuermentBlock的索引,存储着其他部分的offset和size。
(2)data offset/size部分,是所有的MeasurementBlockElement的集合。MeasurementBlockElement内包含了measurement的名字、对应tag的集合以及在文件中的offset和size、当前measurement下所有的series id信息。
(3)hash index部分以hash索引方式存储了MeasurementBlockElement在文件中的offset,可在不读取整体tsi的情况下快速定位某个MeasurementBlockElement文件偏移。
(4)measurement sketch和tombstone measurement sketch是使用HyperLogLog++算法来作基数统计用。
Tag block
我们再来看Tag block,其定义是在tsdb/index/tsi1/tag_block.go中,同样有类似的trailer定义:
const TagBlockTrailerSize = 0 +
8 + 8 + // value data offset/size
8 + 8 + // key data offset/size
8 + 8 + // hash index offset/size
8 + // size
2 // version
(1)Trailer相当于tag block的meta信息,保存其它各组成部分的offset和大小。
(2)key data部分是tag key数据块部分,其内部有二级hash index,可以通过tag key快速定位到指定tag key block部分,Data offset,Data size部分指向了当前tag key对应的所有的tag value block文件区域。
(3)value data的设计与key data部分类似。在tag value block的内部,有我们最关注的series id set。
(4)hash index部分,可以通过tag key快速定位到tag key block的offsset。
_series文件夹
原series id set区域用于存储整个数据库中所有的SeriesKey,这可能是历史遗留的问题。1.7.7版本的influxdb,有一个特殊文件夹_series,在这个文件夹中才存放了series id到series key的映射。
查看_series文件夹目录结构,也是和tsi类似,分为8个partition。最新版本的influxdb通过_series文件夹的series文件检索series id到series key的映射。
分组并发
根据TSI文件倒排索引查询得到所有的SeriesKey之后,要根据groupby条件对SeriesKey进行分组,分组算法为hash。分组后不同group的SeriesKey允许并行独立执行查询并最终执行聚合的,借此大幅提升整个查询的性能。
最后我们来总结一下,TSI文件格式的设计,是一种多级索引的方式,每一层级都设计了Trailer,方便快速找到不同区域的偏移;每个分区内又有各自的Trailer,measurement block、Tag block、Tag block下的key data都设计了hash索引加快查询文件偏移。
对于一次查询,我们根据measurement在measurement block中找到对应MeasurementBlockElement下的tag set,根据查询条件中tag key进行过滤,再在对应的tag block中找到关联的全部tag value block。在tag value block中取得series id set,根据series id到_serise文件夹找到本次查询涉及到的全部SeriesKey。
TSM数据检索
我们先来看一下TSM的设计。一个TSM被设计为4个区域:Header、Blocks、Index和Footer。
其中Header是4位的magic number(用于定义文件类型)以及1个1位的版本号。
在Blocks区域,是一系列独立的数据Block组成,每个Block包含一个CRC32算法生成的checksum保证block的完整性。data内部,时间戳与数据分开存储,按不同的压缩算法进行压缩。拆解图如下:

在Index区域,存放的是Blocks区域的索引。Index区由一系列的index entries组成,它们先按key后按时间戳、以字典顺序排序。一条index entry内部组成包括:key长度、key、数据类型、当前blocks数量、本block的最大最小时间、block文件偏移、block长度。

footer区域存储索引区的文件偏移。
TSM文件的索引层,在InfluxDB启动之后就会全部加载到内存之中,数据部分则因消耗内存过大不加载。数据检索一般安装以下几个步骤执行:
1、首先根据TSI查询获得的所有SeriesKey找到所有对应的Index中的Index Entry,由于Key是有序的,因此可以使用二分查找来具体实现。
2、找到所有Index Entry之后,再根据查找的时间范围,使用[MinTime, MaxTime]过滤剩余需要的Index Entries。
3、通过Index Entries定位到可能的Data Blocks列表。
4、将满足条件的Data Blocks加载到内存中,用对应数据类型的解压算法解压数据,进一步使用二分查找算法查找即可找到。
总结
InfluxDB的查询流程是一个较为复杂的过程,源码实现的逻辑精妙、模块划分清晰,很适合时序数据库领域的开发者深入学习其中思想。由于篇幅有限,本文涉及到的部分并不完整,很多细节需要读者在阅读过程中参照社区开源代码对比研究,由于笔者学识有限也可能有描述失误的地方,欢迎大家斧正。
阿里云InfluxDB®现已正式商业化,欢迎访问购买页面(https://common-buy.aliyun.com/?commodityCode=hitsdb_influxdb_pre#/buy)与文档(https://help.aliyun.com/document_detail/113093.html?spm=a2c4e.11153940.0.0.57b04a02biWzGa)。
[-] .\Navicat-Cracker NavicatCrackerDlg.cpp:332 -3All patch solutions are suppressed. Patch abort!HI
阿里云电脑无影云桌面价格及购买流程(3分钟攻略)
阿里云电脑无影云桌面价格及购买流程(3分钟攻略),阿里云无影云电脑即无影云电脑,云电脑如何使用?云电脑购买后没有用户名和密码,先创建用户设置密码,才可以登录连接到云电脑。云电脑想要访问公网还需要开通互联网访问功能。阿里云百科来详细说下阿里云无影云电脑从购买、创建用户名密码和访问互联网全过程
阿里云域名创建信息模板流程
阿里云域名创建信息模板流程,阿里云域名注册域名持有者个人或企业都需要有已经通过实名认证的信息模板,如果没有可用的信息模板,需要先创建信息模版,等待信息模板实名通过后才可以注册域名,阿里云百科来详细说下阿里云注册域名创建信息模板实名全过程
阿里云PostgreSQL简介和购买流程
阿里云关系型数据库RDS(Relational Database Service)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和SSD盘高性能存储,RDS支持MySQL、SQL Server、PostgreSQL和MariaDB引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼。
阿里云云原生多模数据库Lindorm简介和购买流程
Lindorm是面向物联网、互联网、车联网等设计和优化的云原生多模超融合数据库,支持宽表、时序、文本、对象、流、空间等多种数据的统一访问和融合处理,并兼容SQL、HBase/Cassandra/S3、TSDB、HDFS、Solr、Kafka等多种标准接口和无缝集成三方生态工具,是日志、监控、账单、广告、社交、出行、风控等场景首选数据库
阿里云图数据库GDB简介和购买流程
图数据库(Graph Database,简称GDB)是一种支持Property Graph图模型、用于处理高度连接数据查询与存储的实时、可靠的在线数据库服务。它支持Apache TinkerPop Gremlin查询语言,可以帮您快速构建基于高度连接的数据集的应用程序。
图数据库GDB非常适合社交网络、欺诈检测、推荐引擎、知识图谱、网络/IT运营这类高度互连数据集的场景。例如,在一个典型的社交网络中,常常会存在“谁认识谁,上过什么学校,常住什么地方,喜欢什么餐馆”之类的查询,传统关系型数据库对于超过3张表关联的查询十分低效难以胜任,但图数据库可轻松应对社交网络的各种复杂存储和查询场景
阿里云数据湖分析简介和购买流程
云原生数据湖分析(简称DLA)是新一代大数据解决方案,采取计算与存储完全分离的架构,支持数据库(RDS\PolarDB\NoSQL)与消息实时归档建仓,提供弹性的Spark与Presto,满足在线交互式查询、流处理、批处理、机器学习等诉求,也是传统Hadoop方案上云的有竞争力的解决方案。
阿里云数据传输服务DTS简介和购买流程
数据传输服务DTS(Data Transmission Service)是阿里云提供的实时数据流服务,支持关系型数据库(RDBMS)、非关系型的数据库(NoSQL)、数据多维分析(OLAP)等数据源间的数据交互,集数据同步、迁移、订阅、集成、加工于一体,助您构建安全、可扩展、高可用的数据架构。
阿里云日志服务SLS简介和购买流程
日志服务SLS是云原生观测与分析平台,为Log、Metric、Trace等数据提供大规模、低成本、实时的平台化服务。日志服务一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等功能,全面提升您在研发、运维、运营、安全等场景的数字化能力
阿里云文件存储NAS简介和购买流程
阿里云文件存储NAS是一个可共享访问,弹性扩展,高可靠,高性能的分布式文件系统。兼容POSIX文件接口,可支持上千台弹性计算ECS、容器服务ACK等计算节点共享访问,您无需修改应用程序,即可无缝迁移业务系统上云。
支持智能冷热数据分层,有效降低数据存储成本。广泛应用于企业级应用数据共享、容器、AI机器学习、Web 服务和内容管理、应用程序开发和测试、媒体和娱乐工作流、数据库备份等场景。
阿里云 Elasticsearch简介和购买流程
开源Elasticsearch是一个基于Lucene的实时分布式的搜索与分析引擎,是遵从Apache开源条款的一款开源产品,是当前主流的企业级搜索引擎。作为一款基于RESTful API的分布式服务,Elasticsearch可以快速地、近乎于准实时地存储、查询和分析超大数据集,通常被用来作为构建复杂查询特性和需求强大应用的基础引擎或技术。
阿里云DataV数据可视化简介和购买流程
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
一,阿里云域名简介
互联网年代,如果你是上线一个web的网页项目,那么作为用户,需要访问这个web项目,需要再浏览器输入域名来访问。例如,你在浏览器输入:www.aliyun.com,就可以访问阿里云这个web项目。
如果你上线一个小程序和APP,那么在前端和后台做数据交互的时候,也需要域名的形式,部署接口,然后做数据的交互。
总得来说,域名是互联网的根基,是上线软件项目的必选之一,当然很好的域名更是企业的一种形象的展示。
阿里云ECS简介以及购买和使用流程
阿里云 ECS是阿里云推出的一款云计算产品,用于在云端提供计算资源和存储服务。它为开发者和企业提供了一个高效、可靠、安全的计算平台,可以轻松地管理和扩展应用程序。 ECS采用了分布式架构和多节点部署,具有高可用性和弹
阿里云短信是阿里云推出的一项企业级短信服务,可以帮助企业快速、便捷地实现与员工、客户、合作伙伴之间的短信沟通和信息传递。
阿里云短信支持个性化短信模板、自定义签名、短信分组管理、群发短信等功能,可以满足不同企业的短信需求。同时,阿里云短信还提供了高并发能力、海量存储、稳定安全的短信服务,保障企业的短信发送效果和用户体验。

