

linux 文件io 文件描述符 阻塞和非阻塞 同步和异步


学习于: https://www. bilibili.com/video/av29 268873/?p=13
先看一个c标准库函数的跨平台性:
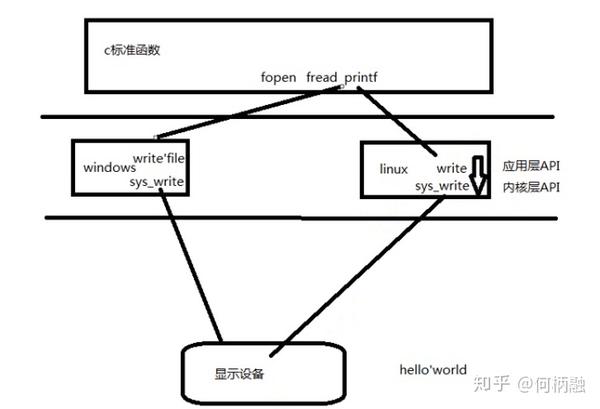

比如你在c中调用printf,打印到控制台上一个helloworld。
那么在linux上运行就是,printf先调用linux的应用层API --write函数,然后write函数又调用内核层API-- sys_write函数,然后再调用显示设备的驱动函数,让helloworld这个字符串显示在控制台。应用层API是我们可以直接使用的,而内核层API是我们这些用户程序不能直接调用的,需要通过应用层API进行调用。而在windows上也是类似的情况。
这里视频说:在windows上编译好的c程序拿到linux上不能调用,因为linux不能识别windows的应用层API。 关于c的底层我不是很理解,但是java的class文件直接拿到linux是可以直接执行的,因为负责解释class文件的是linux的JVM,这才是java跨平台性的主要原因。没记错的话,class文件默认是用unicode编码,所以二进制数据只要按照规则进行识别运行即可。
然后看一个c语言中打开文件的demo;
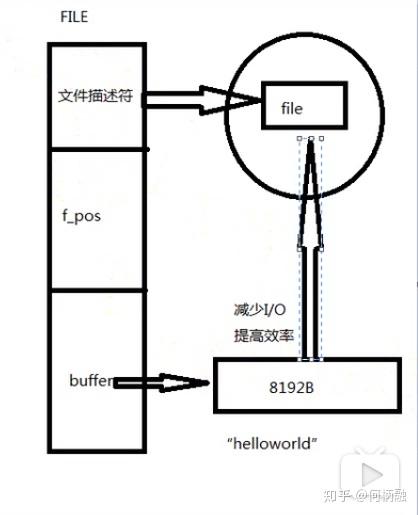
调用fopen打开一个文件的时候, 会创建一个file的结构体,里面分别存放着文件描述符,f_pos,buffer,文件描述符指向磁盘中的文件的位置,f_pos是描述文件的读写指针的位置,buffer是一个指针,指向一个8192B的缓冲区。 缓冲区的作用是减少io操作,提高效率。比如打印”helloworld“字符串到文件中,没有缓冲区就相当于每次写入一个字符到磁盘中,那么就要写19次,而有了缓冲区就相当于一次性把整个字符串写入磁盘中。而写入磁盘的过程中,这里以机械硬盘举例,每次都要磁针先寻址到相应地址,然后再进行读写操作。所以多次操作磁盘,就需要多次的探针寻址,这样就耗费时间。所以要尽量减少磁盘io操作。那什么时候缓冲区的数据刷新到磁盘里的文件呢? 1.最好调用f.flush()函数 2.缓冲区已经满了 3.程序正常退出关闭 。
然后一个文件可以有标准输入,标准输出,标准出错 ,一共三个流。每个流对应一个file结构体。也就是可以一共有三个缓冲区。其实就是终端的输入输出。
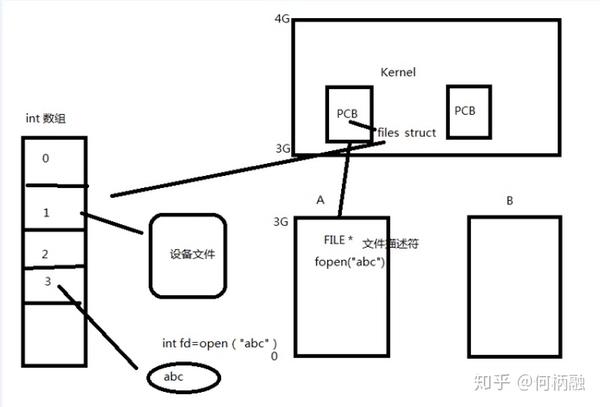
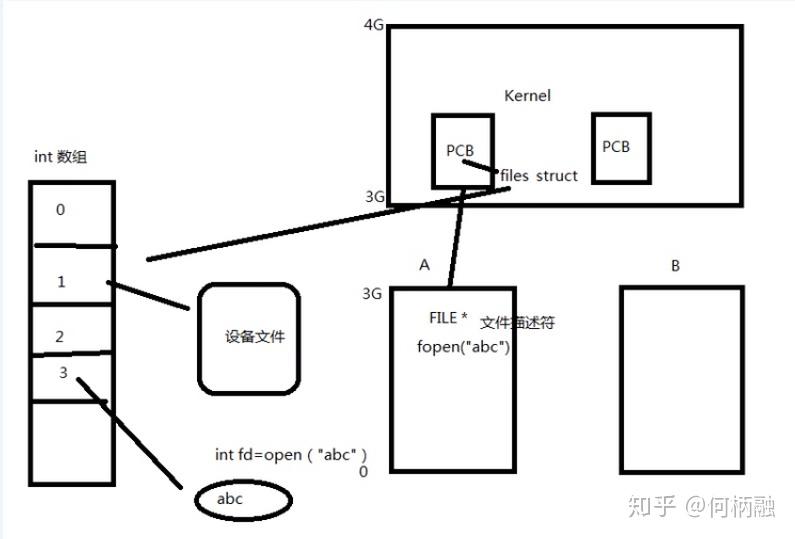
然后我们来了解一下files_struct这个files指针。如下图:
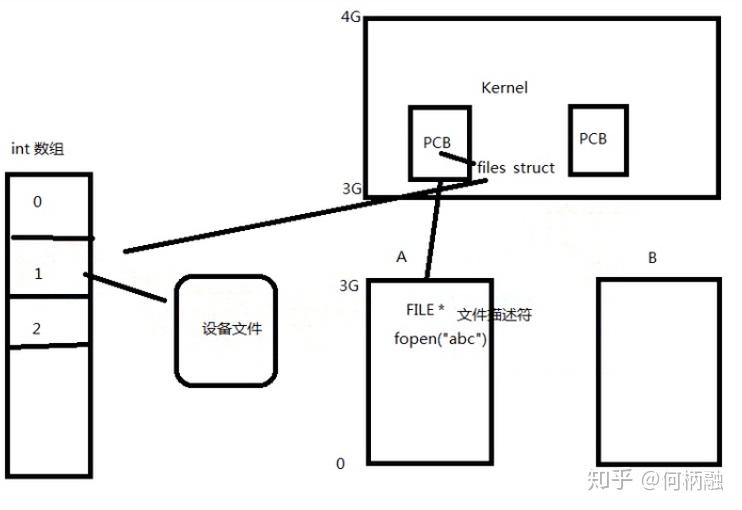
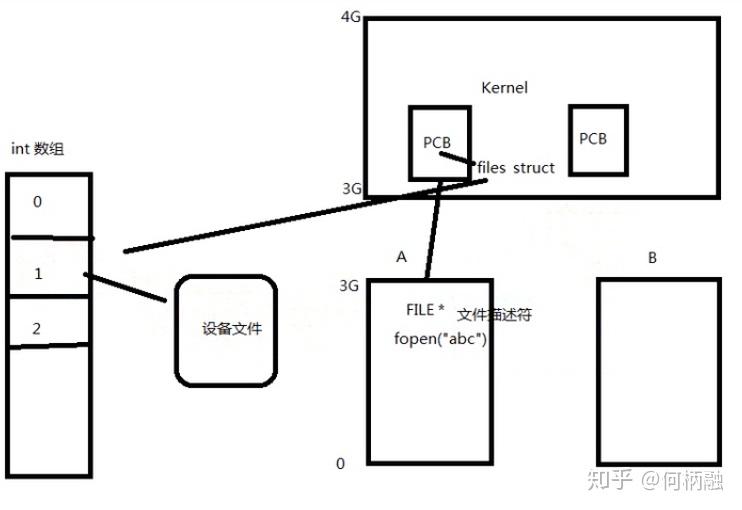
就是PCB在内核空间里,PCB里有一个files_ s truct的结构体files,它指向一个数组,数组里存放着文件描述符,每个文件描述符指向一个设备文件,可能是显示屏文件,也可能是磁盘文件。然后当应用程序调用fopen创建一个文件的时候,就会创建一个前面说的file的结构体,这个结构体里面存储有文件描述符,要操作的这个文件的时候,就去PCB里找到files_struct结构体,然后再找到对应的文件,然后再进行相应的操作。
Linux中进程描述符task_struct结构体详解 - Amber的博客 - CSDN博客 这篇博客里有PCB这个task_struct结构体的具体代码,我在阿里云的centos里面一下子没找到,就直接拿这个看了。
这里对文件描述符做个另外的介绍:
参考:
文件描述符(file descriptor)
对于linux而言,所有对设备和文件的操作都使用文件描述符来进行的。 文件描述符是一个非负的整数,它是一个索引值,指向内核中每个进程打开文件的记录 表。 当打开一个现存文件或创建一个新文件时,内核就向进程返回一个文件描述符 ;当需要读写文件时,也需要把文件描述符作为参数传递给相应的函数。
通常, 一个进程启动时,都会打开3个文件:标准输入、标准输出和标准出错处理。这3个文件分别对应文件描述符为0、1和2(宏STD_FILENO、STDOUT_FILENO和STDERR_FILENO) 。 其实就是每个进程都有终端的输入输出和异常。
每一个文件描述符会与一个打开文件相对应,同时,不同的文件描述符也会指向同一个文件。相同的文件可以被不同的进程打开也可以在同一个进程中被多次打开。系统为每一个进程维护了一个文件描述符表,该表的值都是从0开始的,所以在不同的进程中你会看到相同的文件描述符,这种情况下相同文件描述符有可能指向同一个文件,也有可能指向不同的文件。具体情况要具体分析,要理解具体其概况如何,需要查看由内核维护的3个数据结构。
1. 进程级的文件描述符表
2. 系统级的打开文件描述符表
3. 文件系统的i-node表
由于进程级文件描述符表的存在,不同的进程中会出现相同的文件描述符,它们可能指向同一个文件,也可能指向不同的文件。两个不同的文件描述符,若指向同一个打开文件句柄,将共享同一文件偏移量。因此,如果通过其中一个文件描述符来修改文件偏移量,那么从另一个文件描述符中也会观察到变化,无论这两个文件描述符是否属于不同进程,还是同一个进程,情况都是如此。
8. 文件句柄 vs 文件描述符
文件句柄也称为文件指针(FILE *):C语言中使用文件指针做为I/O的句柄。文件指针指向进程用户区中的一个被称为FILE结构的数据结构。FILE结构包括一个缓冲区和一个文件描述符。而文件描述符是文件描述符表的一个索引,因此从某种意义上说文件指针就是句柄的句柄(在Windows系统上,文件描述符被称作文件句柄)。
---------------------
作者:u013256816
来源:CSDN
原文: 文件句柄(file handles) & 文件描述符(file descriptors)
版权声明:本文为博主原创文章,转载请附上博文链接!
感觉句柄之不过时一个名字而已,认识到里面具体的结构体和指针分别对应的指向才是王道。
比如 int fd=fopen("aaa.txt") ,即返回一个文件描述符,file description 。返回的fd应当是文件描述符表当中未使用的最小的那个。比如有了0,1,2,那么这个返回的就是3了。文件描述符的本质就是一个非负的整数。 然后在内核层面上,把3这个文件描述符和aaa.txt这个文件关联起来。然后3就可以称为一个句柄。通过3这个句柄就可以找到aaa.txt这个文件。然后关闭一个文件也可以通过close(fd),通过文件描述符来关闭。
然后来个比较全面的图片笔记:
然后看程序的阻塞和非阻塞:
先来看一个简单的程序:
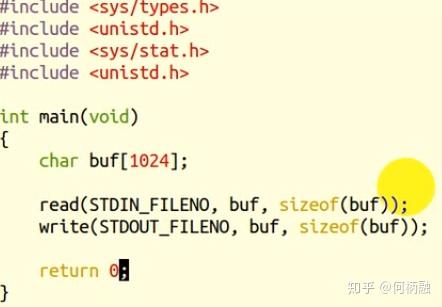

这段程序的作用是从终端读取字符,然后再在终端显示。然后敲下hello之后,回车,即代表终端的输入结束。然后返回hello加上一堆乱码。因为它是把buf写到终端,而buf有1024个字节,后面的字节不确定,没有写,所以以乱码形式显示。如下图:


然后再来看下面这段代码:
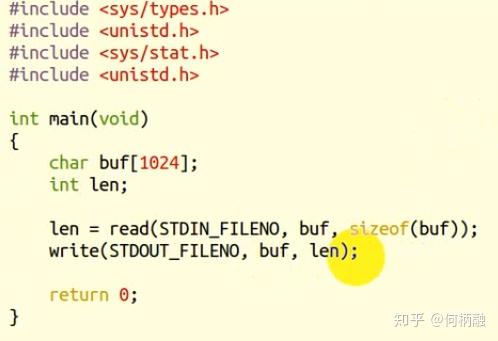

这次是只写buf的写入数据的部分,即接收的len.所以返回无乱码。如下图:


然后回到我们的主题:阻塞和非阻塞。
当我们运行程序的时候,如果我们没有输入字符


那么它就会一直处于阻塞状态。需要我们输入字符,并且敲下回车才能运行下去。也就是说,这里面的read函数就是一个阻塞函数。那么什么是非阻塞呢? 就是当你运行这个程序的时候,如果没有用户没有马上给你字符串,那程序直接就返回-1退出,反正就是不等你。这就叫非阻塞。非阻塞有一个轮询模型,就是如果问你你没有马上返回,我也不等你,我去干其它事情,然后过一定时间,再来问你。这就是轮询模型。
那么,我们来看看服务器使用这两种方式的情况:
1.服务器使用阻塞io。比如服务器等着50个客户端发送数据,50个客户端都连接进来,那么服务器就会选择一个端口阻塞在那里,等待这个端口对应的客户端发送数据过来。而如果此时其它客户端发送数据过来,那么服务器就处理不了,还一直阻塞在那个原来的端口上。此时这个线程所在进程是处于不可中断状态的。这里对进程的不可中断状态进行一些讲解:
不可中断状态 指的是进程正处于 内核态关键流程中的进程,并且这些进程是不可打断的 。比如向一个进程向磁盘读写数据时,为了保证数据的一致性,它是不可以被其它进程或者中断打断的。如果此时的进程被打断,就会出现进程数据和磁盘数据不一致的问题。所以, 不可中断状态实际上是系统对进程和硬件设备的一种保护机制 。ps -l中的 D状态即是不可中断状态 ,即uninterruptibe sleep或disk sleep。 java中的socket,获取锁都是处于不可中断状态。这个状态的进程并不会参与cpu的调度,所以相比下面的轮询机制来说,耗费cpu的资源相对较少,但是接收不到客户端的数据,这不也凉凉嘛。。。
而就 刚才前面的程序而言,只是单纯的等待终端输入数据,这个时候这个进程是处于睡眠状态,也就是说可以被唤醒。 在ps aux当中就是s的状态。不可中断状态也叫不可被中断的睡眠状态,也就是睡得更死些,比如打印数据的时候。 所以,服务器接收客户端的数据的时候,得看服务器用什么样的io阻塞客户端的数据了,这样才好说这个时候的进程是处于什么样的状态。当然,这里的都只是我们的假设,实际服务器并不会选择这种阻塞的方式。
2.服务端使用非阻塞io,也就是使用轮询模式。那么此时,服务器就得一直处于忙碌得每个端口的查询状态。而且此时这个查询的线程还一直占用着cpu,占着cpu的资源。当一个客户端的数据到达时,还得看服务器什么时候查到这个端口了才能进行相应的数据接收。所以,这种服务器也不行。
而现在的服务器使用的都是这样的一种模型:你客户端不来数据前,我就干其他的事情。当你有一个客户端来数据了,那么我就马上去处理你。这样相应就比较快了,而且也没有那么耗费cpu的资源。 这种就叫做多路io复用模型。
何柄融:多路复用I/O select poll epoll 这个是我之前学习的多路io复用模型的几个方法,大家可以试着参考学习一下。
下面是关于阻塞和非阻塞,进程的运行状态中的就绪和正在运行的一些理解:
读常规文件是不会阻塞的,不管读多少字节,read一定会在有限的时间内返回。从终端设备或网络则不一定,如果从终端输入的数据没有换行符,调用read读终端设备就会阻塞,如果网络上没有接收到数据包,调用read从网络读就会阻塞,至于会阻塞多长时问也是不确定的,如果一直没有数据到达就一直阻塞在那里。同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定。
现在明确一下阻塞(Block) 这个概念。当进程调用一个阻塞的系统函数时,该进程被置于睡眠(S1eep) 状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络、上接收到数据包,或者调用sleep指定的睡眠时间到了)它才有可能继续运行。与睡眠状态相对的是运行(Running) 状态,在Linux内核中,处于运行状态的进程分为两种情况:
正在被调度执行。CPU处于该进程的上下文环境中,程序计数器(eip) 里保存着该进程的指令地址,通用寄存器里保存着该进程运算过程的中间结果,正在执行该进程的指令,正在读写该进程的地址空间。
就绪状态。该进程不需要等待什么事件发生,随时都可以执行,但CPU暂时还在执行另一个进程,所以该进程在一个就绪队列中等待被内核调度。系统中可能同时有多个就绪的进程,那么该调度谁执行呢? 内核的调度算法是基于优先级和时间片的,而且会根据每个进程的运行情况动态调整它的优先级和时间片,让每个进程都能比较公平地得到机会执行,同时要兼顾用户体验,不能让和用户交互的进程响应太慢 。
然后到这里,我想讲的视频部分就讲到这里了。
接下来简单补充一下关于同步io和异步io的知识:
同步:
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做,等前一件做完了才能做下一件事。
例如普通B/S模式(同步):提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事
异步:
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
例如 ajax请求(异步): 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
1. 同步,就是我调用一个功能,该功能没有结束前,我死等结果。
2. 异步,就是我调用一个功能,不需要知道该功能结果,该功能有结果后通知我(回调通知)。
---------------------
作者:tengteng_
来源:CSDN
原文: https:// blog.csdn.net/Crazy_Ten gt/article/details/79225913
版权声明:本文为博主原创文章,转载请附上博文链接!
而 D:不可中断的深度睡眠,一般由IO引起,同步IO在做读或写操作时,cpu不能做其它事情,只能等待,这时进程处于这种状态,如果程序采用异步IO,这种状态应该就很少见到了
这就和前面的进程的不可中断状态联系起来了。
但是,这里感觉还是不清晰,linux什么时候是调用同步io,什么时候是调用异步io呢? 打印数据到控制台的时候就是同步io?? 还是等我买的书到了再慢慢进行研究吧。这网上的不权威,只能充当一个理解。
今天就先到这里吧。。。
欢迎交流讨论。
