

python通过爬取汽车之家分析新能源汽车趋势

宁为代码类弯腰,不为bug点提交
新能源汽车的趋势已经越来越明显了,不管是家用车,还是商用车,新能源汽车都成了首选。从最新的汽车销售排行榜上看,排前10的车型中,新能源已经占据了一大半。目前新能源汽车的渗透率已经达到35%,明年就会超过50%。新能源汽车不管从配置,性能,驾驶感,使用成本等各方面来看都对燃油车形成了降维打击,国内的车企已经开始把发展重点转向新能源汽车。

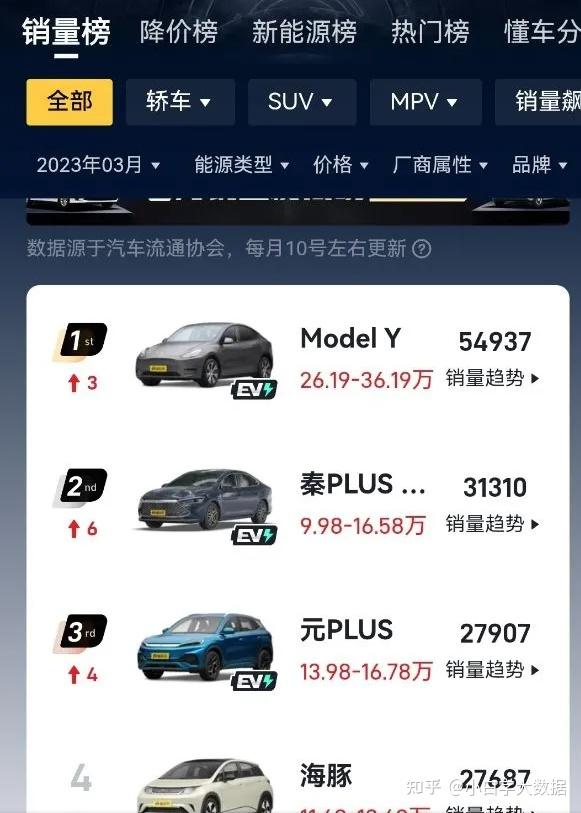
但是不管是新能源车汽车还是燃油车,大家都有不同的使用感受和选择的重点,那么我们就通过python大数据;来了解下,这2种车型大家都是怎么评价的吧?是否燃油车真的有要退出市场的趋势。数据来源于汽车之家论坛评论。但是大家都清楚汽车之家的反爬虫措施做得相当好。也是为了保护个人权益的原因或者是保护用户的信息吧。所以为了完成任务就必须要反反爬虫。其中比较容易解决的就是限制ip访问的反爬机制,如果直接采集会把你的IP封禁掉,返回403 。需要更换高匿稳定的代理IP才可以继续,所以文章中使用了由亿牛云提供的隧道转发爬虫代理,这里我们通过python+urllib库+代理IP,并且使用了threading库和time库,使其能够实现多线程采集,
#! -- encoding:utf-8 -- from urllib import request import threading # 导入threading库,用于多线程 import time # 导入time库,用于延时
#要访问的目标页面
targetUrl = “#! -- encoding:utf-8 -- from urllib import request import threading # 导入threading库,用于多线程 import time # 导入time库,用于延时
#要访问的目标页面
targetUrl = “https://www.baidu.com” # 修改为汽车之家
#代理服务器(产品官网 www.16yun.cn)
proxyHost = “t.16yun.cn” proxyPort = “31111”
#代理验证信息
proxyUser = “www.16yun.cn” proxyPass = “16ip”
proxyMeta = “http://%(user)s:%(pass)s@%(host)s:%(port)s” % { “host” : proxyHost, “port” : proxyPort, “user” : proxyUser, “pass” : proxyPass, }
proxy_handler = request.ProxyHandler({ “http” : proxyMeta, “https” : proxyMeta, })
opener = request.build_opener(proxy_handler)
request.install_opener(opener)
#定义一个锁对象,用于控制每200毫秒只能请求一次
lock = threading.Lock()
#定义一个函数,用于发起请求和打印响应
def get_url(): # 获取锁,如果锁被占用,就等待,直到锁释放 lock.acquire() resp = request.urlopen(targetUrl) # 发起请求 # 判断状态码是否为200,如果不是,打印错误信息 if resp.status_code == 200: print(resp.read()) # 打印响应内容 else: print(f"请求失败,状态码为{resp.status_code}") # 打印错误信息 time.sleep(0.2) # 延时200毫秒 # 释放锁,让其他线程可以获取锁 lock.release()
#定义一个列表,用于存放线程对象
threads = []
#创建10个线程,每个线程执行get_url函数
for i in range(10): t = threading.Thread(target=get_url) # 创建线程对象 threads.append(t) # 将线程对象添加到列表中
#启动所有线程
for t in threads: t.start()
#等待所有线程结束
for t in threads: t.join()” # 修改为百度
#代理服务器(产品官网 www.16yun.cn)
proxyHost = “t.16yun.cn” proxyPort = “31111”
#代理验证信息
proxyUser = “www.16yun.cn” proxyPass = “16ip”
proxyMeta = “http://%(user)s:%(pass)s@%(host)s:%(port)s” % { “host” : proxyHost, “port” : proxyPort, “user” : proxyUser, “pass” : proxyPass, }
proxy_handler = request.ProxyHandler({ “http” : proxyMeta, “https” : proxyMeta, })
opener = request.build_opener(proxy_handler)
request.install_opener(opener)
#定义一个锁对象,用于控制每200毫秒只能请求一次
lock = threading.Lock()
#定义一个函数,用于发起请求和打印响应
def get_url(): # 获取锁,如果锁被占用,就等待,直到锁释放 lock.acquire() resp = request.urlopen(targetUrl) # 发起请求 # 判断状态码是否为200,如果不是,打印错误信息 if resp.status_code == 200: print(resp.read()) # 打印响应内容 else: print(f"请求失败,状态码为{resp.status_code}") # 打印错误信息 time.sleep(0.2) # 延时200毫秒 # 释放锁,让其他线程可以获取锁 lock.release()
#定义一个列表,用于存放线程对象
threads = []
#创建10个线程,每个线程执行get_url函数
for i in range(10): t = threading.Thread(target=get_url) # 创建线程对象 threads.append(t) # 将线程对象添加到列表中