|
|
|


Pytorch模型为什么要用tensorrt、onnx等工具部署,直接写成c的不可以吗?
关注者
28
被浏览
25,680
6 个回答


导读
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个模型推理框架,支持C++和Python推理。即我们利用Pytorch,Tensorflow或者其它框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行该模型,从而提升这个模型在NVIDIA-GPU上运行的速度。
可能很多人不太明白 CUDA,CUDNN和TensoRT的关系 ,这里做个简单介绍:
- cuda是NVIDIA推出的用于自家GPU进行并行计算的框架,用户可通过cuda的API调度GPU进行加速计算(只有当要解决的计算问题是可以大量并行计算时才能发挥cuda的作用)
- cudnn是NVIDIA推出的用于自家GPU进行神经网络训练和推理的加速库,用户可通过cudnn的API搭建神经网络并进行推理,cudnn则会将神经网络的计算进行优化,再通过cuda调用gpu进行运算,从而实现神经网络的加速(当然你也可以直接使用cuda搭建神经网络模型,而不通过cudnn,但运算效率会低很多)
- tensorrt其实跟cudnn有点类似,也是NVIDIA推出的针对自家GPU进行模型推理的加速库,只不过它不支持训练,只支持模型推理。相比于cudnn,tensorrt在执行模型推理时可以做到更快。
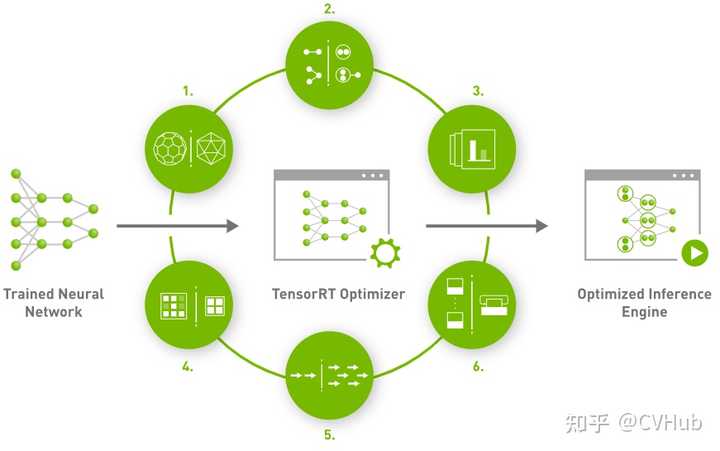
TensorRT主要通过下面两种技术来加速模型运行速度:
- tensorrt对网络结构进行了重构,将一些能合并的运算进行了合并(比如conv,bn,relu算子进行合并运算),且针对gpu的特性做了优化。对于cudnn来说,执行完conv,bn和relu三个操作可能需要调用三次cudnn对应的api进行计算,耗时比较长;但tensorrt则将三个操作进行了重构合并,进一步减少了推理时间
- 我们在模型训练的时候,通常采用float32数据进行训练,当模型训练完毕,其实无需使用float32这么高的精度进行推理。tensorrt则可以执行float16和int8执行推理,基本上几行代码搞定;但cudnn执行float16推理则相对要写比较多代码,也比较复杂
上一篇文章我们介绍了如何使用VSCode远程Linux配置C++大型工程开发环境,这篇文章则介绍一下在ubuntu系统如何正确安装C++版本的TensorRT并测试。
1. 明确ubuntu发行版本、cuda版本和cudnn版本
-
uname -a // 查看ubuntu发行版本信息
-
ls -l /usr/local/ | grep cuda // 查看cuda版本
-
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 // 查看cudnn版本
- cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 // 查看cudnn版本
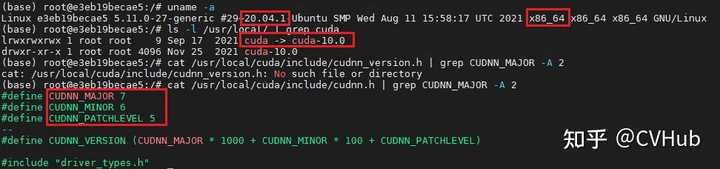
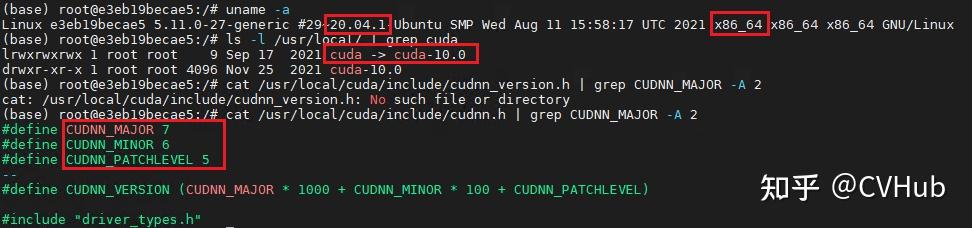
通过使用如上命令可查看linux系统的架构,cuda版本和cudnn版本信息,如上图所示我的linux服务器架构是X86-64位,系统发行版本是20.04,cuda版本是10.0,cudnn版本是7.6.5
注意:TensorRT8.5以下的版本包由于自带了cudnn,所以只需要关注cuda版本,无需关注cudnn版本;而8.5及以上的TensorRT不再捆绑cudnn,所以不仅要明确cuda版本,还需要明确我们系统的cudnn版本,再选择相应cuda和cudnn版本对应的TensorRT8.5及以上的版本进行安装
2. 官网下载对应版本的TensorRT
2.1 确定安装方式
TensorRT安装说明文档: https:// docs.nvidia.com/deeplea rning/tensorrt/install-guide/index.html#downloading
其实NVIDIA官网提供了四种TensorRT的安装方式:
- Debian Installation
- RPM Installation
- Tar File Installation
- Zip File Installation(只针对Win10系统)
由于本文只讨论Linux的TensorRT安装方式,所以只有前三种适用。下面介绍第1种和第3种安装方式。
3. dpkg命令安装TensorRT方式
3.1 下载相应版本TensorRT的deb安装文件
TensorRT下载官网: https:// developer.nvidia.com/nv idia-tensorrt-download

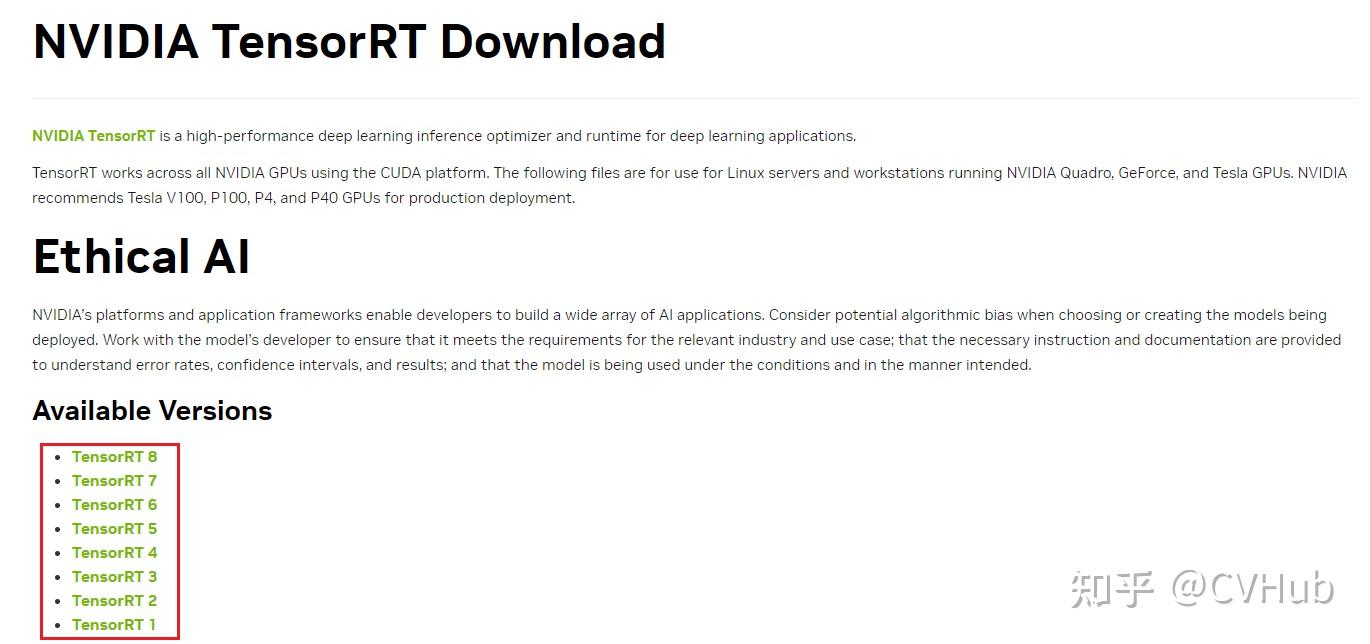
如上图所示,进入到TensorRT下载官网后,我们可以发现目前TensorRT有八个大版本,目前TensorRT8的版本只支持cuda11.0及以上的版本,如果大家的cuda是11.0及以上,可选择TensorRT8的版本进行下载安装。
这里由于笔者的cuda版本是10.0,所以目前选择了TensorRT7版本,下载完成之后是一个deb文件,将该deb文件上传至linux服务器某个位置。
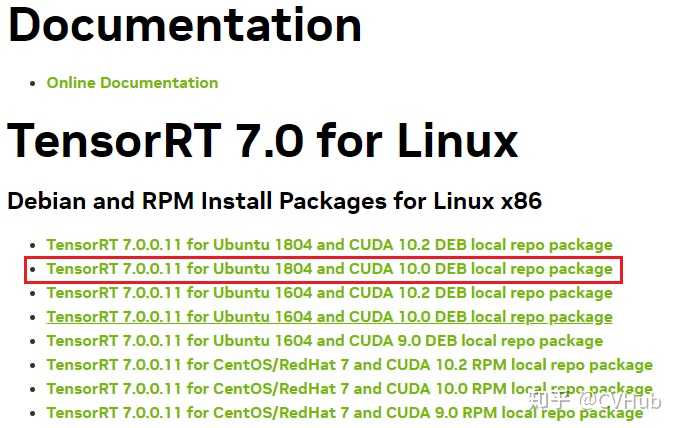

3.2 安装TensorRT
os="ubuntuxx04"
tag="8.x.x-cuda-x.x"
-
sudo dpkg -i nv-tensorrt-local-repo-
{os}-
{tag}_1.0-1_amd64.deb
-
sudo cp /var/nv-tensorrt-local-repo-
{os}-
{tag}/*-keyring.gpg /usr/share/keyrings/
- sudo apt-get update
- sudo apt-get install tensorrt
按照如上4个步骤进行TensorRT的安装,其中nv-tensorrt-local-repo-{tag}_1.0-1_amd64.deb要换成自己刚下载的deb文件。由于笔者先前安装过tensorrt7.0的版本,故运行apt-get install tensorrt之后,直接显示已安装了。


安装完成之后,输入命令: dpkg -l | grep TensorRT 如果显示如下图有关tensorrt的信息,说明tensorrt的c++版本安装成功:


4. Tar文件的TensorRT安装方式
4.1 下载相应版本TensorRT的tar安装文件


注意:大家根据自己的cuda版本下载相应的tensorrt的tar文件即可(由于笔者换了另外一台cuda11.4的linux服务器,所以下载了tensorrt8.5版本的tar包)
4.2 解压tar安装文件,并测试sampleOnnxMNIST
tar -zxvf TensoRT-8.5.1.7.Linux.x86_64-gnu.cuda-11.8.cudnn8.6.tar.gz
通过上面命令解压之后,会得到一个解压文件TensorRT-8.5.1.7,然后执行如下两条命令:
- cd TensorRT-8.5.1.7/samples/sampleOnnxMNIST
- make
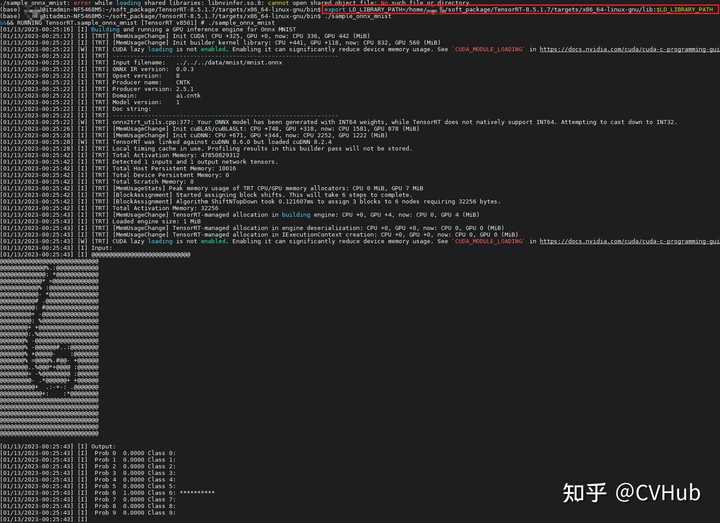
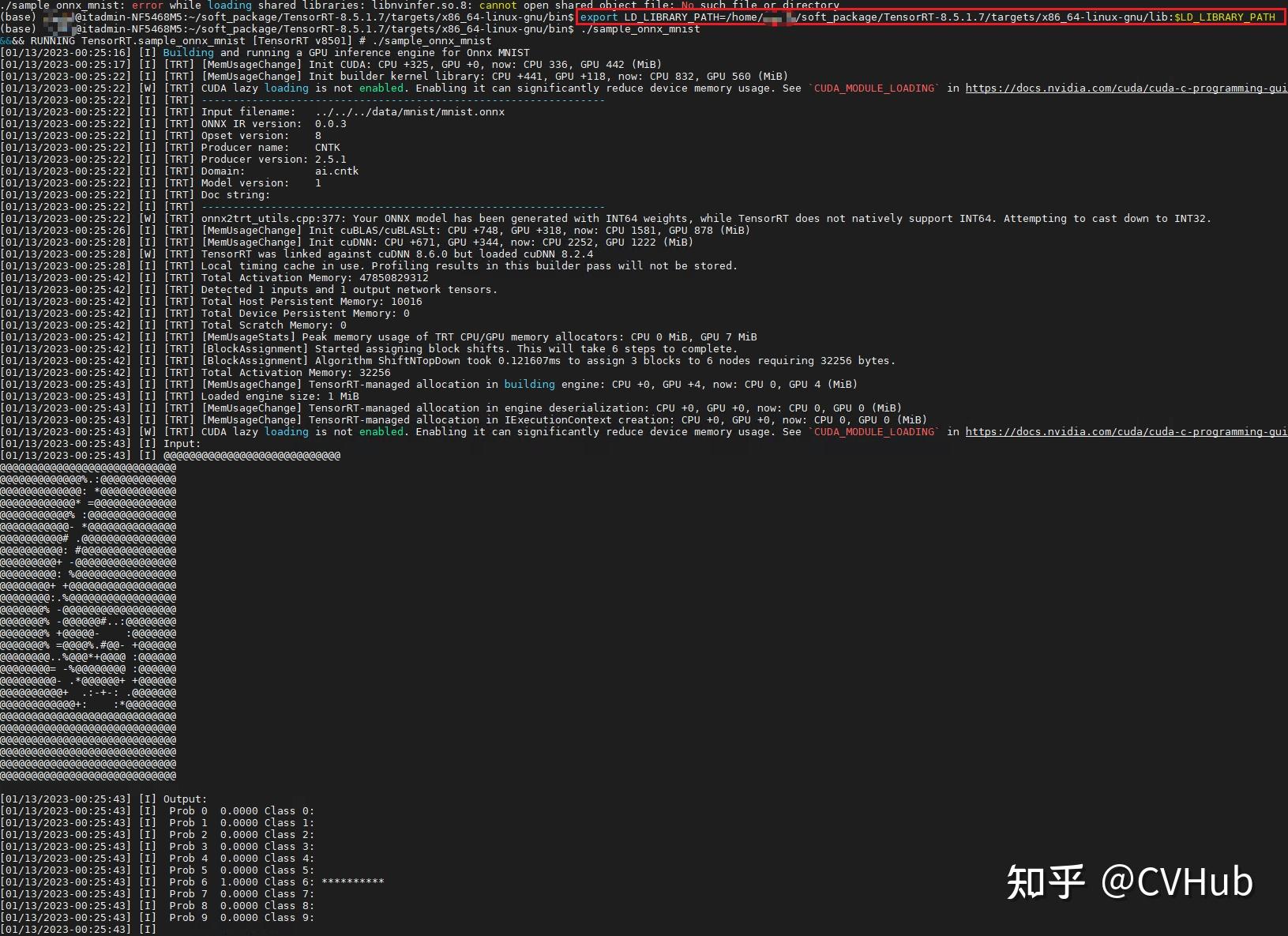
会在 TensoRT-8.5.1.7/targets/x_64-linux-gnu/bin/ 文件夹下得到一个sample_onnx_mnist的可执行文件,我们运行它后,会提示不能链接到libnvinfer.so.8的库:


这时候,我们通过命令export将tensorrt的库添加到环境变量中,再次运行sample_onnx_mnist,会得到如下输出即表明tensorrt安装成功:
总结
考虑到公众号很大一批粉丝量是在校生,在校精力基本集中于科研论文,较少接触到一些模型部署的C++项目。本公众号的《TensorRT模型部署系列》主要面向无C++模型部署经验的人群,让你掌握从零基础到部署自定义网络并集成发包全流程(企业级)。欢迎大家关注本系列文章,《TensorRT模型部署系列》的下一篇文章主要讲解如何编写cmakelists使用tensorrt库,并进行测试验证,欢迎持续关注!
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您加入有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编卫星号: cv_huber,备注"知乎",加入 CVHub 官方学术&技术交流裙,一同探讨更多有趣的话题!

手把手教学!TensorRT部署实战:YOLOv5的ONNX模型部署
1前言
TensorRT是英伟达官方提供的一个高性能深度学习推理优化库,支持C++和Python两种编程语言API。通常情况下深度学习模型部署都会追求效率,尤其是在嵌入式平台上,所以一般会选择使用C++来做部署。
本文将以YOLOv5为例详细介绍如何使用TensorRT的C++版本API来部署ONNX模型,使用的TensorRT版本为8.4.1.5,如果使用其他版本可能会存在某些函数与本文描述的不一致。另外,使用TensorRT 7会导致YOLOv5的输出结果与期望不一致,请注意。
2导出ONNX模型
YOLOv5使用PyTorch框架进行训练,可以使用 官方代码仓库 中的export.py脚本把PyTorch模型转换为ONNX模型:
python export.py --weights yolov5x.pt --include onnx --imgsz 640 640
作者:一天到晚潜水的鱼 | 原文出处: 公众号【自动驾驶之心】 自动驾驶之心->: 技术交流群
强烈推荐!自动驾驶与AI学习社区: 欢迎加入国内首个自动驾驶开发者社区!这里有最全面有效的自动驾驶与AI学习路线(感知/定位/融合)和自动驾驶与AI公司内推机会!
3准备模型输入数据
如果想用YOLOv5对图像做目标检测,在将图像输入给模型之前还需要做一定的预处理操作,预处理操作应该与模型训练时所做的操作一致。YOLOv5的输入是RGB格式的3通道图像,图像的每个像素需要除以255来做归一化,并且数据要按照CHW的顺序进行排布。所以YOLOv5的预处理大致可以分为两个步骤:
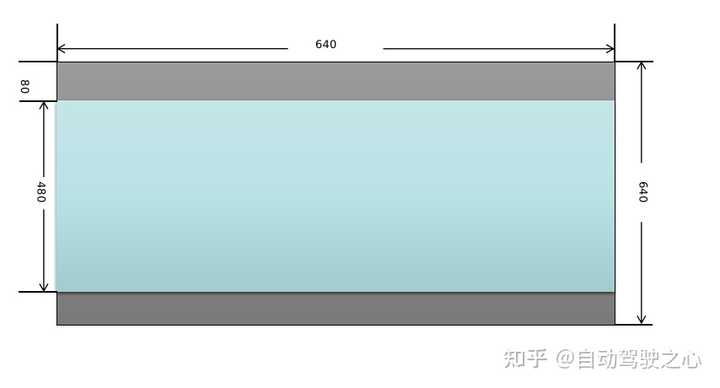
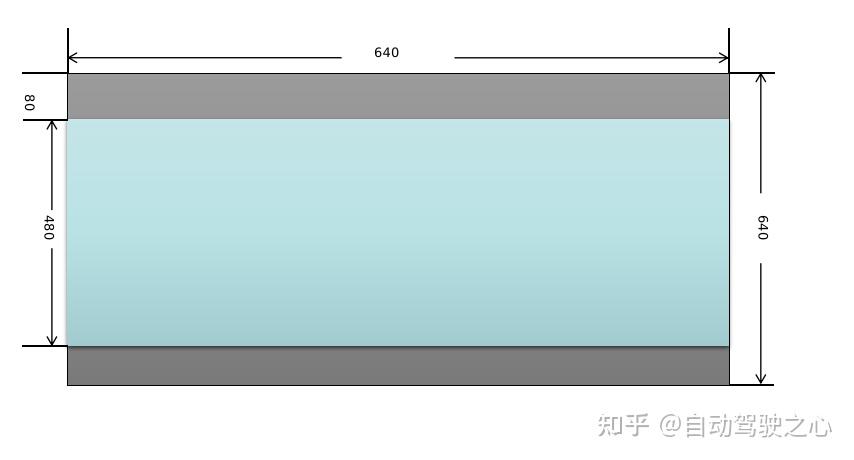
- 将原始输入图像缩放到模型需要的尺寸,比如640x640。这一步需要注意的是,原始图像是按照等比例进行缩放的,如果缩放后的图像某个维度上比目标值小,那么就需要进行填充。举个例子:假设输入图像尺寸为768x576,模型输入尺寸为640x640,按照等比例缩放的原则缩放后的图像尺寸为640x480,那么在y方向上还需要填充640-480=160(分别在图像的顶部和底部各填充80)。来看一下实现代码:
cv::Mat input_image = cv::imread("dog.jpg");
cv::Mat resize_image;
const int model_width = 640;
const int model_height = 640;
const float ratio = std::min(model_width / (input_image.cols * 1.0f),
model_height / (input_image.rows * 1.0f));
// 等比例缩放
const int border_width = input_image.cols * ratio;
const int border_height = input_image.rows * ratio;
// 计算偏移值
const int x_offset = (model_width - border_width) / 2;
const int y_offset = (model_height - border_height) / 2;
cv::resize(input_image, resize_image, cv::Size(border_width, border_height));
cv::copyMakeBorder(resize_image, resize_image, y_offset, y_offset, x_offset,
x_offset, cv::BORDER_CONSTANT, cv::Scalar(114, 114, 114));
// 转换为RGB格式
cv::cvtColor(resize_image, resize_image, cv::COLOR_BGR2RGB);
图像这样处理后的效果如下图所示,顶部和底部的灰色部分是填充后的效果。


- 对图像像素做归一化操作,并按照CHW的顺序进行排布。这一步的操作比较简单,直接看代码吧:
input_blob = new float[model_height * model_width * 3];
const int channels = resize_image.channels();
const int width = resize_image.cols;
const int height = resize_image.rows;
for (int c = 0; c < channels; c++) {
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
input_blob[c * width * height + h * width + w] =
resize_image.at<cv::Vec3b>(h, w)[c] / 255.0f;
4ONNX模型部署
1. 模型优化与序列化
要使用TensorRT的C++ API来部署模型,首先需要包含头文件NvInfer.h。
#include "NvInfer.h"
TensorRT所有的编程接口都被放在命名空间nvinfer1中,并且都以字母I为前缀,比如ILogger、IBuilder等。使用TensorRT部署模型首先需要创建一个IBuilder对象,创建之前还要先实例化ILogger接口:
class MyLogger : public nvinfer1::ILogger {
public:
explicit MyLogger(nvinfer1::ILogger::Severity severity =
nvinfer1::ILogger::Severity::kWARNING)
: severity_(severity) {}
void log(nvinfer1::ILogger::Severity severity,
const char *msg) noexcept override {
if (severity <= severity_) {
std::cerr << msg << std::endl;
nvinfer1::ILogger::Severity severity_;
上面的代码默认会捕获级别大于等于WARNING的日志信息并在终端输出。实例化ILogger接口后,就可以创建IBuilder对象:
MyLogger logger;
nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger);
创建IBuilder对象后,优化一个模型的第一步是要构建模型的网络结构。
const uint32_t explicit_batch = 1U << static_cast<uint32_t>(
nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicit_batch);
模型的网络结构有两种构建方式,一种是使用TensorRT的API一层一层地去搭建,这种方式比较麻烦;另外一种是直接从ONNX模型中解析出模型的网络结构,这需要ONNX解析器来完成。由于我们已经有现成的ONNX模型了,所以选择第二种方式。TensorRT的ONNX解析器接口被封装在头文件NvOnnxParser.h中,命名空间为nvonnxparser。创建ONNX解析器对象并加载模型的代码如下:
const std::string onnx_model = "yolov5m.onnx";
nvonnxparser::IParser *parser = nvonnxparser::createParser(*network, logger);
parser->parseFromFile(model_path.c_str(),
static_cast<int>(nvinfer1::ILogger::Severity::kERROR))
// 如果有错误则输出错误信息
for (int32_t i = 0; i < parser->getNbErrors(); ++i) {
std::cout << parser->getError(i)->desc() << std::endl;
模型解析成功后,需要创建一个IBuilderConfig对象来告诉TensorRT该如何对模型进行优化。这个接口定义了很多属性,其中最重要的一个属性是工作空间的最大容量。在网络层实现过程中通常会需要一些临时的工作空间,这个属性会限制最大能申请的工作空间的容量,如果容量不够的话会导致该网络层不能成功实现而导致错误。另外,还可以通过这个对象设置模型的数据精度。TensorRT默认的数据精度为FP32,我们还可以设置FP16或者INT8,前提是该硬件平台支持这种数据精度。
nvinfer1::IBuilderConfig *config = builder->createBuilderConfig();
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1U << 25);
if (builder->platformHasFastFp16()) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
设置IBuilderConfig属性后,就可以启动优化引擎对模型进行优化了,这个过程需要一定的时间,在嵌入式平台上可能会比较久一点。经过TensorRT优化后的序列化模型被保存到IHostMemory对象中,我们可以将其保存到磁盘中,下次使用时直接加载这个经过优化的模型即可,这样就可以省去漫长的等待模型优化的过程。我一般习惯把序列化模型保存到一个后缀为.engine的文件中。
nvinfer1::IHostMemory *serialized_model =
builder->buildSerializedNetwork(*network, *config);
// 将模型序列化到engine文件中
std::stringstream engine_file_stream;
engine_file_stream.seekg(0, engine_file_stream.beg);
engine_file_stream.write(static_cast<const char *>(serialized_model->data()),
serialized_model->size());
const std::string engine_file_path = "yolov5m.engine";
std::ofstream out_file(engine_file_path);
assert(out_file.is_open());
out_file << engine_file_stream.rdbuf();
out_file.close();
由于IHostMemory对象保存了模型所有的信息,所以前面创建的IBuilder、IParser等对象已经不再需要了,可以通过delete进行释放。
delete config;
delete parser;
delete network;
delete builder;
IHostMemory对象用完后也可以通过delete进行释放。
2. 模型反序列化
通过上一步得到优化后的序列化模型后,如果要用模型进行推理,那么还需要创建一个IRuntime接口的实例,然后通过其模型反序列化接口去创建一个ICudaEngine对象:
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(logger);
nvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine(
serialized_model->data(), serialized_model->size());
delete serialized_model;
delete runtime;
如果是直接从磁盘中加载.engine文件也是差不多的步骤,首先从.engine文件中把模型加载到内存中,然后再通过IRuntime接口对模型进行反序列化即可。
const std::string engine_file_path = "yolov5m.engine";
std::stringstream engine_file_stream;
engine_file_stream.seekg(0, engine_file_stream.beg);
std::ifstream ifs(engine_file_path);
engine_file_stream << ifs.rdbuf();
ifs.close();
engine_file_stream.seekg(0, std::ios::end);
const int model_size = engine_file_stream.tellg();
engine_file_stream.seekg(0, std::ios::beg);
void *model_mem = malloc(model_size);
engine_file_stream.read(static_cast<char *>(model_mem), model_size);
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(logger);
nvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine(model_mem, model_size);
delete runtime;
free(model_mem);
3. 模型推理
ICudaEngine对象中存放着经过TensorRT优化后的模型,不过如果要用模型进行推理则还需要通过createExecutionContext()函数去创建一个IExecutionContext对象来管理推理的过程:
nvinfer1::IExecutionContext *context = engine->createExecutionContext();
现在让我们先来看一下使用TensorRT框架进行模型推理的完整流程:


- 对输入图像数据做与模型训练时一样的预处理操作。
- 把模型的输入数据从CPU拷贝到GPU中。
- 调用模型推理接口进行推理。
- 把模型的输出数据从GPU拷贝到CPU中。
- 对模型的输出结果进行解析,进行必要的后处理后得到最终的结果。
由于模型的推理是在GPU上进行的,所以会存在搬运输入、输出数据的操作,因此有必要在GPU上创建内存区域用于存放输入、输出数据。模型输入、输出的尺寸可以通过ICudaEngine对象的接口来获取,根据这些信息我们可以先为模型分配输入、输出缓存区。
void *buffers[2];
// 获取模型输入尺寸并分配GPU内存
nvinfer1::Dims input_dim = engine->getBindingDimensions(0);
int input_size = 1;
for (int j = 0; j < input_dim.nbDims; ++j) {
input_size *= input_dim.d[j];
cudaMalloc(&buffers[0], input_size * sizeof(float));
// 获取模型输出尺寸并分配GPU内存
nvinfer1::Dims output_dim = engine->getBindingDimensions(1);
int output_size = 1;
for (int j = 0; j < output_dim.nbDims; ++j) {
output_size *= output_dim.d[j];
cudaMalloc(&buffers[1], output_size * sizeof(float));
// 给模型输出数据分配相应的CPU内存
float *output_buffer = new float[output_size]();
到这一步,如果你的输入数据已经准备好了,那么就可以调用TensorRT的接口进行推理了。通常情况下,我们会调用IExecutionContext对象的enqueueV2()函数进行异步地推理操作,该函数的第二个参数为CUDA流对象,第三个参数为CUDA事件对象,这个事件表示该执行流中输入数据已经使用完,可以挪作他用了。如果对CUDA的流和事件不了解,可以参考我之前写的 这篇文章 。
cudaStream_t stream;
cudaStreamCreate(&stream);
// 拷贝输入数据
cudaMemcpyAsync(buffers[0], input_blob,input_size * sizeof(float),
cudaMemcpyHostToDevice, stream);
// 执行推理
context->enqueueV2(buffers, stream, nullptr);
// 拷贝输出数据
cudaMemcpyAsync(output_buffer, buffers[1],output_size * sizeof(float),
cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
模型推理成功后,其输出数据被拷贝到output_buffer中,接下来我们只需按照YOLOv5的输出数据排布规则去解析即可。
4. 小结
在介绍如何解析YOLOv5输出数据之前,我们先来总结一下用TensorRT框架部署ONNX模型的基本流程。
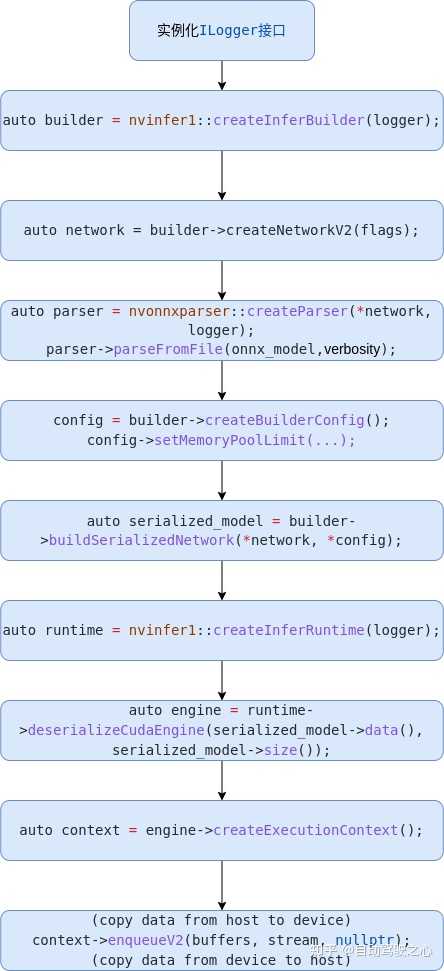
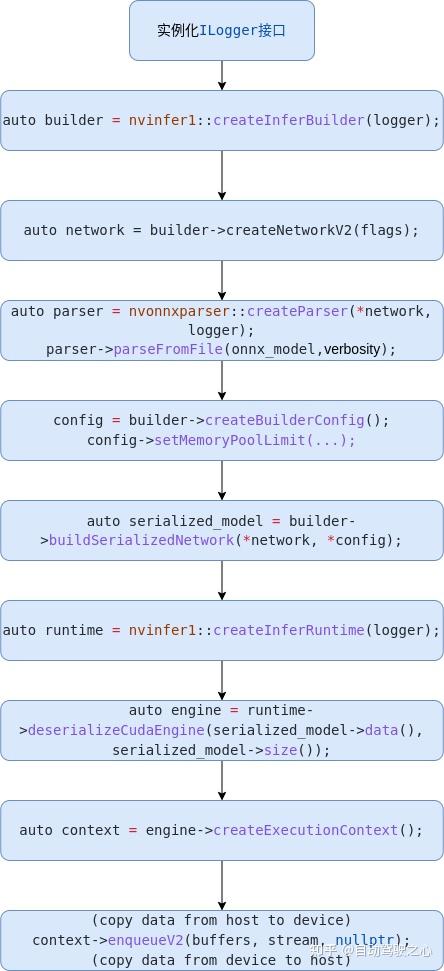
如上图所示,主要步骤如下:
- 实例化Logger;
- 创建Builder;
- 创建Network;
- 使用Parser解析ONNX模型,构建Network;
- 设置Config参数;
- 优化网络,序列化模型;
- 反序列化模型;
- 拷贝模型输入数据(HostToDevice),执行模型推理;
- 拷贝模型输出数据(DeviceToHost),解析结果。
5解析模型输出结果
YOLOv5有3个检测头,如果模型输入尺寸为640x640,那么这3个检测头分别在80x80、40x40和20x20的特征图上做检测。让我们先用Netron工具来看一下YOLOv5 ONNX模型的结构,可以看到,YOLOv5的后处理操作已经被包含在模型中了(如下图红色框内所示),3个检测头分支的结果最终被组合成一个张量作为输出。
yolov5m
YOLOv5的3个检测头一共有(80x80+40x40+20x20)x3=25200个输出单元格,每个单元格输出x,y,w,h,objectness这5项再加80个类别的置信度总共85项内容。经过后处理操作后,目标的坐标值已经被恢复到以640x640为参考的尺寸,如果需要恢复到原始图像尺寸,只需要除以预处理时的缩放因子即可。这里有个问题需要注意:由于在做预处理的时候图像做了填充,原始图像并不是被缩放成640x640而是640x480,使得输入给模型的图像的顶部被填充了一块高度为80的区域,所以在恢复到原始尺寸之前,需要把目标的y坐标减去偏移量80。
详细的解析代码如下:
float *ptr = output_buffer;
for (int i = 0; i < 25200; ++i) {
const float objectness = ptr[4];
if (objectness >= 0.45f) {
const int label =
std::max_element(ptr + 5, ptr + 85) - (ptr + 5);
const float confidence = ptr[5 + label] * objectness;
if (confidence >= 0.25f) {
const float bx = ptr[0];
const float by = ptr[1];
const float bw = ptr[2];
const float bh = ptr[3];
Object obj;
// 这里要减掉偏移值
obj.box.x = (bx - bw * 0.5f - x_offset) / ratio;
obj.box.y = (by - bh * 0.5f - y_offset) / ratio;
obj.box.width = bw / ratio;
obj.box.height = bh / ratio;
obj.label = label;
obj.confidence = confidence;
objs->push_back(std::move(obj));