mask(掩码、掩膜)是深度学习中的常见操作。简单而言,其相当于在原始张量上盖上一层掩膜,从而屏蔽或选择一些特定元素,因此常用于构建张量的过滤器(见下图)。
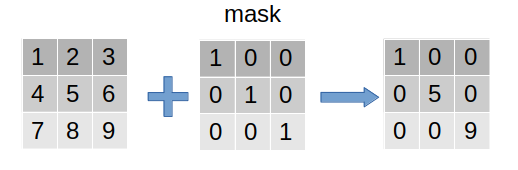
按照上述定义,非线性激活函数Relu(根据输出的正负区间进行简单粗暴的二分)、dropout机制(根据概率进行二分)都可以理解为泛化的mask操作。
从任务适应性上,mask在图像和自然语言处理中都广为应用,其应用包括但不局限于:图像兴趣区提取、图像屏蔽、图像结构特征提取、语句padding对齐的mask、语言模型中sequence mask等。
从使用mask的具体流程上,其可以作用于数据的预处理(如原始数据的过滤)、模型中间层(如relu、drop等)和模型损失计算上(如padding序列的损失忽略)。
尽管上述操作均可统称为mask,但其具体的算法实现细节需要根据实际需求进行设计,下面利用pytroch来实现几个典型的例子。
实例1:图像兴趣区提取
通过mask张量定义兴趣区(或非兴趣区)位置张量,将非兴趣区上的张量元素用0值填充。
import torch
a = torch.randint(0, 255, (2, 3, 3))
mask = = torch.tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]]).bool()
a.masked_fill_(~mask, 0)
实例2:文本Embedding层中对padding的处理
在NLP中,虽然CNN特征抽取器要求文本长度为定长,而RNN和Tranformer特征抽取器虽然可应对不定长的文本序列,但为了在batch维度上进行并行化处理,一般还是选择将文本进行长度对齐,即过长序列进行截断,而长度不足序列进行padding操作。padding操作只是数据维度上的对齐,其并不应该对整个网络的计算贡献任何东西,所以必须进行mask操作。
在pytorch中的词嵌入对象Embedding中,直接通过设定padding_idx参数,即可自动对指定的pad编号进行mask操作,即将padding_idx对象的词向量元素均设为0,从而使得该词对网络的正向传播和梯度反向传播均失活,从而达到了mask的目的。
import torch
import torch.nn as nn
a = torch.tensor([[1,2,3], [2,1,0]])
net = nn.Embedding(num_embeddings=10, embedding_dim=5, padding_idx=0)
b = net(a)
下面来手动实现下上述功能:
import torch
import torch.nn as nn
a = torch.tensor([[1,2,3], [2,1,0]])
net = nn.Embedding(num_embeddings=10, embedding_dim=5)
a_ = net(a)
mask = (a!=0).float().unsequeeze(-1)
b = a_ * mask
实例3:padding的损失计算问题
对于文本序列中的NLP,其中<padding>-token位置处的损失不应该计入,具体而言就是最终的损失应当是一个mask-mean的计算过程。
在pytorch中的损失计算对象CrossEntropyLoss等中,直接通过设定ignore_index参数,即可自动忽略<padding>处的损失计算。
下面是pytorch中的一个简单的例子:
import torch
import torch.nn as nn
targets = torch.tensor([1, 2, 0])
preds = torch.tensor([[1.4, 0.5, 1.1], [0.7, 0.4, 0.2], [2.4, 0.2, 1.4]])
criterion1 = nn.CrossEntropyLoss()
criterion2 = nn.CrossEntropyLoss(ignore_index=0)
loss1 = criterion1(preds, targets)
loss2 = criterion2(preds, targets)
下面,手动实现下该机制:
import torch
import torch.nn as nn
import torch.nn.functional as F
targets = torch.tensor([1, 2, 0])
preds = torch.tensor([[1.4, 0.5, 1.1], [0.7, 0.4, 0.2], [2.4, 0.2, 1.4]])
def pad_loss(pred, target, pad_index=None):
if pad_index == None:
mask = torch.ones_like(target, dtype=torch.float)
else:
mask = (target != pad_index).float()
nopd = mask.sum().item()
target = torch.zeros(pred.shape).scatter(dim=1, index=target.unsqueeze(-1), source=torch.tensor(1))
target_ = target * mask.unsqueeze(-1)
loss = -(F.log_softmax(pred, dim=-1) * target_.float()).sum()/nopd
return loss
loss1 = pad_loss(preds, preds)
loss2 = pad_loss(preds, preds, pad_index=0)
实例4:self-attention对padding的处理
Transformer中提出的self-attention机制可以通过文本内部两两元素进行信息的提取,在其中计算各score的softmax权重时,不能将padding处的文本考虑进来(因为这些文本并不存在)。所以在进行softmax前需要进行mask操作(如下图)。

其具体策略是,将padding的文本处的score设定为负的极大值,这样最终的权重接近于0,从而这些文本不会对attention后生成的向量其作用。
import torch
import torch.nn as nn
import torch.nn.functional as F
a = torch.tensor([2,1,0])
score = torch.tensor([1.2, 2.3, 4])
mask = (a == 0).bool()
score_ = F.softmax(score.masked_fill(mask, -np.inf), dim=-1)
实例5:序列生成模型中对后续未知文本的处理
在Transformer中Decoder部分的self-attention处,由于是模型的目的在于序列生成,所以无论在训练过程中需要特意将后续文本进行mask,不让模型看到。
此时的mask操作称为针对序列的sequence mask,其以文本序列长度为单位,生成一个上三角矩阵矩阵,其中上三角元素为0,其余元素为1,表示在当前word处(即矩阵的对角元)模型看不到后面的words。
import numpy as np
import torch
def sequence_mask(size):
mask_shape = (size, size)
return torch.from_numpy(np.tril(np.ones(mask_shape),k=0))
实例6:mask的联合操作
比如在Transformer的Decoder中self-attention中,既需要对<pad>进行mask,也需要对后续序列进行mask,此时就需要对两个mask进行&位运算,以迭加效果。
def combine_mask(batch_text, inpad_index=0):
batch_text: 文本batch, Batch * Sequence
pad_mask = batch_text != inpad_index
sequence_len = batch_text.shape[1]
sequence_mask = torch.tensor(np.tril(np.ones((sequence_len, sequence_len)), k=0)).byte()
mask = pad_mask.unsqueeze(-2) & sequence_mask
return mask
mask(掩码、掩膜)是深度学习中的常见操作。简单而言,其相当于在原始张量上盖上一层掩膜,从而屏蔽或选择一些特定元素,因此常用于构建张量的过滤器(见下图)。按照上述定义,非线性激活函数Relu(根据输出的正负区间进行简单粗暴的二分)、dropout机制(根据概率进行二分)都可以理解为泛化的mask操作。从任务适应性上,mask在图像和自然语言处理中都广为应用,其应用包括但不局限于:图像兴趣区...
本文来自于csdn,本文章主要通过实验来讲解深度学习FasterRCNN框架的实例分割任务以及RoIAlign操作,希望对您的学习有所帮助。基于FasterRCNN框架,在最后同分类和回归层,增加了实例分割任务【asmallFCNappliedtoeachRoI】将FasterRCNN中的RoIPooling替换成RoIAlign操作最终的特征层,采用FPN(FeaturePyramidNetwork)进行特征提取采用ResNet101作为基础网络RPN中的anchor采用5scales和3aspectratios注:MaskRCNN在FasterRCNN最后扩展了分类和回归任务,增加了一个针
Mask RCNN沿用了Faster RCNN(https://blog.csdn.net/YOULANSHENGMENG/article/details/121850364)的思想,特征提取采用ResNet-FPN的架构,另外多加了一个Mask(用于生成物体的掩模)预测分割分支。如下图1所示。其中黑色部分为原来的Faster-RCNN,红色部分为在Faster-RCNN网络上的修改。将RoI Pooling 层替换成了RoIAlign层;添加了并列的FCN层(mask层)。
参考:浅析深度学习中的mask操作_guofei_fly的博客-CSDN博客_深度学习mask
参考:图像中的掩膜(Mask)是什么_bitcarmanlee的博客-CSDN博客_掩膜
mask(掩码、掩膜)是深度学习中的常见操作。简单而言,其相当于在原始张量上盖上一层掩膜,从而屏蔽或选择一些特定元素,因此常用于构建张量的过滤器。
按照上述定义,非线性激活函数Rel
撰写时间:2019年2月20日
听到“遮罩层”这个词顾名思义大家都知道最少也要有两层,上面一层是遮罩层,下面一 层是被遮罩层。这两个图层中只有相重叠的地方才会被显示。也就是说在遮罩层中有对象的地方就是“透明”的,可以看到被遮罩层中的对象,而没有对象的地方就是不透明的,被遮罩层中相应位置的对象是看不见的。
解答:pytorch 通过索引赋值后 梯度还能正常反向传播吗
版权声明:本文为CSDN博主「会写代码的孙悟空」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/artistkeepmonkey/article/details/117420543
结论:能继续传播,不会中断。
2. abs
PyTorch 的 abs 函数是否会打断梯度反向求导或者计算图
版权声明:本文为CSDN博主「HuanCa
首先我们从物理的角度来看看mask到底是什么过程。
在半导体制造中,许多芯片工艺步骤采用光刻技术,用于这些步骤的图形“底片”称为掩膜(也称作“掩模”),其作用是:在硅片上选定的区域中对一个不透明的图形模板遮盖,继而下面的腐蚀或扩散将只影响选定的区域以外的区域。
图像掩膜与
SDIO是一种用于连接多种设备的接口标准,包括Wi-Fi等无线网络设备。SDIO接口Wi-Fi驱动程序是用来管理和控制SDIO模块连接Wi-Fi设备的程序。Wi-Fi驱动程序通常是由设备制造商或操作系统供应商提供的,它们可以针对特定的SDIO模块和Wi-Fi设备进行定制。驱动程序管理SDIO接口与Wi-Fi设备的通信,控制数据流和网络连接以及提供对Wi-Fi设备的配置和监视功能。
在SDIO接口中,Wi-Fi设备一般作为一个SDIO卡出现,并通过SDIO总线与主处理器通信。因此,SDIO接口Wi-Fi驱动程序需要充分考虑SDIO总线和Wi-Fi设备之间的交互,并提供相应的操作和处理流程。常见的SDIO接口Wi-Fi驱动程序包括驱动层和协议层两部分。驱动层主要负责设备驱动程序的加载和卸载,以及控制SDIO总线与Wi-Fi设备之间的基本交互。协议层则实现与Wi-Fi设备之间的高级通信协议和数据传输,如TCP/IP协议栈、接入控制和传输协议等。
SDIO接口Wi-Fi驱动程序的设计和实现需要考虑多方面的因素,如SDIO总线的带宽和时序控制、Wi-Fi设备的固件和驱动程序兼容性、网络连接和性能要求等。通常需要经过严格的测试和优化才能实现良好的性能和稳定性。
总之,SDIO接口Wi-Fi驱动程序是一项关键技术,它的实现对Wi-Fi设备的性能和可靠性都有着重要的影响。需要专业的技术团队和优秀的开发工具支持,才能实现高品质的SDIO接口Wi-Fi驱动程序。

