[
−
r
,
r
]
-
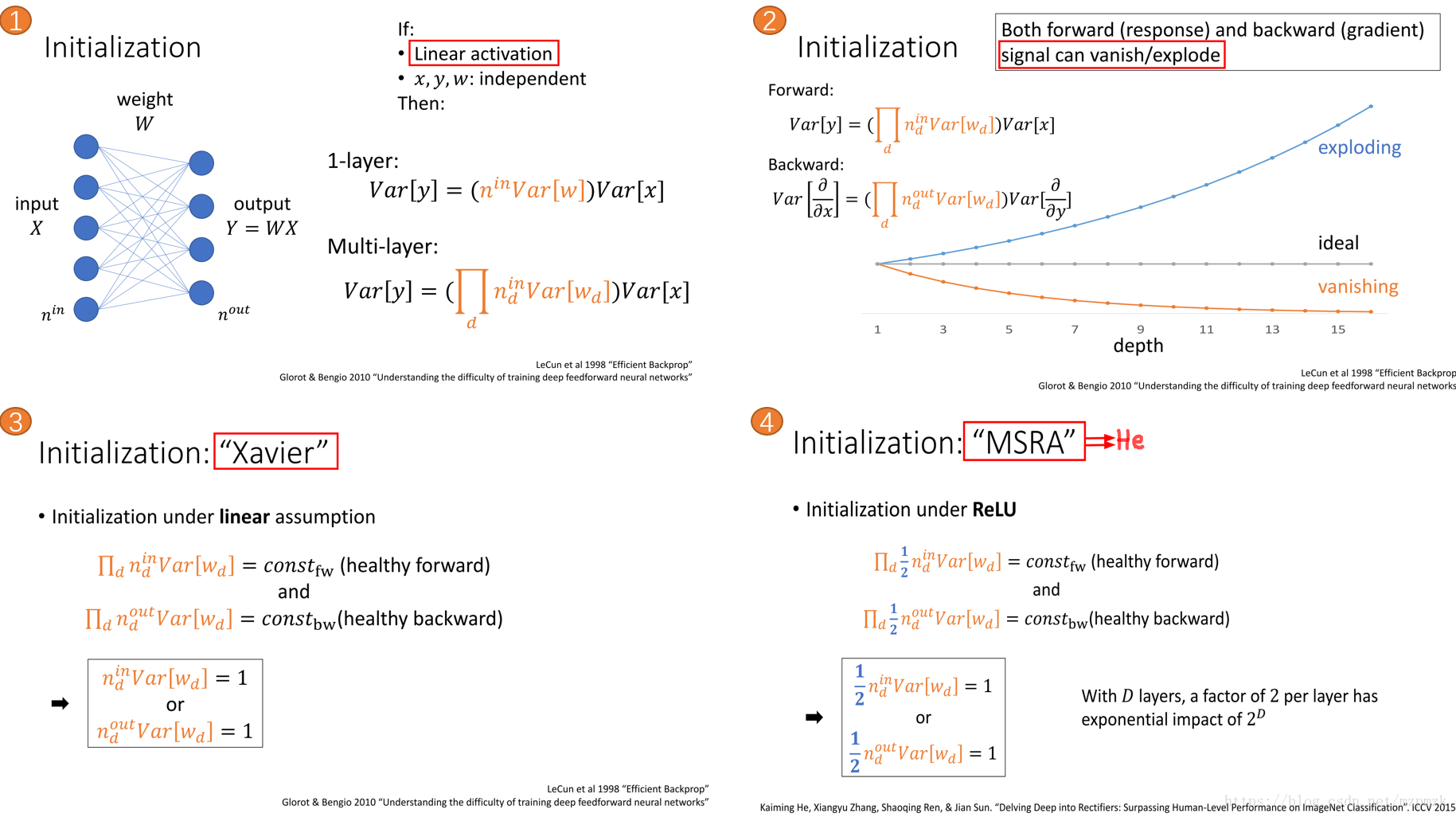
使用 RELU(without BN) 激活函数时,最好选用 He 初始化方法,将参数初始化为服从高斯分布或者均匀分布的较小随机数
-
使用 BN 时,减少了网络对参数初始值尺度的依赖,此时使用较小的标准差(eg:0.01)进行初始化即可
-
借助预训练模型中参数作为新任务参数初始化的方式也是一种简便易行且十分有效的模型参数初始化方法
二、参数初始化代码实践
0、符合约定
n_in:为网络的输入大小
n_out:为网络的输出大小
n:为 n_in 或 (n_in + n_out) * 0.5--->(同时考虑信号在前向和反向传播中都不被放大或缩小)
1、Xavier 初始化
stdev = np.sqrt(1/n)
W = tf.Variable(np.random.randn(n_in, n_out) * stdev)
scale = np.sqrt(3/n)
W = tf.Variable(np.random.uniform(low=-scale, high=scale, size=[n_in, n_out]))
2、He 初始化
stdev = np.sqrt(2/n)
W = tf.Variable(np.random.randn(n_in, n_out) * stdev)
scale = np.sqrt(6/n)
W = tf.Variable(np.random.uniform(low=-scale, high=scale, size=[n_in, n_out]))
3、BN+高斯分布(小
)随机初始化
W = tf.Variable(np.random.randn(node_in, node_out) * 0.01)
======
W = tf.Variable(np.random.randn(shape) * 0.01)
......
fc = tf.contrib.layers.batch_norm(fc, center=True, scale=True, is_training=True)
fc = tf.nn.relu(fc)
4、TensorFLow 中的实现
三、参考文献
1、聊一聊深度学习的weight initialization
2、深度学习网络训练技巧汇总
3、A tutorial on Deep Learning for Objects and Scenes at CVPR(Kaiming He)
4、tensorflow 1.0 学习:参数初始化
5、第七章 网络优化与正则化(复旦-邱锡鹏)
神经网络的
参数
学习是一个非凸优化问题,当使用梯度下降法来进行优化网络
参数
时,
参数
初始值的选取十分关键。如果
参数
的初始值不恰当,轻则影响网络的优化效率和泛化能力,重则导致梯度爆炸或消失。
参数
初始化
的方式通常有三种:预训练
初始化
、随机
初始化
、固定值
初始化
。预训练
初始化
是指用已经训练好的模型的
参数
来
初始化
待训练网络的
参数
。固定值
初始化
是指用一个固定值来
初始化
参数
。随机
初始化
是指用一个随机值来
初始化
参数
。这个随机值可以没有规律,也可以让其服从某个分布。
实践
中
,随机
初始化
是较常用的权值
初始化
方法。现有的
深度学习
理
我们需要牢记
参数
初始化
的目的是为了让神经网络在训练过程
中
学习到有用的信息,这意味着
参数
梯度不应该为0。而我们知道在全连接的神经网络
中
,
参数
梯度和反向传播得到的状态梯度以及入激活值有关——激活值饱和会导致该层状态梯度信息为0,然后导致下面所有层的
参数
梯度为0;入激活值为0会导致对应
参数
梯度为0。所以如果要保证
参数
梯度不等于0,那么
参数
初始化
应该使得各层激活值不会出现饱和现象且激活值不为0。我...
在BN出现之前,权值
初始化
决定了神经网络的初始优化位置,如图6。
正向传播时,神经元的输出会被作为激活函数的输入来进行激活判断。如果神经元的输出不合适,则难以优化(恒为0或1),神经元的输出应当控制在均值为0,方差为1的范围内比较合适。
为了使神经元输出控制在这个范围内,如此处神经元输出范围为N~(0,1)正态分布,该神经元的输入有n个神经元,则权重矩阵元素
初始化
就应当为N~(0,1/n),如式5。在反向传播时,由于梯度的连乘效应(梯度=激活层1斜率*权重1*激活层2斜率*权重。。),权值的过大或过小会
看了文章《Understanding the difficulty of training deep feedforward neural networks》,里面提出了两种
参数
初始化
的方法:以及normalized initialization——xavier方法:最近做实验,发现网络的
初始化
太重要!其实神经网络本身就是一个dark box, 但是每一个
参数
怎么设置怎么调节是最有技术的。几种可行...
最新tensorflow采用了keras封装,和古早写法相比变化很大,但是用起来确更加方便了,恰逢最近需要倒腾tensorflow,所以记录一下。这是一个系列文章,将从浅入深地介绍新的tensorflow的用法,文章列表:林青:学习tensorflow(00)--从源代码编译tensorflowzhuanlan.zhihu.com林青:学习tensorflow2(01) -- 让tensorfl...
BN层(batch normalization)常用于
深度学习
模型
中
,借此来加快模型的收敛速度,提高模型的泛化能力和防止梯度消失等——BN层的作用。在模型训练阶段,通过计算每个batch的平均值 和方差 来对batch
中
的每个样本做归一化: 在模型测试和推理时,模型切换为eval状态,BN层将采用训练阶段时通过移动平均来计算得到的均值 和方差 。训练阶段: 其
中
为batch size, ...
初始化
参数
指的是在网络模型训练之前,对各个节点的权重和偏置进行
初始化
赋值的过程。在
深度学习
中
,神经网络的权重
初始化
方法(weight initialization)对模型的收敛速度和性能有着至关重要的影响。模型的训练,简而言之,就是对权重
参数
W的不停迭代更新,以期达到更好的性能。而随着网络深度(层数)的增加,训练
中
极易出现梯度消失或者梯度爆炸等问题。
我们常见的几种
初始化
方法是按照“正态分布随机
初始化
——对应为normal”和按照“均匀分布随机
初始化
——对应为uniform”,这里就不再多说了,这里介绍几种遇见较少的
初始化
方法。
1、Glorot
初始化
方法
(1)正态化的Glorot
初始化
——glorot_normal
Glorot 正态分布
初始化
器,也称为 Xavier 正态分布
初始化
器。它从以 ...
目录参考地址1. 均匀分布 XXX ~ U(a,b)U(a,b)U(a,b)2. 正态分布 XXX ~ N(mean,std2)N(mean,std^2)N(mean,std2)3.
初始化
为常量constant、ones、zeros、eye、dirac4. Glorot initialization:xavier_uniform_()和xavier_normal_()5. He initialization:kaiming_uniform_()和kaiming_normal_()
很棒的博客:p