


记一次真实SQL性能调优(调优思路及数据偏移实现)

近日,接到一则报表性能优化的需求,起因是客户用了五年的报表,最近不好使了。预览报表报错:超时时间已到,可把客户给急得。


乍一看报表样式,浓浓的“中国式报表”风(还是老版的报表设计器),表格列是各公司类型下的工单类型,共25列;表格行是各项目下的各项指标,最多20*14行,从整体记录数来看,行数并不多,怎么会超时呢?


打开SQL Server Profilers跟踪器,捕捉到该报表是通过存储过程实现的,存储过程运行30秒,前台便报超时,说明超时时间为30秒(翻了下产品文档,超时时间还不给调)。
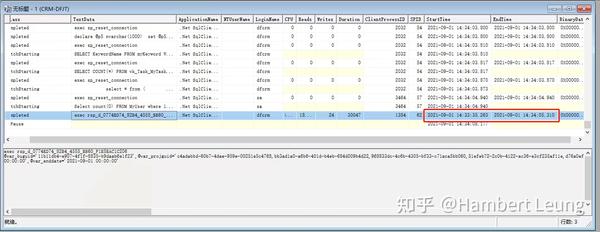
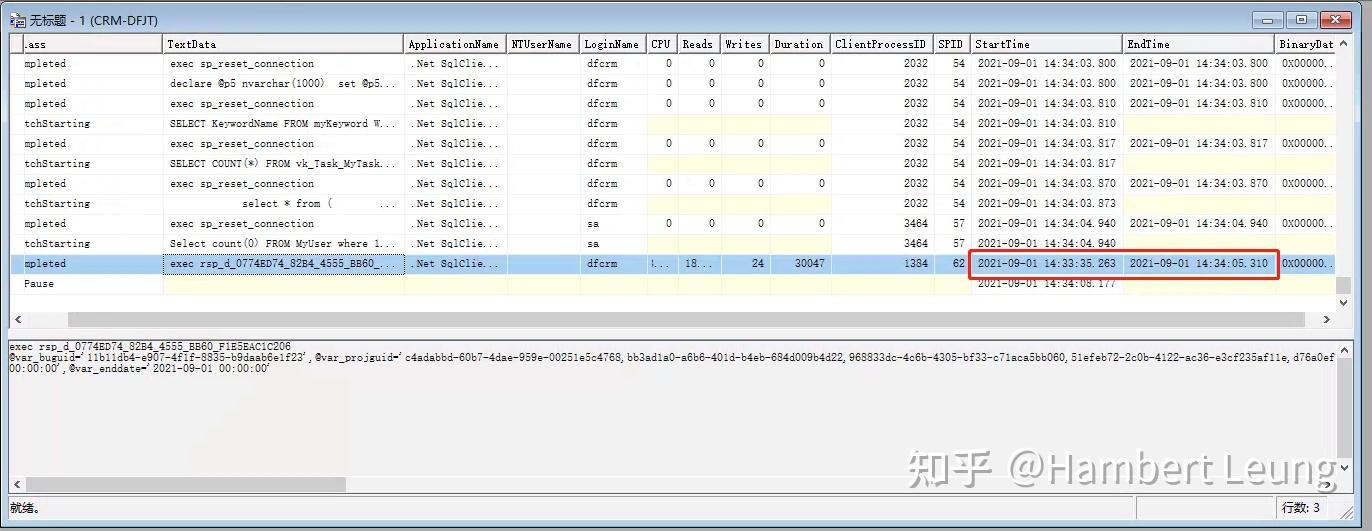
在SSMS中单独执行存储过程,40+秒,还没走到前端渲染这步就妥妥超时了。
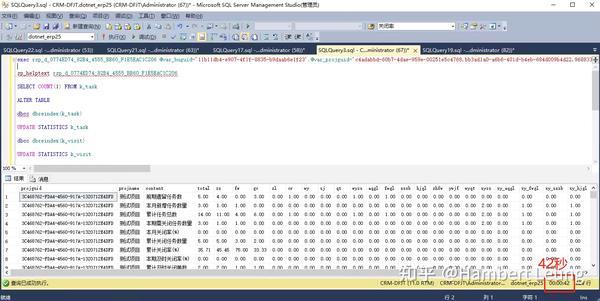
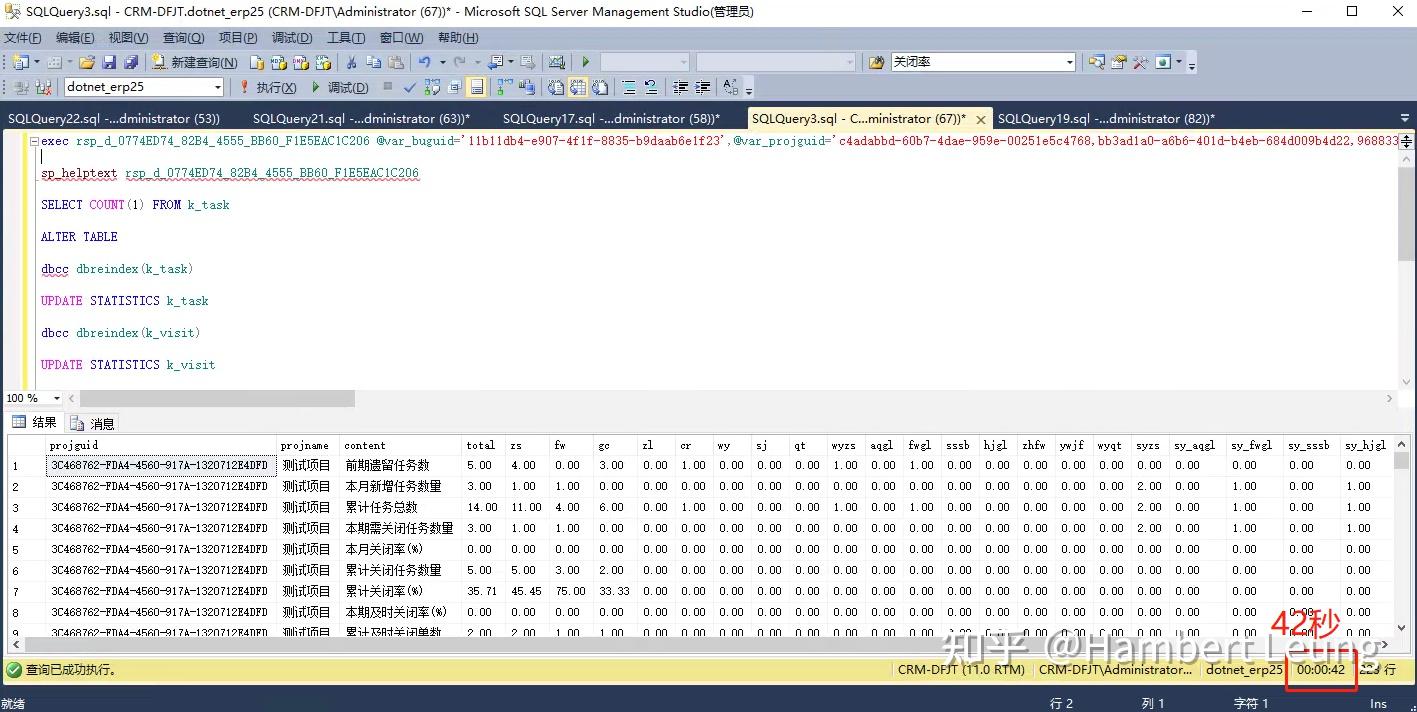
翻开存储过程的代码扫望一遍,引用的表并不多,更多是计算,先上常规优化手段:重建索引+更新统计信息+表收缩(业务繁忙时切忌全表优化,需要限定下表名),结果依旧。
--重建索引 更新统计信息 表收缩
DECLARE @DBCCString NVARCHAR(1000)
DECLARE @DBCCString1 NVARCHAR(1000)
DECLARE @DBCCString2 NVARCHAR(1000)
DECLARE @TableName VARCHAR(150)
declare @n int
declare @cu int
select @n= (select count(1) from sysobjects WHERE xType='U' and (name like 'T_%') and name not like 'tmp%')
select @cu=1
DECLARE Cur_Index CURSOR FOR
SELECT Name AS TblName FROM sysobjects WHERE xType='U' and (name like 'T_%') and name not like 'tmp%' ORDER BY TblName
FOR READ ONLY
OPEN Cur_Index
FETCH NEXT FROM Cur_Index INTO @TableName
WHILE @@FETCH_STATUS=0
BEGIN
SET @DBCCString ='alter index all on '+@TableName+ ' rebuild;'
EXEC (@DBCCString)
SET @DBCCString1 = 'UPDATE STATISTICS '+@TableName+ ';'
EXEC (@DBCCString1)
SET @DBCCString2 = 'ALTER TABLE '+@TableName+ ' rebuild WITH (DATA_COMPRESSION =ROW);'
EXEC (@DBCCString2)
PRINT '第' + CONVERT(varchar (12), @cu)+ ' /共 ' +CONVERT(varchar (12), @n) + ' 表: ' + @TableName +' 重建索引、更新统计信息、表收缩完成!'
FETCH NEXT FROM Cur_Index INTO @TableName
select @cu=@cu+1
CLOSE Cur_Index
DEALLOCATE Cur_Index
PRINT '操作完成!'
继续上武器,打开MSSQL的执行计划,找开销占比最高的查询及节点,发现几个计算关闭率的节点查询开销占比高,而且还是实打实的开销,打开查询计划建议的“缺少索引”建议,发发现是把所有用上的字段拼接的组合索引,凭经验看,这类索引一般没效果,果然不行。
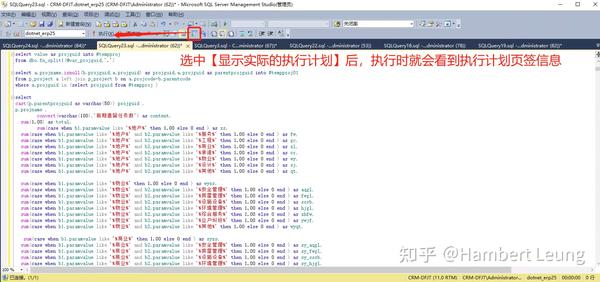
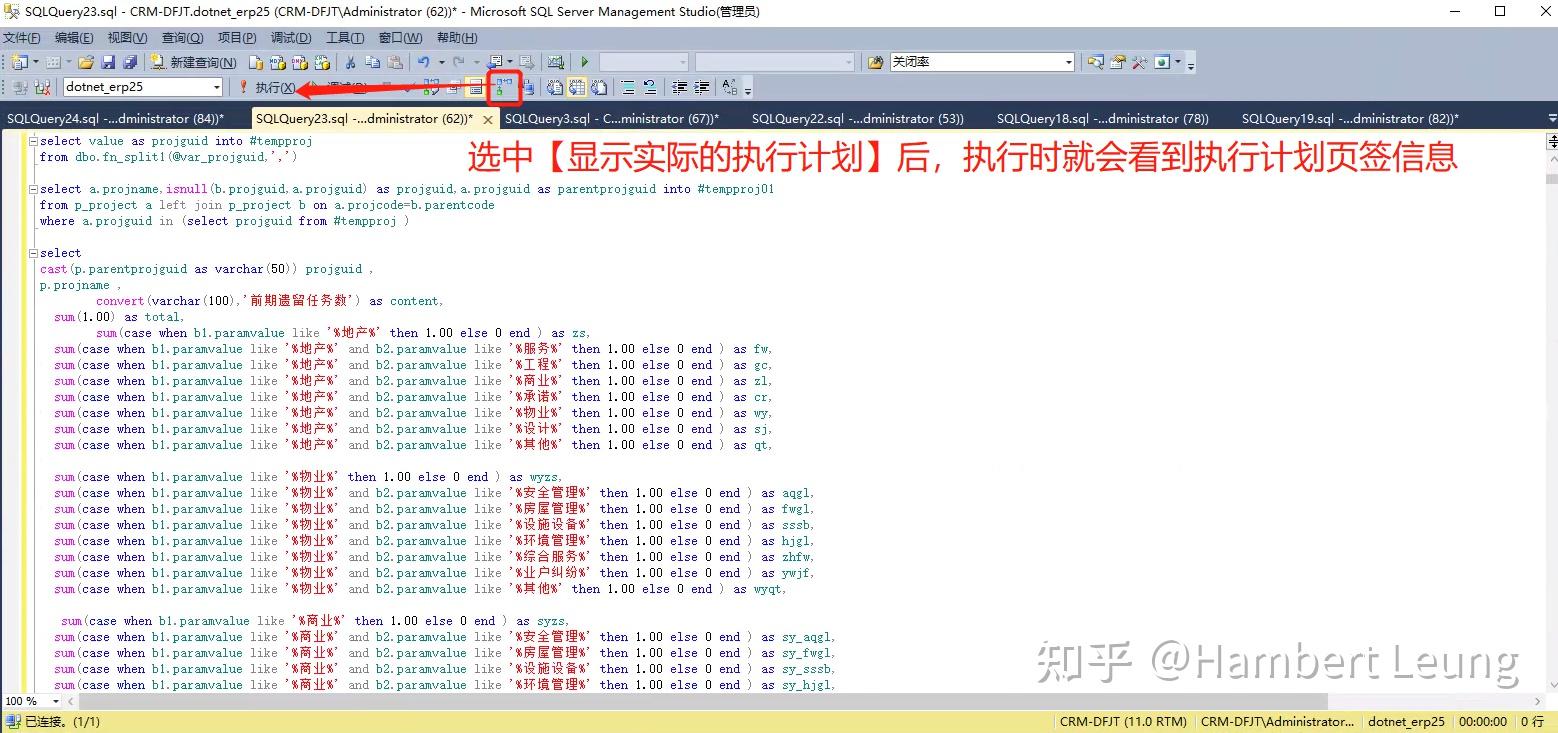
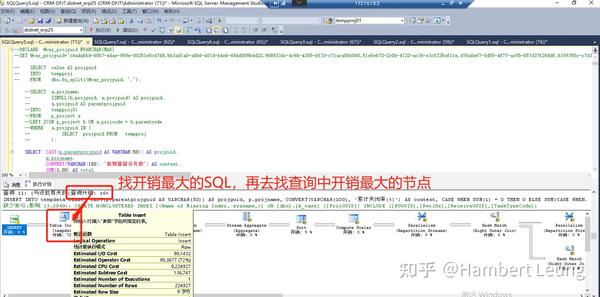
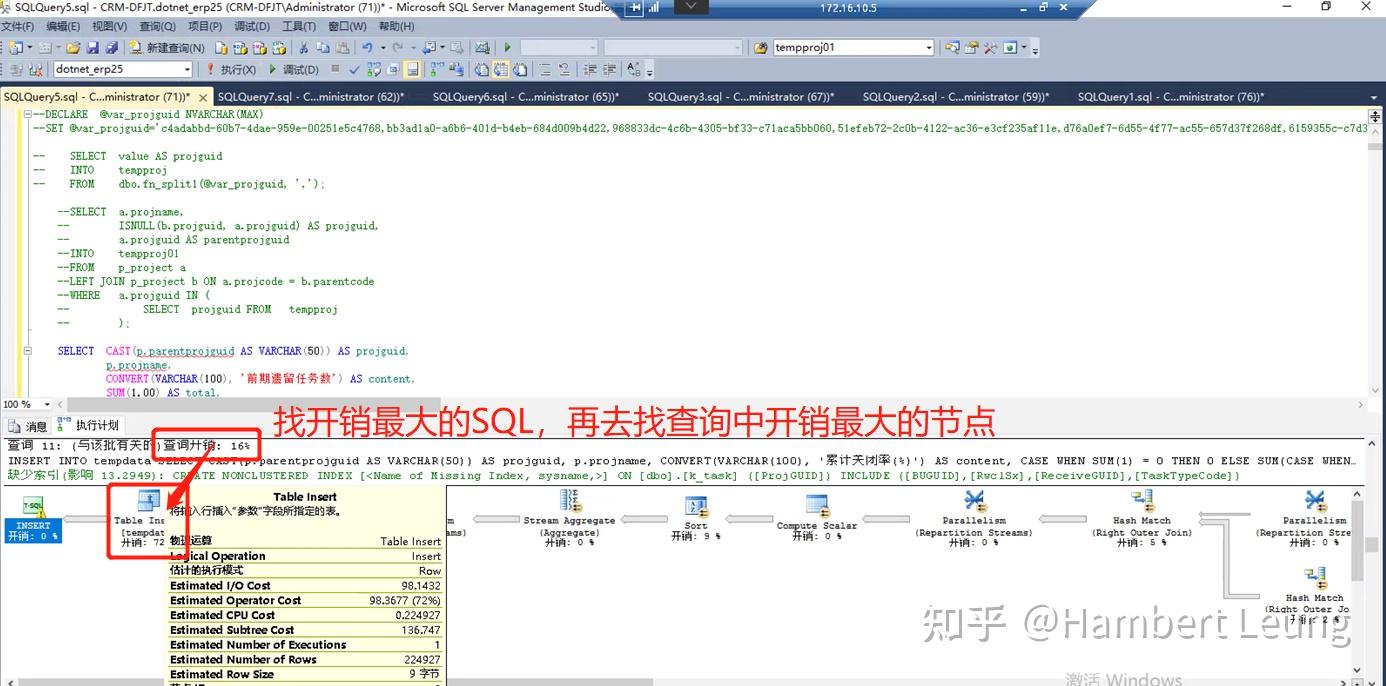
接下来,只能真枪实弹,分析原始代码逻辑,直奔 开销占比最高 的SQL代码块分析,发现疑点:怎么比例用除法做计算,写得那么复杂;进一步分析,原来是其他指标已经实现的汇总计算,却为了计算比例,再次进行SUM汇总,可谓事倍功半。
不过事出必有因,我们常用的相除都是同一行的字段间的“列”相除,想要做到“中国式报表”的“行”相除,还真的不好整(SQL sever2012以上版本,可以利用 LAG函数 ,但是也涉及到函数的重复调用;编程语言中,如Python中的 SHIFT函数 实现数据上下偏移),只好搞点骚操作: 先排个序标个号,在通过排号关联实现偏移(文末有演示数据和实现SQL) ,把被除数和除数放在同一行之后再进行相除(记得除以零的兼容处理)。
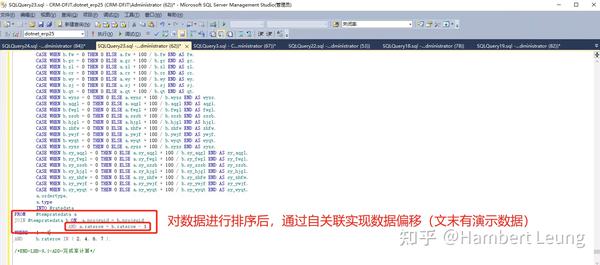
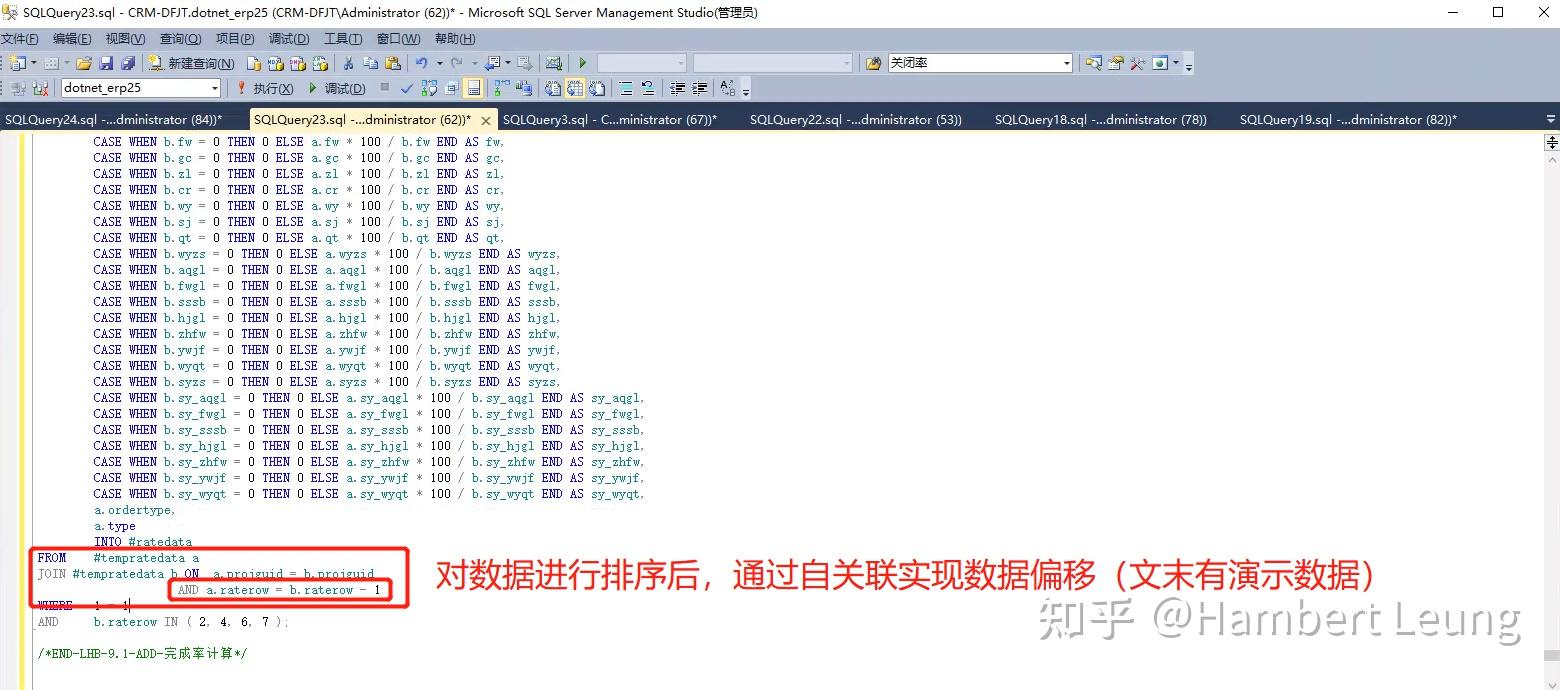
把比例计算好后,构造好相应的行数据,再通过UNION ALL“放”回原数据集中,构造完成。执行新的存储过程,15秒+,美滋滋。
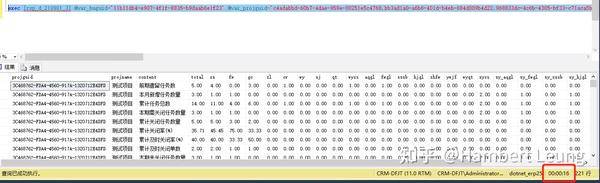
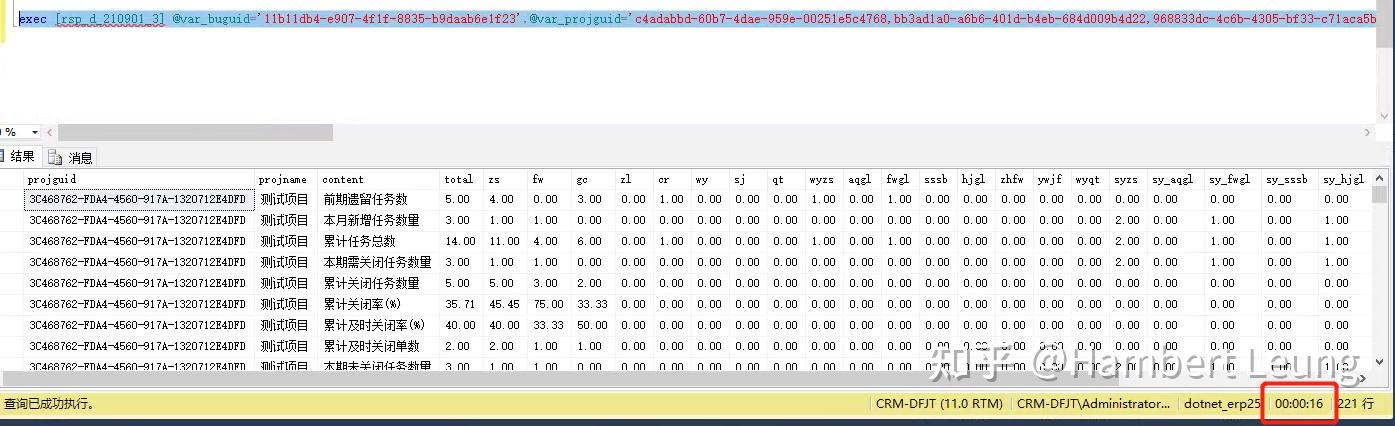
当然,改造归改造,保证结果准确性也是必须滴,借助EXCEL的条件筛选,新旧结果集比对一目了然。参考:
至此,大功告成。从40秒到15秒,提速 167% ,靠的是一步步顺藤摸瓜。最后,总结下优化点和知识点。
优化点: 避免重复计算,对计算结果再运算时,保证在已经“浓缩”的结果集上再运算,减少运算量。
知识点: 排查SQL性能问题的思路(化整为零,步步为营),数据上下偏移的SQL实现
附:数据上下偏移的SQL实现(SQL Server)
原始数据集:
| 指标 | 主要任务量 | 次要任务量 |
|---|---|---|
| 本期关闭 | 8 | 9 |
| 本期新增 | 10 | 12 |
| 累计关闭 | 96 | 97 |
| 累计新增 | 100 | 200 |
结果数据集:
| 指标 | 主要任务量 | 次要任务量 |
|---|---|---|
| 本期关闭 | 8 | 9 |
| 本期新增 | 10 | 12 |
| 本期关闭率(%) | 80 | 75 |
| 累计关闭 | 96 | 97 |
| 累计关闭 | 100 | 200 |
| 累计关闭率(%) | 96 | 48 |
SQL实现:
--1 原始数据集构造
SELECT *
INTO #TEMP_SHOW_DATA
FROM (
SELECT '本期关闭' 指标, 8 主要任务量, 9 次要任务量
UNION ALL
SELECT '本期新增', 10, 12
UNION ALL
SELECT '累计关闭', 96, 97
UNION ALL
SELECT '累计新增', 100, 200)
--2 自定义排序,添加序号
SELECT ROW_NUMBER() OVER (ORDER BY 主要任务量 ASC) AS 序号,
主要任务量,
次要任务量
INTO #TEMP_SHOW_DATA_SEQ
FROM #TEMP_SHOW_DATA;
--3 通过关联实现上下偏移,并计算指标
SELECT CASE WHEN A.指标 = '本期关闭' THEN '本期关闭率(%)' WHEN A.指标 = '累计关闭' THEN '累计关闭率(%)' END AS 指标,
CASE WHEN B.主要任务量 = 0 THEN 0 ELSE A.主要任务量 * 100 / B.主要任务量 END AS 主要任务量,
CASE WHEN B.次要任务量 = 0 THEN 0 ELSE A.次要任务量 * 100 / B.次要任务量 END AS 次要任务量
INTO #TEMP_SHOW_DATA_RATE
FROM #TEMP_SHOW_DATA_SEQ A
JOIN #TEMP_SHOW_DATA_SEQ B ON A.序号 = B.序号 - 1
WHERE B.序号 IN ( 2, 4 );
--4 拼接获得结果集
SELECT * FROM (
SELECT 指标,
主要任务量,
次要任务量
FROM #TEMP_SHOW_DATA
UNION ALL